深度變分貝葉斯投資組合理論
2019-05-18 11:38:28晁夢遙
大眾投資指南 2019年12期
晁夢遙
(陜西省西安翻譯學院,陜西 西安 710105)
一、引言
投資組合選擇的選擇是金融市場學中的一個關鍵問題。其基本思想在于回報和風險的均衡,即根據一個最優化準則選擇最好的投資組合。Markowitz 的投資組合選擇理論[1]為我們提供了如何推導出具有最小可能方差(最小風險)的投資組合和生成位于有效邊界的投資組合的工具。基于這個理論框架,研究者們針對各種問題產生了大量的研究工作[2]-[10]。
這個方案及其變體理論使用統計模型進行建模,捕捉到了淺層因素,而在金融領域,隨著事件復雜性的提升,即所有抽象級別可能看起來同樣可行,主要的深層因素往往與輸入數據呈非線性關系。這些需求激發了深層架構的通用性,即深度投資組合選擇理論。深度學習工具具有極佳的使用價值[3],其極強的建模能力,其可以計算任何函數映射數據的最佳可用方法,以將可能回報以及風險數據,轉化為價值。深度學習在金融市場領域有諸多研究[9]。
另外,組合投資學說的研究假設模型和漂移以及波動的參數是已知的且為常數,這使得參數需用以往數據估計且在此之后保持恒定。在實際變化的市場條件下,這個傳統的解決方案存在一定的不足[4][6]。將貝葉斯學習應用到投資組合分析中能很好地解決這些問題。首先,貝葉斯方法將未知參數視作隨機變量并可以設置先驗信息,從而可以將量化已知信息引入到建模中為學習提供參照而非決策。其次,貝葉斯模型很好地解釋了估計風險和模型不確定性[5]。本文中,我們將貝葉斯推斷引入到深層次因素的學習中。這些使得貝葉斯理論廣泛引用于金融領域[10][9]。
綜合以上考量以及思路,我們設計的深度變分貝葉斯投資組合最優化方法分為學習和優化部分。在學習階段中,(一)使用深度變分自編碼器網絡構建的市場映射算法,其用于捕捉輸入數據的深層次表征;(二)基于深層次表征,使用深度神經網絡實現多變量投資組合支出的監督模型;在優化部分,我們目的在于均衡學習階段的誤差。基于此,本文的貢獻主要有三點,一是,針對投資配置中變量間復雜非線性關系進行建模,并捕捉到深層影響因素;二是,將完全由數據驅動的深度學習和貝葉斯理論引入到投資配置理論從而解決了傳統方法中存在的參數估計誤差以及模型依賴型算法在大數據情況下的不適定性;三是,設計了一個統一的學習框架,從而可以以監督學習的方式端到端優化投資配置模型。
本文的組織結構如下。第二章,我們對深度變分貝葉斯投資配置算法進行詳細的描述。第三章中,我們利用實驗對算法的有效性進行探討。第四章我們簡述本文所得到的一般性結論。
二、深度貝葉斯變分投資組合理論
在本文中,我們構建變分自編碼和多變量投資組合輸出模型。首先,根據深度學習中的數據集分類思想,我們將市場數據劃分為訓練集和驗證集,表示為和,同時我們將目標變量設為。給定具體目標,我們設計智能化投資組合方法,其在投資組合選項中進行權衡以匹配目標函數。
我們的投資組合結構可以分為學習和權衡兩部分,表述如下:
(一)學習部分
針對市場數據以及相應的目標期望,學習部分主要進行數據深層次因素的捕捉以及利用監督學習模式來得到投資組合到目標的映射函數。在深層次因素的捕捉中,我們使用變分自編碼器,其依據貝葉斯理論,能以無監督的方式獲取隱藏變量以作為的優化表征。公式如下:

此為變分自編碼器的變分下界,運用重參數化技巧可得:
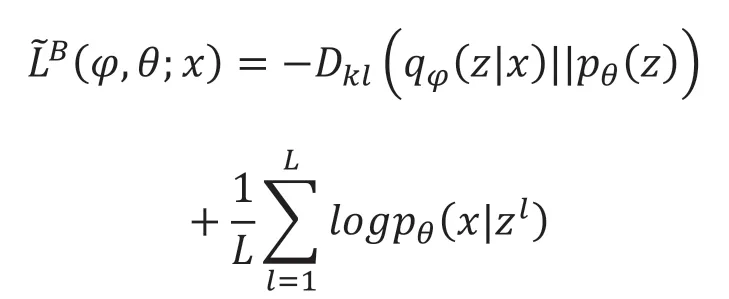
同時,需要得到投資到目標結果的映射函數,其優化公式如下:
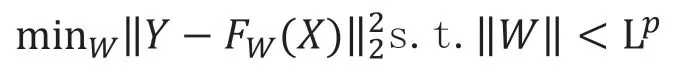
其依據目標,從輸入信息創造一個非線性投資組合映射。
在理論上,深度學習可以捕捉變量間復雜和非線性的關系,以構建性能極佳的回歸模型,這在大部分場景中均優于傳統金融經濟學的簡單線性因子模型以及統計套利和其他定量投資管理技術。同時,我們所提出的變分自編碼器將總信息減少到適用于大量輸入的信息子集,即隱層的編碼,并以編碼后信息與其自動編碼版本的接近度作為衡量標準,對投資組合進行評判。
