基于Web的地形匹配系統設計與開發
2019-05-27 08:23:22宋敦江2
計算機測量與控制 2019年5期
關鍵詞:系統
高 香,宋敦江2,梅 新
(1.湖北大學 資源環境學院,武漢 430061; 2.中國科學院科技戰略咨詢研究院,北京 100190)
0 引言
地理信息系統 (GIS,geographic information system),遙感(RS,remote sensing)以地理信息資源和測繪數據等為基礎數據[1],包括大量的航空航天圖片,遙感影像, 地形圖以及各尺度的DEM(digital elevation model)數據。這些地理信息基礎數據具有與其它數據不同的特性,拓撲關系強,具有自相關性,而且數據量龐大,計算復雜,處理困難。國內外學者將機器學習(Machine Learning)和深度學習算法應用于各領域大數據處理、分析,獲取有用信息[2]。例如運用圖像模式識別來進行大數據挖掘,構建大數據智能地質學[3]。
圖像匹配技術是圖像處理、分析的重要內容,其結果的精度與可靠性直接決定了后續工作能否正常進行。圖像匹配它是根據目標的特殊特征,按一定相似性準則,建立未知圖像與已知圖像之間的匹配[4]。隨著社會信息化程度逐漸提高,計算機存儲和計算能力大幅度提升,深度學習技術和方法在飛速發展,圖像匹配技術也趨于成熟,圖像匹配是幾乎所有圖像分析過程中的關鍵組成部分。圖像匹配成功應用于例如導航、指導,自動監視,計算機視覺、繪圖科學、無人駕駛、醫學診斷交通監控等領域[5]。
地形匹配是圖像匹配的一種,在遠程巡航導彈導航、潛水器導航,飛機航行跟隨、地形回避,模式識別,地理定位,目標跟蹤等領域具有十分重要的作用[6-7]。地形匹配制導自主、可靠、不受干擾、導航精度與航程無關,無需在導航區域建立信號中繼站等基礎設施,它不受氣象條件和其他電子設備干擾等的影響,是GPS導航的一種有效輔助手段[8]。
地形匹配是利用已知地形數據,從基準圖中提取具有不變特征或明顯特征的子區,或者用已知地面控制點作為模板,在所匹配的圖中搜索與模板相似的區域。當兩個地圖的匹配相似性測度達到最大,且超過預先規定的閾值時,判定為找到了正確的匹配位置[9]。在地形匹配過程中,基準地形(假定稱為A)是全國或全球地形,待匹配地形(假定稱為T)是任意一塊具有明顯地形特征的地形,地形匹配就是要在A中進行搜索或進行特征匹配,確定T在A中的位置,包括中心點坐標和邊角拐點坐標。與地形匹配相關研究一般運用三維表面匹配算法、計算機視覺技術[10]來確定基準地形A內恢復待匹配圖形T的位置和方向。但到目前為止卻很少有基于深度學習來進行地形匹配的相關研究。
