基于統計特征的微博垃圾用戶檢測系統研究
2019-03-17 09:36:34范雨萌易秀雙倪石建王興偉
網絡空間安全 2019年9期
范雨萌 易秀雙 倪石建 王興偉
摘? ?要:微博作為國內用戶規模較大的在線社交網絡平臺之一,面臨著來自垃圾用戶的困擾。垃圾用戶通過微博平臺發起網絡攻擊,污染網絡環境、威脅用戶隱私安全,甚至造成了經濟損失,因此如何有效地檢測垃圾用戶是一個亟待解決的問題。目前,基于機器學習的檢測方法并沒有考慮時間的變化性,隨著時間推移其檢測性能下降。文章采用機器學習分類方法挖掘用戶信息與微博信息的統計特征,基于Spark大數據平臺,設計并實現了一套微博垃圾用戶檢測系統。該系統結合傳統的離線檢測與在線檢測,通過在線檢測解決時間的變化性問題,優化了傳統離線檢測的性能。文章的實驗結果表明該系統離線檢測部分的準確率最高可達到93.4%,在線檢測部分的準確率最高可達到94.8%,均高于微博反垃圾系統的67.4%。
關鍵詞:垃圾用戶檢測;離線檢測;在線檢測;半監督學習檢測;主動學習檢測
中圖分類號:TP391? ? ? ? ? 文獻標識碼:A
Abstract: As one of the large-scale online social networking platforms for domestic users, Weibo faces troubles from spammers. Spammers launch attacks through weibo platform, polluting the network environment,threatening users' security of privacy, and even causing economic losses. Therefore, how to effectively detect spammers is an urgent problem to be solved. Current detection methods based on machine learning do not take into account the variability of time, and their detection performance declines over time. In this paper, the machine learning classification method is used to mine the statistical characteristics of user information and microblog information,designed and implemented a set of Weibo spammer detection system based on Spark big data platform. The system combines traditional offline detection and online detection. Solving the problem of time variability through online detection, and optimizes the performance of traditional