局部最優(yōu)分箱及其在評分卡模型中的應(yīng)用
2019-05-05 06:30:08夏晨琦
統(tǒng)計與決策 2019年7期
夏晨琦
(北京中關(guān)村融匯金融信息服務(wù)有限公司,北京 100089)
0 引言
信用評分卡類型眾多,從客戶業(yè)務(wù)周期角度出發(fā)有申請、行為評分卡,從產(chǎn)品對象角度有風險、收益、流失評分卡等,各評分卡既有相同的基礎(chǔ)指標,又有自身的特色變量,其目標變量各不相同。各變量數(shù)據(jù)的探索、采集、加工、衍生是建模的基礎(chǔ)和關(guān)鍵,特別地,一個優(yōu)秀的自變量往往能夠大幅提高模型效率。大數(shù)據(jù)時代,在數(shù)據(jù)處理及計算機運算能力卓越的基礎(chǔ)之上,現(xiàn)代評分卡建模前往往預(yù)收集成百上千的變量。
針對不同的變量類型,傳統(tǒng)的變量能力評測方法是對原始變量進行t檢驗(連續(xù)性變量)、F檢驗、卡方檢驗(分類變量)、列聯(lián)表分析、相關(guān)系數(shù)(Pearson,Spearman)等。由于邏輯回歸對變量數(shù)據(jù)質(zhì)量的要求高(數(shù)據(jù)無缺失,異常值對建模的最終結(jié)果影響程度大等),連續(xù)性自變量的預(yù)測能力往往無法從原始數(shù)據(jù)中充分體現(xiàn)。為此,對原始數(shù)據(jù)進行轉(zhuǎn)化后,提高建模穩(wěn)定性,挖掘變量“隱藏”的預(yù)測能力成為了現(xiàn)代評分卡模型優(yōu)化的常用方法,其中,以分箱(分段)方法最為普遍及有效。
1 模型評價方法
對于有監(jiān)督模型(分類器,包括評分卡),主要評價方法有ROC曲線、LIFT(提升度)曲線或LORENZ曲線(捕獲率)等。
1.1 ROC曲線
以ROC曲線評價方法為例,首先引入混淆矩陣的概念(見圖1)。
其中:TP代表真陽性數(shù),即預(yù)測為陽性,真實值也為陽性的樣本數(shù);FP代表假陽性數(shù),即預(yù)測為陽性,真實值則為陰性的樣本數(shù);TN代表真陰性數(shù),即預(yù)測為陰性,真實值也為陰性的樣本數(shù);FN代表假陰性數(shù),即預(yù)測為陰性,真實值則為陽性的樣本數(shù)。
因此,TP/P(真陽性數(shù)/樣本陽性數(shù))代表捕獲率(或稱召回率、靈敏度),TN/N(真陰性數(shù)/樣本陰性數(shù))則為真負率(或稱特異度)。

圖1 混淆矩陣
按預(yù)測概率對樣本排序后選取臨界百分位點(一般選取等距間隔,且間隔越小,曲線越平滑),根據(jù)每個百分位點可得到n組TP/P(TPR)和(1-TN/N)(1-TNR),將這些值對應(yīng)的點連接起來,就構(gòu)成了ROC曲線,而曲線下的面積AUC(Area Under Curve,范圍為[0.5,1))便成為評價模型的一種標準(越大越好)。
1.2 LIFT曲線
許多業(yè)務(wù)場景往往關(guān)注模型的響應(yīng)率,此時ROC曲線(捕獲率)不再是模型評價的核心,而另一種方法LIFT曲線能更清晰地展現(xiàn)模型的命中能力:

提升度即模型在選定深度(百分位)的命中率與基線概率(也稱先驗概率,即樣本概率)的比值。LIFT越高表明模型對原始概率的優(yōu)化提升能力越強。例如,在風險識別的業(yè)務(wù)場景中,樣本原始不良率為5%。現(xiàn)定義深度為10%,即取預(yù)測概率排名前10%的樣本,其不良率上升至30%,則不良樣本命中率提升至原先的6倍(LIFT=6),提高了風險識別能力。
1.3 帶懲罰的評價指標
在邏輯回歸模型中,可以使用AIC、SC等準則統(tǒng)計量來判斷方程的擬合優(yōu)度,且均考慮了模型復(fù)雜度的懲罰。設(shè)回歸模型的極大似然函數(shù)為L,值越大,擬合度越好。AIC、SC公式分別如下:

其中,K是自變量的個數(shù),n是樣本數(shù)量。模型越復(fù)雜,K值越大,即“懲罰”越大。AIC、SC的評價標準為其值越小(可為負數(shù)),模型越優(yōu),因此“懲罰”迫使模型降低變量數(shù)。
1.4 K-S檢驗
K-S檢驗主要檢驗兩個樣本分布是否存在顯著差異,在對二元分類模型進行評價時,測算各累計分組(按模型得分進行排序)中正負樣本在總體正負樣本中各自占比的差異(分布的百分位點是否存在差異),由此評價模型對正負樣本的分離程度。

2 分箱方法
分箱技術(shù)自誕生以來,形成了許多經(jīng)典方法,大致可以分為無監(jiān)督的分箱算法和有監(jiān)督的分箱算法,前者更易處理,但未提煉目標變量與解釋變量的關(guān)聯(lián)性信息。
2.1 無監(jiān)督分箱
(1)等深分箱
將樣本根據(jù)指定變量進行排序,并按照樣本個數(shù)等分成n組,每組數(shù)據(jù)的指標上下界作為之后指標分段的依據(jù)。
(2)等寬分箱
將變量的取值間距等分,使得每個箱體的區(qū)間距離相同,但箱體的樣本個數(shù)可能各不相同。
(3)聚類分箱
基于k均值聚類的分箱,首先確定分箱的數(shù)量K,然后根據(jù)K均值聚類法將觀測值聚為K類。
2.2 有監(jiān)督分箱
(1)最小熵分箱
有監(jiān)督分箱方法均要考慮目標變量的取值。

箱中的類別越純凈,熵值則越小,若因變量只有一個水平,則熵值等于0。
令wi表示第i個分箱的觀測數(shù)占比;那么總熵值為:

最小熵分箱能夠最大限度地區(qū)分因變量的各類別,即分箱具有良好的區(qū)分能力。
(2)最小GINI分箱
類似地,用GINI不純度替換熵值,同樣可以進行最優(yōu)分箱。此時,再次令表示第l個分箱內(nèi)因變量取值為j的比例,GINI不純度為:

GINI不純度越小,分箱效果越好。
綜上,最小熵分箱及最小GINI分箱均屬于決策樹分箱的方法類,存在過度分箱的問題,即最優(yōu)化指標值會使得分箱太依賴于目標變量值,導致分箱不平滑或是箱數(shù)過多。
(3)BEST K-S分箱
K-S檢驗除應(yīng)用于模型外,還可直接對變量進行分箱。將單變量作為一個特殊的二分類模型:
①K-S檢驗給出區(qū)分度最大的區(qū)間臨界值,并將數(shù)據(jù)左右分割;
②對于分為兩類的樣本數(shù)據(jù),重復(fù)K-S檢驗對數(shù)據(jù)進行分割,以此類推。
與最小熵、最小GINI系數(shù)分箱相同,BEST K-S分箱同樣屬于全局最優(yōu)分箱,但其具有計算成本低,易于調(diào)控分裂數(shù),穩(wěn)定性較強等特點。
3 變量篩選方法
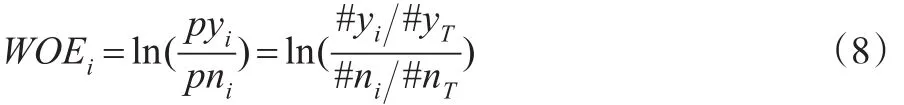
實際上WOE與K-S的思想非常類似,都是對正負樣本進行分布差異的檢驗,其區(qū)別在于K-S的取值范圍是0-1,而WOE進行了對數(shù)轉(zhuǎn)換使得取值范圍擴大為(-∞,+∞ )。IV值的公式如下:
3.1 變量自身解釋能力
信息值(IV值)全稱“Information Value”,顧名思義是對變量的解釋信息的提取,IV值越大,表明變量包含的信息越多,對于建模越重要。IV值由WOE值進行加權(quán)求和,其中,WOE(Weight of Evidence)表示自變量取某個值的時候?qū)`約比率的一種影響,公式如下:

3.2 變量降維
變量降維是剔除“重復(fù)”變量的過程,“重復(fù)”指的是變量間的信息包含重合度,即變量間的相關(guān)性。對兩個變量進行相關(guān)性檢驗,若變量間相關(guān)性強,則保留對模型更重要的變量(一般用IV值的大小評判變量對模型的作用)。對于兩個連續(xù)變量,可計算其Pearson相關(guān)系數(shù);若存在一個變量為離散型變量,可采用Spearman相關(guān)系數(shù);但對于成百上千的變量,進行兩兩比較往往花費大量時間。
變量聚類是高維變量批量篩選的首選方法,基本思想是將變量的相關(guān)系數(shù)矩陣進行因子旋轉(zhuǎn),得到涉及變量互不相同的主成分,后對第二特征值大于給定閥值的變量類進行分解。聚類后的每組變量中均有最好的代表變量,評判標準為(1-R2)比:

4 局部最優(yōu)分箱及變量篩選
4.1 局部分箱算法
局部分箱思想基于Best K-S分箱,將Best K-S分箱的全局性拓展為局部性。
(1)Response加權(quán)分箱
Response加權(quán)分箱是將響應(yīng)率(準確率)考慮進分箱的算法中,考慮如下虛擬數(shù)據(jù)(見表1)。

表1 切分點比較
其中,P%代表正樣本分布,N%代表負樣本分布,|P%-N%|即區(qū)分度,Response代表響應(yīng)率(準確率)。以一次分裂為例,通過Best K-S分箱,易知切分點為2,該水平下樣本數(shù)據(jù)達到K-S值63.55%,然而其Response僅為15.81%,較變量水平<=1時(42.06%)下降了60%以上的準確率,這與區(qū)分度的提升幅度(23.25%)形成較大的差異,因此,若從切分點為1轉(zhuǎn)換至切分點為2,變量的解釋效用呈現(xiàn)衰減特征。
引進創(chuàng)新加權(quán)變量,將區(qū)分度與響應(yīng)率進行加權(quán)綜合考慮,如表1所示,將兩者的權(quán)重定為50%,相加后的得分最大值(46.81%)指向了切分水平1,雖然在全局上未形成最大的區(qū)分度,但在局部(前10%)的數(shù)據(jù)中得到了最優(yōu)切分。
不同的數(shù)據(jù)對權(quán)重的敏感性較強,因此較優(yōu)的分箱方式是對權(quán)重進行遍歷。考慮更新虛擬數(shù)據(jù)(見表2)。
當變量水平<=1時,Response達到了100%,但此時正樣本數(shù)為1,負樣本數(shù)為0,該水平下樣本本身不具規(guī)模,Response沒有代表性。將Response權(quán)重從50%降至40%,同樣得到了局部優(yōu)化。算法實現(xiàn):
第一步:對連續(xù)型變量水平進行從小到大排序,分別計算向上及向下累積正樣本量、累積負樣本量、累積分組樣本量,從自變量與目標變量概率的正負相關(guān)性考慮其解釋能力。
第二步:用加權(quán)(權(quán)重可調(diào)整)Response最高分對應(yīng)的變量水平值作為分裂點將樣本分為左右兩部分。