盡管圖像匹配技術發展快速,地形匹配相關研究也很多,但運用深度學習進行地形匹配相關研究卻很少。將地形匹配數據,相關匹配算法進行系統集成可以使地形匹配流程系統化,能夠對地形圖進行快速匹配、更新。但由于地形數據數據量大,計算復雜,不能僅依賴于 CPU的計算,CPU+GPU 的硬件框架更能滿足實際需求,由于GPU服務器租用昂貴,從經濟因素與算法安全性因素出發,本文嘗試GPU服務器和WEB服務器分離相互獨立的做法。本文研究基于Java開發的地形匹配Web系統,運用當今互聯網、云計算等技術優勢搭建的分布式在線處理系統,解決了本地系統或局域網環境系統下的專業模型或處理算法在互聯網上的應用,提供了更廣泛的共享[11]。同時,該架構采用了消息調度概念及應用模式,對地形匹配算法進行了封裝,復用了已有的地形匹配算法,開發效率大大提高。該系統托管在阿里云服務器中,它通過消息傳遞機制與另外一臺GPU服務器進行通信,實現GPU地形匹配計算與地圖網站的功能分離,增加了系統的可擴展性,方便進一步的升級。
1 地形匹配服務的架構設計
已有全國地形數據A(30米分辨率的DEM),對現有區域的地形等高線(數據A)(contourA.shp),任意切割一個方形區域得到子集等高線數據B,對數據B進行平移和旋轉得到數據C,對數據C隨機加入噪音得到數據T(contourT.shp)。地形匹配服務目標實現上傳數據T,恢復或匹配、查找后確定數據T在數據A原始位置,并反饋匹配結果。考慮算法的復用性,以及進一步的改進與升級,地形匹配服務在架構設計時,采用基于“消息/訂閱”模式的消息調度模式[12],對地形算法庫進行了封裝,將網站平臺模塊,消息隊列傳遞模塊等與地形匹配算法進行分離,相互獨立運行工作,通過消息隊列服務器建立網站與算法之間的通信,構建了地形匹配服務體系。如圖1所示。
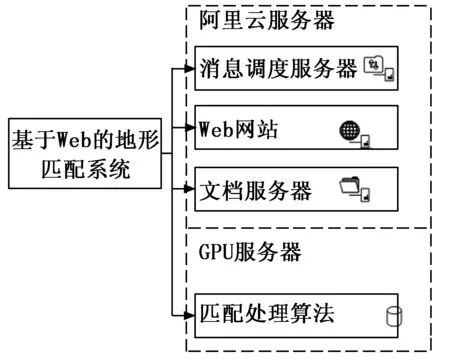
圖1 地形匹配服務架構體系
如圖1所示,地形匹配系統整個服務架構體系分為Web網站、消息調度服務器、文檔服務器、匹配處理服務四部分,其中Web網站、消息調度服務器、文檔服務器部署于阿里云服務器中,匹配處理算法部署于局域網環境。其中Web網站負責整個系統的前端的顯示以及交互操作,消息調度服務器、文檔服務器負責門戶網站與地形匹配算法服務的溝通,匹配算法部分負責地形匹配運算。整個系統采取松耦合的模式,彼此之間保持相對獨立性。
Web網站模塊主要是網頁部分,負責為用戶提供系統應用界面,用戶通過操作Web網站輸入待匹配地形圖片,執行匹配命令,網站獲取地形匹配信息,發起執行操作,最后接收匹配處理后結果,并儲存到Web網站數據庫中。