offline detection. The experimental results in this paper show that the accuracy of the off-line detection part of the system can reach 93.4%, and the accuracy of the online detection part can reach 94.8%, which is higher than 67.4% of Weibo anti-spam system.
Key words: spammer detection; offline detection; online detection; semi-supervised learning detection ; active learning detection
1 引言
隨著互聯網的飛速發展,人們越來越依靠網絡進行日常活動[1],微博等在線社交網絡已成為人們交流互動的重要平臺,同時也為垃圾用戶提供了傳播惡意消息的機會。大量垃圾用戶的評論和轉發淹沒了正常用戶的消息,影響用戶上網體驗。有的垃圾用戶發布的消息含虛假信息,甚至還會鏈入含木馬的釣魚網站,威脅用戶的隱私和財產安全。因此,如何營造一個可靠安全的網絡環境,有效地在微博社交平臺進行垃圾用戶檢測成為一個關鍵的問題。
目前檢測垃圾用戶的方案主要有三類。第一類是基于社交網絡圖的相關算法。Yang[2]等人應用隨機游走方法對社交網絡上的虛假垃圾賬戶進行了檢測識別。Gong[3]等人通過二進制隨機變量將每個用戶標記為正常用戶或垃圾用戶,然后使用馬爾可夫隨機場計算用戶良性的概率。第二類是基于文本內容的檢測方法。Hu[4]等人利用E-Mail、短信息、Web等其他媒體中惡意垃圾用戶的文檔,與Twitter 中的文檔共同組成跨媒體知識庫模型來識別垃圾用戶。第三類是基于機器學習算法的檢測方法。Cao[5]等人提出轉發消息樹定義并從中提取特征來訓練分類器,以找到將某些可疑消息轉發到一起的隱藏可疑帳戶。Fu[6]等人提出從用戶的時間演化模式中提取特征,然后將無監督聚類和監督分類相結合,以檢測不斷變化的垃圾用戶。Cao[7]等人通過分析轉發行為與惡意URL傳播之間的聯系,提出了三種基于轉發的特性,將這些功能與其他社交功能相結合,以訓練分類器識別惡意URL,從而識別垃圾用戶。機器學習檢測是大數據時代使用最為廣泛的解決方案,但是一些檢測算法未考慮時間的變化性。
本文通過對用戶信息和微博信息進行挖掘,確定了四大類統計型數值特征,采用單分類機器學習檢測模型與集成機器學習檢測模型進行離線垃圾用戶檢測。而針對離線檢測存在的問題,提出了對應的解決方案,包括半監督學習檢測方法、主動學習檢測方法、離線數據更新機制,對這三種方法進行融合得到微博垃圾用戶在線檢測方案。經過實驗證明本文系統比微博反垃圾系統檢測效果要好,有效、可行,具有一定的實際應用價值。
2 垃圾用戶檢測方法
2.1 離線檢測方法
(1)特征選擇
本文通過對微博用戶文本內容、互動性信息、個人信息的特點進行分析,提取了用戶行為特征、微博整體特征、原創微博特征、轉發微博特征四大統計特征。
