DCE-MRI及DWI影像特征對乳腺癌病理組織學分級及Ki-67表達的預測研究
2019-05-14 02:34:14趙文芮許茂盛王世威厲力華
中國生物醫(yī)學工程學報 2019年2期
趙文芮 許茂盛 王世威 范 明* 厲力華
1(杭州電子科技大學生命信息與儀器工程學院,杭州 310018)2(浙江省中醫(yī)院放射科,杭州 310006)
引言
乳腺癌是女性最常見的惡性腫瘤之一,其發(fā)病率位居女性惡性腫瘤之首,占全身各類惡性腫瘤的7%~10%,每年全球大約有130萬人被診斷為乳腺癌,有約40萬人死于該疾病[1]。目前,我國乳腺癌的發(fā)病率正以每年3%~4%的速度急劇增長,而且患者群體日漸年輕化[2]。因此,精準的乳腺癌的預后治療對提高乳腺癌的整體療效乃至降低死亡率十分關(guān)鍵[3]。為了實現(xiàn)該目標,除了采取積極有效的防治策略外,還需對乳腺癌的生物學指標進行準確判斷和預測。
腫瘤的組織學分級與患者預后的關(guān)系已引起腫瘤學家的重視[4]。Elston和Ellis使用量化的分級標準,即Nottingham聯(lián)合組織學分級[5]。腫瘤的分級由形態(tài)學特征決定,包括腺管形成的程度、細胞核的多形性以及核分裂計數(shù)[6]。根據(jù)評分規(guī)則將每項評分相加,得到3個等級[7]。乳腺癌的組織學等級越高,代表其惡性程度越高,預后越差[8],它可以對乳腺癌的臨床診斷及預后評估提供參考,因此對乳腺癌的組織學分級進行預測判斷具有極其重要的意義[9]。
Ki-67抗原是一類與細胞周期相關(guān)的增殖細胞核抗原,它的功能與有絲分裂密切有關(guān),在細胞增殖過程中是不可缺少的[10-11]。Ki-67的評分體系一般是基于腫瘤細胞核著色的百分比。2011年,St.Gallen早期乳腺癌國際專家達成共識,提出將14%作為Ki-67陽性指數(shù)高低的界限值[12]。當Ki-67陽性細胞數(shù)小于14%時為低表達,大于14%為高表達[13]。Ki-67是一種腫瘤侵襲的重要指標[14],在乳腺癌診斷中是判斷惡性腫瘤細胞增殖活性程度最可靠的指標之一[15]。已有大量研究表明,Ki-67在腫瘤的診治與預后監(jiān)測等方面均顯示出重要的臨床價值,其高表達反映了腫瘤的高增殖性、高惡性程度以及相對較差的預后。
由于組織學分級不同,或Ki-67表達狀態(tài)不同的乳腺癌在影像學檢查中有不同的表現(xiàn),根據(jù)影像學檢查所反映的信息來判斷乳腺癌的組織學分級和Ki-67的表達成為一種可行的方式。目前,常用的乳腺癌影像學檢查方法主要有乳腺鉬靶X線攝影、乳腺超聲、乳腺CT以及乳腺核磁共振(magnetic resonance imaging,MRI)等[16]。乳腺鉬靶X線對發(fā)現(xiàn)微小鈣化最具有優(yōu)勢,但該方法容易遺漏腫塊;乳腺超聲對結(jié)節(jié)、腫塊的顯示優(yōu)于鉬靶,但對于無腫塊型病灶難以分辨;CT檢查分辨率高,但具有放射損傷且價格昂貴[17-18]。與上述3種檢查方式相比,MRI技術(shù)無放射損傷,具有較高的敏感性,所提供的信息豐富,可以無創(chuàng)性地顯示血流動力學及功能改變,對乳腺癌腫瘤的定性診斷幫助較大[19]。MRI是多參數(shù)成像,其中動態(tài)增強磁共振(dynamic contrast enhancement MRI,DCE-MRI)通過靜脈注射造影劑,獲取一系列的連續(xù)動態(tài)增強圖像,觀察動態(tài)對比劑的進入、分布和流出組織狀況,可以反映腫瘤內(nèi)部的血流動力學情況;DCE-MRI不僅可以獲得病變的形態(tài)學特征信息,還可以反映病變組織的生理性變化情況。