基于深度強化學習的無人駕駛智能決策控制研究
2019-04-17 09:00:34朱武哲
贏未來 2019年11期
朱武哲

摘 要:隨著人工智能技術的發展,越來越多的智能應用正在潛移默化地改變我們的生活。普及無人駕駛車輛是未來交通的發展方向,決策控制問題則是無人駕駛技術發展需要面對的重要問題。本文針對無人駕駛決策控制問題,提出將示教學習與強化學習相結合的解決方案,嘗試吸取示教學習算法的優點,對強化學習算法訓練效果進行提升。基于深度確定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG),本文提出了融合示教的 DDPG 算法(DDPG with Demonstration, DDPGwD),并使用了開源微軟仿真環境對算法進行了仿真驗證,證明了上述算法在自動駕駛決策控制中的有效性。
關鍵詞:無人駕駛智能決策;深度確定性策略梯度算法;示教學習;強化學習
一 引言
隨著自動駕駛技術的不斷突破,無人駕駛車輛的生產已經向實用化邁進,在未來數年內將對提高道路安全、促進交通管理和改善城市環保等產生顛覆性影響。據統計,在所有車輛肇事情況中,九成以上的車禍是由駕駛員的失誤造成的。因此,無人駕駛功能的出現,有可能大幅降低交通肇事案件的數量。我國對于無人駕駛的研究起步較早,但是隨著對自動駕駛應變能力要求的不斷提高,新一代的無人駕駛車輛既需要對復雜的道路場景進行識別與分析,又需要克服不同環境下的傳感器噪聲等問題,同時還需要實時應對各種突發狀況,這對自動駕駛人工智能的快速學習能力、泛化能力提出了更高的要求,成為急需攻克的難點問題。當前,制約無人駕駛技術應用的一個關鍵問題是如何保證車輛在不可控復雜環境中長時間安全自主行駛。在不可控復雜交通環境中,道路情況復雜(包括道路標志缺失、被遮擋、表面破損,行人及車輛共存等),道路周圍環境多變(包括天氣、光照和氣候多變,城市部分片區改造或重新規劃等)。在不可控環境中要求無人駕駛車輛具有更加智能的決策控制能力,能夠綜合利用感知信息,在緊急突發情況下做出安全合理的決策控制。以示教學習(Imitation Learning)為代表的一系列通過人類示教來引導機器進行學習的智能方法,已經在機器人與智能控制領域取得了很大的成就。但是,如何將人類的經驗用于汽車自動駕駛人工智能的訓練,尤其是在示教樣本較少的情況下,如何應付不可控復雜交通場景、如何提高泛化能力,都是無人駕駛研究的難點。無人駕駛的決策與控制模塊是決定無人駕駛汽車安全性、穩定性的關鍵。圖1展示了谷歌無人車和特斯拉自動駕駛模式下發生的事故。會發生這些事故,主要原因是面對不可控的突發交通狀況時,無人車無法做出最佳的實時決策與控制。因此,不可控復雜環境中的無人駕駛的決策和控制,逐漸成為制約無人駕駛技術發展的關鍵問題。
二 國內外研究現狀