消息調度服務和文檔服務器模塊負責門戶網站與地形匹配算法服務的溝通。消息隊列調度服務[13]可以簡單的理解為系統各部分之間建立聯系的“橋梁”,它通過隊列的方式實現各模塊之間的消息傳遞,屬于系統的中間組件,它將數據與計算進行分離,確保了數據的獨立性,提高了算法的重用性,便于后期算法的完善。文檔服務器提供了消息監聽機制,后臺匹配處理接收消息調度服務器發送的處理請求,進行數據從阿里云文檔服務器上下載。
匹配處理服務模塊主要負責地形匹配算法的實現,匹配處理后臺需要集成消息隊列接收處理消息,包括文件名和數據庫此數據的id號。通過FTP服務器(File Transfer Protocol Server)下載對應save_name的數據,執行匹配處理,然后通過Web網站API將數據結果及狀態寫入到數據庫表中。
2 地形匹配系統的實現
2.1 軟件環境搭建
網站部分通過Java 體系開發,采用 Play框架, 消息隊列采用Rabbitmq服務器,后臺空間匹配采用Python開發語言。考慮系統的安全性以及算法的重要性,消息調度服務器,Web網站和FTP服務器部署在阿里云上,后臺匹配算法部署在局域網內。系統實現流程圖如圖2所示。

圖2 系統實現流程圖
如圖2所示,在阿里云CPU環境中安裝系統依賴軟件,并搭建Web網站,配置相關環境,在本地GPU環境中進行地形匹配算法的訓練,以及地形匹配算法封裝及應用,并配置相關環境。系統相關依賴軟件如表1所示。
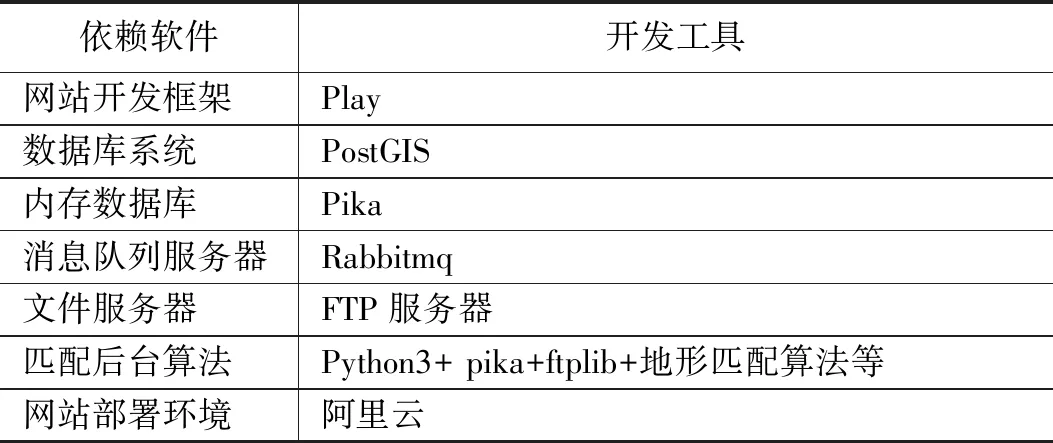
表1 系統開發平臺工具
如表1所示,系統開發網站選擇了play開發框架、 Postgis數據庫、Pika內存數據庫、Rabbitmq消息隊列服務器、FTP服務器、后臺算法地形匹配算法使用python3語言開發、網站部署在阿里云環境中。
Play框架(http://www.playframework.com/),它是開源Web框架,相比于其他框架,靈活性高,具有熱重載(hot reload)[14]特性,修改代碼,可直接刷新頁面顯示效果,無需重新構建,使用Play框架開發,可以快速搭建網站,大大提高了系統的開發效率。
PostGIS數據庫是對象關系型數據庫系統 PostgreSQL(https://www.postgresql.org/) 的一個擴展,能夠有效的對空間數據進行管理與處理,地形數據屬于空間數據的一種,為了便于存儲空間數據的空間位置、空間關系,選用了PostGIS數據庫。
