關聯規則算法在小數據挖掘中的技術研究
2019-04-08 00:46:32王金娟段珊彭浩徐紅
現代計算機 2019年6期
王金娟,段珊,彭浩,徐紅
(湖南涉外經濟學院,長沙410205)
0 引言
互聯網技術的迅猛發展已然將人類帶到“互聯網+新能源”為聚合推動力的又一次革命中,在這場革命的推動下,互聯網己經不再是一個簡單的獲取資源的工具,它更是一個以難以想象的速度發展成為與現實世界緊密融合的數據世界。
目前,大數據有很多種不同的定義。大數據先是從各行各業如證券金融、電子商務、搜索引擎等行業中產生的海量的每天數萬TB的數據[1],這些日益積累出的大數據仍然在不停地爆發式增長,后得出大數據既是數據量達到PB級甚至EB級的大規模數據。
“大”是大數據最直觀最重要的特征,且這些各個行業里產生的數據都緊密相連,如何獲取這些數據里的價值是必須也必然要做的長期課題,所以大數據更可以準確描述為:無法在可容忍的時間內用傳統方法和軟、硬件平臺對其進行感知、獲取、管理、處理和可視化的數據集合,它更涵蓋了數據及其采集、處理、分析、解釋等在內的一系列相關的技術[2]。這些技術包含數據采集,數據信息的抽取和清理,數據集成于分析,數據解釋與部署等內容[5],這些內容又涉及到數據存儲、數據安全、數據可視化、流計算、云計算、數據共享等多方面的技術集成,所以大數據的研究發展是現代信息產業技術的挑戰同時也是新的機遇,它的技術變革同時也會帶來科技與生活的不斷更替。
1 大數據與小數據
1.1 小數據概述
在當今這個大數據世界,其數據的價值最終要體現在,能更深層次的對人民的生產和生活帶來更好的支持,這就需要行業縮小與最終用戶的距離,隨著推薦系統領域的提出和發展,針對單個用戶的個性化推薦技術己經在新聞、閱讀、視頻、音樂等諸多領域大放異彩[7],如何獲取用戶相匹配的信息并推薦給用戶符合其興趣偏好的產品成為一項非常重要的課題,此時小數據的概念應運而生。
小數據是指以單個用戶為中心的全方位數據,包含數據被采集對象實時的身體狀況、社交習慣、財務、喜好、行為等一系列的數據信息[3]。通過分析小數據信息,可初步形成針對個人的數據系統,利用它能對個人的需求和行為進行預測,并給出相應的決策依據。小數據是基于概率論和數理統計的傳統統計思想,通過數據挖掘算法進行聚類,過濾,挖掘數據與用戶之間隱藏的關聯特征,并分析計算從而獲得的有限、固定、不連續、不可擴充的結構型數據[6],它更具有個人色彩,也更加符合現在社會要求提供個性化服務的技術要求。
1.2 大數據與小數據的關系
首先,大數據反映的是規律,小數據體現的是個性化。大數據的4V特征即量度(Volume)、異度(Variety)、速度(Velocity)和精度(Veracity)反映出的是海量數據的總體規律[2],為提高數據在采集、處理、存儲和分析過程的效率可控性,大數據要求數據信息的組織結構與類型必須標準化,要求數據覆蓋行業面廣、收集內容要多、要求具有普適性,能分析得出其變化的規律。而小數據是針對單個用戶的數據集合,技術的研究方向集中圍繞著個人的信息的數據采集存儲、分析與決策,它更具有針對性,是為了提供更具有個性化用戶服務的產品的一次產業深度細分,因此小數據和大數據是對平衡的共同追求,而小數據注重抽樣,是大數據技術的一個深度分支。
其次,小數據在安全方面比大數據有更高的要求。大數據都來源于很多不同的計算機平臺,只能收集到反映群體特征的數據,分析的規律一般是動態的、具有階段性數據特征的重復結果[8],而且會有大量的虛假干擾信息,信息價值密度低,安全性也不高。而小數據是以用戶個人為中心進行數據采集、決策分析對象,一定會涉及到包括用戶的個人生活環境、興趣愛好,所處的位置信息等多方面的隱私數據,因此如何通過更好的行業規范和技術手段來保護獲取到的用戶數據,是擺在面向小數據挖掘技術的一個重要課題。
2 關聯規則算法下小數據的挖掘技術研究
圍繞著用戶的小數據挖掘并以此為驅動設計出相應的產品,就必須以用戶的需求為中心,即基于用戶需求的數據挖掘過程是決策最為重要的影響因素,如何準確掌握用戶需求變化,提高數據信息采集的針對性并保障小數據的安全性[9],是在小數據挖掘的設計階段必須要重點關注的問題。
2.1 關聯規則
