重尾估計在金融數據中的應用
2019-06-03 03:39:38陳海龍黃飛謝晟
哈爾濱理工大學學報 2019年2期
陳海龍 黃飛 謝晟


摘 要:重尾分布是存在于許多高頻時間序列的邊緣分布,而且在尾部存在著大量的信息。基于重尾分布尾指數估計的Hill估計方法提出優化改進的AvHill估計方法,該方法成功地降低了Hill估計的方差。同時,融合矩估計方法和最大似然估計方法的思想,給出重尾評測的MM估計,其在漸近方差上也低于Hill估計。基于理論仿真隨機獲取的1 000個數據進行評測方法的比較分析,Hill估計、AvHill估計和MM估計在的測試中表現了各個估計的穩定程度并在不同的數據容量中表現出了不同的優點。針對股票數據的漲跌絕對值的測試中,將3種方法進行綜合運用估計,通過對3種估計方法的交點進行數據上的分段,可發現各種估計方法在不同的數據容量中的優缺點以及各種估計方法的優缺點。
關鍵詞:重尾估計; Hill估計; AvHill估計; MM估計; 股票數據
DOI:10.15938/j.jhust.2019.02.014
中圖分類號: TP399
文獻標志碼: A
文章編號: 1007-2683(2019)02-0096-07
Abstract:There exist many marginal distributions of high frequency time series data in the Heavytailed distribution which stores a great deal of information in its tail. Based on the Hill's estimator which is the classic in the Heavytailed index, the AvHill's estimator is proposed and AvHill's estimator successfully reduce the variance of the Hill's estimator. The MM estimator is proposed which is based on the moment estimator and the maximum likelihood meanwhile and it also reduces the variance of the Hill's estimator. Based on the theoretical simulation in the 1000 data and compare the data, Hill's estimator , AvHill's estimator and MM estimator express their own advantage in the different data capacity and degree of stability. We use Hill's estimator , AvHill's estimator and MM estimator to estimate the absolute value in the up and down of the stock data. We find the data segment using the intersections of the curves of the three estimators to reflects the function and the advantage of the three estimator in the different data segment.
Keywords:Heavy tailed estimation; Hill's estimator; AvHill's estimator; MM estimator; stock data
收稿日期: 2017-04-14
基金項目: 黑龍江省自然科學基金(A201301); 哈爾濱市科技創新人才研究專項資金(2017RAQXJ045).
作者簡介:
黃 飛(1990—),男,碩士研究生;
謝 晟(1994—),男,碩士研究生.
通信作者:
