基于圖嵌入的軟件項目源代碼檢索方法?
2019-06-11 07:40:06凌春陽鄒艷珍林澤琦趙俊峰
軟件學報 2019年5期
關鍵詞:方法
凌春陽,鄒艷珍,3,林澤琦,謝 冰,趙俊峰,3
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(北京大學 信息科學技術學院,北京 100871)
3(北京大學(天津濱海)新一代信息技術研究院,天津 300450)
在軟件開發過程中,開發者最常用的復用方式就是通過檢索、調用軟件項目提供的 API(application programming interface,應用程序接口)來實現所需的功能.然而隨著軟件項目源代碼的規模變得越來越大,源代碼之間的依賴關系越來越復雜,API檢索也變得越來越困難[1].比如,開源項目Lucene包含了超過5 377個類以及 34 042種方法.而研究人員在研究搜索引擎查詢日志時發現,開發者往往花費了大量的時間與精力來查找API[2],通用搜索引擎(如 Google)在檢索軟件代碼方面存在許多問題且效率較低[3].由此也促生了在很多技術性問答網站(如StackOverflow)上,可以發現大量關于如何使用API的提問.
受自然語言處理技術的影響,目前許多軟件源代碼檢索工具,比如 Krugle、Ohloh和 Sourcerer[4]等,都是將源代碼視為純文本進行處理.其基本思路是:利用軟件源代碼中的自然語言特征,基于查詢問題與代碼的文本相似度進行匹配,返回相似度較高的檢索結果.典型的相似度匹配模型包括布爾模型(Boolean model)[5]、向量空間模型(vector space model)[5]、BM25模型[5]等.然而研究表明,這些工具的準確率不能讓人滿意.在 Lü等人[6]于2015年進行的一項研究中表明,Ohloh返回的排名前十的結果中,只有25.7%~38.4%是有用的.研究者們指出,導致現有軟件源代碼檢索工具效果不理想的一個主要原因是其缺乏對自然語言查詢問題語義的理解.對此,研究者們從深化問題理解的角度提出了許多新的方法,如擴展語義相近的詞(semantic similar word)[7]、引入查詢重構策略(query reformulation)[8]或利用其他在線文檔(如 MSDN)來優化問題理解和檢索過程[6]等.雖然這些技術很大程度上提高了API定位的準確度,但其需要積累和利用大量的輔助信息,在上述信息缺乏的情況下,往往不能達到預期效果.本文則希望僅從軟件項目的源代碼出發,幫助開發者提高API檢索的效率,因為源代碼是復用過程中能夠直接獲得的資源,其他信息有時則難以獲得.
此外,現有這些檢索工具返回的結果往往只有相關的代碼片段信息,缺乏對關聯API的說明與展示,不便于用戶理解目標API調用背后的邏輯關聯和整體概念,在一定程度上影響了軟件復用的效率.為此,研究者們指出,不應單純地將軟件代碼視為純文本.比如在McMillan等人和Chan等人[9,10]的工作中,將源代碼以有向圖的形式組織起來,圖中的結點表示代碼元素,邊表示代碼元素之間的關聯關系.圖結構是對源代碼知識的一種自然且有效的表示,被廣泛應用于軟件文檔檢索、特征定位等問題.借助代碼的結構圖,對源代碼的檢索就轉化為圖上的搜索過程,這樣得到的結果既能包含需要被定位的代碼元素,又能充分體現代碼之間的關聯關系.舉例來說,假設在使用開源軟件項目 ApacheLucene(http://Lucene.apache.org/)的過程中,開發者當前使用 StringField類對一個字符串的字段進行處理.當需求發生變化,還要對含有浮點數的字段進行處理時,這個開發者就需要使用FloatPoint類并考慮如何重構代碼.而我們可以從圖1所示的源代碼圖中發現,這兩個類都繼承自Field類,實現了IndexableField接口,同時具有tokenStream方法.因此對開發者來說,一種更好的策略是使用該抽象的父Field作為變量類型,并在處理不同查詢時賦值為不同的子類,從而能夠較好地滿足其上述需求.

Fig.1 Code graph of Lucene project (Part)圖1 Lucene項目的代碼圖示例(部分)
目前,在基于圖結構的 API檢索方面,主要采用了最短路徑[10]、PageRank[9]等淺層語義分析技術.考慮到在圖上進行搜索是一個計算量很大的問題,且要求延遲越短越好,算法的效率至關重要.如果使用在線查詢最短路徑的方式,則由于搜索過程中經常需要計算圖上兩個結點之間的距離,將會導致較長的延遲時間.Chan等人的工作[10]也提到了這個問題,并利用了一些近似算法進行優化.