1)用戶行為特征包括用戶互動性特征、注冊時間特征、用戶信息相關特征三大類。用戶互動性特征包含關注數、粉絲數、微博數及相關組合特征微博數/粉絲數、關注數/粉絲數、用戶名譽度;注冊時間特征為微博注冊時間,垃圾用戶大多注冊時間很短;用戶信息相關特征包括0-1型特征,即是否含有生日信息、是否含有簡介信息、是否含有興趣標簽、是否是認證用戶、是否包含教育工作信息與會員等級。
2)微博整體性特征包括微博互動性特征 、微博發表平臺特征、微博時間特征、內容符號信息特征四大類。微博互動性特征包括微博轉發平均數、微博評論平均數、微博點贊平均數;微博平臺特征為使用互聯網平臺占比;內容符號特征包括微博含有鏈接平均數,含有@平均數,含有熱門話題標簽平均數。
3)原創微博特征包括原創微博地址特征、原創微博圖片視頻特征、原創微博文本特征三大類。原創微博地址特征為原創微博含有地址占比;原創微博圖片視頻特征包括原創微博配圖平均數、原創微博秒拍視頻平均數;原創微博文本特征為原創微博字數平均數。
4)轉發微博特征包括轉發理由特征、轉發原文特征、轉發時間特征三大類。轉發理由特征包括轉發理由平均字數、轉發微博中無理由占比、轉發微博當次轉發距原始微博轉發次數平均數;轉發原文特征包括互動性特征:原文轉發平均數、原文評論平均數、原文點贊平均數、原文微博字數平均數;轉發時間特征為轉發微博與原文時間間隔平均數。
為了精簡特征,提高檢測分類器分類性能,對與類標簽相關性不是很強的特征進行淘汰處理。方差選擇法作為預處理方法,Pearson相關系數、互信息選擇法、卡方檢驗法作為特征選擇方法,每種方法均會產生特征重要性權重排名,取三種方法權重平均數,進行綜合排名,最后選擇k個排名較高特征,其中k根據實驗結果選取為25。
(2)檢測模型
本文采用單分類檢測模型包括邏輯斯蒂回歸,支持向量機檢測分類模型,集成檢測模型包括隨機森林,梯度提升決策樹分類模型共四種分類器,對其相關參數進行調優,使之更加高效適用于微博垃圾用戶離線檢測分類環境。最后,結合實驗結果與各自檢測分類器的特點,選擇檢測效果較好、模型訓練復雜度適中、魯棒性較強的隨機森林檢測分類器作為最終的離線檢測分類器,同時也作為本文在線檢測訓練的默認檢測分類器。
2.2 在線檢測方法
(1)半監督學習檢測
為了解決離線檢測類標注效率低的問題,引入半監督學習可以為初始數據集中大量的未標注的微博用戶樣本進行類標注[8]。本文的半監督學習算法主要包含兩部分,基于圖的類標簽傳播半監督分類算法與離線檢測驗證機制。采用半監督分類方法后,初始微博用戶數據集全部均獲得了類標簽,為了提高類標簽的置信度,本文采用離線檢測驗證機制。離線檢測分類器驗證機制是對全部未獲得類標注的微博用戶樣本采用離線檢測分類器進行檢測,留下強類型的微博用戶樣本,與半監督分類方法獲得的類標簽相結合,如果同時滿足,則加入到半監督學習訓練集中。將半監督學習訓練集與初始有類標注訓練集合并,形成在線檢測的初始訓練集。
(2)主動學習檢測
隨著時間的推移,由于后續沒有引入新的微博用戶數據,離線檢測分類器檢測性能會有一定的下降。通過主動學習可以實現引入少量價值度高的新的微博用戶樣本對分類器進行更新迭代。本文結合基于不確定性采樣和基于委員會采樣兩種主動學習采樣方法,采用基于最大不確定性的停止準則,通過對微博用戶數據進行分析和相關實驗比較,停止準則閾值選擇范圍為0.889~1.0。每種采樣方法得到對應的用戶數據集,如果微博用戶樣本存在于兩種用戶數據集中,則將該用戶加入本次在線更新微博用戶數據集。最終將本次在線更新微博用戶數據集加入到上次檢測的微博用戶訓練集中一起訓練,從而得到本次的在線檢測分類器。
