基于近紅外光譜的胡椒產地鑒別方法研究
2019-05-22 01:13:48劉廣昊祝詩平袁嘉佑吳習宇黃華
中國調味品 2019年5期
劉廣昊,祝詩平*,袁嘉佑,吳習宇,2,黃華
(1.西南大學 工程技術學院,重慶 400716;2.西南大學 食品科學學院,重慶 400716)
胡椒是常用的食品調料、藥用原料。其在止瀉、消化、解毒等方面有很大的作用,在很多領域有著巨大的市場潛力和研究價值[1]。不同產區的胡椒,其外觀、氣味及內部化學成分存在差異,品質存在優劣之分。隨著胡椒市場需求快速增長,以劣充優、摻假摻雜、濫標產地等現象層出不窮。傳統方法通過檢測胡椒油和胡椒堿的含量來實現胡椒的品質檢測,通常采用有機溶劑萃取等方法提煉,采用薄層色譜法、氣相色譜法等進行測定[2-4]。
傳統鑒別方法費時費工,而近紅外光譜技術高效環保、節省化學試劑[5],已廣泛應用于各個行業[6,7]。He W等結合近紅外光譜技術與偏最小二乘法,對茶樣品起源進行了快速測定[8]。王元忠等用近紅外光譜技術結合偏最小二乘法,對瑪咖進行了產地鑒別[9]。吳習宇等應用近紅外光譜技術實現了對8個不同產地花椒的分類[10]。
當前,基于近紅外光譜技術對胡椒產地進行快速鑒別,國內外尚無文獻報道。本文旨在探索一種基于近紅外光譜技術對胡椒產地快速識別的方法。
1 試驗材料與方法
1.1 樣品收集及前期準備
從胡椒加工廠、各大超市、花椒種植戶等地收集胡椒主產地樣品。所購買的胡椒在外觀上無明顯差異。以賦值法確定胡椒品種,海南白胡椒賦值為1、云南白胡椒賦值為2、廣西白胡椒賦值為3、越南白胡椒和黑胡椒賦值為4、馬來西亞白胡椒和黑胡椒賦值為5。
光譜采集實驗前,將采集到的胡椒樣品置于干燥的環境下常溫(約25 ℃)保存。使用IKA公司生產的手持式粉碎機(型號為A-11-B-S25)將樣品進行粉碎處理,過80目篩,保證樣品的顆粒度一致,制成每份10.0 g的300份樣品,存放于自封袋中密封、編號。其中海南白胡椒60份、云南白胡椒39份、廣西白胡椒32份、越南白胡椒44份、越南黑胡椒40份、馬來西亞白胡椒45份、馬來西亞黑胡椒40份。
1.2 儀器與設備
布魯克MPA型近紅外光譜儀;OPUS 6.0;MATLAB R2017b;Unscrambler 10.4;Origin 9.0。
1.3 譜圖采集
掃描樣品前將光譜儀開機預熱30 min,以保證樣品測試的穩定性。在約25 ℃環境下,對300份胡椒樣品進行全譜段的光譜掃描:范圍12000~4000 cm-1,次數32次,分辨率8 cm-1,光譜點數2307。每袋樣品掃描3次,取3次的平均光譜。
1.4 光譜預處理方法
掃描得到的光譜圖像往往含有噪聲,這是由儀器放置的環境以及儀器本身的原因造成的;另一方面,光源帶有其他光譜的干擾或者樣品的基質也會對光譜產生影響。儀器和背景產生的噪聲會影響分析的準確度。預處理可以減少高頻隨機噪聲,強化樣品的特征信息,使模型更加穩定。
常用的方法有基線校正(baseline)、平滑處理(smoothing)、小波分解去噪等[11]。小波分解去噪中小波模極大值去噪法計算量大,效率低,層數低時系數受噪聲影響大,產生偽極值點;層數高時會丟失局部特性,低頻系數直接重構容易丟失高頻系數中的有用成分[12]。基于閾值的去噪方法在最小均方誤差下可達近似最優。由于小波基函數數目過多,難以對小波去噪全部參數進行全面實驗以探尋最優參數組合。依據以往的文獻,選取表現較好的小波基函數coif2、haar、sym5等作為候選的小波基函數[13]。經多次篩選和比較,得到了較優參數組合即haar、db5、sym5和bior1.1小波函數,分解層數均為5,閾值方案是sqtwolog規則。
1.5 數據分析方法
1.5.1 偏最小二乘判別法
PLS兼具模型式方法和認識性方法的特點,能完成多組變量線性回歸、降低維度和變量分析[14]。PLS對光譜矩陣X和濃度矩陣Y同時進行分解,在矩陣X和Y中提取相關因子并從大到小排列。改善了主成分分析法中有效變量的相關性較小時,選取主成分容易遺失,導致模型可信度下降的缺陷。PLS-DA算法(Partial Least Squares-Discrimination Analysis,PLS-DA)建立在PLS方法的基礎上,將濃度變量替換為二進制變量,求出光譜向量與類別向量的相關性[15]。
1.5.2 支持向量機
1995年Vapnik等人引入支持向量機的概念,這是一種適合處理小樣本、非線性數據的機器學習方法,廣泛用于數據的分類、模型的預測以及各種回歸分析。
在低維空間中,向量集往往難以劃分,SVM將它們映射到高維空間進行分析。通過在高維空間尋找一個超平面從而將數據劃分開來。高維空間中帶來的數據計算復雜化又可以通過不同的核函數加以解決。核函數的多樣性大大增加了SVM算法的多樣性與靈活性。對核函數的選擇是根據已知數據來進行的,這個過程中存在的誤差通過確定松弛系數加以校正。
設一個數據集經過挑選得到的訓練集為{xi,yi},i=1,…,n,xi∈Rn,yi∈{-1,1},則SVM分類器的形式為:

(1)


(2)
對未知樣本進行測試的誤差上限為:

(3)
上式表明,支持向量的個數越少,誤差越小。
1.5.3 徑向基神經網絡
1980年Powell引入RBF神經網絡的概念[16]。RBF神經網絡有輸入層、輸出層和隱含層。輸入層為感知單元,是網絡內外的橋梁。徑向基函數作為隱藏單元構成隱藏層,完成非線性變換。輸出層負責做出響應。
RBF神經網絡的基礎是函數逼近理論。插值是函數逼近的重要組成部分。創建2個集合{xi∈Rn|i=1,2,…,N}和{di∈R1|i=1,2,…,N}。前者有N個不同點,后者有N個實數。映射Rn→R1構成函數F使得:
F(xi)=di。
(4)
RBF神經網絡的目的是選擇一個F滿足:

(5)
{υ(||x-xi||)|i=1,2,…,N}為N個任意函數;||·||為范數。υ為徑向基函數,xi∈Rn為函數的中心。
給定T={(xi,d1),…,(xN,dN)}∈RN×R1,將式(4)帶入式(5),構成下列方程組:

(6)
υji=υ(||xj-xi||),j,i=1,2,…,N。
元素為υji的N×N階矩陣為非奇異陣時,存在唯一解[17]。
RBF神經網絡具有訓練方式簡單易學、收斂快、對非線性函數的擬合效果好等特點。
1.5.4 線性判別分析
線性判別分析是由Fisher在1936年提出的。將多維數據投影到一個方向上,使得所有數據在這個方向上滿足類與類之間擁有最大距離。而同一類樣本數據的類內距離最小。使數據的分類分離效果最好。既壓縮了維數,又提取了特征。線性判別方法常用于人臉識別,圖像分類和森林覆蓋率等方面的問題研究。
2 結果與分析
2.1 樣品近紅外光譜
300份胡椒的光譜見圖1。

