基于隨機森林算法的恩施市用水量預測
2019-05-27 09:57:58鄔述飛
陜西水利 2019年4期
關鍵詞:模型
鄔述飛,劉 遠,金 鍇
(湖北省恩施土家族苗族自治州水文水資源勘測局,湖北 恩施 445000)
0 引言
用水量是區域生產生活、生態環境用水的總度量,準確掌握用水情況,對合理調配、科學管理水資源尤為重要[1~2]。恩施位于湖北省經濟、人口、水資源密集地帶,但近幾年來隨著工業化發展區域用水需求增加,起用水結構也隨著發生改變。鑒于此,本文擬以恩施地區為案例,闡釋基于隨機森林算法的用水量預測模型構建與方法有效性,并為區域水資源規劃與管理提供參考依據。
1 隨機森林算法
隨機森林(Random Forest,RF)是Breiman等[3]提出的集成多棵決策樹(Decision tree)模型{h(X,θk),k=1,2,…,}而形成的融合算法。該算法借助隨機子空間和自助聚集理論,運用bootstrap方法從全部特征變量屬性中進行隨機等概率地放回抽樣,對每個bootstrap樣本構建決策樹,通過打分尋找得分最高結果作為分類或回歸的結果[4]。該算法主要流程為:
先利用bootstrap隨抽樣法從原始訓練集T={(x1,y1),(x2,y2),…,(xn,yn)}中抽取n個樣本,記作訓練集Tt,進行k次抽樣,則有k個獨立樣本形成的訓練集。
然后對各bootstrap訓練集構建回歸決策樹組合模型,單樹由根節點遍歷向下分裂,使其自由生長而不剪枝處理,k棵樹集成即為隨機森林。對于單棵樹,從隨機選擇的m個屬性中選出最優屬性進行分裂。
生成的單棵樹模型即為獨立領域的專家,組合k棵樹中得分最高的類別即為預測的結果。RF回歸預測結果表示為k棵回歸模型的預測結果是k棵決策樹{h(X,θi,i=1,2,...,k)}回歸的均值:
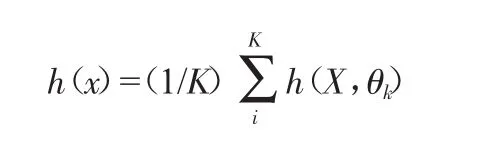
式中:P(x)為隨機森林組合模型結果,pi為單棵樹分類模型,I為指示函數,Y為輸出變量[5]。
2 應用實例
2.1 恩施用水量預測變量選取