擴散加權(quán)成像(diffusion weighted imaging,DWI)是一種能提供與常規(guī)SE序列完全不同的成像對比,可通過檢測人體組織中水分子擴散運動和程度等信息,間接反映組織微觀結(jié)構(gòu)的變化[20-21]。這些技術(shù)逐漸成熟,并應于與臨床研究,使得MRI檢查更有利于癌癥的診斷。DWI是唯一能夠活體檢測水分子擴散情況的無創(chuàng)影像檢查技術(shù)[22],可根據(jù)彌散敏感系數(shù)(b值)計算出的表觀擴散系數(shù)(apparent diffusion coefficient,ADC)對其定量分析[23]。
從MRI影像中提取各類影像特征,對乳腺癌的各類預后指標進行分類和預測,此類研究在國內(nèi)發(fā)展得較為成熟。但研究者多數(shù)只用單一參數(shù)磁共振成像的影像做研究,而忽略了不同參數(shù)磁共振成像之間的信息互補關(guān)系。本研究的目的就是將不同參數(shù)的MRI影像聯(lián)合起來運用,充分利用其各自的優(yōu)勢,獲得更豐富、更可靠的特征信息,用來預測乳腺癌的組織學分級和Ki-67的表達。本研究分別從DCE-MRI和ADC影像的病灶區(qū)域提取了紋理特征、統(tǒng)計特征以及統(tǒng)計特征,進行單變量邏輯回歸分析和多變量邏輯回歸分析,最后進行多分類器模型融合。結(jié)果表明,相比單一參數(shù)磁共振成像的預測研究,多參數(shù)磁共振的聯(lián)合應用(DCE-MRI和DWI)可以取得更優(yōu)的預測結(jié)果,為乳腺癌的預后提供可靠的信息參考。
1 資料和方法
1.1 患者數(shù)據(jù)
本研究數(shù)據(jù)均采集自浙江省中醫(yī)院,共計203例BI-RADS 3級及以上的乳腺癌病例。所采集的全部病例在MRI檢查前均未進行過任何乳腺手術(shù)或化療,根據(jù)研究需要篩選出病理報告及影像序列均完整的病例。所采集的病例中導管內(nèi)癌、黏液癌、浸潤性小葉癌等非浸潤性導管癌共計26例,其病理報告均未說明乳腺癌的組織學分級情況;浸潤性導管癌病理報告未說明分級情況的共計6例;病理報告完全缺失的共計3例;DCE序列數(shù)量異常的共計4例;DWI序列缺失或不完整的共計15例;ADC序列不完整的共計5例。經(jīng)過以上數(shù)據(jù)篩選,最終采用144個病例作為本研究的數(shù)據(jù)集。對這144個病例進行統(tǒng)計分析,發(fā)現(xiàn)均為女性乳腺癌患者,年齡分布在28~83歲之間,平均年齡約為52歲,其中絕經(jīng)前78例,絕經(jīng)后66例。
1.2 影像數(shù)據(jù)
本研究所處理的醫(yī)學影像(包括DCE-MRI,及DWI影像)均采自浙江省中醫(yī)院放射科,所使用的設(shè)備為德國西門子3.0T超導型磁共振掃描設(shè)備。全部患者均取俯臥位,采用專用的8通道雙乳房線圈進行掃描。在每次MRI檢查中,先掃描和獲取脂肪抑制T1加權(quán)圖像和脂肪飽和T2加權(quán)前對比序列(記作S0序列)。所用順磁性對比劑Gd-DTPA的劑量為0.2 mmol/kg,在以4 mL/s的速度靜脈注射造影劑后,可以獲得5個增強后(postcontrast)序列(分別記作S1~S5序列)。注射造影劑60 s后獲得第一個序列,后續(xù)5個序列分別按時間間隔60 s的順序進行采集。