強化學習是一種再激勵學習算法,和上述的監督學習方法不同,它通過和環境交互試錯進行在線的學習,獲取反饋,從而優化策略,不依賴環境模型和先驗知識。近年來很多學者將強化學習用于無人車路徑規劃上面。Liwei Huang等在動態環境下基于強化學習進行車輛的路徑規劃和避障,將狀態空間分為八個角度區間,動作域分為三向前、左轉和右轉三個動作,并加入ε-貪婪策略改進了獎勵函數,實現了無人小車導航,但是該方法未考慮后退動作,難以解決若前方堵死時車輛如何選擇動作的問題,還有避讓的路線是折線,并不是光滑的,與現實車輛行駛路線不符;董培方等加入初始引力勢場和陷阱搜索的改進Q-learning算法,在其基礎上對環境進行陷阱區域逐層搜索,剔除凹形陷阱區域Q值迭代,加快了路徑規劃的收斂速度,搜索到較好的路徑,但是其收斂速度還有待提高,規劃的路徑也可能不是最優的;張明雨利用代價地圖的cost信息來構建狀態空間,動作空間,獎賞函數和值函數,然后對移動機器人進行訓練,獲得Q值表,然后在后面的導航過程中遇到障礙物時,用學習到的策略選擇動作,避過障礙物,使用代價地圖結合Q-learning算法來修改全局路徑實現機器人的動態導航;張汕播等針對未知環境,利用情感學習機制輔助強化學習系統,給出算法在當時環境下的決策空間,實現agent的實時決策,最后將強化學習模型和A*算法結合構建路徑規劃系統。
現在大部分的無人駕駛車輛都是在無人區域或者簡單的道路環境下行駛的,但是現實的路況都是實時變化的,障礙物分布隨機且多,我們希望在復雜動態環境下無人車輛能自主搜索出合適的路徑并自主避讓障礙物。
三 DDPGwD 算法框架
本文采用組合運動規劃方法進行無人車的行為規劃。運動規劃的組合方法通過連續的配置空間找到路徑,而無需借助近似值。組合方法通過對規劃問題建立離散表示來找到完整的解,首先使用路徑規劃器生成備選的路徑和目標點(這些路徑和目標點是融合動力學可達的),然后通過優化算法選擇最優的路徑。
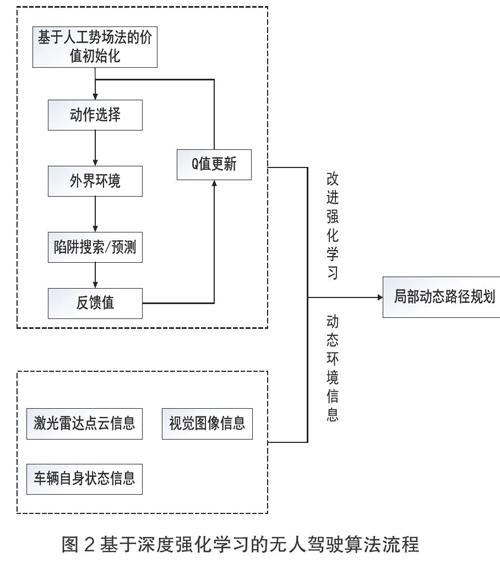
在大規模學習時強化學習普遍有收斂速度慢、規劃效率低的缺點,對于無人車輛來說,其“試錯”機制可能會使車輛撞擊到障礙物,不能直接應用于真實環境中。針對上述問題,擬加入人工勢場法對環境的勢能進行賦值作為搜索啟發信息對Q值進行初始化,從而在學習初期便能引導移動機器人快速收斂,提高規劃效率,使用攝像機、激光雷達等識別周圍環境,結合強化學習進行動態的路徑規劃,流程圖如下:
利用強化學習解決機器人路徑規劃問題時,機器人會在相應的環境中“試錯”學習,在執行動作的同時會得到相應的獎勵,考慮動作選擇和回報的馬爾科夫過程稱為馬爾科夫決策過程。強化學習的各種方法都是以馬爾科夫決策過程(MDP)為基礎的。
S:表示系統環境狀態的集合;
A:表示Agent可采取的動作集合;
P(s|s,a)描述在當前狀態s∈S下,Agent采取動作a∈A,轉移到s∈S的概率;
R(s,a)表示在狀態s下Agent執行動作a后獲得的獎賞值;
目標就是求出累計獎勵最大的策略的期望。
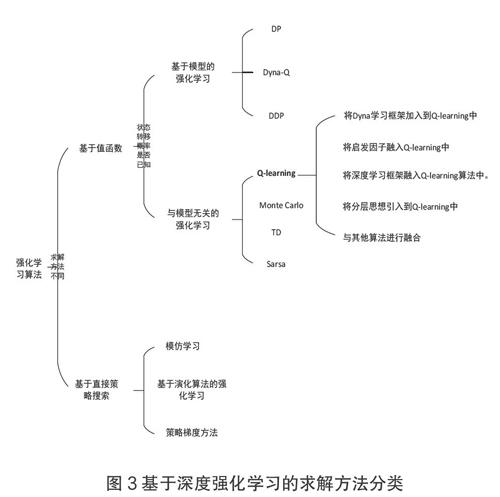
根據求解方法不同,強化學習的算法主要分為兩大類:基于值的算法(Value-Based)和基于策略的算法(Policy-Based)。
四 試驗驗證
(一)環境因素分析