針對這些問題,本文提出一種基于圖嵌入的軟件項目源代碼檢索方法.圖嵌入是一種表示學習技術,能夠將圖上的結點映射為低維空間中的實值向量,通過向量之間的關系來表達圖上的結構信息.對于本文的問題而言,圖嵌入技術一方面能夠有效表達軟件代碼圖中的深層結構信息,與最短路徑等方法相比,更充分地考慮了結點的上下文和關聯關系;另一方面,圖嵌入過程可以離線進行,在用戶在線查詢階段可以立即參與計算,時間復雜度僅是常數級別,大大提高了算法效率.
對比現有工作,本文主要貢獻包括:
(1) 提出了一種將軟件源代碼進行圖嵌入表示的方法,該方法能夠能夠基于軟件項目源代碼,自動構建其代碼圖結構,并通過圖嵌入對源代碼進行信息表示.
(2) 提出了一種基于圖嵌入的軟件項目源代碼檢索方法,該方法能夠基于項目源代碼的圖嵌入技術表示,將自然語言查詢問題語義匹配到代碼子圖,提高了檢索的準確性,同時展示了API的關聯關系;
(3) 實現了一個基于圖嵌入的軟件項目API檢索工具原型,并通過2個具體軟件項目中關于源代碼檢索的實際問題為例,驗證了本文方法的有效性.與Chan等人提出的方法相比,本文方法在召回率、F1值上有了顯著提升,并有效減低了檢索響應時間.
本文第1節介紹圖嵌入技術.第2節詳細描述本文提出的基于圖嵌入的軟件項目源代碼檢索方法.第3節通過實驗驗證本文方法的有效性.第4節介紹相關工作.第5節對本文工作進行總結并展望未來研究工作.
1 圖嵌入
圖嵌入(graph embedding)的主要目的是將一張圖上的結點映射到低維空間的向量,通過這些向量來體現原本圖上的結構信息.這里的結構信息可以是一階、二階甚至更高階的結構,一階結構信息即保持原本相鄰的結點在嵌入空間中的距離仍然很近,而更高階的結構信息則可以保持原本具有相似上下文的結點在嵌入空間中的距離仍然很近.目前,圖嵌入技術在知識表示領域頗受關注,被廣泛應用于可視化、頂點分類、關聯預測、推薦等任務.現有的圖嵌入技術主要可以分為以下幾類[11].
· 基于因子分解的圖嵌入方法.該類方法將圖上結點之間的關系表示成矩陣,對該矩陣進行因子分解從而得到嵌入的向量.矩陣的類型包括鄰接矩陣、拉普拉斯矩陣(Laplacian matrix)、卡茲相似矩陣(Katz similarity matrix)等,根據不同的矩陣類型有不同的分解方法,其中,Belkin等人[12]提出的 Laplacian Eigenmaps就是對拉普拉斯矩陣做特征值分解得到的;Ahmed等人[13]提出的GF算法則是基于對鄰接矩陣做因子分解.這種方法的時間復雜度是結點數的平方量級,可擴展性較差,對于規模龐大的代碼圖而言并不適用.
· 基于隨機游走的圖嵌入方法.該類方法算法能夠近似表示圖的許多屬性,比如結點的中心度和相似度.Perozzi等人提出的 DeepWalk[14]就是該方法的典型代表,該算法利用了神經語言模型 SkipGram的思想,根據周圍的鄰居結點來預測當前結點的嵌入向量.該類方法通常從某一結點為中心出發進行多次隨機游走,最大化觀測到的前k個結點以及后k個結點的概率,能夠保持高階的相似性.當只需要觀測圖的部分結構或者圖太大而無法全部測量時,該類方法是一個不錯的選擇.但是該類方法通常只能捕捉到一條路徑上的局部結構信息,并且難以找到最佳的采樣方法,調優困難.
· 基于深度學習的圖嵌入方法.該類方法有的利用深度自編碼器(deep autoencoder)來實現降維,因為自編碼器擁有學習數據中非線性結構的能力.典型地,Wang等人[15]提出的SDNE包括無監督和有監督兩部分:前一部分由自編碼器學習能夠重新構鄰居的結點嵌入,后一部分則基于 Laplacian Eigenmaps對那些本來相鄰而映射到嵌入空間后卻相距很遠的結點進行懲罰.還有一些算法利用卷積神經網絡來得到嵌入向量,如Kipf等人[16]提出的一種半監督學習的方法,這些算法的計算開銷更小,更適用于相對稀疏的圖.這一類方法雖然能更好地捕捉非線性的結構,然而復雜度還是較高,需要大量的計算開銷.