動態(tài)增強掃描的參數(shù)設(shè)置如下:重復時間TR為4.5 ms,回波時間TE為1.6 ms,翻轉(zhuǎn)角度FA為10°,視野FOV為 340×340(mm2),層厚為1.0 mm,層間距為1.0 mm,空間分辨率為0.79 mm。采集的增強前序列以及5個增強后序列均具有相同的規(guī)格,每個序列均包含144張斷層截面圖,每張影像的采集矩陣均為448×448。DWI序列是在蒙片掃描前進行的,使用以下參數(shù):b值有3個,分別為50、400、800 s/mm2,重復時間TR為8 400 ms,回波時間TE為84 ms,翻轉(zhuǎn)角度FA為 90°,視野FOV為147×359(mm)2,層厚為4.0 mm,層間距為6.0 mm,像素帶寬為1 263 Hz,空間分辨率為1.64 mm。每個b值對應24張DWI影像,故一個DWI序列共有72張斷層截面圖,每張影像的采集矩陣為220×90。在工作站通過對DWI數(shù)據(jù)后操作處理,可以形成灰階ADC圖。ADC序列共有24張影像,每張影像的采集矩陣與DWI影像相同,為220×90。
1.3 影像預處理
對于所采集的乳腺癌原始影像,需將病灶從區(qū)域分割出來進行研究;對于DCE-MRI影像,采用實驗室前期基于空間模糊C均值和馬爾科夫隨機場的方法進行分割[24]。對DCE-MRI的每個序列都進行分割操作,各序列均會得到一個三維病灶。隨后,將分割得到的一個序列的病灶區(qū)域與對應的ADC影像進行配準,最終在ADC影像上獲取到與DCE-MRI病灶輪廓一致的病灶區(qū)域。
1.4 特征提取
在本研究中,對DCE-MRI的病灶區(qū)域的影像選取了蒙片,對第二增強序列以及第五增強序列進行分析,這兩個增強序列在進行特征提取之前都分別在圖像像素上減去了蒙片序列。共提取了97維特征,具體分為以下三大類特征:一是紋理特征,包括能量、相關(guān)性、平方和方差、同質(zhì)性等19維特征;二是統(tǒng)計特征,包括均值、標準差、峰度、偏度等10維特征;三是形態(tài)特征,包括體積、離心率、表面積、緊致度等10維特征。ADC病灶影像同樣提取了上述的三大類特征,共計39維特征。
1.5 表達統(tǒng)計
從浙江省中醫(yī)院采集的病理報告中,可以得到每個病例的乳腺癌組織學分級情況,以及相應的Ki-67陽性細胞的百分比。經(jīng)過統(tǒng)計,組織學分級為II級的病例共計68例,III級的病例共計76例;Ki-67 低表達的病例共計36例,Ki-67高表達病例共計108例(見表1)。對組織學分級進行卡方檢驗,P<0.001,說明Ki-67表達與組織學分級是有關(guān)聯(lián)的;對PR表達、絕經(jīng)情況以及年齡分別進行卡方檢驗,P值分別為0.074、0.334、0.605,說明Ki-67表達情況對PR表達、絕經(jīng)情況以及年齡的分布沒有顯著影響。

表1 樣本Ki-67表達特征統(tǒng)計Tab.1 Characteristics of Ki-67 expression for patients
注:a表示利用卡方檢驗計算P值,b表示利用方差分析計算P值,PR為孕激素受體。
Note:aData were tested using the chi-square test;bData were tested using the analysis of variance(ANOVA); PR, progesterone receptor.