表2 切分點比較
第三步:對左右兩部分樣本重復(fù)第一步和第二步后停止,即一般將變量分為4個箱。
(2)K-S領(lǐng)域分箱
該分箱方法與上文相似,對變量的累計區(qū)分度和響應(yīng)率進行交互作用,但此處不使用加權(quán)求和的方法,而是通過查詢接近K-S范圍的區(qū)分度領(lǐng)域中的累積提升度(當響應(yīng)率不低于基線概率時,提升度=響應(yīng)率/基線概率;反之,提升度=基線概率/響應(yīng)率(當響應(yīng)率=0時,提升度取空值))進行評價,尋找分裂點。算法實現(xiàn):
第一步:同上文。
第二步:計算變量的K-S值(即區(qū)分度最大的值),記為ks。
第三步:計算在區(qū)分度>=α×ks(其中α為擾動參數(shù),設(shè)置范圍一般為0.95~0.99)時,最大提升度對應(yīng)的變量水平值,作為分裂點將樣本分為左右兩部分。
第四步:對左右兩部分樣本重復(fù)第一步至第三步后停止。
(3)召回設(shè)限下的最優(yōu)Response分箱
與Response加權(quán)分箱的思想有所不同,不考慮區(qū)分度,而對正樣本的召回率設(shè)定下限,以此保證分裂后的數(shù)據(jù)具有規(guī)模代表性,后以最優(yōu)Response點進行分裂。
同樣以上文中案例為例,如果設(shè)定召回率P(%)下限為30%,則其結(jié)果與Response加權(quán)分箱一致。
該方法的難點在于召回率下限設(shè)定:取值過大往往造成對優(yōu)秀響應(yīng)率的忽視(如樣本在25%召回率時達到40%響應(yīng)率,但30%召回率或更大時其響應(yīng)率衰減至10%以下);取值過小使得變量不能完全發(fā)揮效用(如樣本在20%召回率時達到60%響應(yīng)率,但在50%召回率時其響應(yīng)率也能維持在50%)。為此,采用兩維搜索法(見圖2)。

圖2 Response搜索
按圖2箭頭方向搜索,若同時滿足召回率及響應(yīng)率,則尋找最優(yōu)的Response,其中每個參數(shù)都可以進行設(shè)置算法實現(xiàn):
第一步:同上文。
第二步:用上述兩維搜索法分裂樣本。
第三步:不再對滿足兩維條件的數(shù)據(jù)集進行分裂,而對剩余一邊數(shù)據(jù)進行第二步,以此類推。
該算法存在復(fù)雜度較高,運行時間成本大,低自動化等劣勢。
(4)BEST IVi分箱
根據(jù)IV值的思想,對累積分組進行WOE與IVi值的計算,搜索使得IVi最大的水平值作為分裂點。
因WOE值是區(qū)分度的對數(shù)化,其值比RESPONSE值對極端情況更為敏感,所以BEST IVi分箱同樣存在結(jié)構(gòu)不平衡的問題。
(5)其他分箱
關(guān)于局部最優(yōu)解思想的分箱層出不窮,可以增加加權(quán)的維度,搜索區(qū)分度下降速度等,有些遍歷方法甚至可以展開探索,本文不再一一列舉。
(6)邊界調(diào)優(yōu)
原始分箱后,得到的邊界值往往不具備業(yè)務(wù)意義或業(yè)務(wù)部署效果解讀性較差(如邊界值為49.67,模型部署時調(diào)優(yōu)至50為宜),因此,分箱后需對原始分箱邊界進行調(diào)優(yōu),即有效位數(shù)的保留,使得分段數(shù)值更具業(yè)務(wù)解讀性。遍歷所有有效數(shù),并保留3位有效數(shù)字,末位為0或5。
4.2 變量篩選
在對變量進行分箱以發(fā)揮效用后,得到IV值作為對變量的最優(yōu)評價。變量篩選時,首先剔除IV值過小(一般認為<=0.02)的變量,然后進行變量聚類。
當變量數(shù)成百上千時,直接聚類會降低每類中變量相關(guān)性的解釋能力。一般地,可以對變量進行人工的初分組,將基于初始變量的衍生變量分為一組,對每組變量進行聚類。
變量聚類可以在變量分箱前完成,這樣可以降低變量數(shù),大幅減少建模時間,其缺點是通過變量聚類篩選出的變量雖有最佳的(1-R2)比,而被剔除的變量中可能存在“黃金”變量(IV值高)。因此,本文采用綜合評判標準篩選變量,將聚類后每組中變量的IV值和(1-R2)比加權(quán)綜合,選取綜合指標最高的變量。
5 模型實現(xiàn)及分箱對比
本文樣本數(shù)據(jù)來源于KAGGLE網(wǎng)站等互聯(lián)網(wǎng)現(xiàn)有的或改造后的虛擬數(shù)據(jù)。
5.1 模型實現(xiàn)
(1)將建模樣本分層抽樣為訓練集(70%)和驗證集(30%);
(2)剔除缺失率超過60%的變量;
(3)對數(shù)值型變量進行分箱(分箱方法為BEST K-S分箱及Response加權(quán)分箱(權(quán)重設(shè)為0.2)、K-S領(lǐng)域分箱(α=0.99)等,并進行了取整優(yōu)化);
(4)對字符型變量根據(jù)水平響應(yīng)率進行K-MEANS聚類(K=5),從而達到水平降維的效果;
(5)對每個變量進行WOE及IV值的計算,并剔除IV值0.02及以下的變量;
(6)利用綜合指標法對變量降維;
(7)變量WOE轉(zhuǎn)碼;
(8)邏輯回歸建模(backward選擇法);
(9)評分刻度轉(zhuǎn)換;
(10)模型評價。
5.2 分箱對比
以BEST K-S分箱、Response加權(quán)分箱、K-S領(lǐng)域分箱模型進行對比(建模其他環(huán)節(jié)完全一致):
(1)變量分箱對比
選擇某一變量進行對比,結(jié)果如表3至表5所示。

