對2018年前三季度我國各地區社會服務水平評價
2019-04-29 06:23:26
福建質量管理 2019年9期
關鍵詞:服務
(東北大學秦皇島分校 河北 秦皇島 066000)
一、緒論
(一)研究背景
近年來,隨著我國經濟的持續增長,國家對改善民生越來越重視,因此我國的社會服務水平得到很大的提高。然而隨著社會服務需求的日益增長,我國的社會服務已經不能適應人們日益增長社會服務需求。我國社會服務發展的“短板”愈來愈明顯。因此,建立有效的社會服務指標體系,對我國各地區社會服務情況進行分析,找出社會服務建設較弱的地區進行有針對性地完善提高已經成為迫切需要。
(二)數據來源和指標確定
本文數據源自于中國民政部官網的2018年度各地區社會服務情況統計表。根據我國國家基本公共服務體系中涉及的社會服務內容確定指標體系,通過查詢數據剔除一些數據缺省的指標,根據國務院2017年公布的《“十三五”推進基本公共服務均等化規劃》[1]對基本社會服務的定義,選取了具有代表性的9項指標:民政事業費累計支出(萬元)、社會服務機構數(個)、孤兒數(人)、城市低保人數(人)、農村低保人數(人)、臨時救助人次數(人)、結婚登記(對)、離婚登記(對)、火化遺體數(個)。
二、聚類分析
(一)聚類分析模型
類平均法是一種使用比較廣泛、聚類效果比較好的系統聚類方法。本文使用SAS軟件調用CLUSTER過程來對各地區進行聚類分析。
通過反映社會服務水平的各項指標對不同地區進行聚類,使用類平均法聚類得到樹狀圖及聚類歷史圖如圖2.1所示。

圖2.1 類平均聚類法的譜系聚類圖
樹狀圖2.1展現了聚類分析中每一次合并的情況,橫軸代表個案樣本間的距離,縱軸代表的31個樣本,即31個省市。
從聚類歷史中我們可以確定31個樣本分為幾類比較合適。首先指定類數NCL6,然后綜合R2統計量、半偏R2統計量、偽F統計量、偽t2統計量分析,最終確定分為兩類或四類比較合適。
分為兩類的結果:

分為四類的結果:


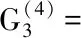

(二)聚類結果分析
不同的聚類方法得到的結果或多或少都有些差別,在實際應用中應綜合各種計算結果,所以我們可以計算出各類地區社會服務平均水平(見表2。1)。由表2。1可見第一類地區民政事業費支出、社會服務機構數等社會服務水平正向指標均較高,說明這些地區服務水平較高,第二類的地區社會服務水平其次,但是孤兒數和低保人數較多,說明雖然社會服務支出高但是社會弱勢群體數也較多,第三類社會服務水平居中,第四類地區社會服務水平在全國看來還較低,要提升這些省市的社會服務,要從多方面入手。
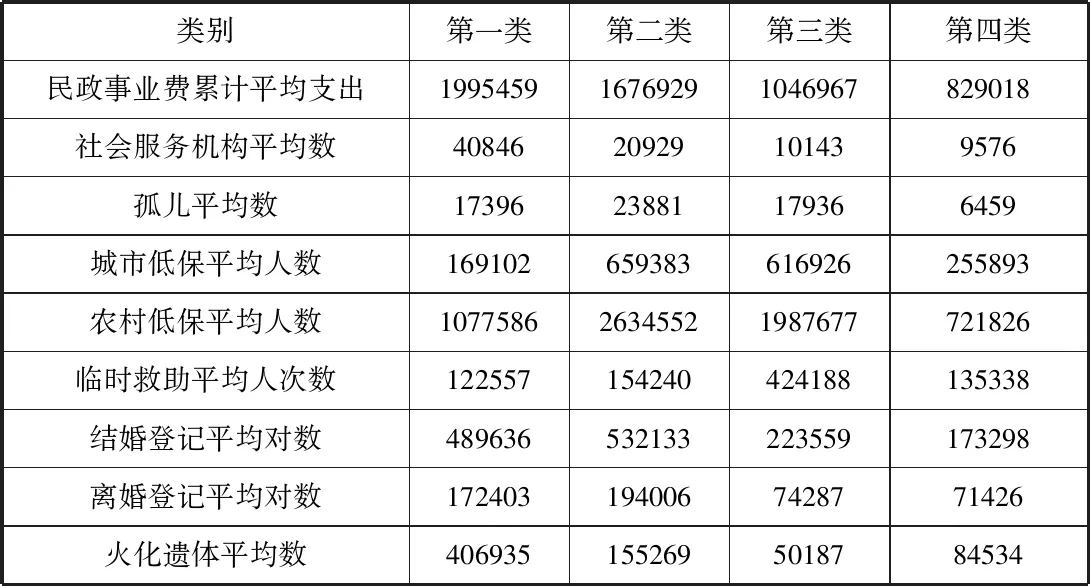
表2.1 各地區的分類及社會服務平均水平
三、主成分分析
設法將原來變量重新組合成一組新的互相無關的幾個綜合變量,同時根據實際需要從中可以取出幾個較少的綜合變量盡可能多地反映原來變量的信息的統計方法叫做主成分分析或稱主分量分析,也是數學上用來降維的一種方法[3],
把31個地區作為樣本,將民政事業費累計支出(Xl),社會服務機構數(X2), 孤兒數(X3),城市低保人數(X4),農村低保人數(X5),臨時救助人次數(X6),結婚登記數(X7),離婚登記數(X8),火化遺體數(X9)作為變量。為消除量綱影響,在SAS代碼中對數據進行標準化。
本問題中,p=9,n=31,調用SAS軟件PRINCOMP過程從相關陣出發進行主成分分析,把九項指標綜合成幾個互不相關的綜合變量。
(一)主成分分析結果
SAS輸出的相關陣和特征向量如圖3.1、圖3.2所示。