Rabbitmq(http://www.rabbitmq.com/)是開源消息傳遞中間組件,可在多平臺,多操作系統中運行,具有可靠性,使消息和消息隊列具有可恢復性,消息隊列調度服務機制進行數據的傳遞,將數據與后臺算法進行分離,確保了數據的獨立性,提高了算法的重用性[15]。
Ftp服務是通過Internet利用FTP服務器和FTP客戶機實現的是一種高效可靠的文件傳輸服務,客戶端進行FTP會話,服務器與客戶端之間連接建立雙向的傳輸文件的連接,實現計算機與計算機之間實現相互通訊[16]。此系統在阿里云上配置了FTP服務器,建立了后臺匹配處理與前端網站間的數據傳輸機制,后臺匹配平臺接收消息調度服務器發送的處理請求,連接到在阿里云主機上的FTP服務器程序進行數據的下載。匹配處理后將處理后的結果返回給前端網站。
Pika是類似于Redis的一款開源的存儲系統,它的優勢在于Pika 是多線程的結構,因此在線程數比較多的情況下,某些數據結構的性能可以優于 Redis,由于系統需要儲存的為全國范圍內的地形圖,數據量較大,若選擇Redis會因內存過大恢復時間長,而Pika正好解決了用戶使用Redis內存過大恢復時間長的問題。
匹配后臺算法采用Python開發語言,利用深度學習算法對全國地形數據進行訓練,之后模糊匹配,再利用機器視覺方法進行精確定位。pika,ftplib是python的內置的標準模塊,Pika包進行消息接收,ftplib包提供了強大的對FTP服務器的操作,通過它連接并操作FTP服務端使用。
地形匹配系統中消息調度服務器,Web網站和FTP服務器部署在阿里云(https://www.aliyun.com/?utm_content=se_1000301881)上,后臺匹配算法部署在局域網內,具體配置如圖3所示。
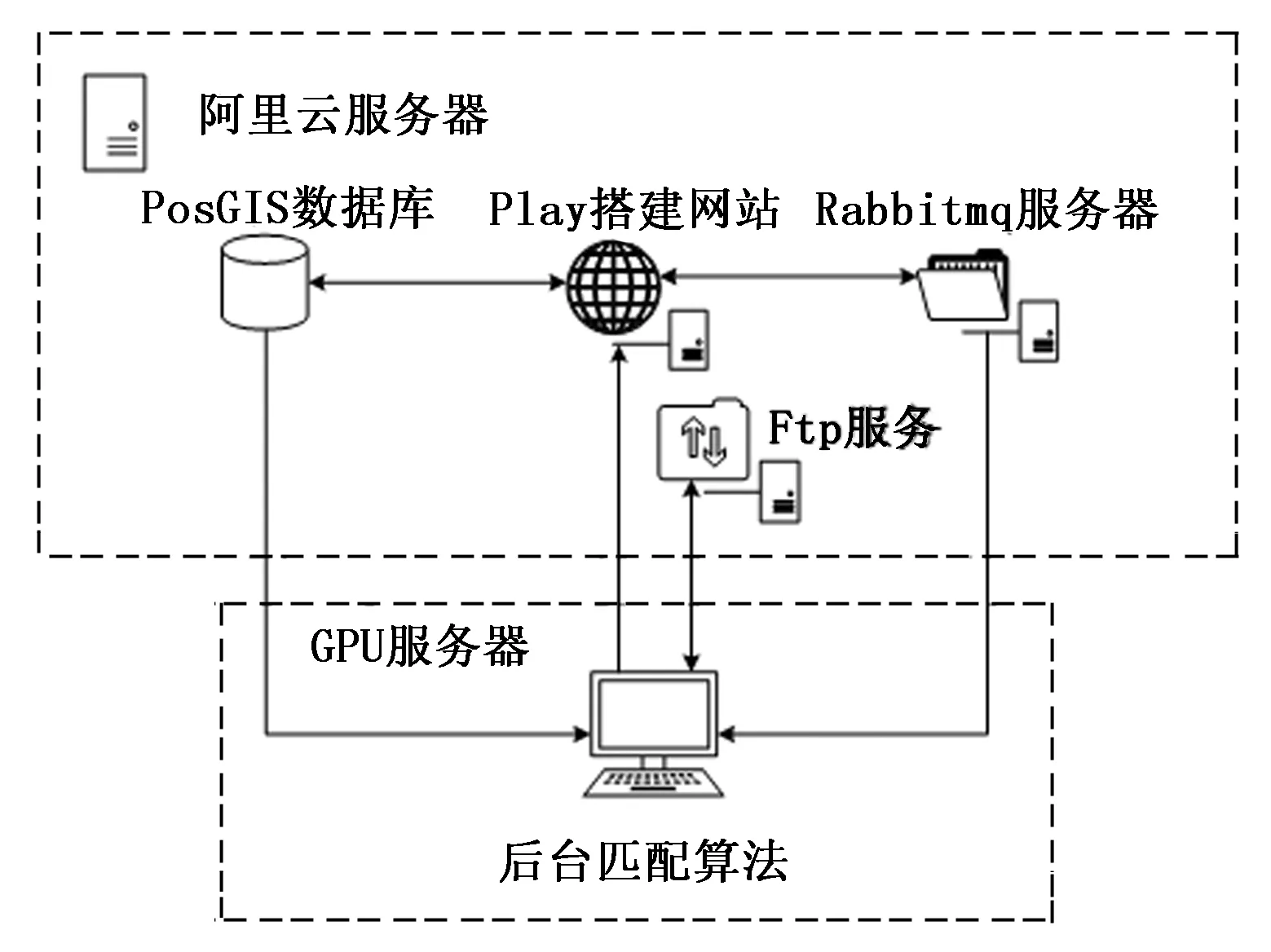
圖3 系統部署圖
如圖3所示,地形匹配系統Web網站部署在阿里云上,遠程登錄阿里云服務器,進行PostGIS數據庫、消息隊列服務器 Rabbitmq、文件服務器 FTP服務等依賴軟件的安裝。并運用Play框架搭建網站,修改配置文件application.conf進行相關服務配置。修改配置信息如下所示:
file_path=["C:zkydataimg"]
save_file_path=["C:zkydataimg"]
mq = ["47.105.32.162"]
file_path為輸入文件路徑,save_file_path為保存文件路徑 mq為阿里云公網IP地址。然后構建消息隊列服務,新建隊列(queue),命名為web_pro1,全國地形數據A存放于PostGIS數據庫中。