陳海龍(1975—),男,博士,教授,碩士研究生導師,Email:hrbustchl@163.com.
0 引 言
重尾分布現像經常出現在金融、氣象學、經濟等領域的研究中,尤其是高頻時間序列數據的邊緣分布。現實生活中所遇到的大量非高斯信號或噪聲也具有顯著的尖峰脈沖特性[1],通常這種情況下并不符合高斯分布的假設,而且該種信息不能用簡單的線性模型進行描述[2]。許多研究也表明,金融資產價格、保險索賠、網絡流量以及許多人類行為現象不滿足正態分布假設,而是服從重尾分布[3]。唐笑通等在對著名的ON/OFF模型進行研究后指出,聚合流量的突發性由ON和OFF周期的重尾分布引起的[4]。后來的學者發現高額的金融資產收益率不是正態分布而是重尾分布的,正態分布的假設將會導致嚴重低估的極端情形下的內在風險。在現實生活中,極端的情況(如巨額虧損和巨額盈利)發生的概率要遠遠高于標準正態分布所顯示的概率。極端情況往往會帶來巨額風險,2015年的股票暴跌帶來的嚴重后果充分地說明了這一點。重尾分布的尾部也存在著大量的信息,若我們忽視這些存在于尾部的信息則會帶來決策上的誤區。若想準確地捕捉極端事件發生的可能性以及通過尾部的信息帶來更直觀的觀察,必須能準確描述分布的重尾程度,即準確地估計重尾分布的尾部指數,我們稱之為重尾指數。
Pareto在1987年提出了Pareto理論以及指出20%的經營往往帶來80%的利潤[5],而且Pareto分布也是一種常用的重尾分布。20世紀,許多學者發現了重尾分布的現象并且提出了許多估計重尾分布尾指數的方法。英國人Gosset的1908年發現了在小分布的數集中的一種特殊的重尾分布——T分布。在1949年,Zipf[6]發現分布具有尖峰厚尾的特點當他在研究日常用的詞匯表時并提出了一種估計方法。1975年,Pickands[7]提出了現在仍在頻繁地應用在重尾指數估計的Pickands估計。Pickands估計有一個缺陷:當它是一致性的估計的時候,它的估計是無窮的。Hill[8]基于最大似然函數提出了Hill估計。其他的學者提出了矩估計,核估計[9]以及更多的其它估計。
自20世紀90年代初期上海和深圳兩個股票交易所建立以來,中國的股票市場已經經過了幾十年的發展。股票作為經濟發展的重要指標,集中體現了國家宏觀調控對股票市場影響的效果。在行為金融學中認為股票名義收益率是不確定的,實際收益率是穩定的,它與市場的擾動是相關的[10]。早在1963年Mandelbort[11-12]就已指出:高額的金融資產是非正態的,是厚尾的。由于金融經濟數據往往具有尖峰重尾的統計特征,難以用高斯分布法擬和,因此近年來重尾序列的研究成為統計學及相關領域的熱點問題之一[13]。李秀敏等[14]在觀察上證指數每日收盤價時也發現股票收益率服從正態分布是不合適的,而且它的分布具有較厚尾部特征。簡志宏等[15]研究了滬深股指,發現其收益序列具有右偏、尖峰厚尾等典型特征。本文根據Hill估計、AvHill估計和MM估計綜合考慮并給出了一種新的綜合估計方法。在模擬實驗中,這種綜合估計方法取得了優秀的模擬效果。綜合估計方法比3種方法中和任何一種的估計更準確,并且將數據進行了分段處理,對每段選擇優勢的估計方法進行估計。并根據數據量的大小進行不同的分段和不同的組合估計。將其應用在股票的漲跌的絕對值中,可以體現出重尾分布估計的優勢,及時發現較大的變動并對以后的漲跌作出合理的估計。
1 極植理論與重尾分布
1.1 極值理論與經典估計方法
隨機現象中的極端事件在各統計領域的應用都是主要研究的方向,極值理論主要研究隨機樣本或隨機過程中極端事件發生的概率及其統計推斷,是研究分布尾部行為的一個重要工具[16]。極植理論也為罕見事件的估計和預測提供了有效的數學工具[17]。對于極值理論來說,最能體現其作用的是如何正確地描述曲線。重尾分布的尾部擁有許多的信息,極值在極值理論當中也占有非常重要的地位。在分析隨機變量的極值問題時常遇到的問題是如何根據經驗確定分位函數,也就是說當真正的分位點在可選擇的函數覆蓋的范圍內被分層的可用數據使用,也就是將數據進行了可易的分配。