用水量主要受供水量、用水需求的制約,其中供水量的直接影響因素有水資源總量、降水量等,用水需求則體現為水資源供應對人口、經濟發展的承載。在借鑒前人研究的基礎上[6],綜合考慮恩施市人口、經濟、水資源環境等三方面因素,確定用水量預測模型的解釋因子,依次為:總人口數(萬人)、水資源總量(億 m3)、人均水資源量、d.GDP(億元)、單位 gDP 耗水量、第一產業占GDP的比重(%)、有效灌溉面積(千hm2)、城市人均日生活用水量(L)、農業人口數(萬人)、第一產業用水總量(億m3)、第二產業用水總量 (億m3)、第三產業用水總量 (億m3)、降水量(mm)。指標數據的時間域為2000年~2015年,從《恩施統計年鑒》(2001~2015)、《恩施市水資源公報》(2000~2015) 中提取指標原始數據。
2.2 基于隨機森林的用水量預測模型構建
2.2.1 變量設置與參數優選
選取的13個變量分屬不同量綱,不具可比性且其絕對數值差異較大,出于預測模型精度的考慮,將其進行歸一化處理[7]。將所有樣本數據劃分為兩部分,2000年~2010年的數據為訓練樣本,2011年~2015年的數據為檢測樣本,兩類樣本中解釋變量作為輸入值,用水量數據作為輸出值,在RStudio1.0平臺上調用randorForest程序包進行編程實現,樣例代碼參見[8]。
2.2.2 預測結果與精度比較
圖1和表1分別為RF算法計算得到訓練樣本和測試樣本的預測結果。為比較算法優越性,另使用RBF、SVM實施建模預測。依圖1可知,3種不同算法均能夠較好擬合用水量變化,對訓練樣本各年份用水量預測的相對誤差介于-0.372億m3~0.464億m3之間,表明訓練模型精度可靠。2000年~2010年恩施市用水量總體呈上升趨勢,而于2003年用水量較之于往常年份有所降低,對這種局部異常 (圖1-a、1-b),SVM和RBF算法未能準確模擬,RF模型則能夠通過各解釋變量變化特征捕捉到這一細節變化。訓練模型統計顯示,RF、SVM、RBF訓練模型的平均絕對誤差依次為0.78%、0.89%、0.67%。測試結果表明,基于RF的預測結果最優,其平均絕對誤差僅為0.94%,而基于SVM和RF的預測結果的平均絕對誤差分別為1.15%、1.58%。綜合來看,基于RF的用水量預測模型精度高、預測效果良好,能夠適用于用水量預測建模。