(3)離線數據在線更新機制
垃圾用戶特點會隨著時間發展發生變化,比如前幾年的惡意URL這種垃圾行為在當今微博平臺中已經很少見了。主動學習檢測方法雖然會引入新的微博用戶數據,但是老舊樣本仍占據著較大比例,嚴重影響分類模型的檢測效果,因此本文提出了離線數據在線更新機制。綜合考慮微博用戶發表微博頻率并結合數據獲取效率,選擇15天更新頻率進行更新微博用戶數據,包含兩個操作,更新操作與淘汰操作。
更新操作包括采集最新用戶相關信息,采集用戶發表最新的50條微博,保存到本地數據庫中。利用在線檢測分類器,計算出當前用戶的檢測概率值。與上次檢測的概率值進行比較,對于那些檢測概率值有較大變化的微博用戶,需要提交人工校驗,重新進行類標簽標注。如果檢測概率值變化超過閾值時,同樣需要供人工校驗重新標注。
淘汰操作是對于一些老舊的微博用戶樣本,如果出現長時間沒有更新、每次更新內容較少者、當前用戶被封禁這三種情況,那么就可以認為這些用戶為不活躍用戶,對于這類的微博用戶樣本則需要進行淘汰。對于每一個樣本,如果當前未被封禁但是未更新次數達到四次,當前被封禁且未更新次達到兩次,如果當前未封禁但是每次更新微博數低于兩條且累計次數達到六次,那么當前微博用戶需要從當次在線檢測訓練集中淘汰掉,不再參與后續在線檢測訓練。
3 實驗結果與分析
3.1 實驗環境
選擇五臺PC機作為集群節點,其中一臺作為Master節點,四臺作為Worker節點部署安裝Hadoop,之后在各自節點基礎上安裝Spark。HDFS集群在Master節點部署NameNode與ResourceManager,在Worker節點上部署DataNode與NodeManager。
3.2 實驗數據
(1)初始數據集
初始數據集為爬蟲獲取到的9萬條微博用戶共計約450萬條微博用戶數據,之后隨機選擇1萬名微博用戶進行類標簽標注,獲取到2168個垃圾用戶與7089個正常用戶,743個中間地帶用戶,而其余8萬條微博用戶數據沒有進行標注。
(2)在線數據集
由于后續需要有離線數據更新操作,因此每月在線獲取2萬微博用戶數據作為在線數據集,采集4個月共計8萬微博用戶約400萬條微博數據。每個月隨機選擇部分微博用戶數據進行類標注后,選出1400垃圾用戶與1400正常用戶作為相關檢測的驗證數據集。
(3)高級僵尸粉
其他渠道購買的高級粉絲數據共計5042名微博用戶約25萬條微博數據,這部分大多為高級僵尸粉,主要用于微博平臺檢測與本文提出微博垃圾用戶檢測系統之間比較。
3.3 離線檢測模型對比實驗
對離線檢測采用的兩種模型四種分類器的相關參數進行調整優化,經過相關特征處理后,進行訓練得到離線檢測分類器。不同檢測分類器的檢測效果結果如圖1所示。
通過結果可以發現集成模型檢測效果較好。而集成模型中,隨機森林與梯度提升決策樹檢測效率相當,但是隨機梯度提升決策樹模型訓練較為復雜,模型訓練收斂時間較長,與后續在線檢測所要求的高效準確原則相沖突。且隨機森林具有隨機選取數據可避免過擬合、對數據不平衡不敏感、數據噪聲與缺失值較多情況下仍然表現較好等優點,這樣隨機森林檢測分類器可以很好地克服在線檢測中一些新的微博用戶數據問題。本文后續在線檢測訓練使用隨機森林作為默認檢測分類器。
3.4 在線檢測實驗
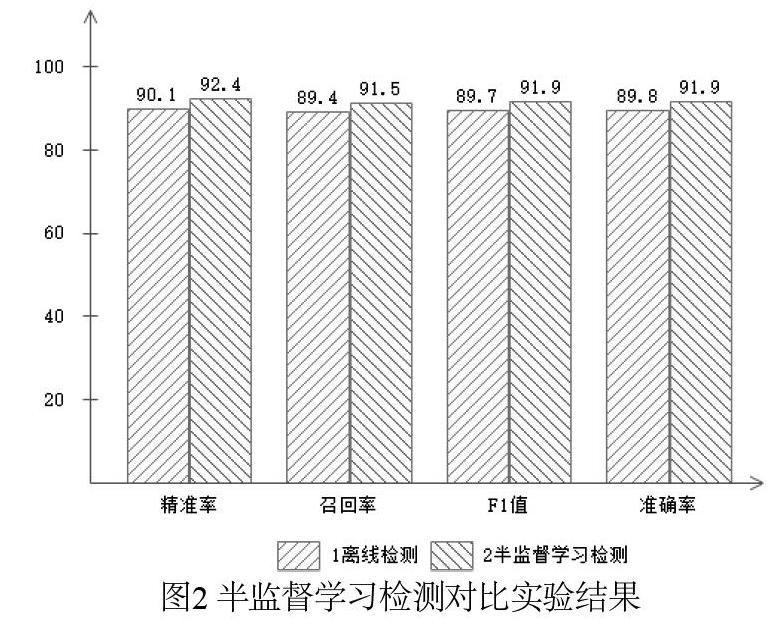