外界環境因素作為無人駕駛車輛的主要信息輸入,對無人駕駛過程中的環境感知、系統決策,路徑規劃和系統控制都有十分重要的影響。外界環境因素本身也是一個龐大而且復雜的系統,從廣義上講,外界環境因素主要包括靜態環境因素和動態環境因素。其中靜態的環境因素有不同類型的道路和交通標志、道路上和兩邊的場景以及靜態障礙物等;動態的環境因素有車輛、行人、交通信號燈以及動態障礙物等。
1.結構化道路
影響無人駕駛車輛的主要靜態環境因素是道路和靜態障礙物,道路兩旁的建筑和場景對于車輛路徑規劃的影響較小,故本文不做討論。其中道路又分為結構化道路和非結構化道路兩種,在結構化道路中又有直道、彎道、十字路口、Y型路口、環島、主干道的出口和入口以及這些要素的組合道路等,對于非結構化道路本文不做討論。
①直道,作為結構化道路中最簡單的組成元素,是結構化道路主要的存在形式,大多數的道路都是以盡量直道的原則建造。直道又分為單車道和多車道,直道的邊界都是直線,主要的參數是道路的長度、寬度和邊界位置等信息。車輛在直道上行駛的方式較為固定,一般是直行、換道行駛,同時采取一些避障行為。
②彎道,通常作為道路的連接,彎道也是典型路況中的典型組成元素。由于其特殊性,彎道是交通事故的多發地。所以在做無人駕駛車輛的局部路徑規劃時,要著重考慮車輛在彎道的曲率值下的行駛能力。車輛在彎道上行駛的類型一般是沿著彎道作轉向行駛。
③匯入和匯出道路,兩條或者多條道路的合并形成匯入道路。單條道路分成多條道路形成匯出道路。車輛在匯入匯出道路上,一般會進行變道和避障行駛。
④十字路口,兩條或者多條道路相會產生十字路口,無人駕駛車輛的路徑規劃主要考慮來往車輛和行人。車輛在十字路口上,一般有轉向、調頭和直行等行駛方式。
⑤U型路,U型路通常是曲率比較大的彎道,有可能出現在雙向直道上需要調頭的位置。和彎道相類似,車輛在U型路上,一般是沿著U型路作調頭行駛,和彎道不同時是,轉向角度更大,目標點一般在身后。
2.行人
行人在道路上行走一般具有很大的隨意性,是道路交通上的不確定因素,同時由于行人缺少相應保護,往往在發生交通事故時會受到較大的傷害。行人在道路上行走一般可以分為兩類,一類是沿著道路行走,另一類是橫穿道路行走。由于行人具有隨意性,無人駕駛車輛如何檢測和避讓行人是研究的重點和難點之一。
為了驗證DDPGwD最終訓練得到的模型泛化性,我們在微軟開源仿真平臺測試軌道中進行了測試,軌道形狀及場景如下圖所示,無人車能夠順利地完成整圈的駕駛。
綜合上述仿真實驗,我們提出的DDPGwD算法能夠合理地解決無人駕駛的決策控制問題,并且通過引入示教監督數據,能夠在相同的獎勵值函數下、在一定量的訓練回合中獲得比原始DDPG算法更多的訓練步數,可以更快地學到一個相對合理的策略。在弱化獎勵值函數后,我們提出的算法效果雖有所下降,但相較于DDPG算法仍然能夠維持在一個較高的訓練水平。
五 結語
本文介紹了基本深度強化算法原理,分析了DDPGwD算法作為無人駕駛車輛局部路徑規劃與決策算法的優缺點。針對無人駕駛車輛使用DDPG算法進行局部路徑規劃的缺點,提出了基于場景約束的DDPGwD規劃方法,在此基礎上設計了基于示教學習與深度強化學習融合的路徑節點修剪與優化方法,最后結合整車轉向控制模型對路徑進行了進一步的優化。