1.6 統(tǒng)計分析
為了研究影像特征對組織學分級和Ki-67表達的預測能力,分別對提取的不同序列的影像特征進行單變量回歸分析和多變量回歸分析,最后利用模型融合,將DCE-MRI與DWI兩個成像參數(shù)不同的影像聯(lián)合起來預測腫瘤分級。
1.6.1回歸分析
首先對基于DCE-MRI和DWI病灶影像提取的單個特征進行單變量邏輯回歸分析。對于分級的預測任務(wù),令I(lǐng)I級為0、III級為1。隨后依次按照特征提取的順序取出一個特征值,使用留一法交叉驗證法(LOOCV)進行訓練和預測[25]。為了評價分類模型的性能,繪制了受試者工作特征曲線(receiver operating characteristic curve, ROC),并計算了ROC曲線下的面積(area under the ROC, AUC)。對于Ki-67的預測任務(wù),令Ki-67低表達為0、Ki-67高表達為1。同樣,采用上述的留一法交叉驗證評價每個特征對Ki-67的預測能力。
1.6.2特征選擇
單變量邏輯回歸分析中,對提取的特征逐個進行了評價,但并沒有分析各個特征之間的共同作用,故需要再進行多變量邏輯回歸分析。對于DCE-MRI影像和DWI影像,在特征提取之后,特征的數(shù)量可能仍然很多,所以需要通過特征選擇進行降維處理。
首先兩兩計算特征之間的皮爾遜相關(guān)系數(shù),將相關(guān)系數(shù)大于0.9的特征刪除。在此基礎(chǔ)上,本研究分別選用無監(jiān)督判別特征選擇方法UDFS(unsupervised discriminative feature selection)和有監(jiān)督學習的Fisher Score算法進一步對特征進行選擇。UDFS算法對每個樣本定義一個局部判別得分,然后通過解決L2,1歸一化問題,尋找讓所有樣本局部判別得分之和最高的特征子集[26]。Fisher Score算法可以有效地區(qū)分數(shù)據(jù),給最有效區(qū)分數(shù)據(jù)點(不同類的數(shù)據(jù)點盡可能分開,而同類的數(shù)據(jù)點盡可能聚在一起)的特征賦予最高的分值[27]。
通過刪除相關(guān)性高的特征之后,后續(xù)的特征選擇算法均在留一法的框架內(nèi)進行。具體地說,通過留一法將特征集分為K個子樣本集(樣本數(shù)為K),每次不重復地取出一個作為測試,用其余的K-1個子樣本集進行特征選擇,得到特征排序,越重要的特征,排序越靠前;按照特征的重要性依次加特征,每加一個特征后都將得到的特征集進行十折交叉驗證,計算得到AUC值,直到全部的特征加完停止;找出最大的AUC值對應的特征集,即為選擇的最優(yōu)特征集;將測試集樣本的特征按照最優(yōu)特征集的特征進行建模,用來預測測試樣本;如此循環(huán)K次,即所有K個子樣本集均輪到作為一次驗證樣本,每次均進行上述的特征選擇。
1.6.3模型融合