本文采用的是Tang等人[17]提出的LINE(large-scale information network embedding)方法,該方法的可擴展性很好,能夠快速地對大規模網絡進行嵌入,并且能夠同時保留局部和全局的結構信息.該方法嚴格意義上不屬于上述的 3種類型,而是在模型中顯式地定義了一階和二階的近似函數以及任意 2個結點之間的聯合概率分布,通過最小化嵌入矩陣與鄰接矩陣所代表的兩個概率分布之間的 KL(Kullback-Leibler)散度得到圖嵌入的向量.定義好目標函數之后,LINE并沒有采用傳統的隨機梯度下降算法進行優化,而是提出了一種新的邊采樣的方法(edge-sampling),根據邊的權值成比例的概率進行采樣,這樣能夠防止隨機梯度下降中由于邊的權值過大導致的梯度爆炸問題.為了進一步形象地闡明一階近似和二階近似的意義,我們以圖2為例進行說明.一階近似能夠將直接有邊相連的結點映射到更近的距離,比如圖2中的結點6和結點7,它們之間有一條權重很大的邊連接.而二階近似則能夠將具有相同鄰居的結點映射到更近的距離,比如圖2中的結點 5和結點 6,它們都具有很多相同的鄰居結點.因此,一階近似能夠保留更多局部的結構信息,而二階近似能夠保留更多全局的結構信息.同時考慮2種近似的結果,就是將結點5~結點7都映射到嵌入空間中更近的距離.
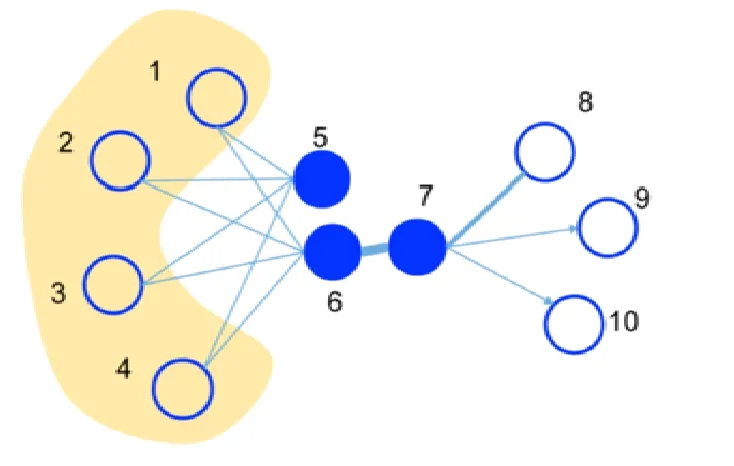
Fig.2 Graph embedding maps nodes with similar structure to closer distance in the embedding space[17]圖2 圖嵌入將結構相似的結點映射到嵌入空間中更近的距離[17]
2 本文工作
本文提出了一種基于圖嵌入的軟件項目源代碼檢索方法,其基本思想是:利用圖嵌入技術有效表達軟件代碼圖中的深層結構信息,在檢索過程中充分地考慮了結點的上下文和關聯關系.如圖3所示.

Fig.3 Framework of searching software project’s source code based on graph embedding圖3 基于圖嵌入的軟件項目源代碼檢索方法框架
該方法主要包括4個部分.
1)代碼圖的構建:獲取項目的源代碼并做相應解析,自動構建其代碼圖.
2)代碼圖的嵌入:使用圖嵌入技術將代碼圖中的結點表示為向量,以備后續階段使用.
3)問題與代碼圖結點的匹配:對用戶輸入的自然語言問題進行預處理,然后匹配到代碼圖中結點作為候選結點,并對候選結點進行度量.
4)代碼子圖的生成與推薦:從第 2階段得到的候選結點中挑選合適的結點構成子圖,并擴展為連通的子圖,將排名最佳的結果返回給用戶.
2.1 代碼圖的構建
在一個軟件項目(對于面向對象的函數庫而言)的源代碼中,主要有兩種組成成分:一種是類或接口,另一種是方法.而類與方法之間的關聯關系的類型大體上所有面向對象語言都共有,當然,部分關聯關系與具體編程語言有關.本文以Java語言作為實驗對象,考慮了Java語言中的如下6種關聯關系,分別為繼承(Inh)、實現(Imp)、成員(Mem)、參數(Par)、返回值(Ret)和調用(Call),用集合Rel={Inh,Imp,Mem,Par,Ret}表示(見表1).在此基礎上,我們可以利用現有工具對一個開源軟件項目的源碼進行解析,構建代碼圖并存儲于圖數據庫中.