圖3.1 相關陣特征值
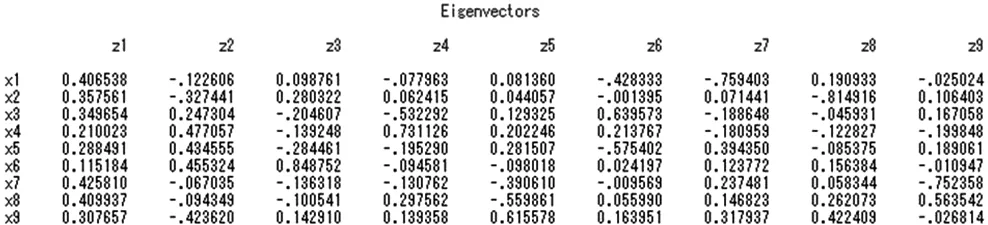
圖3.2 相關陣特征值對應的特征向量
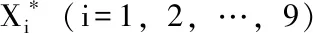
由最大的兩個特征值對應的特征向量可以寫出第一和第二主成分:
利用特征向量各分量的值可以對各個主成分進行解釋。
第一大特征值對應的第一個特征向量的各分量都是正值,且相差不大,說明這九項指標對第一主成分的貢獻相差不大,即第一主成分代表各項指標的綜合情況,所以本文把第一主成分定義為社會服務的綜合水平。
第二個主成分中X4、X5、X6系數都是正值,而且值很大,它們分別對應城市低保人數、農村低保人數及臨時救助人次數,而X1、X2、X9系數均為負,而且絕對值較大,分別對應民政事業費累計支出、社會服務機構數及火化遺體數,綜合起來說明第二主成分是在這樣的情況下:生活保障人數較多,民政事業費累計支出和社會服務機構個數較少,所以本文把第二主成分定義為地區政府的補助和救助。

