高光譜技術結合迭代決策樹的香腸菌落總數預測
2019-04-12 05:34:48郭培源董小棟許晶晶
食品科學 2019年6期
郭培源,徐 盼,董小棟,許晶晶
(北京工商大學計算機與信息工程學院,食品安全大數據技術北京市重點實驗室,北京 100048)
隨著人們生活水平的提高以及愈來愈多食品問題的發生,食品安全逐漸成為人們重點關注的問題,因而食品檢測的方法及其性能近年來成了研究熱點之一。香腸作為種類豐富且深受大家喜愛的食品,其檢測研究具有重要意義。受加工過程中不達標的衛生條件以及運輸貯藏過程中環境因素的影響,香腸品質會有所下降,而帶來很多安全問題和隱患[1]。評價香腸品質常用的指標是揮發性鹽基氮含量、蛋白質分解產生、過氧化值和酸價含量[1-2],以及亞硝酸鹽含量,少量的添加可給香腸上色且提供獨特的風味,過量使用,則會對身體造成危害。除此之外,香腸的菌落總數也是一項重要的評價指標,因為細菌會加速香腸的腐敗,從而給人體的健康帶來不利影響[3-4]。
香腸中菌落總數的測定,傳統是采用理化實驗的方法,即通過培養皿計數獲得,但是用理化實驗獲取香腸菌落總數周期長、耗試劑、操作繁瑣,且對樣品具有破壞性[5]。而近年來興起的高光譜成像技術是一種無損檢測技術,與理化實驗相比,它具有在線實時、對樣品無破壞性、準確便捷等優點,現已廣泛應用于食品檢測領域[6-7]。王莉等[8]采用波長范圍400~1 000 nm可見近紅外高光譜對冷鮮羊肉的菌落總數和揮發性鹽基氮含量進行新鮮度的檢測研究,其中,采用偏最小二乘回歸得到了最佳預測結果,建立的菌落總數和揮發性鹽基氮含量預測模型的校正集相關系數分別為0.906 7和0.914 7,預測集相關系數分別為0.874 3和0.880 2。劉善梅等[9]采用高光譜成像技術對生鮮豬肉的含水率進行無損檢測,建立偏最小二乘回歸預測模型,交叉驗證和預測相關系數分別為0.926和0.924,均方根誤差(root mean square error,RMSE)分別為0.467%和0.438%。張雷蕾等[10]在470~1 000 nm波長范圍內,從高光譜圖像中提取反射光譜,對光譜進行多元散射校正(multiplicative scatter correction,MSC)處理,并采用偏最小二乘建模分析,實現對豬肉的新鮮度評價。Jin Huali等[11]利用偏最小二乘方法分別在400~1 000 nm全波段上和1 000~2 500 nm中選取的6 個特征波長上進行建模預測花生油中的成分含量,兩種方法的效果都很好,但是后者的效果優于前者。Xiong Zhenjie等[12]采用偏最小二乘-連續投影算法的方法實現了紅肉中色素含量的定量檢測,并采用圖像處理的方法將色素在紅肉中的分布進行可視化研究。