接著進行匹配算法運行環境的搭建,在后臺匹配算法中進行Rabbitmq環境配置,在匹配算法中輸入消息隊列登錄名稱,以及登陸密碼和Rabbitmq服務器配置網站url,并進行FTP環境的配置,使后臺匹配算法能夠獲取消息隊列message信息,需包括網站url,獲取時間以及文件名稱。
2.2 地形匹配算法封裝
系統地形匹配的目標是實現輸入任意變換后的地形數據T執行匹配命令,匹配后得到T在全國地形數據A的具體位置。
地形匹配過程分成兩個子過程:
1)第一個子過程是先對總圖A用深度學習的殘差網絡模型(ResNet)進行訓練學習,再進行模糊匹配,找出子圖T在A中的大概位置T’;
2)第二個子過程是利用計算機視覺OpenCV里的尺度不變特征變換(Scale-invariant feature transform,SIFT)方法對T進行精確定位,精確確定T與T’的相對位置。匹配結果示意圖如圖4所示。

圖4 匹配結果示意圖
如圖4中所示T1、T2待匹配地形圖為數據總圖變換后的子圖。P為T1、T2重疊部分,A、P為未重疊部分。
為了便于算法后期的完善和升級,提高算法的復用性,我們對地形匹配算法進行了封裝。匹配算法通過集成消息隊列接收消息體名稱和隊列名稱,獲取處理請求,得到文件名和數據庫此數據的id號。通過FTP服務器下載對應save_name的數據,執行匹配處理,形成標準算法庫。并將處理后的結果通過Web網站API將數據結果及狀態寫入到數據庫表中。
算法庫的封裝,實現了后臺算法與前端網站的分離,后臺匹配算法只負責算法方面的開發,前端網站只需通過消息調度機制與后臺算法建立聯系,提高了匹配系統的效率,以及系統的復用性。
2.3 地形匹配系統頁面設計
地形匹配系統頁面設計遵循簡潔,醒目的原則,主要包括導航欄模塊,地圖顯示模塊,地形圖片輸入模塊,以及執行處理模塊。如圖5所示。

圖5 頁面設計圖
如圖5,頁面右側模塊設計用戶輸入待匹配地形圖,左側設計執行匹配命令按鈕,并顯示匹配信息,中間模塊顯示地圖,并顯示匹配成功結果。
2.4 地形匹配結果輸出
地形數據經過地形匹配算法匹配后,數據的輸出形式為匹配地形圖在參考全國地形數據A上的坐標信息,即四個頂點的經緯度信息,并將坐標信息通過Web數據接口傳送給前端網頁,并顯示在前端網頁地圖中。
2.5 地形匹配處理流程
整個體系系統統分Web網站建設、消息調度服務、后臺匹配處理服務三部分。消息調度服務器,Web網站和FTP服務器在阿里云上部署。空間算法部署在局域網內,用戶通過操作Web網站瀏覽器頁面輸入待匹配的地形圖,執行匹配命令,消息調度機制通過接收Web網站信息將處理請求發送給后臺匹配處理,匹配處理后臺集成消息隊列包括文件名和數據庫此數據的id號接收處理消息,然后通過FTP服務器下載阿里云環境中PostGIS數據庫中對save_name的數據,執行匹配處理,處理完成后,然后通過Web網站API將數據結果及狀態寫入到數據庫表中并在Web瀏覽器頁面中展示。具體過程如圖6所示。
