基于優化概率神經網絡的制造業財務預警研究
2019-03-11 07:29:31張丹曹紅蘋
智能計算機與應用 2019年6期
張丹 曹紅蘋

摘要:財務預警通過對企業相關指標分析構建出預測模型,達到對其風險進行預測的目的,可為利益相關者的關聯決策提供依據,使得預警效率的研究成為重點。以90家制造企業的相關數據構成樣本搭建概率神經網絡模型進行預警研究,為提升模型的效率,引入粒子群算法對模型進行優化。實證分析中得出,未用粒子群算法優化前模型的預測準確率為87.5%,經優化后模型的預測正確率為93.75%。則使用粒子群算法對神經網絡的優化的可行性較高,這可做為財務預警研究的一種新思路。
關鍵詞:財務預警;概率神經網絡;粒子群算法;主成分分析
0引言
財務預警是一種基于風險表征性指標進行危機預測的研究,通過構建預警體系,利益相關者可以發現企業在經營管理活動中的潛在風險,在決策時能夠考慮得更充分,進而避免產生不必要的損失。危機越早防范越有利于企業的健康穩定成長,有效的危機預警可促進企業的平穩化發展。近年來,隨著經濟全球化和互聯網經濟的發展,企業之間的競爭更加激烈,利益相關者日益增加對預警情況的關注力度,這為預警研究的進一步發展提供契機。
企業財務預警的表述形式雖然較為多樣化,但主要思想是基于相關指標對于陷入財務危機的企業構建有效模型,以期得到改善不良經營狀態的監管策略,進而使得企業得到長遠的發展。在20世紀30年代,隨著美國經濟大蕭條時期的出現,大多數公司的經營管理面臨著較大的波動風險,財務預警問題也隨之被重視起來,而國內則是于90年代后才開始相關的研究。早期的預警研究是單變量模型,即通過單項指標進行分析,如Fitzpatrick(1932)和Beaver(1966);隨后的研究則更傾向于多變量型,經典的模型是Altman(1968)的Z-Score模型,F模型、Logit、Probit、時間序列分析和生存分析。隨著信息時代的來臨,智能化分析方法也開始涌現,神經網絡、決策樹等滲入到預警研究中,使得預警達到更為良好的效果,
由于神經網絡模型在預測分析問題的適用性強,其中概率神經網絡對于參數的設置較少且對噪聲的容忍度較高,則可將其引入到預警研究中。現階段人工智能飛速發展,算法的引用為預警研究拓寬渠道,其與基礎模型的融合可提升研究的效率,文中擬引入粒子群算法進行模型的優化。通過嵌入粒子群算法,構建出優化的預測模型,以期達到更好的預測效果,
1優化模型理論
1.1 粒子群算法
粒子群算法(Particle Swarm Optimization.PSO)是由Eberhart和Kennedy于1995年提出的一種優化算法,二人從鳥群搜食過程發現個體與全局之間的信息共享傳遞機制,該機制的精髓在于可在目標空間中尋求最優解。該方法從隨機解出發,根據需要擬定隨機解后迭代尋求最優解,解的效果是通過適應度函數進行評價,通過在解空間追隨最優的粒子進行搜索,使其容易實現優化且參數調整較少。
在PSO中,開始時會產生一群隨機粒子,每個都代表目標問題的一個可能解,對應著適應值(c.粒子在搜索空間的移動由矢量化的速度表示移動的方向和距離,粒子的移動會伴隨著極值的迭代。每次迭代中,粒子會追尋兩項極值進行更新:
(1)個體極值,粒子自身的最優解;