雖然高光譜成像技術已廣泛應用于食品檢測領域,但利用高光譜技術檢測香腸內化學物質的含量以及對香腸進行分級的相關研究與應用非常少。本實驗采用400~1 000 nm高光譜儀采集香腸的高光譜數據,并分別采用迭代決策樹(gradient boosting decision tree,GBDT)和支持向量回歸(support vector regression,SVR)方法建立香腸菌落總數的預測模型,以期為香腸菌落總數的快速定量和品質控制提供參考。
1 材料與方法
1.1 材料與儀器
廣式香腸,購于北京永輝超市,將香腸切塊,每塊香腸厚2 cm,獲取50 份樣品,其中每份樣品有200 g,每天取一份樣本,將樣品平放于電移臺上,采用“推掃式”成像的方法獲取香腸的光譜值,然后進行菌落數測定。
肉制品光譜檢測儀購自北京卓立漢光公司,波段范圍400~1 000 nm,采樣分辨率5 nm,共有128 個波段。高光譜成像系統硬件由裝有圖像采集卡的計算機、CCD相機、成像光譜儀、光源等系統組成。
1.2 高光譜檢測原理
高光譜成像技術既可以獲取含有物質內外理化信息的光譜值,同時也能通過成像設備獲取樣品各個波段的圖像數據,這種圖譜合一的三維數據稱為“數據立方體”[13],如圖1所示。其中,圖像代表兩維的空間維度,而波長代表一維的光譜維度。“數據立方體”中每個波段可獲取一幅二維圖像,樣品的每個像素可以獲取一條光譜曲線[14-15]。圖像信息能夠全面反映物體的外在特征,而光譜信息則能夠反映物體的內在物理結構和化學成分等信息[16]。
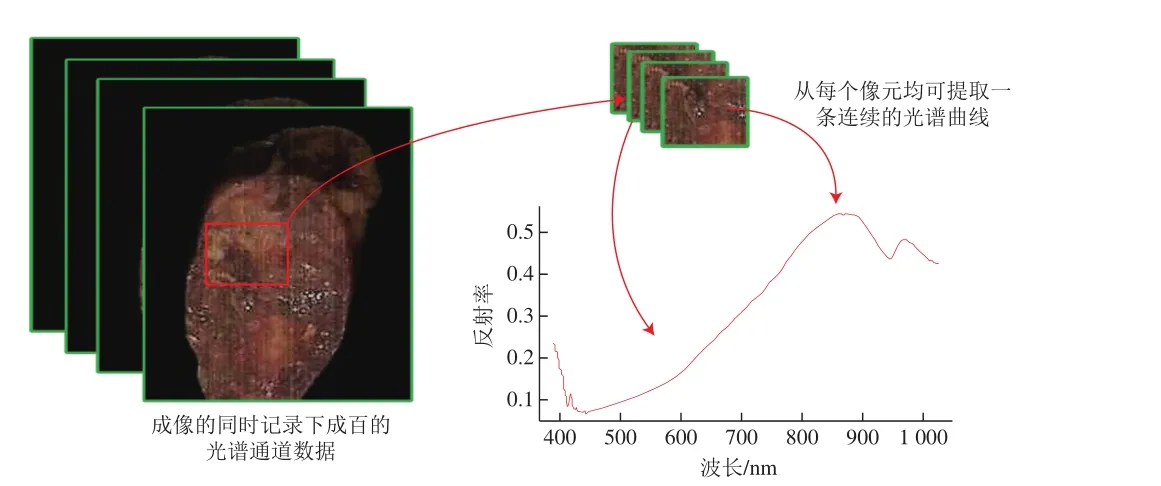
圖1 高光譜成像技術檢測原理Fig. 1 Detection principle of hyperspectral imaging technology
1.3 方法
1.3.1 高光譜數據采集
由于高光譜圖像采集系統獲得的原始高光譜圖像在各個波段范圍內的光源強度、光源亮度分布不均勻,并且暗電流和噪聲等因素會對光譜信息產生影響[17],因而需要對采集到的高光譜圖像進行黑白板校正處理[18],得到樣品的光譜反射值,具體如式(1)所示:

式中:R為校正后圖像;IR為原始圖像;ID為黑板校正圖像;Iw為白板校正圖像。
使用高光譜分析處理軟件ENVI5.1,在每個樣本的高光譜圖像上選取感興趣區域(region of interest,ROI),對ROI采用N維可視化工具獲取平均光譜曲線[19],如圖2所示。對50 個樣本中每個樣本選取10 個ROI,共得到500 個光譜數據。