關聯規則挖掘是數據挖掘中的一個非常重要的課題,它的本質是從數據背后發現事物之間可能存在的關聯或者聯系。當海量數據經過采集、處理、分析、解釋后,將不同來源的數據進行整合,再利用數據分析工具進行快速處理,結果提供給決策人員作為依據以此來挖掘小數據。小數據包含個體特征數據、行為監控數據、第三方共享數據及外圍社會數據四個部分[10]。用戶個人的特征產生的數據是小數據的核心,包括用戶的基本信息數據、消費生活數據、相關的社會關系數據等多方面信息組成,它有較高的科學性、真實性、高價值密度和決策可用性;行為監控數據主要由傳感器網絡、服務器監控設備采集數據組成,主要實現對個體位置與移動路徑、社會關系等數據的采集與存儲;第三方共享數據,主要由通信運營商及其它第三方增值服務商共享數據組成,該數據全面但安全性較低[3];外圍社會數據是合約數據提供商提供的共享數據,它具有很大的挖掘潛能,是小數據挖掘非常重要的數據補充。
所以,小數據的挖掘應建立在以用戶個性化需求為前提,從以上四個方面分析采集數據集的置信度、支持度,推導出合適的頻繁項集,找出其中的關聯規則再進行判斷、分析并提供能保障安全可靠的數據過濾和處理技術之上,希望能進一步弄清用戶的真實需求。
2.2 關聯規則算法對于小數據驅動的研究
關聯規則算法是從數據項的事務集合中挖掘出,滿足支持度和置信度最低閾值要求的所有關聯規則,這個閾值是由用戶指定,它的數據挖掘過程分為兩個過程:先從事務集合中找出頻繁項目集,再從頻繁項目集合中生成滿足最低置信度的關聯規則。常用的關聯規則挖掘的算法有Apriori算法、FP-Growth算法、CBA算法等。本文采用最經典的Apriori算法討論關聯規則對于小數據挖掘的決策影響。
決策因素縱橫交錯,在已有的數據支持下,要做出相對好的決策就必須建立相關的算法去反映問題的實質。Apriori算法是常用的用于挖掘出數據關聯規則的算法,它采用頻繁項集的先驗性質來壓縮搜索空間,利用逐層搜索的迭代方法,找出數據值中頻繁出現的數據集合[11],找出這些集合的模式有助于做出更好的數據推薦。假設已經處理多個數據來源的數據并整合,得到用戶的數據預處理結果后得到圍繞著小數據的用戶模型如圖1所示,其中個體特征數據包含數據庫里記錄的基本信息數據、消費生活數據、相關的社會關系數據等數據,占用戶數據里比率最多;其次是行為監控數據包含用戶當前所在位置、瀏覽行為習慣、移動路徑等數據,在數據比率里占第二;而和通信服務商及增值服務商采集的用戶訪問過的網絡信息及流量監控等數據是共享數據在數據分布里占第三;而用戶與固定的一些接口程序或者例如百度、搜狗等這些合約數據提供商共享的數據是外圍數據,占比最少。針對小數據的特征,通過關聯算法找出頻繁數據集,給出支持度表,就可以提供參考推薦數據。表1是利用隨機數生成法,從某網站的訪問數據中,采集到圍繞著移動用戶具有代表性的四個特征數據的表格,表中的性別、年齡是個體的特征數據,可以從數據庫直接讀取。

圖1 用戶小數據分布模型圖
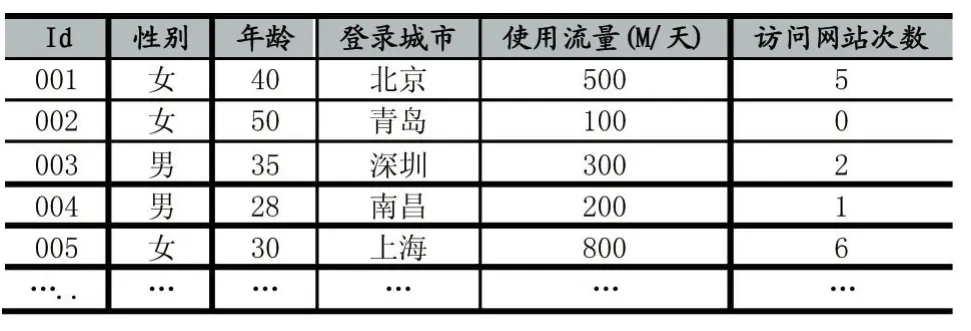
表1 用戶部分小數據表
針對大部分用戶注冊的性別數據不一定真實需要去掉噪聲,這里可以從用戶的行為屬性中逐步辨別。登錄城市是行為監控數據、用戶每天使用的流量是共享數據、訪問網站的次數屬于外圍數據。Apriori算法中的頻繁項集表示數據在一起出現的概率最大,先以支持度作為判斷頻繁項集的標準,再以數據的條件概率即置信度進行評估,以下列出算法步驟:
步驟1:生成單一個體數據頻繁項集列表,遍歷所有數據檢查生成的頻繁項集是否滿足最小支持度,對數據剪枝刪除不滿足支持度的項。
步驟2:使用組合方法,在當前個體數據頻繁項集中生成個體數據和行為監控數據的兩項數據頻繁項集,再檢查生成的頻繁項集是否滿足最小支持度,并刪除不滿足支持度的項。
步驟3:重復步驟2的過程,得到具有四個特征的頻繁項集。
步驟4:從步驟3生成的頻繁項集中挖掘關朕規則,判斷每條規則是否滿足置信度,不滿足則刪除,滿足則保留,生成的所有的規則按照其置信度進行排序[7],最后得到Apriori算法關聯挖掘的結果。
分析Apriori算法挖掘小數據后的結果,發現用戶的個體數據與外圍數據,共享數據均有較強的聯系,而共享數據與外圍數據同樣有很強的關聯性,可以解釋為具有某種個體屬性的用戶更傾向于訪問同樣的外圍數據,從而得到相同的共享數據。例如,在一線城市的女性更喜歡訪問提供服務相近的網站,同時消耗更多的流量,給增值服務商和網站運營商提供了更多的決策數據。
3 結語
和大數據挖掘相比,小數據挖掘圍繞用戶特征進行,具有更高的針對性和準確性,但是如何提高共享數據和外圍數據的安全性問題仍然亟待解決。關聯規則挖掘算法能從發現數據之間可能存在的關聯,但Apriori算法每輪迭代都要掃描數據集,在數據集很大,數據種類繁雜的時候,時空復雜度很高,算法效率太低,因此需要進一步研究能大幅度減少計算時間復雜度的關聯算法進行小數據挖掘,為用戶提供更好更高效的服務。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