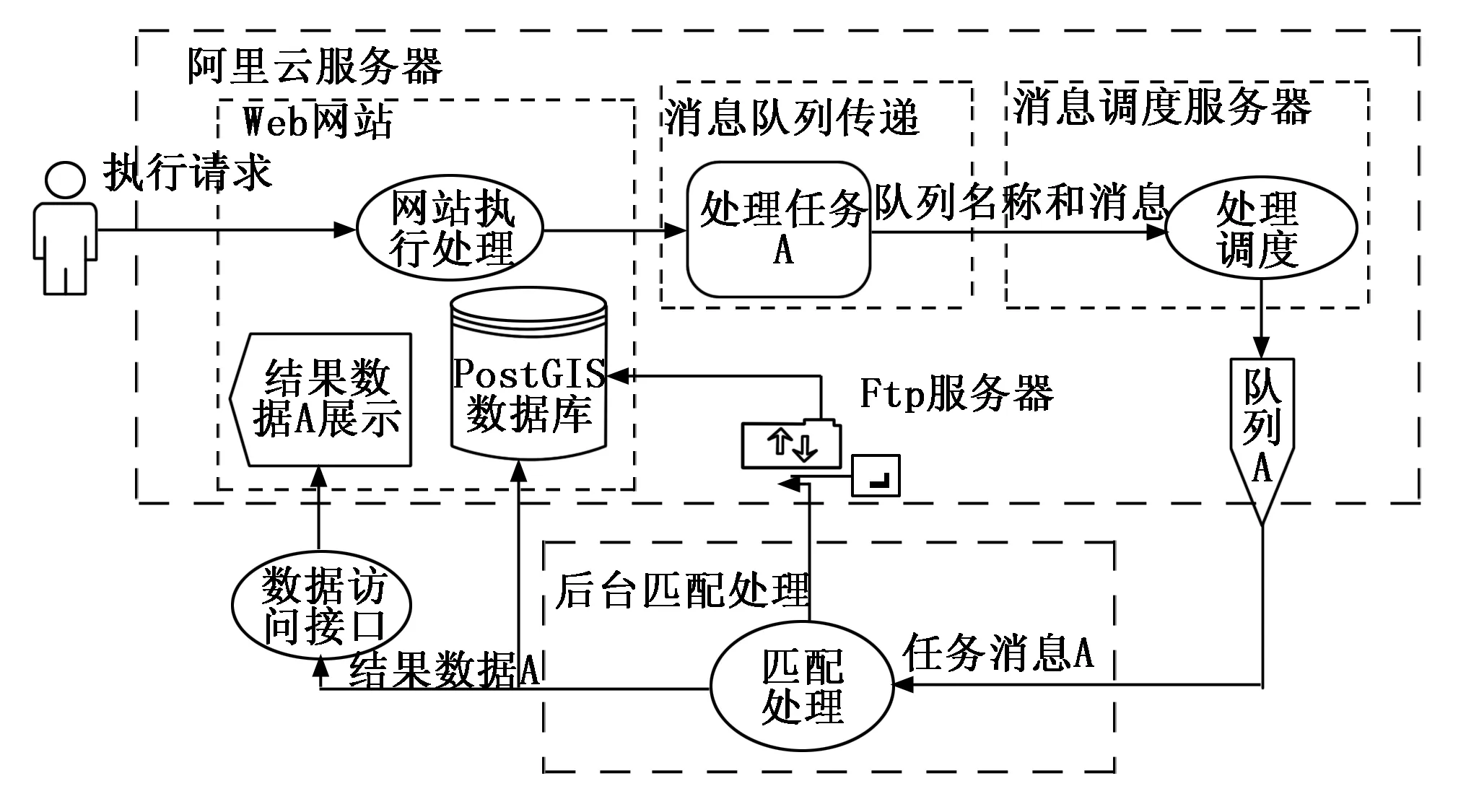
圖6 系統流程圖
3 應用實例分析
3.1 實驗步驟和方法
在實際應用中,構建了基于Web的地形匹配系統,瀏覽器頁面由導航欄,執行處理命令部分,地圖部分,上傳待匹配地形圖四部分組成,用戶通過操作瀏覽器在頁面右側上傳待匹配地形數據,上傳成功后,點擊頁面左側執行命令,通過消息調度服務,后臺匹配算法進行處理,將執行結果在瀏覽器地圖上顯示,如圖 7所示。

圖7 匹配成功結果截圖
圖7中綠色虛線位置即為待匹配地形圖T所在位置。
在地形匹配系統主要實現過程分為:1)樣本數據制作;2)地形匹配算法模型訓練;3)地形匹配算法模型應用。本文重點在于訓練好的地形匹配模型的應用。
在全國地形數據A中隨機提取一方形區域T(300行*300列),并對數據進行旋轉得到37個樣本數據,其中包括18個副本數據,隨機提取160 000批數據,得到實驗數據T約為600萬個樣本數據。
以600萬個樣本數據作為訓練樣本,利用深度學習的殘差網絡模型(ResNet50)進行訓練,進行模糊匹配,隨機選取2 000個樣本數據作為測試樣本測試精度,每個訓練樣本返回10張地形圖,利用計算機視覺OpenCV里的尺度不變特征變換方法對T進行精確定位,利用ResNet50訓練模型,匹配結果精度達到97%。
將訓練好的模型進行封裝,應用到地形匹配系統中。在阿里云CPU環境中,搭建Web網站環境,配置消息隊列服務環境、FTP服務器,以及安裝數據庫系統等軟件。在本地GPU環境部署匹配算法運行環境。首先遠程登錄阿里云服務器,進行PostGIS數據庫、消息隊列服務器 Rabbitmq、文件服務器 FTP服務等依賴軟件的安裝。并通過Java 體系進行Web網站的搭建,然后構建消息隊列服務,新建隊列(queue),命名為web_pro1,然后將全國地形數據A存放于PostGIS數據庫中,之后將封裝好的匹配算法匹配算法部署在本地GPU環境部署中,在匹配算法中進行Rabbitmq環境配置,在匹配算法中輸入消息隊列登錄名稱,以及登陸密碼和Rabbitmq服務器配置網站url,并進行FTP環境的配置,使后臺匹配算法能夠獲取消息隊列message信息,需包括網站url,獲取時間以及文件名稱。