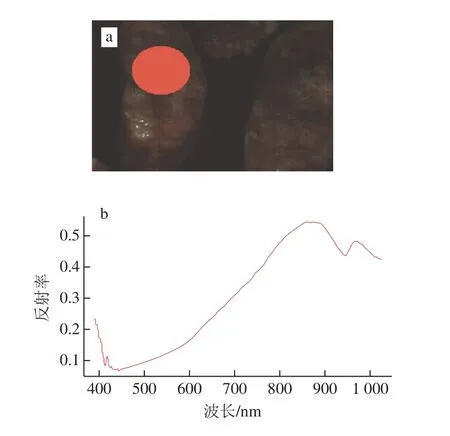
圖2 香腸樣本的ROI(a)及其平均光譜曲線(b)Fig. 2 Region of interest in sausage samples (a) and its average spectral curve (b)
1.3.2 光譜預處理
在采樣過程中,由于樣品的不均勻性、高頻隨機噪聲、基線漂移、光散射等因素會對建模效果產生負面影響[20],所以為了減少或消除此類因素的影響,需對采集的原始高光譜數據進行不同的預處理,本研究采用MSC的預處理方法。MSC是高光譜建模最常用的預處理方法,分析結果較好[21]。它可以有效地消除樣品顆粒分布不均勻或者樣品大小不同等情況造成的散射誤差。
首先計算樣品得到的所有高光譜的平均光譜,將得到的平均光譜作為基準光譜。每個光譜與基準光譜進行一元線性回歸運算,求得各光譜相對于基準光譜的線性平移量(回歸常數)和傾斜偏移量(回歸系數)。在每個原始光譜中減去回歸常數且除以回歸系數后,每個光譜的基線平移和偏移都得到了修正,而樣品成分含量對應的光譜信息在數據處理的過程中沒有受到影響,進而提高原始光譜的信噪比。平均光譜、回歸方程和MSC運算的算法過程如(2)~(4):

式中:Ai,j為香腸樣品的平均光譜曲線;Ai(MSC)為經多元散射校正后的光譜;A為n×p維定標光譜數據矩陣;n為光譜數量;p為波長點數;A為原始光譜的平均矢量;Ai為1×p維矩陣,表示每個光譜矢量;mi為Ai與A線性回歸得到的相對偏移系數,Bi為Ai與A線性回歸獲得的平移量。
1.3.3 主成分分析
高光譜數據的數據量較為龐大,且相鄰波段的圖像相互重疊,具有很大的關聯性,因此高光譜數據降維處理的效果將影響后續的建模效果[22],而主成分分析(principal component analysis,PCA)在數據降維方面具有獨特的優勢,所得的主成分分量之間相互獨立,可以有效地消除高光譜數據中的冗余信息[23]。一般情況下,PC1包含波段中80%的方差信息,前3 個主成分包含了所有波段中90%以上的信息量[24]。本實驗對光譜的128 個波段進行PCA,選取前5 個主成分建立模型,這5 個主成分的方差累計貢獻率達到95%以上。
1.3.4 SVR
SVR是將復雜實際問題通過非線性變換轉換到高維特征空間,在高維空間中構造線性決策函數來實現原空間中的非線性決策[24-27]。它是找到一個超平面,使到超平面最遠的樣本點的“距離”最小。本研究選用SVR方法實現香腸菌落總數的預測,所用的高斯核函數[28]如式(5)所示:
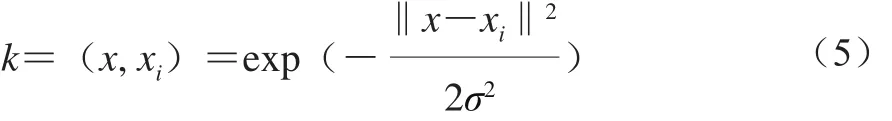
式中:σ為核函數的寬度參數;x、xi分別為超平面最遠的樣本點及中心點。
高斯核函數對數據中存在的噪聲有著較好的抗干擾能力,由于其具有很強的局部性,其參數決定了函數作用范圍,隨著參數σ的增大而減弱。
SVR高斯核函數的c和g參數,常用粒子群(particle swarm optimization,PSO)算法、網格搜索、遺傳算法(genetic algorithm,GA)3 種方法進行尋優。其中,c為懲罰系數,即對誤差的寬容度。c越高,說明越不能容忍出現誤差,容易出現過擬合;c越小,容易欠擬合。c過大或過小,泛化能力都差。g為選擇高斯核函數后自帶的一個參數,隱含地決定了數據映射到新的特征空間后的分布。g越大,支持向量越少;g越小,支持向量越多,支持向量的個數影響訓練與預測的速度。
1.3.5 迭代決策樹
迭代決策樹(gradient boosting decision tree,GBDT)作為回歸樹的一種,相對于一般決策樹算法具有防止過擬合、泛化能力較強等優點。模型訓練的時候,對于輸入的一個樣本,首先會賦予一個初值,然后會遍歷每一棵決策樹,每棵樹都會對預測值進行調整修正,每一次迭代是為了改進上一次結果,減少上一次模型的殘差,并且在殘差減少的梯度方向上建立新的組合模型[29]。其基本思想是通過構建M個弱分類器,經過多次迭代最終組合而成一個強分類器。
GBDT又被稱為提升樹,其可以表示為決策樹的加法模型:

式中:T(xi,θm)為決策樹;θm為決策樹的參數;M為樹的個數。
針對不同問題的GBDT,其主要區別在于使用的損失函數不同,包括用平方誤差損失函數的回歸問題,用指數損失函數的分類問題,以及用一般損失函數的一般決策問題。本研究使用平方誤差損失函數實現回歸。
提升樹的訓練流程如下:
輸入:訓練數據集T={(x1,y2), (x2,y2), …, (xN,輸出:提升樹fM(x)。
1)初始化f0(x)=0;2)對m=1, 2, …,M;a)按式(6)計算殘差rmi=yi-fm-1(xi),i=1, 2, …,N;b)擬合殘差rmi學習一個回歸樹,得到T(x,θm);c)更新fm(x)=fm-1(x)+T(x,θm);3)得到回歸問題提升
1.3.6 模型評價指標
1.3.6.1 RMSE
RMSE是觀測值與真值偏差的平方和與觀測次數n比值的平方根,它能很好地反映測量的精密度,RMSE越小,模型的預測效果越好。具體如式(7)所示:
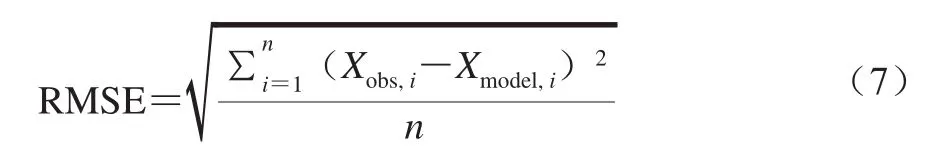
式中:Xobs,i為觀測值;Xmodei,i為真實值。
1.3.6.2 決定系數R2
決定系數用于判斷回歸方程的擬合程度,R2越接近1,模型的預測效果越好。具體如式(8)所示:

式中:yi為真實值;y為均值;為估計值。
1.4 數據處理
實驗采用10折交叉驗證的方法對原始數據進行處理,即每次用9 個子集的并集作為訓練集,余下的1 個子集作為測試集,這樣總共獲得10 組訓練/測試集,從而進行10 組訓練和測試,最終訓練與測試的結果返回的是10 組的均值。因而本實驗中每次有450 個香腸光譜樣本作為訓練集,50 個作為測試集。對經MSC預處理和PCA降維處理后的光譜分別采用SVR和GBDT方法建立香腸菌落總數的預測模型,并驗證模型的預測效果。采用RMSE和R2作為評價模型預測效果的指標,獲得了較好的實驗結果,其訓練集和測試集均方根誤差分別為0.001和0.003,決定系數R2分別為0.998和0.996。
2 結果與分析
2.1 光譜預處理的結果
原始光譜以及經MSC后的光譜圖如圖3所示。
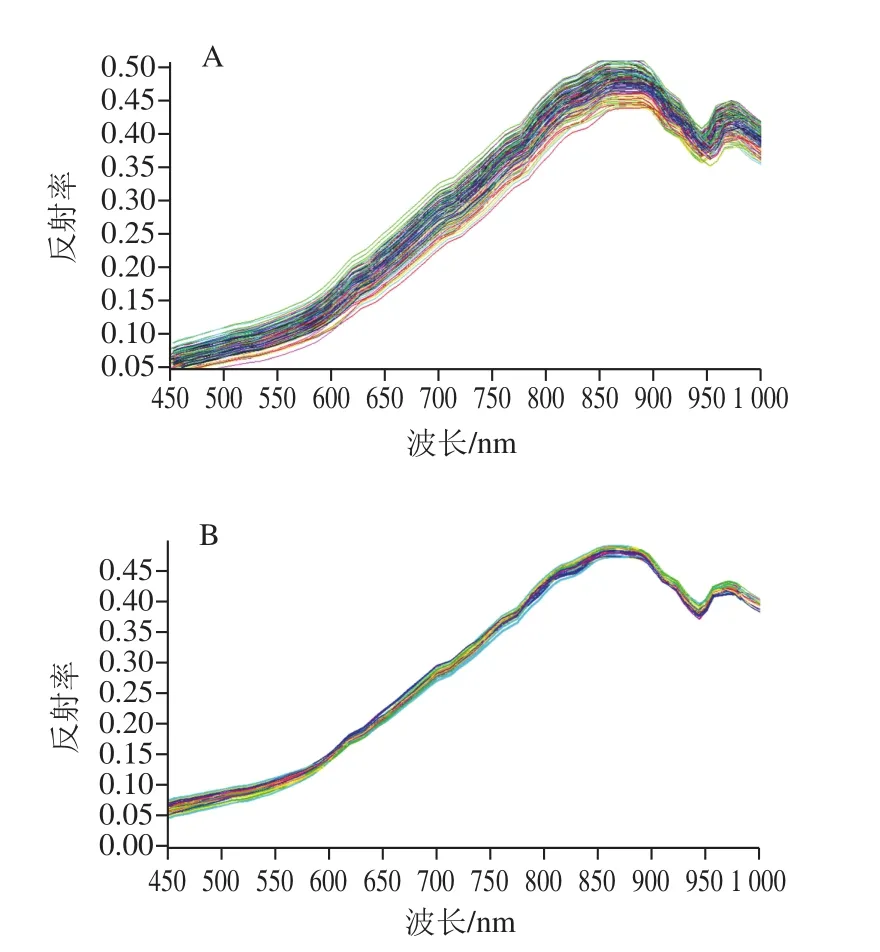
圖3 原始(A)和經MSC預處理后(B)的光譜圖Fig. 3 Original spectra (A) and spectra preprocessed by MSC (B)
2.2 SVR建模結果
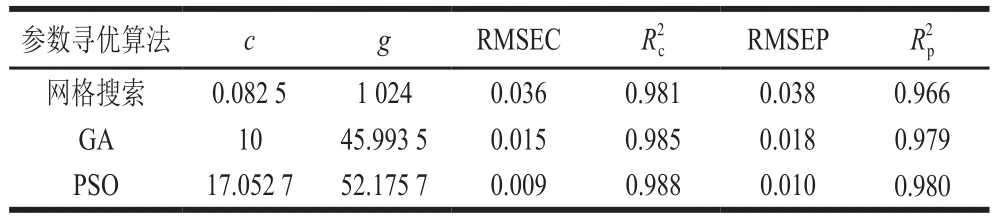
表1 不同參數尋優算法對應的SVR建模結果Table 1 Modeling results of SVR with different parameter optimization algorithms
3 種尋優算法得到的最優c和g參數及其對應模型的預測結果如表1所示。SVR方法采用PSO算法進行c和g參數尋優得到的預測模型最優。PSO算法的收斂速度快,受問題維數的變化影響較小,使得求解過程更容易計算[30]。采用PSO算法進行c和g參數尋優的SVR方法對香腸光譜訓練集和測試集樣本的菌落總數預測結果如圖4所示。
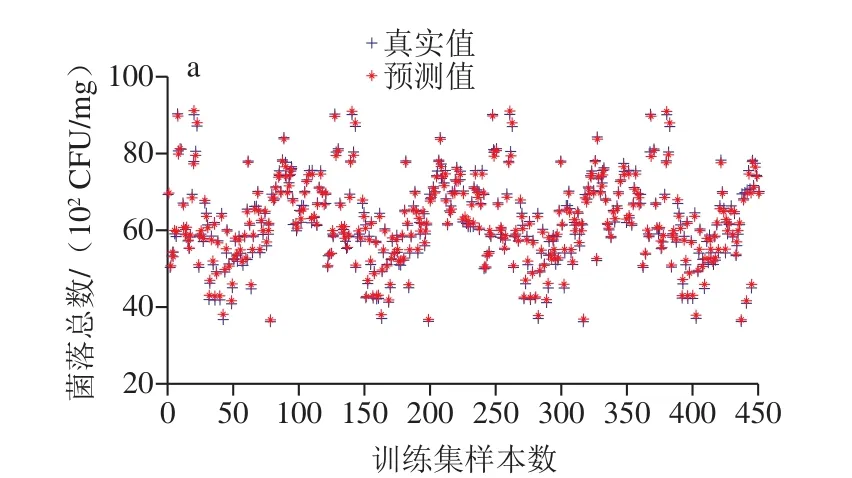
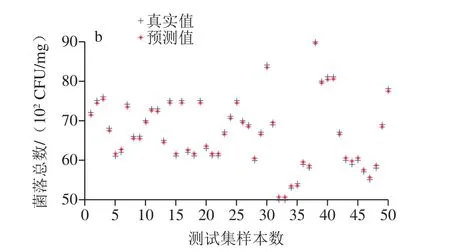
圖4 SVR模型的訓練集(a)與測試集(b)的預測結果Fig. 4 Prediction results of training (a) and test (b) sets with SVR model