在留一法特征選擇的每次循環(huán)中,根據(jù)特征選擇之后的最優(yōu)特征子集進行邏輯回歸,建立預測模型,并將訓練好的模型對特征選擇后產(chǎn)生的新測試樣本進行預測,直至留一法循環(huán)結(jié)束,最終可以得到一個評價整體模型的AUC值。
對于研究的每個序列均進行了前述的多變量邏輯回歸分析,每個序列都訓練出各自的分類模型,而這些分類模型是各自獨立互不影響的。為了分析它們之間的共同作用關(guān)系,采用模型融合的方式進行研究。選用多分類器融合方法,具體過程如下:在每個序列利用留一交叉驗證法進行多變量邏輯回歸分析時,每次迭代均會產(chǎn)生一個預測的條件概率,共有4個序列,故每次留一法迭代會產(chǎn)生4個條件概率,將這4個概率求均值,得到的新條件概率作為融合后模型的預測值,留一法循環(huán)結(jié)束后,可得到一列4個模型融合后產(chǎn)生的條件概率,根據(jù)此數(shù)據(jù)可計算出AUC等評價指標。此外,根據(jù)上述方法,將不同序列的模型進行兩兩融合或三三融合,可得到最佳的模型融合效果。
2 結(jié)果
2.1 單變量邏輯回歸結(jié)果
通過單變量邏輯回歸分析,分別比較了DCE-MRI和DWI的單個影像特征的性能。其中,紋理特征中的對比度特征為最佳性能特性,即對應S0、S2、S5、ADC的圖像序列,預測分級任務(wù)分別生成了0.690、0.712、0.720和0.671的AUC值,預測Ki-67表達狀態(tài)分別生成了的0.724、0.719、0.692和0.690的AUC值,圖1是該特征的盒形圖。
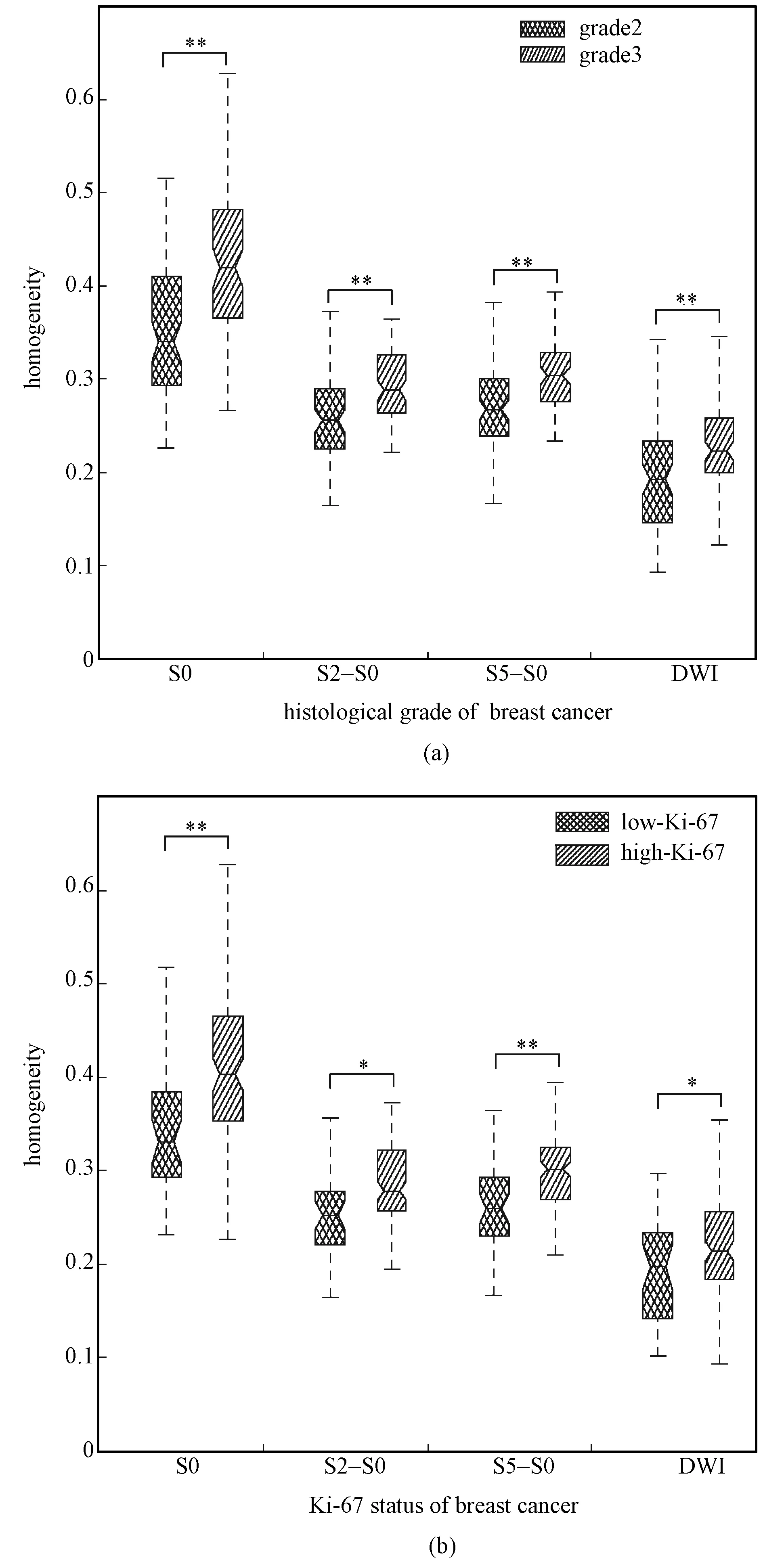
圖1 最優(yōu)單特征盒形圖。(a) 分級任務(wù);(b) Ki-67表達任務(wù)(統(tǒng)計學顯著性表示為*P<0.05,**P<0.001)Fig.1 Boxplots of texture feature of dissimilarity. (a) Histopathologic grading; (b) Ki-67 expression(Statistical significance is represented as *P<0.05,**P<0.001)
2.2 單參數(shù)多變量邏輯回歸結(jié)果
對DCE-MRI和DWI的各個序列都進行了多變量邏輯回歸分析,同時比較了UDFS和Fisher Score兩種特征選擇方法的效果。預測分級任務(wù)的結(jié)果見表2,其中第二增強序列在采用UDFS特征選擇算法時取得了0.780的最佳AUC,特異度為0.647,靈敏度為0.934。預測Ki-67表達任務(wù)的結(jié)果見表3,其中DWI序列在采用Fisher Score特征選擇算法時取得了0.756的最佳AUC,特異度為0.806,靈敏度為0.695。
2.3 不同序列的模型融合結(jié)果