(1)半監督學習檢測與離線檢測對比試驗
實驗選擇全部初始數據集作為訓練集,選擇8月度進行類標記的微博數據作為測試集,采用離線檢測默認的隨機森林檢測分類器與半監督學習檢測分類器作比較,選擇F1值指標作為展示結果如圖2所示。可以發現半監督學習檢測的效果比離線檢測方法的檢測效果要好,這是因為半監督學習檢測方法引入了大量的未標注初始微博用戶數據集后為檢測分類器提供大量信息,使檢測分類器更趨于完善。
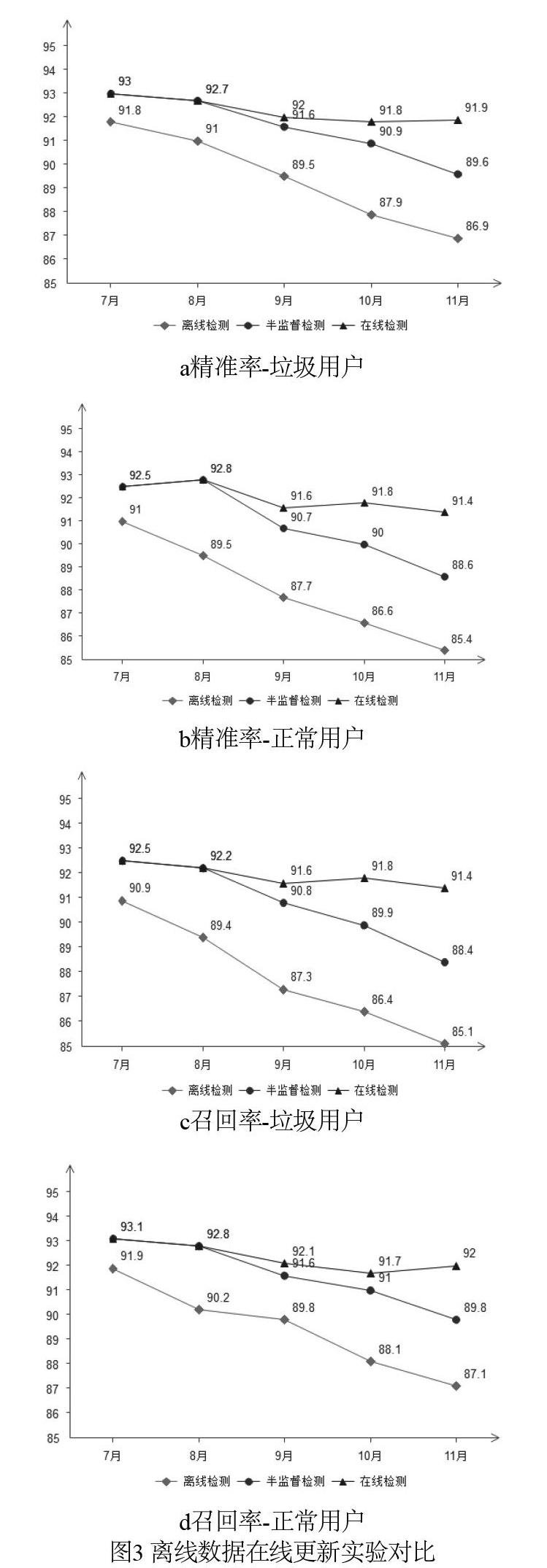
(2)離線數據更新機制實驗
本次實驗選擇四個月在線采集數據集中除去標注用戶數據外全部微博用戶數據作為訓練在線檢測訓練數據集,而每個月單獨標注的微博用戶數據作為測試數據集,采用離線檢測分類器、半監督學習檢測得到的初始檢測分類器與在線檢測分類器進行三種方法進行對比實驗,選擇垃圾用戶與正常用戶的精準率、召回率兩個指標進行展示,實驗結果如圖3所示。
通過實驗結果可以發現在線檢測分類模型的檢測效果比離線檢測與半監督學習檢測效果要好,而且隨著時間推移檢測分類性能基本維持在較高水平。反觀傳統檢測方法與半監督檢測方法均會出現隨著時間推移檢測性能下降的問題。
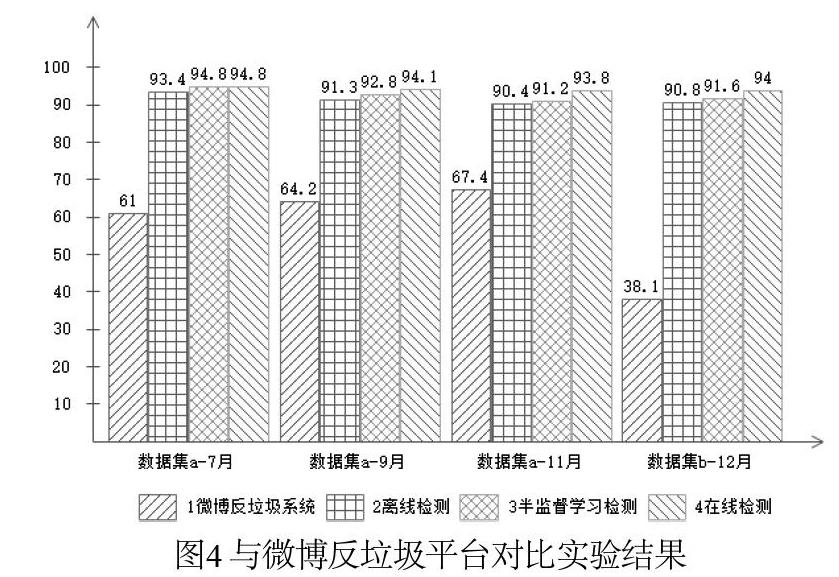
(3)與微博反垃圾平臺對比實驗
選擇四個月在線采集數據集除去標注用戶數據外全部微博用戶數據作為訓練在線檢測訓練數據集,選擇2018年5月購買的微博高級粉絲作為測試數據集a,2018年11月購買的微博高級粉絲作為測試數據集b,測試數據集a中的微博用戶經過每月兩次更新且同步更新至11月,如果期間被封禁則保留上月度數據。采用微博反垃圾系統檢測、離線檢測分類器、半監督檢測得到的初始檢測分類器、在線檢測分類器,對預測數據集a在7月、9月、11月三個月度的檢測情況與預測數據b在12月初檢測情況進行對比,結果如圖4所示。
可以發現,本文提出的微博垃圾用戶檢測系統有著較高的準確率,可以很好地檢測微博垃圾用戶,且在線檢測分類器檢測效果十分顯著,隨著時間推移其檢測效果依然可以維持較高水平,可以很好的適應數據的變化性。高級假粉絲這種垃圾用戶有著類似正常用戶轉發、發表微博、簽到等行為,因而微博反垃圾系統檢測效果不是很好,但是本文提出的微博垃圾用戶檢測系統可以很好地對之檢測。
4 結束語
本文針對微博用戶的特點,并對微博用戶數據做相關統計分析,建立了基于四大類統計型數值特征,然后采用機器學習分類方法訓練得到離線檢測分類器。為了解決時間的變化性,在其基礎上采用半監督學習檢測方法、主動學習檢測方法與離線數據更新機制三種方法構成的在線檢測方案進行微博垃圾用戶檢測,并達到了很好的檢測效果。
本系統雖然采用全面謹慎原則的類標簽判定方法,但是實際檢測中還是會出現將正常用戶判成垃圾用戶的情況,僅依靠機器學習檢測分類不能完全解決這個問題,因此可以再探索添加一個模型對垃圾用戶進一步處理,避免誤判。
基金項目:
1.國家重點研發計劃項目(項目編號:2017YFB0801701);
2.國家自然科學基金資助項目(項目編號:61572123);
3.遼寧省高校創新團隊支持計劃資助項目(項目編號:LT2016007);
4.賽爾網絡創新項目(項目編號:NGII20160616)。
參考文獻