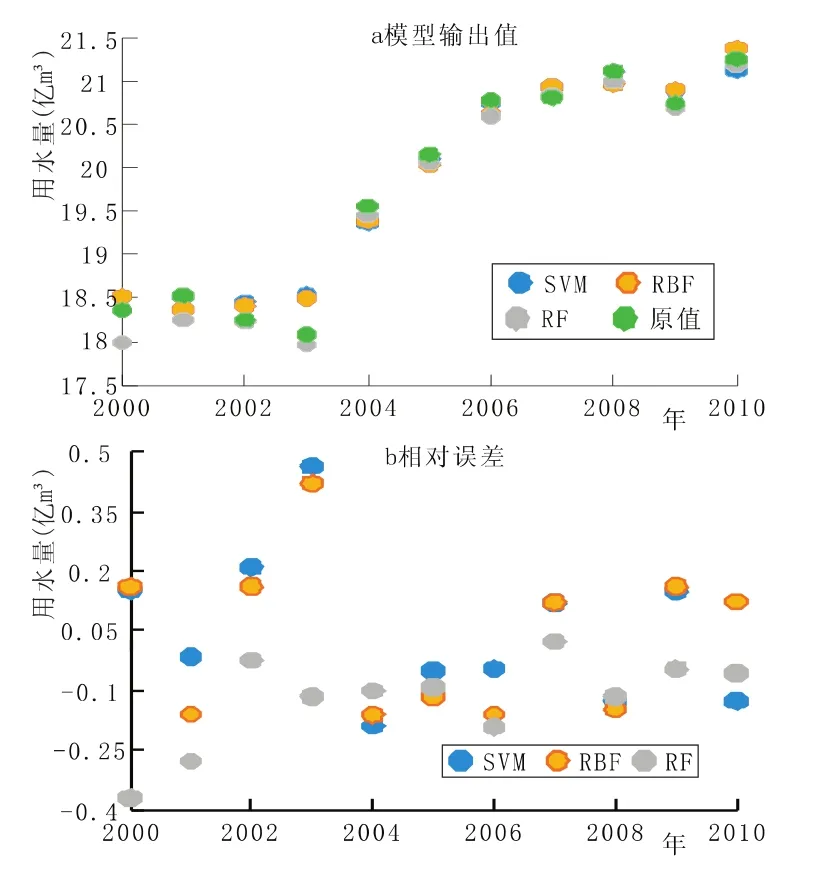
圖1 三種預測模型訓練精度對比
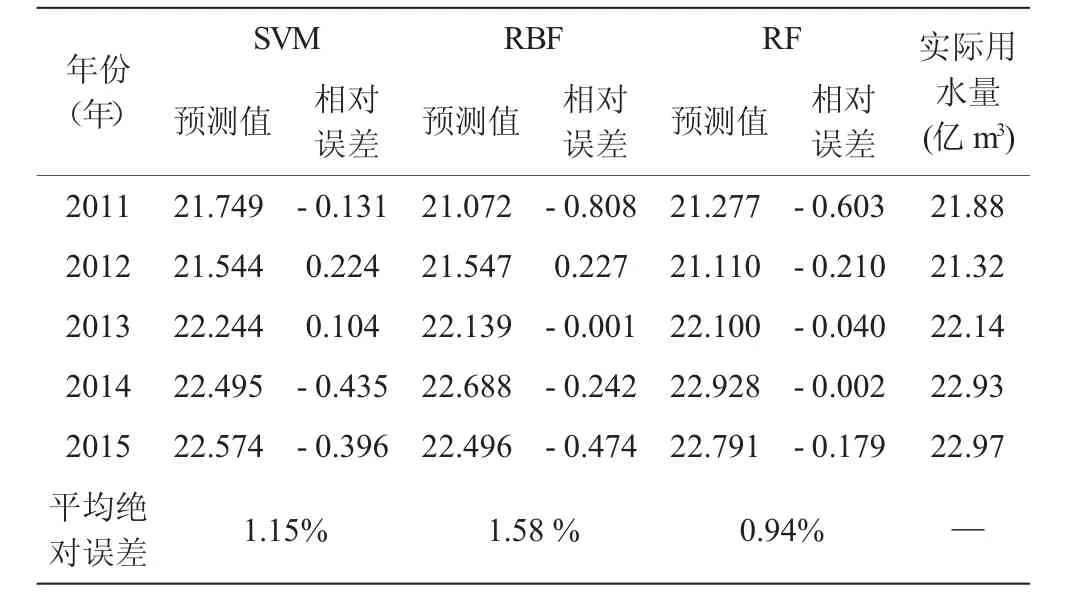
表1 三種模型測試精度與相對誤差
2.2.3 解釋變量重要性分析
在RF的每棵樹中,使用隨機抽取的訓練自助樣本構造決策樹,并計算未選擇數據即袋外數據(Out of bag,OOB)對模型的性能影響,即袋外誤差,然后隨機對OOB數據全部特征加入噪聲干擾,再次計算袋外誤差,變量重要性為兩次OOB誤差之差經標準化后在所有樹中的平均值,其值越大,表明該變量對模型的重要性越大[9]。應用randomForest程序包中的importance函數獲取重要性分值(圖 2),可知農業人口數(萬人)、總人口數(萬人)、城市人均日生活用水量(m3)的分值最大,依次為達4.48、4.05、4.04,表明其對模型精度具有重要影響;第三產業用水總量、GDP(億元)、第一產業占GDP的比重(%)、單位GDP耗水量、第二產業用水總量(億m3)、第一產業用水總量(億m3)的重要性分值介于2.93~3.93之間,它們對模型精度的影響次之;其他變量的重要性分值僅為0.083~0.072左右,表明其對模型精度貢獻較差,在后續建模中應予以替換。
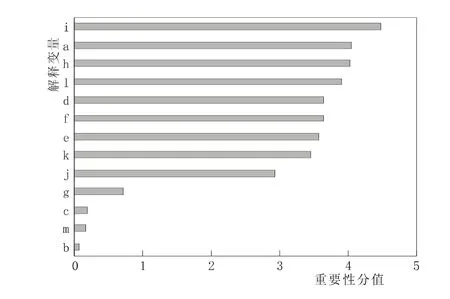
圖2 解釋變量的重要性
3 結論
隨機森林算法能夠較好地擬合2000年~2015年恩施市用水量變化,訓練誤差與預測誤差均較小,表明該模型具有一定應用價值。用水量預測模型受多維因子共同制約,隨機森林算法能夠排除多維因素非線性的影響,并輸出各因子對模型精度的影響荷載,這對于預測因子的篩選和模型精度提高具有重要意義。基于隨機森林算法的用水量預測模型較于傳統RBF和SVM算法的精度高,泛化能力強,具有一定優越性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