(2)全局極值,粒子在空間內運動得到的目前整個種群的最優解。
當粒子迭代達到設定的循環次數或者與目標函數的誤差率達到一定精度時就會終止,得到全局最優適應值。設定在D維目標搜索空間中,有N個粒子構成的粒子群(i=1.2.…,N),過程相應參數表示如下:
在速度替換公式中c1和c2是加速常數,也稱學習因子,通常取2.r1和r2是[0.1]內均勻隨機數。速度公式中其替換是由三項加總而成,第一項是“慣性”部分,表明粒子維持原來速度的傾向,w表示對原來速度的保留程度,數值越大,全局收斂能力越強,反之局部收斂能力越弱:第二項是“認知”部分,是粒子對歷史經驗的記憶,表明粒子向其最佳位置逼近的傾向:第三項是“社會”部分,是粒子間協作共享群體歷史經驗,表明粒子向鄰域最佳位置逼近的傾向。粒子的速度有一定的范圍,是研究者根據需要設定的,主要用來限制其速度。粒子群算法中搜索迭代式工作使其形成一個有效地循環體,過程中對目標函數的計算貫徹始終,是PSO指導搜索方向的依據,PSO的適應度函數種類較多,在進行模擬搜索中應結合目標問題設定。
1.2 概率神經網絡
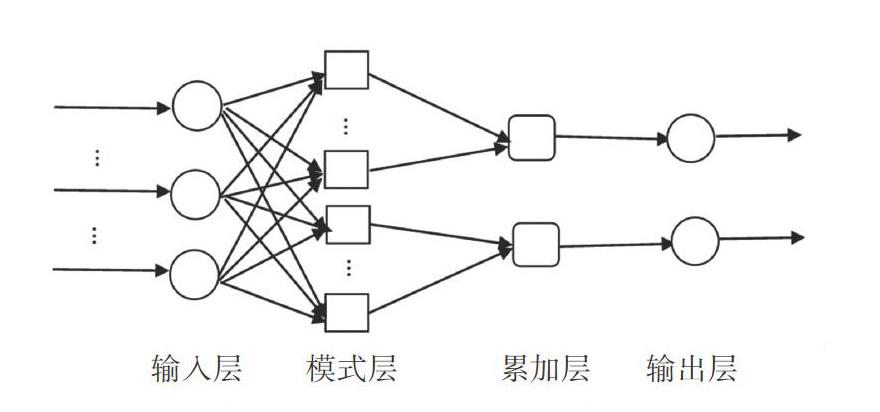
概率神經網絡(PNN)是由d.f.Specht于1990年提出的一種神經網絡,常用于進行模式。其為基于最小風險貝葉斯決策的層內互連的前向網絡,具有四層神經元結構:輸入層、模式單元層、匯總單元層和輸出層。基本結構如圖l所示。
輸入層導人樣本數據,節點數與其維度保持一致:輸入層通過一定的權重與模式層結合,模式層針對傳輸過來的數據進行處理:累加層可稱為求和層,每個結點對應特定的模式分類形成映射,根據這種映射關系產生特定類型的分布函數:輸出層根據匯總情況得出判定類型,輸出類別。概率神經網絡處理任意維度輸出的分類應用問題的效率較高,模式簡潔學習速度較快,且對樣本數量要求不高,根據不同需求層次可設定相應決策面的范圍,對于錯誤及噪聲容忍度較高。
概率神經網絡模式分類的具體過程如下:
(1)假定研究對象中有m個訓練樣本,特征向量為n.表示如下:
(3)把預期進行分類的測試樣本歸一化,用輸入層讀取。
(4)計算輸入的測試樣本與樣本矩陣中樣本距離。
(5)模式層神經元被激活,得到原始概率矩陣,若有p個測試樣本,用Epm表示測試樣本p到訓練樣本m的距離,概率矩陣可表示如下:
(6)在判別函數中選擇值最大的,相應類別就是輸入的測試樣本最可能的類別。
1.3優化模型
在將樣本數據導入神經網絡之前需要對其進行預處理,為保證數據涵蓋面的廣泛性,則需構建較多的指標,則會造成數據的冗余。為提升數據的有效性,擬對原始數據進行主成分分析處理。經處理的數據導人PNN進行分析,然后經過粒子群算法對其效果進行優化,達到較好的分析效果。具體分析步驟如圖2所示,
2實證分析
2.1 樣本數據的選取
研究樣本的選擇需要從兩方面出發:目標公司及其對應指標。鑒于制造業對國民經濟的影響程度較高且每年風險型公司在該行業內的數量最多,則從制造業行業內進行篩選。在進行公司樣本提取時選擇滬深A股,主要是其數據的完整性及與中國國情貼合度均相對較高。從國泰安數據庫中導出2016年制造業中被ST的共計45家公司,另匹配45家同行業且規模相當的正常經營公司作為對照組。為了后續模型能夠對公司風險狀況進行識別,將風險型公司標記為2.正常型標記為1.且設定兩種類型各自的前37個劃分為訓練集,后續的8家劃分為測試集。指標的篩選涵蓋盈利能力、經營能力、償債能力、發展能力、比率結構、風險水平、現金流分析、基本每股收益共計8類31項指標。