采用多分類器融合的方法,通過將不同序列影像特征數(shù)據(jù)訓練的分類器進行不同組合的融合,比較并分析融合后的結(jié)果。預測分級任務(wù)的模型融合結(jié)果及預測Ki-67表達任務(wù)的模型融合結(jié)果分別見表4、5,不同序列的模型融合結(jié)果有所差異。
從表4可以看到,對于預測分級的任務(wù),相比單參數(shù)多變量邏輯回歸中0.780的最佳AUC,S2、S5和DWI 的融合達到了0.808的最佳AUC,特異度為0.706,靈敏度為0.895。采用UDFS特征選擇算法時,只有S0+S5、S0+S2+DWI這兩種融合方式的結(jié)果相對于0.780沒有提高,其他的模型融合結(jié)果均比0.780有所提升;采用Fisher Score特征選擇算法時,只有S2+DWI、S5+DWI、S2+S5+DWI這3種融合方式的結(jié)果相對于0.780有所提高。將表4和表2的靈敏度與特異度進行比較可以發(fā)現(xiàn),雖然整體結(jié)果差異不大,但采用UDFS特征選擇算法時,相比S5序列0.706的最高特異度,S0+S2+S5模型融合后的特異度達到了0.735;采用Fisher Score特征選擇算法時,相比DWI序列0.829的最高靈敏度,S0+S2+S5模型融合后的靈敏度達到了0.882。
從表5可以看到,對于預測Ki-67表達的任務(wù),相比單參數(shù)多變量邏輯回歸中0.756的最佳AUC,S2和DWI 的融合達到了0.783的最佳AUC,特異度為0.778,靈敏度為0.722。采用UDFS特征選擇算法時,只有S2+S5、S2+DWI這兩種融合方式的結(jié)果相對于0.756沒有提高,其他的模型融合結(jié)果均比0.756有提升;采用Fisher Score特征選擇算法時,沒有DWI序列融合的結(jié)果均低于0.756,其他加入DWI序列的融合結(jié)果除S5+DWI外相對于0.756均有提高。對表5和表3的靈敏度與特異度進行比較可以發(fā)現(xiàn),采用UDFS特征選擇算法時,相比0.722的最高特異度,S0+S2+DWI和S0+S5+DWI能將特異度提高到0.806;且S2+S5的模型融合,可將靈敏度從0.722提高到0.796。

表2 單參數(shù)多變量邏輯回歸預測的分級結(jié)果Tab.2 Histopathologic classification prediction of multivariable Analysis for single parametric image

表3 單參數(shù)多變量邏輯回歸預測的Ki-67結(jié)果Tab.3 Ki-67 expression prediction of multivariable Analysis for single parametric image

表4 預測分級任務(wù)模型的融合結(jié)果Tab.4 Classifier performance of histopathologic classification for DCE-MRI and DWI series
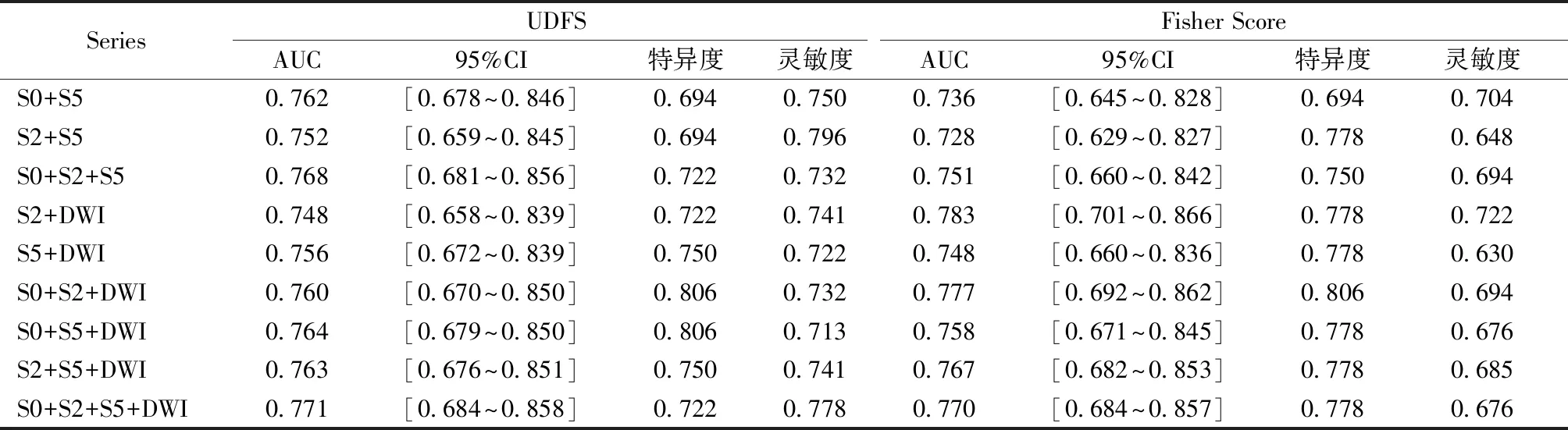