在Web網站中點擊上傳圖片或直接拖拽,將實驗數據T導入到網頁中,點擊網頁左側執行匹配按鈕,通過消息隊列將待匹配信息傳送到后臺,匹配處理后臺需要集成消息隊列接收處理消息,包括文件名和數據庫此數據的id號。通過FTP服務器下載對應save_name的數據,執行匹配處理,計算待匹配地形圖在參考全國地形數據A上的坐標信息,即四個頂點的經緯度信息,然后通過Web網站API將數據結果及狀態寫入到數據庫表中,并將坐標信息通過Web數據接口傳送給前端網頁,并顯示在前端網頁地圖中。
基于Web的地形匹配系統采用了消息調度概念及應用模式,對地形匹配算法進行了封裝,復用了已有的地形匹配算法,實現GPU地形匹配計算與地圖網站的功能分離,增加了系統的可擴展性,方便進一步的升級。
但系統同時存在不足,例如地形匹配過程中上傳地形數據必須和數據庫中全國地形數據A同一比例尺才能進行匹配。
3.2 實驗數據基礎
系統匹配數據為全國地形數據A(30米分辨率的DEM ),共計約1000塊,每塊空間范圍為108 km*108 km(3 600行*3 600列),存放在postgis數據庫中。
待匹配實驗數據T由Web網站輸入,是從全國地形數據A隨機提取一方形區域T(300行*300列)得到數據B,數據B經過旋轉、平移等得到實驗數據T。
4 總結及展望
文章研究構建了基于Web的地形匹配系統, 對匹配算法進行了封裝,Web網站通過消息調度服務器建立于后臺匹配之間的信息傳遞與溝通,三部分分工合作,極大的提高了系統開發效率,匹配算法基于深度學習的地形匹配(Deep Learning-based Terrain Matching, DLTM),匹配樣本來自于數據集任意一塊旋轉,變換,加噪后的子集。相比于其他地形匹配研究,文章有如下優點:
1)文章將機器學習運用于地形匹配算法之中,并對算法進行了封裝,可直接調用。
2)文章將地形匹配數據,相關匹配算法進行系統集成,使地形匹配流程系統化,能夠對地形圖進行快速匹配、更新。
3)文章將GPU地形匹配計算與地圖網站的功能分離,將消息調度服務器,Web網站和Ftp服務器部署在阿里云服務器,匹配處理算法部署于局域網環境內本地GPU服務器中,極大的降低了租用GPU服務器的成本,同時確保了數據的獨立性,提高了算法的重用性,便于后期算法的完善。
但文章中地形匹配算法無法應用于不同尺度地形數據的相互匹配和多分辨率的地形匹配。今后將對不同尺度地形數據的相互匹配、解決多分辨率的地形匹配、基于切割等高線方法的地形匹配、基于地學信息圖譜的地形分類、輔助地形匹配、全球影像的自動定位等問題進行研究。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