2.2 主成分分析結果
為確保主成分分析的可行性,先將樣本數據進行相關性檢驗,見表1。
從表1中可知KMO>0.5.即原始數據適合做主成分分析。通過SPSS22提取有效因子,見表2。
在主成分分析結果表中前13個因子的累計方差貢獻率為87.077%,超過85%,可對原始數據進行有效概括,則提取13個因子,計算對應得分以備導人概率神經網絡。
2.3 粒子群優化參數值
粒子群分析適應度函數設定為訓練組的預測正確率,部分相關參數設置見表3。
粒子群算法中,各粒子為追求最優解按照矢量化的速度在目標空間移動,速度伴隨著粒子的運動不斷變化。初始化速度需事先設定,文中結合粒子最大速度隨機產生設定為vmax*(2*rand(1.N)-1)。慣性權重打破常規的定值,改為隨著迭代次數的增加而逐漸減小,既可突破前期落到局部最優誤區又可在后期加速收斂,能夠維持算法的穩定性,公式如下:
w=wmax-(wmax-wmin)*k/kt(k為循環體內當前循環次數) (10)
粒子的更新速度為:v=w*v+cl*r*(Pbest-pn)+c2*r*(gbest-pn)
(11)
gbest=1.0557.gfbest=0.9375.即在spread=1.0557時,訓練組的預測正確率得到最優h=93.75%。
通過粒子群算法的優化,spread=1.0557構建模型。針對模型分析結果的誤差進行分析,樣本的誤差值為樣本預測風險類型值與樣本實際風險類型值的差值,樣本的預測結果有2種可能性1或2.真實的風險狀況值為1或2.則誤差的取值為0.-1.1三種情形,得到訓練組和測試組結果見表4。
由表4知,訓練組74個樣本中僅有1個預測錯誤,正確率達到98.65%,測試組16個樣本中僅有一個樣本由風險型判為正常型,正確率為93.75%,90個樣本的整體預測率為97.78%。
2.4 各模型預測結果對比
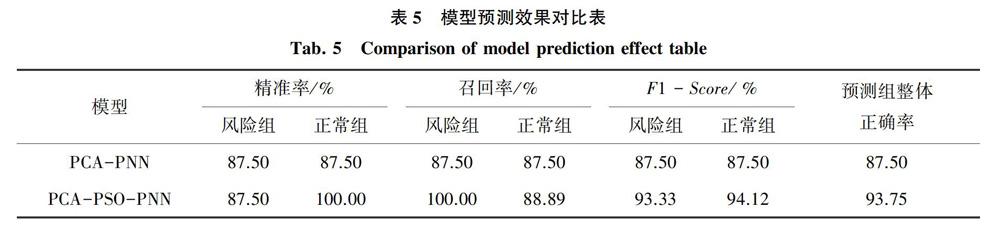
通過模型進行分析預測,其效果的評判應當從測試集人手,則對優化前后的模型進行對比結果見表5。
從預測效果對比表可知,經過粒子群對參數進行優化,對正常組的識別更為突出可達到100%,預測組的整體正確率有一定幅度的提升一超過90%,預測效果較好。企業在通過模型判定風險類型后,可按照因子得分將樣本公司排序,通過對比分析,查看自身的優勢及不足,制定對應的個性化風險規避方案。
3 結束語
以90家制造業上市公司的31項財務指標為樣本數據,通過主成分分析處理后導人概率神經網絡,并通過粒子群算法尋優得到較為理想的參數值,模型最后的預測效果也較好,表明改進方法是有效的,可為利益相關者的規避風險提供一種研究途徑。在深層次上,各家企業在整理自身相關指標的同時,又能得到現行或潛在利益相關者的有效信息,根據信息的整合可為公司的戰略發展提供一定的支撐。文中僅選擇制造業公司某一年的數據進行研究,但是企業陷入危機是一種持續性變化的狀態,以后的研究中可采用多個時間段進行動態化分析。