圖1 樣品近紅外光譜圖Fig.1 Near infrared spectra of the samples
由圖1可知,原始光譜在波數8334,6862,5182,4734,4326,4007 cm-1附近有明顯吸收峰。其中8334,4734,4326 cm-1處的吸收峰可能是由C-H基團的合頻、二倍頻和三倍頻吸收造成的。因為O-H伸縮振動的二倍頻區域在6700 cm-1附近,H2O的一個合頻吸收區在5155 cm-1附近,因此6862,5182 cm-1處的吸收應該是胡椒中的水分引起的。水分含量越高的樣本其反射率越低,吸光度越高。全光譜范圍內的吸光度可分為3個階梯,依次是12000~6800,6800~5200,5200~4000 cm-1。光譜較為平緩,波峰較寬,且吸收強度較弱。譜圖趨勢大致相同,說明不同產地胡椒的組分大致相同,曲線的差異主要是不同產地胡椒主要成分的含量差異所致。由圖1中還可以看出,由于光譜特征信息重疊較多,樣品的特征值無法根據峰位等直接得到。所以,需通過化學計量學方法進一步提取有效光譜信息,實現胡椒的產地鑒別。
2.2 光譜預處理
圖2中a~f為6種較有代表性的預處理方法下的光譜曲線。






圖2 不同預處理方法下的光譜曲線Fig.2 Spectral curves with different preprocessing methods
由圖2可知,所有預處理方法都明顯減弱了散射的影響。預處理后的光譜曲線更為平滑,波形的特征尖峰點沒有改變。對比發現,經過基線校正、SNV、基線校正結合MSC、基線校正結合SNV以及sym5小波分解后的數據與原始數據在譜線趨勢上保持高度一致。而非線性趨勢消除(DET)處理后的數據與原始數據在譜線趨勢上有明顯差異。基線校正是一種對原始光譜值減去最小值處理的方法,所以在譜線變化及數值分布上最接近原始數據。對于連續性較好的信號,sym5小波在已選的4種小波方法中去噪效果較好。
進一步探究不同預處理方法的預處理效果,對全譜數據建立PLSDA模型,結果見表1。

續 表
由表1可知,在單一的預處理方法中,除了數據歸一化和非線性趨勢消除外,其他單一預處理方法的模型精度都明顯高于原始光譜模型精度。基線校正與SNV對光譜數據的預處理都大大提高了模型精度。在校正集和內部驗證集中,兩種方法得到的相關系數與均方根誤差非常接近。但是在預測集中,基線校正的參數要好于SNV。在基線校正與MSC及SNV組合的兩種預處理方法中,校正集的相關系數并沒有明顯提高,而內部驗證集與預測集的相關系數相較于原始數據模型有了明顯下降,且內部驗證集與預測集的均方根誤差有了明顯上升。原因可能是該方法在消除隨機噪聲的同時濾掉了部分有用信息。在眾多預處理方法中,小波分解去噪法的模型精度普遍高于其他預處理方法的模型精度。在校正集與預測集中,小波去噪預處理后的模型均方根誤差低于0.01。其中db5小波預處理后的模型精度最佳。綜合考慮,本研究選擇基線校正與小波分解去噪法作為最佳預處理方法進行分類建模。
2.3 產地鑒別
采用Kennard-Stone算法從300份胡椒樣品中選取225份樣品作為校正集,剩余75份樣品作為預測集。必須保證225份樣品中有海南45份,云南30份,廣西24份,越南66份,馬來西亞60份;75份樣品中有海南15份,云南9份,廣西8份,越南23份,馬來西亞20份。海南、云南、廣西、越南、馬來西來的編號分別為“1”、“2”、“3”、“4”、“5”。對挑選出的基線校正、sym5小波、db5小波、haar小波和bior1.1小波分解預處理后的光譜數據進行PCA降維,選擇合適的主成分數,分別建立SVM、LDA、RBF 3種產地鑒別模型。經過RBF神經網絡建立產地鑒別模型的分類結果見圖3。