(二)權衡部分
構建數據到深層次因素(即隱層)以及從數據到投資組合目標的映射網絡后,需要權衡上述誤差以平衡模型在深層次因素學習和目標近似上的能力。則需要尋找最佳Lm和Lp:
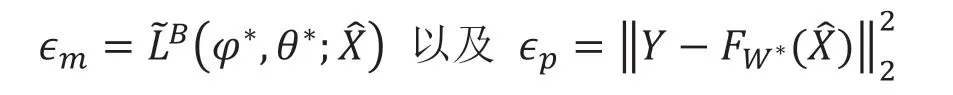
從而我們需要找到φ,θ以及FW以確保上述條件的成立。為此,我們將檢查隱含的深層投資組合邊界以獲得感興趣的目標作為正則化量的函數,以提供可量化可訓練優化的度量函數。
三、實驗
我們的實驗配置如下所述。
數據設置:本章實驗部分所用的數據來自生物技術IBB指數的成分股,數據周期為2012年一月到2016年4月并按周計算回報數據。我們希望找到最優策略從而可以擊敗由(see Merton,1971)給出的生物技術IBB指數。
數據劃分:對于本文所提出的學習和權衡兩個階段,我們采用2012年1月到2013年12月的數據用于學習,用2014年1月到2016年5月的數據作為權衡階段的輸入。
實驗設置:在網絡設置中,我們采用單隱層結構,即變分自編碼器中輸入通過一個10個神經元的中間層和隱藏層相連,最終編碼層包含5個神經元。而對于學習階段的目標映射函數,我們同樣采用包含10個神經元的中間隱藏。以變分自編碼器的中間層編碼作為對股票的編碼,并考慮每個股票與其自動編碼版本間的2范數差異,然后以此接近程度作為度量標準對股票進行排名。我們將10個最多的公共股票和非大多數股票相加來增加深度投資組合中的股票數量。各模塊的訓練batch size大小為10,而epoch 為500。
我們的實驗結果如圖1所示:

Fig1.我們的深度變分貝葉斯投資組合理論在實驗各階段的實驗結果。其中(a)為深層次因素學習階段,即變分編碼階段,(b)為數據校準階段,而(c)和(d)為優化階段。
在學習階段,我們捕捉到了深層次因素即圖(a),在圖(b)的校準階段,我們將所有小于□5%的回報替換為5%,這旨在創建一個在大幅度下降時具有反相關性的指標跟蹤器,而修改后的目標視為圖3(b)中的紅色曲線。在(c)(d)中,我們看到了學習的深層投資組合在優化過程中如何實現卓越績效。驗證表明,對于當前模型,應采用至少40種庫存的深度投資組合進行可靠預測。
四、結論
本文中所提出方法建立在傳統的Markowitz基礎上,即投資選擇問題。然而,不同于傳統方法,我們的理論基于對市場信息的變分編碼,從而校準數據以形成一個針對其后獲取最優投資組合的有效數據。深度變分貝葉斯投資組合理論將深度學習引入以學習數據從而在自動編碼步驟中發現深層功能,同時對數據進行校準。在之后,我們同步優化二者進行權衡,從而展示如何查找投資組合來實現預先指定的目標。這兩個程序都涉及優化,需要選擇正規化量的問題。為此,我們使用了一個樣本驗證步驟。具體而言,我們避免使用可能受模型風險影響的統計模型,并且,我們直接將目標建模到正規化中以直接優化,而不是事前的有效邊界。實驗表明,我們所提出的理論在實際應用中有很好的性能,且以直觀的網絡設計規避了可能受模型風險影響的統計模型。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
當代陜西(2022年5期)2022-04-19 12:10:18
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:28
建材發展導向(2021年12期)2021-07-22 08:06:48
湘潮(上半月)(2021年4期)2021-07-20 08:05:28
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
汕頭大學學報(自然科學版)(2020年4期)2020-12-14 07:05:00
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