在這個表達式里,只有一個未知數,也就是我們常說的重尾分布的尾指數估計。在重尾指數估計中有兩種估計方式:半參數式估計,可以分為Hill估計、Pickands估計以及矩估計;另外一種是基于Pareto分布(GPD)和極值分布的參數估計。在極值理論中,理解理論中的所有尾信息是必要的。正確合理地估計未知數是最為直接的途徑。許多知名的學者在重尾估計領域提出了他們自己的見解并得到了廣泛的使用以及認可。在極值理論中最重要的一個問題就是對形狀參數(極值指標)的統計估計,常用的方法有Hill估計、Picakands估計和矩估計等。在下一節中我們將介紹兩種經典的估計方法以及針對它們的改進方法。
1.2 重尾估計方法優化
1.2.1 Hill估計與AvHill估計
2 仿真及實際系統驗證
2.1 理論仿真
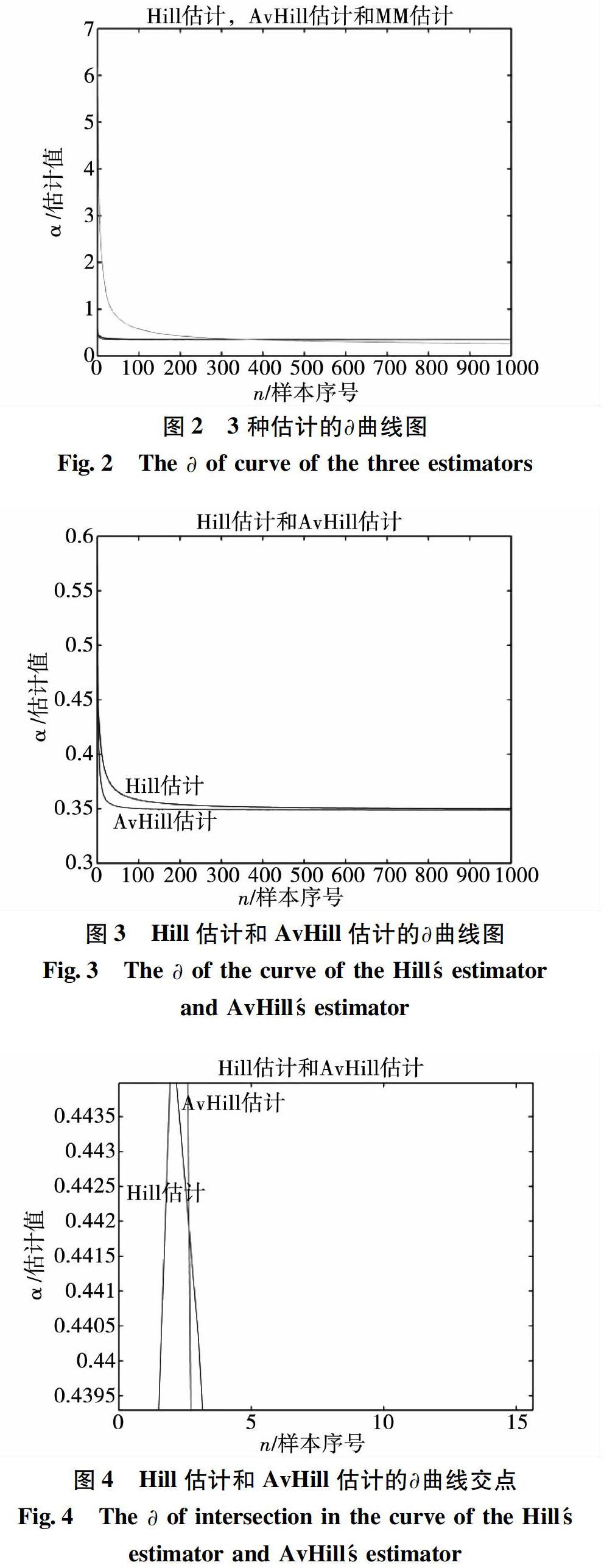
綜上所述,3種估計方法在估計金融數據時各有自己的優勢,故將它們共同應用在高頻的金融數據中。我們模擬人工時間序列并利用Matlab R2014b對3種估計方法進行測試,并對改進的方法進行系統性估計。我們隨機生成1000個0到1之間的獨立同分布變量并將其從小到大進行排列以符合估計的條件。
2.2 實際數據驗證
數據來源于軟件同花順上的上海證券交易所于2005年到2017年的上證指數的漲跌變化量,數據總量為2953個數據量。由于在數據在跌的過程中為負數,故我們將其列為絕對值以更好地對極端事件進行估計。上證指數反映了上海證券交易市場的總體走勢,同時也給我們對股票的漲跌帶來了更好的研究。股票的極端事件往往帶來巨大的收益或者損失,因此我們會著重觀察它的極端事件以此來預防大量的虧損。由于數據過于龐大,故我們將其進行歸一化處理使其范圍在0到1之間并利用Matlab R2014b進行實際數據的驗證。然后根據我們的新的綜合估計方法對該數據進行估計,并且獲取最優的分段估計方法。
上海證券交易所的上證指數的每日變化量均有所有不同,漲為正值,跌為負值,如圖7所示。在圖7中,我們可以看到其值有正有負,且它們的變化量也不盡相同,但是它們的漲跌均不會超過400。極端的情況(如巨額虧損和巨額盈利)會對股市帶來不良的影響,雖然它不經常發生,但是會使股民損失慘重。我們依據其漲跌的絕對值進行數值上的從小到大排序,如圖8所示。圖8顯示數據明顯符合重尾估計的尖峰厚尾現像,故對其進行科學的數值上的估計以期獲得規律性的理論,對未來的發展做出合理的估計。
2.3 模擬分析結果
在模擬的過程中,綜合估計方法取得了良好的估計方法,在各個階段取得了較好的估計值。由于3種估計的優勢點不同,故它們在不同的范圍有不同的優勢,取得的值達到了各個階段的最優。因此在綜合估計上取得了良好的改進方法,比任何一種方法更優秀。當取值不同的時候,可以進行不同的估計方法的組合,并給出相對應的優秀值,使重尾分布得到了良好的估計。在股票數據的實際應用中,該綜合方法也取得了良好的估計方法。雖然在綜合估計中,只分成了兩個階段,但是根據曲線的發展趨勢,如果數據量足夠大時,MM估計的曲線最后會交于一點。在此也足以說明不同的組合方式以及數據量的大小會取得不同的效果,但是它比其中任何一種的單一估計方法都要優秀。在兩個階段,它們在各自和范圍內取得了良好的估計。
3 結 論
本文介紹了兩種經典的重尾估計方法Hill估計和矩估計以及它們的改進方法。在模擬實驗中,Hill估計和AvHill估計的曲線要比MM估計的曲線更早地獲得了比較平緩的曲線。MM估計在數據容量較小時,得到重尾估計值有較大的變化值,但是Hill估計和AvHill估計的變化量趨于穩定。數據量較小時,Hill估計和AvHill估計要優于MM估計。當數據量逐漸增大時,MM估計逐漸表現出了它的優越性并且趨于穩定。在股票漲跌的絕對值的應用中,容量較小時,與模擬數據所得到的曲線相似,Hill估計和AvHill估計要優于MM估計。但隨著數據量的增大,Hill估計和AvHill估計略微優于MM估計。3個重尾估計方法數據容量不同的情況下各有優勢,因此我們可以根據估計方法的優勢與弱點,在不同的范圍內使用不同的估計方式。在金融領域的使用中,我們發現股票的漲跌會給投資者帶來巨大的利益或者巨大的損失。根據不同的時間點帶來不同的漲跌,我們需要制定更合理的股票機制并帶給企業和投資人更好的投資環境。
參 考 文 獻:
[1] 陳海龍, 劉春麗, 由承姬. Alpha穩定分布參數評估及應用研究[J]. 哈爾濱理工大學學報, 2013,18(4):63.