表5 預測Ki-67任務(wù)模型的融合結(jié)果Tab.5 Classifier performance of Ki-67 expression for DCE-MRI and DWI series
3 討論
在本研究中,對采集的影像原始數(shù)據(jù)進行病灶分割,并從中提取各類特征數(shù)據(jù)。首先對每個特征通過邏輯回歸建模進行評價,隨后將特征集合經(jīng)過皮爾遜相關(guān)系數(shù)進行篩選,再分別利用UDFS算法和Fisher Source算法進行特征選擇,使用留一法交叉驗證的方法進行邏輯回歸建模,然后將所得的不同分類器進行多分類器模型融合,根據(jù)計算所得的AUC對分類器的性能進行評估。結(jié)果發(fā)現(xiàn),不同影像序列特征訓練的分類器經(jīng)過模型融合之后,其性能大多數(shù)有所提高。下面對結(jié)果里的每個圖表分別進行討論。
在單變量邏輯回歸分析中,利用所提取的影像特征,分析了單個特征建立模型的預測性能,選取了最優(yōu)單特征,并通過t檢驗評估了最優(yōu)單特征在預測標簽之間的統(tǒng)計學差異。在圖1的盒形圖中,可以看出經(jīng)過t檢驗計算得到的P值均小于0.05,結(jié)果表明,利用計算機分割病灶并提取得到的特征有顯著的預測意義,而這些特征區(qū)別于放射科醫(yī)生觀測到的定性特征,提取的基于灰度共生矩陣的紋理特征、統(tǒng)計特征以及形態(tài)特征能定量地描述病灶的信息,具有更好的分類性能。故使用計算機將乳腺癌腫瘤分割出來并在上面進行計算,可以更充分利用醫(yī)學影像所提供的信息,同時降低醫(yī)生閱片的工作強度。
隨后對每個序列都進行了單參數(shù)的多變量邏輯回歸分析,其中運用了兩種不同的特征選擇方法。從表2中的結(jié)果可以看出,對于預測乳腺癌分級,UDFS算法得到的結(jié)果整體要優(yōu)于Fisher Score算法的結(jié)果。而對于Ki-67表達狀態(tài)的預測,兩種算法在不同序列上的表現(xiàn)并無規(guī)律可循,可能是Ki-67樣本分布不均衡導致的,這一點也是本研究的一個局限性。對于分級預測任務(wù),S2序列達到了AUC為0.78的最佳分類效果;對于Ki-67預測任務(wù),DWI序列達到了AUC為0.756的最佳分類效果。這兩個最佳結(jié)果均比單變量邏輯回歸的最優(yōu)單特征的預測結(jié)果有所提高,表明多變量邏輯回歸分析更能充分利用不同特征之間的信息,考慮不同特征之間的聯(lián)系,利用多特征建立的模型更具有泛化能力。