圖3.3 第二主成分對第一主成分的散布圖
(二)第二主成分對第一主成分散布圖
輸出第二主成分對第一主成分的散布圖如圖3.3所示。
從圖中可以直觀地看出:按社會服務綜合水平,這31個地區應該分為兩組(以第一主成分得分值2。5為分界點)。按地區政府的補助和救助可將這些地區分為3組(以第二主成分得分值-2和1為分界點)。另外,由圖還可以得知:橫坐標第一主成分代表著社會服務綜合水平,其值越靠右代表社會服務綜合水平越高;縱坐標第二主成分反映的是地區政府的社會補助和救助,其值越靠上代表著地區政府社會補助和救助越到位。縱觀全圖,發現四川的社會服務綜合水平最高,新疆的政府補助和救助做的最好,但是其社會服務綜合水平偏低。
(三)按主成分得分排序
對各地區社會服務水平分別根據第一主成分得分和第二主成分得分排序綜合成一個表如表3.1所示。
由表可知,按第一主成分得分和第二主成分得分排序結果差異明顯。我國社會服務做得最好的地區是四川省,河南省、湖南省、云南省社會服務也很到位;江蘇省、廣東省、山東省、浙江省社會服務的綜合水平較高,但是政府救助和補助投入過少;北京、上海、天津、福建省、西藏自治區、青海省、寧夏省的社會服務綜合水平較低,政府救助和補助也較少;河北省、湖北省、安徽省、江西省、陜西省、新疆維吾爾族自治區的綜合水平和政府救助投入都還不錯;內蒙古自治區、吉林省、重慶市、廣西壯族自治區的社會服務綜合水平和政府救助和補助投入都處于居中狀態;江蘇的政府救助 和補助狀況最弱,西藏的社會服務綜合水平最差。

表3.1 各地區按第一、第二主成分得分排序
四、時間序列預測模型
為了預測未來四個季度內的全國民政事業費累計支出,本文從民政部官網上搜集并整理了到了從2014年第三季度至2018年第三季度關于全國民政事業費的累計支出[4]見表4.1所示,利用SAS時間序列預測模型去預測未來四季度數據。

表4.1 全國民政事業費累計支出序列表
(一)數據預處理
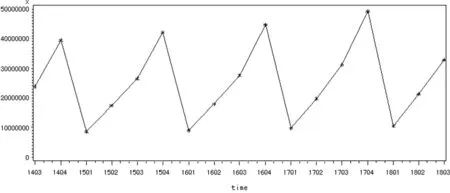
圖4.1 時序圖
使用SAS繪制時序圖和自相關圖如圖4.1所示。觀察時序圖發現從2014年三季度至2018年三季度的數據周期性特別強,而且整體具有長期遞增的趨勢,得出該序列明顯是非平穩序列。
綜上所述,我們可以采用非平穩序列的確定性分析方法[5]去預測,這種方法認為任何一種時間序列都可以用長期趨勢、循環波動、季節性變化、隨機波動這四個因素的某個函數進行擬合。由時序圖可知民政事業費累計支出序列既有長期趨勢,又有周期效應,即可確定本次預測應該選用Holt-Winters三參數指數平滑模型。
(二)Holt-Winters三參指數平滑預測模型
使用SAS軟件利用 Holt-Winters三參指數平滑預測加法模型[5]對民政事業費累計支出序列進行擬合預測,得到擬合值與預測值,繪制擬合和預測效果圖如圖4.2所示。紅線為擬合預測值,黑線為已知序列值,綠線為預測值95%的置信區間。但由于觀察值較少,所以擬合效果并不是很精確。在觀察值個數較多時該方法更具優勢。
對未來四季度的民政事業費累計支出預測值如表4.2所示。結果顯示,全國民政事業費累計支出在未來四個季度的值會比之前每一年對應季度的值都要高,這說明在未來我國財政在民政事業上的支出會越來越多。

表4.2 未來四季度預測值
五、結論
本文從聚類分析和主成分分析兩個角度對各地區的社會服務水平做了較全面的分析,并對未來民政事業費的支出進行了預測。最終得出這樣的結論:我國大部分地區社會服務水平處于中等,四川省、河南省、湖南省社會服務做得相對最好,北京、上海、西藏、海南、天津等地區社會服務水平較低,需要從多方面需要改善。而且以后國家財政在民政事業上的支出會越來越多。
總之我國大部分省市在社會服務水平上都存在或多或少需要提高的地方,要基于各地區的實際情況從多方面入手來提高社會服務水平。
猜你喜歡
杭州金融研修學院學報(2022年5期)2022-06-15 11:41:48
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年11期)2019-08-13 00:49:08
今日農業(2019年13期)2019-08-12 07:59:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
銅仁學院學報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