2.3 GBDT建模結果
迭代1 000、1 500 次和2 000 次的GBDT建模結果如表2所示。迭代2 000 次得到的建模結果最好,并且迭代過程很快。迭代2 000 次的GBDT方法對香腸光譜樣本的訓練和測試結果如圖5所示。
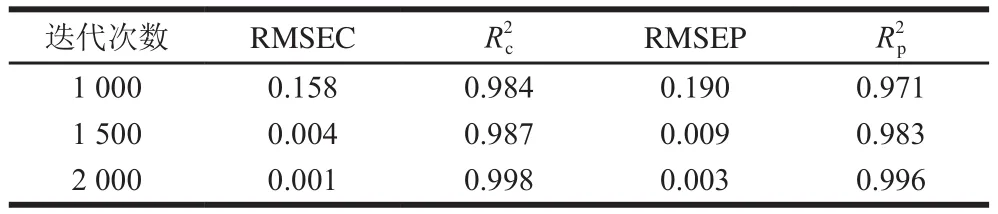
表2 不同迭代次數的GBDT建模結果Table 2 Modeling results of GBDT with different iterations
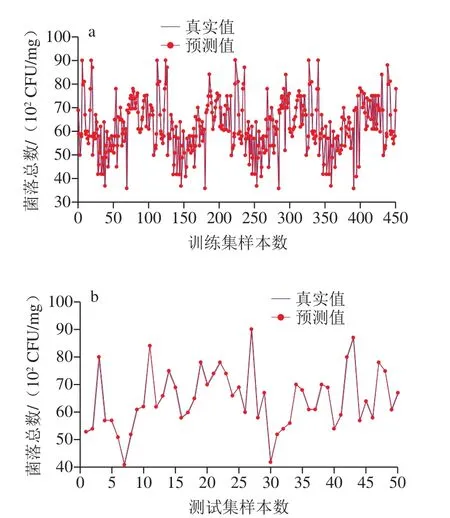
圖5 GBDT模型的訓練集(a)與測試集(b)的預測結果Fig. 5 Prediction results of training (a) and test (b) sets with GBDT model
2.4 兩種方法建模結果的比較
由SVR和GBDT的建模結果,比較采用PSO算法進行參數尋優的SVR建模結果與迭代2 000 次的GBDT建模結果可知,GBDT建模結果要遠優于SVR的,GBDT所得的RMSE非常小,比SVR所得的要小一個數量級,并且GBDT所得的R2幾乎為1。除此之外,SVR建模所需的訓練時間很長,GBDT訓練時間則很短。因而基于高光譜成像技術利用GBDT方法預測香腸菌落總數的方法可行且有效。
3 結 論
本實驗通過高光譜成像系統采集50 個香腸樣本的高光譜數據,并利用高光譜分析處理軟件ENVI5.1,在每個香腸樣本的高光譜圖像中選擇10 個ROI,從而獲得500 個香腸樣本的平均光譜數據。實驗采用MSC方法對光譜預處理,并采用PCA方法從128 個光譜波段中選擇5 個特征波段,從而提高了模型的預測精度。以處理過的光譜數據作為輸入,理化實驗所得的香腸菌落總數值作為輸出,分別采用SVR和GBDT方法建立香腸菌落總數的預測模型。實驗結果可知,迭代2 000 次的GBDT建模結果最優。本實驗中,GBDT模型迭代2 000 次時,訓練集和測試集的RMSE都很小,R2也都接近1,但是當迭代次數多于2 000 次時,是否會產生過擬合、建模效果需要進一步論證。除此之外,進一步需要探索研究地是,將每個像素點下預測出的菌落總數定量反演到香腸樣本表面圖像上,生成可視化分布圖,使香腸新鮮度的動態變化趨勢更加直觀、形象地呈現。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