為了研究不同參數(shù)磁共振圖像之間的相互影響,將不同序列進行多分類器模型融合。從表4、5的模型融合結(jié)果來看,不同序列模型融合的效果也有所差異。對于分級任務(wù),S0、S5和DWI 3個序列的融合達到了0.808的最佳AUC值,所用特征選擇方法為UDFS算法;對于Ki-67任務(wù),S2和DWI兩個序列的融合達到了0.783的最佳AUC值,所用特征選擇方法為Fisher Score算法。除了這兩個最優(yōu)結(jié)果外,其他不同組合的序列融合結(jié)果相比單序列多變量邏輯回歸結(jié)果均有所提高。此外,還對預測模型進行了特異度與靈敏度的分析計算,雖然整體來看多分類器模型融合的方法對于模型的特異度與靈敏度的提升并不具有明顯優(yōu)勢,但有些序列的融合結(jié)果明顯提高了特異度和靈敏度。結(jié)果表明,與單一參數(shù)磁共振成像的預測研究相比較,多參數(shù)磁共振的聯(lián)合應用(DCE-MRI和DWI)可以充分利用不同影像的優(yōu)勢,從而取得更優(yōu)的預測結(jié)果,這對乳腺癌的前期診斷以及預后治療提供更精準的指導,具有重要意義。
乳腺癌的病理組織學分級的研究是一個較新的探索領(lǐng)域,同類研究基本上很少對其進行預測判斷。Shin等的研究表明,DCE-MRI灌注參數(shù)中的Ktrans參數(shù)與Ki-67狀態(tài)顯著相關(guān)[28],但未建立預測模型進行研究。在前期進行基于乳腺癌異質(zhì)性區(qū)域特征的Ki-67表達預測研究[10]的基礎(chǔ)上,本課題組首次嘗試將多參數(shù)磁共振影像(DCE-MRI和DWI)應用于乳腺癌病理組織學分級及Ki-67表達預測的研究中,預測性能基本達到了預期效果,但由于數(shù)據(jù)的局限性,仍需進一步地優(yōu)化提高。
本研究存在局限性:一是前述的Ki-67高表達和低表達樣本不均衡,這可能對實驗結(jié)果造成一定偏差,導致結(jié)果不穩(wěn)定;二是本研究的多參數(shù)磁共振圖像只有DCE-MRI和DWI兩種參數(shù),圖像種類少,使研究范圍較為單一。
4 結(jié)論
本研究主要利用多參數(shù)磁共振圖像(DCE-MRI和DWI),對乳腺癌的組織學分級和Ki-67表達進行預測。采用了UDFS和Fisher Score算法進行特征選擇,對于不同的序列影像,兩種算法各有優(yōu)勢。為了防止過擬合,本研究中的預測模型都建立在留一法的框架上,每次留一迭代中的特征選擇在選取最優(yōu)子集時采用了十折交叉驗證方法。實驗結(jié)果顯示,多參數(shù)磁共振的聯(lián)合應用(DCE-MRI和DWI)可以提高分類器的性能。研究表明,多參數(shù)磁共振成像的聯(lián)合應用對乳腺癌的前期診斷和預后治療具有一定的研究參考價值,后續(xù)將增加更多不同的參數(shù)磁共振圖像進行研究,從而進一步驗證以及豐富實驗研究結(jié)果。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:11:42
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年6期)2019-01-06 09:20:12
祝您健康(2018年5期)2018-05-16 17:10:16