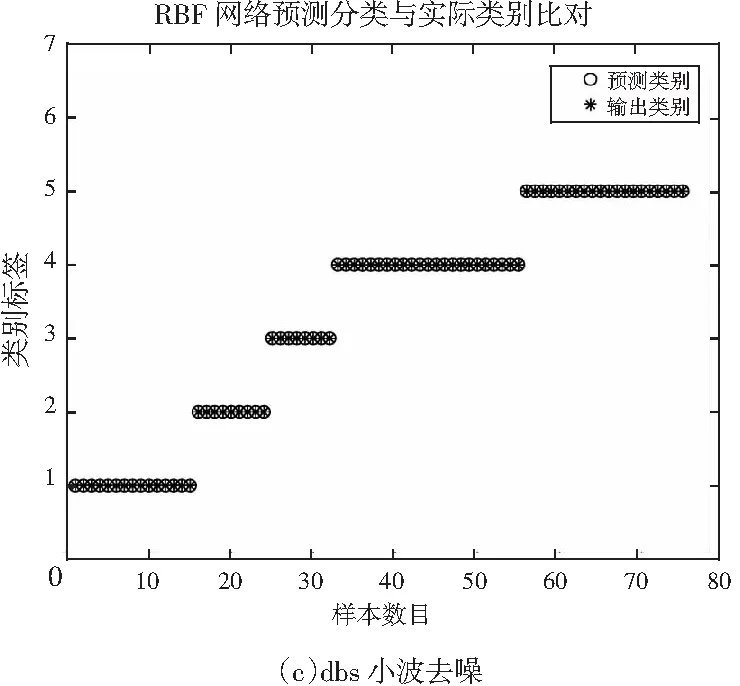

圖3 RBF神經網絡定性鑒別結果Fig.3 The qualitative discrimination results of RBF neural network
圖3(a)為原始光譜未進行預處理的RBF神經網絡鑒別結果。預測集中15個海南白胡椒樣本出現了4個偏差,9個云南白胡椒樣本出現了2個偏差,8個廣西白胡椒樣本出現了2個偏差。鑒別準確率為(75-8)/75=89.33%。
圖3(b)為基線校正后的RBF神經網絡鑒別結果。預測集中15個海南白胡椒樣本出現了1個偏差,9個云南白胡椒樣本出現了1個偏差,8個廣西白胡椒樣本出現了1個偏差。鑒別準確率為(75-3)/75=96%。
圖3(c)為db5小波去噪預處理后的RBF神經網絡鑒別結果。預測集中75個樣品沒有預測偏差。鑒別準確率為100%。
圖3(d)為haar小波去噪預處理后的RBF神經網絡鑒別結果。預測集中20個越南胡椒樣本出現了1個偏差。鑒別準確率為(75-1)/75=98.67%。
不同預處理方法下分別采用SVM、LDA、RBF 3種建模方法對胡椒產地鑒別分類的結果見表2。

表2 不同光譜預處理的胡椒產地分類結果Table 2 The classification results of the places of origin of pepper with different spectral preprocessing methods
在全光譜范圍內,預處理方法不同,建模效果也有所差異。在無預處理的情況下,對數據進行PCA降維,最佳主成分數為17,3種模型中最佳分類模型為SVM,準確率達到96%。原始光譜采用基線校正與sym5等4種不同小波預處理后,經過PCA降維選出各自最佳主成分數進行建模。其中SVM模型和RBF神經網絡模型的鑒別準確率均大于或等于原始光譜鑒別模型的準確率,而LDA鑒別模型的準確率有所降低,可能是在壓縮維數的同時提取的特征有所不足導致的。基線校正和db5小波去噪后的光譜數據經PCA降維后建模分類效果較好,最高達到100%。其中db5小波僅選擇了7個主成分,大大減少了數據處理的復雜性。總體來看,支持向量機模型分類效果優于LDA模型與RBF神經網絡模型。
3 結論
采用SVM、LDA和RBF神經網絡建立了胡椒樣品產地的定性鑒別模型。未對光譜進行預處理時,3種模型的正確率最高為96%。通過基線校正與小波分析的方法對光譜進行預處理并通過PCA對數據降維后,SVM和RBF神經網絡模型鑒別準確率均有明顯提升,最高達到100%。db5小波預處理后僅選擇7個主成分正確率達到100%的數據。分析表明,基線校正與小波去噪能夠明顯改善胡椒判別模型的準確率。因此,基于近紅外光譜的胡椒產地鑒別方法是可行的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