[2] 劉春麗, 邵雷, 陳海龍,等. 標準參數系下Alpha穩定分布隨機變量的產生及仿真[J]. 哈爾濱理工大學學報, 2014,19(3):51.
[3] 王元月, 杜希慶, 曹圣山. 閾值選取的Hill估計方法改進--基于極值理論中POT模型的實例分析[J]. 中國海洋大學學報,社會科學版, 2012(3):42.
[4] 唐孝通, 焦秉立. 通信網絡聚合流量突發性的產生機理研究[J]. 哈爾濱理工大學學報, 2011, 16(2): 29.
[5] Colin S. Gillespie. Fitting Heavy Tailed Distributions: the PoweRlaw Package[J]. Journal of Statistical Software, 2014, 64(2): 1.
[6] ZIPF G K. Human Behavior and the Priciple of Least Effort:an Introduction to Human Ecology[M].Cambridge:Mass,1949.
[7] PICKANDS J. Statistical Inference Using Extreme Order Statistics[J].Annals of Statistics,1975(3):119.
[8] HILL B.A Simple General Approach to Inference About the Tail of a Distribution[J].Annals of Statistics, 1975(3):1163.
[9] CSORGO S.DEHEUVELS P,MASON D.Kernel Estimates of the Tail Index of a Distribution[J]. Annals of Statistics, 1985, 13(3):1050.
[10]史永, 丁偉, 袁紹峰. 市場互聯、風險溢出與金融穩定——基于股票市場與債券市場溢出效應分析的視角[J]. 金融研究, 2013(3): 170.
[11]MANDELBROT B. The Variation of Certain Speculative Prices[J]. Journal of Business, 1963(6): 94.
[12]B.Mandelbrot. New Methods in Statistical Ecnomics[J]. Journal of Political Economy , 1963(71):421.
[13]秦瑞兵, 孟萍. 重尾過程協整檢驗的Bootstrap逼近[J]. 云南民族大學學報: 自然科學版, 2015,24(6):480.
[14]李秀敏,蔡霞。金融市場中極值指標的位移尺度不變估計[J]. 數學的實踐與認識, 2013,43(14):231.
[15]簡志宏, 曾裕峰, 劉曦騰. 基于CAViaR型的滬深300股指期貨隔夜風險研究[J]. 中國管理科學, 2016, 24(9): 1.
[16]劉維廳, 赫英迪, 陳琳. 重尾分布的尾部指數估計及滬深股市實證分析[J]. 數學的實踐與認識, 2011, 6(4): 1.
[17]WAN Huixia Judy, LI Deyuan, HE Xuming. Estimation of High Conditional Quantiles for HeavyTailed Distributions[J]. Journal of the American Statistical Association. 2012,107(500):1453.
[18]RESNICK S, STRIC C. Smoothing the Hill estimator[J] . J Appl. Probab, 1996,33: 139.
[19]DEKKERS A , EINMAHL J , DE Haan L.A Moment Estimator for the Index an Extreme Value Distribution[J]. Annals of Statistics , 1989(17):1833.
[20]FRAGE Alves MI, GOMES M I, DE Haan L,et al. Mixed Moment Estimators and Location Invariant Alternatives[J]. Extremes, 2009(12):149.
(編輯:溫澤宇)