[1] Liu Yuchen, Wang Wei . Privacy mining and emotional intelligence portrait in social networks[J]. Cyberspace Security, 2019, 10(2): 1-8.
[2] Yang Z, Xue J, Yang X, et al. VoteTrust: Leveraging Friend Invitation Graph to Defend against Social Network Sybils[J]. IEEE Transactions on Dependable & Secure Computing, 2016, 13(4):488-501.
[3] Gong N Z , Frank M , Mittal P . SybilBelief: A Semi-Supervised Learning Approach for Structure-Based Sybil Detection[J]. IEEE Transactions on Information Forensics & Security, 2017, 9(6):976-987.
[4] Hu X, Tang J, Liu H. Leveraging knowledge across media for spammer detection in microblogging[C]//Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval. ACM, 2014: 547-556.
[5] Cao J , Fu Q , Li Q , et al. Discovering hidden suspicious accounts in online social networks[J]. Information Sciences, 2017, 394-395(C):123-140.
[6] Fu Q, Feng B, Guo D, et al. Combating the evolving spammers in online social networks[J]. Computers & Security, 2018, 72: 60-73.
[7] Cao J, Li Q, Ji Y, et al. Detection of Forwarding-Based Malicious URLs in Online Social Networks[J]. International Journal of Parallel Programming, 2016, 44(1):163-180.
[8] 劉建偉,劉媛,羅雄麟.半監督學習方法[J].計算機學報, 2015(8):1592-1617.
作者簡介:
范雨萌(1997-),女,漢族,遼寧鞍山人,東北大學,碩士;主要研究方向和關注領域:大數據、分布式拒絕服務攻擊檢測。
易秀雙(1969-),男,漢族,內蒙古赤峰人,博士,東北大學教授;主要研究方向和關注領域:下一代互聯網、網絡安全及大數據分析。
倪石建(1994-),男,漢族,安徽人,東北大學,碩士;主要研究方向和關注領域:網絡安全和虛擬現實技術。
王興偉(1968-),男,漢族,遼寧蓋州人,東北大學,博士,教授,博士生導師;主要研究方向和關注領域:未來互聯網、云計算、網絡安全和信息安全。