表3 Response加權(quán)分箱

表4 BEST K-S分箱

表5 K-S領(lǐng)域分箱
比較上述關(guān)于同一變量的三種不同分箱方法,發(fā)現(xiàn)Response加權(quán)分箱具有最高的IV值,同時其響應(yīng)率的區(qū)分度最為顯著;另外,K-S領(lǐng)域分箱在考慮提高區(qū)分度的同時,兼顧區(qū)間劃分的樣本規(guī)模結(jié)構(gòu),因此在第一段箱體上得到最高的IVi值,有利于最大效用地發(fā)揮變量能力。
(2)模型對比
對基于上述三種分箱方法的建模結(jié)果進行比較,情況如下:
①基本指標對比
如表6所示,通過Response加權(quán)分箱建模后的指標變量27個,與K-S領(lǐng)域分箱的模型變量相同,而BEST K-S分箱后的模型使用了篩選后的全部變量,模型復(fù)雜度較高。
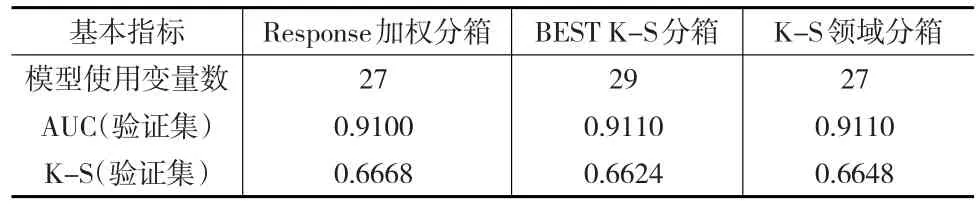
表6 模型效果對比
ROC曲線面積方面,三種模型的差異極小,BEST K-S分箱及K-S領(lǐng)域分箱均為0.911,而Response加權(quán)分箱后模型的AUC為0.91,僅降低0.001。
K-S值方面,Response加權(quán)分箱后模型表現(xiàn)最佳,為0.6668,其次是K-S領(lǐng)域分箱及BEST K-S分箱模型。
Response加權(quán)分箱IV值較BEST K-S分箱高的變量數(shù)15個;反之,BEST K-S分箱較Response加權(quán)分箱IV值高的變量數(shù)有23個,表明權(quán)重對每個變量的解析力度不同。
②提升度對比
在SAS環(huán)境中分別進行Response加權(quán)分箱建模、BEST K-S分箱建模以及K-S領(lǐng)域分箱建模(見表7),并從模型提升度效果的角度出發(fā)評價其局部預(yù)測能力。根據(jù)結(jié)果對比發(fā)現(xiàn),K-S領(lǐng)域分箱模型在局部領(lǐng)域的表現(xiàn)最佳,體現(xiàn)了該分箱方法對于頭部樣本預(yù)測能力的提升。

表7 提升度效果對比
6 結(jié)束語
基于局部最優(yōu)思想的分箱方法是對傳統(tǒng)全局最優(yōu)評價的一種補充和創(chuàng)新,除了在Logistic回歸方法領(lǐng)域,決策樹的分裂規(guī)則同樣可以利用局部最優(yōu)的思想進行嘗試,特別是衍生至GBDT、隨機森林等領(lǐng)域,對于局部最優(yōu)的集成或許可以得到大幅提升的效果。目前,對局部最優(yōu)的探索尚處于初級階段,許多方法和思路有待驗證和完善,但顯然這種價值挖掘值得長期探索。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