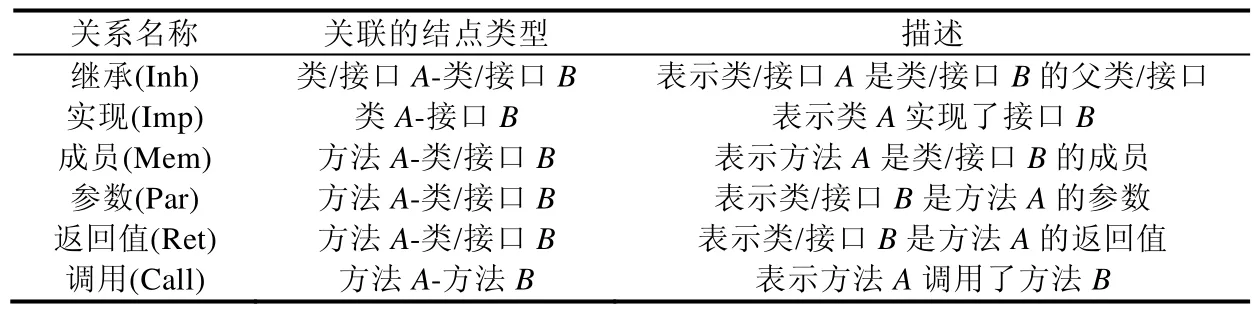
Table 1 Relationship types in code graph表1 代碼圖中的關系類型
代碼圖(code graph).代碼圖G=(VG,EG)是一個有向無權圖,頂點集VG是所有的類和方法的結點,邊集EG中任一條邊e(u,v),?R∈Rel,使得uRv.其中,uRv表示u,v之間存在R類型的關聯關系.
現在主流的Java源碼解析工具有很多,例如CheckStyle,JAVAssist,Yasca,JDT等.這些工具都現成可用,可以解析Java項目并提取出代碼元素以及它們之間的關系.本文使用的是Eclipse的JDT,作為一個輕量級的代碼解析工具,它可以迅速將Java代碼構建成一個DOM結構的抽象語法樹(AST).代碼中的每個元素都對應AST上的一個結點,通過遍歷AST就可以得到所有代碼元素和它們之間的關系,用來構建軟件代碼結構圖.
本文使用圖數據庫Neo4j(https://neo4j.com/)來存儲代碼圖.Neo4j是一個用Java實現,完全兼容ACID的圖數據庫,其本身數據組織的結構和我們需求的代碼結構圖非常相似,也是通過結點與結點之間的關系構成整張圖.除此之外,Neo4j還提供了諸如索引(index)、遍歷(traversal)等機制以及一種類SQL的查詢語言Cypher,以方便在圖上進行更高級的操作.
2.2 代碼圖的嵌入
本文使用圖嵌入的原因是在第 3階段,即代碼子圖的生成與推薦時,需要計算圖上任意兩個頂點之間的距離.圖嵌入技術可以使得這一步驟變得十分方便與快速.如果采用在線查詢兩個頂點的最短路徑的方式則將非常耗時,而圖嵌入過程卻是離線的,在構建完代碼圖后即可完成.
本文使用了Tang等人[17]提出的名為LINE的方法,該方法的可擴展性很好,時間復雜度較低,能夠快速地對大規模網絡進行嵌入,并且同時保留局部和全局的結構信息,能夠適用于有向圖、無向圖、帶權圖等多種類型.LINE的源代碼可以在Github上找到,本文用Java語言重新實現了該算法.
結點之間的距離.代碼圖嵌入以后,代碼圖中的任一頂點v∈VG,都映射到一個向量rv∈Rd,其中,d表示該向量的維度;任意2個頂點u,v之間的距離定義為相應的向量之間的歐氏距離,即dist(u,v)=||ru-rv||2.
2.3 問題與結點的匹配
從這一階段開始,便進入在線查詢的過程.當用戶輸入一個自然語言的問題后,我們先對問題進行預處理,然后匹配到代碼圖中一些候選結點.
2.3.1 問題與結點的預處理
本文采用簡單的詞袋模型(bag of words),將問題視為一些無序的詞組成的集合,忽略其句式和位置等信息.由于自然語言文本還存在單詞之外的一些符號,如標點符號等,本文將去除非數字和非字母的其他符號,并以此作為分隔符進行切詞.切詞以后,進行停用詞處理.自然語言包含許多無實際意義的功能詞,比如冠詞和介詞等.這些詞存在十分普遍而包含信息的卻極少,人們一般稱之為停用詞(stop words).本文去除的停用詞包括常見的英文停用詞、Java保留字以及項目領域特有的功能詞(比如Lucene),等.
代碼圖中結點(類或方法)的預處理是將該類或方法的名字通過切詞得到一個詞袋,用來描述該結點的語義信息.本文使用駝峰切詞法進行處理,比如QueryParser這個類名,切詞后的結果就是{query,parser}.
問題(query).問題Q是由一些去除停用詞之后的單詞的集合組成,將該單詞集合記為BOWQ={q1,…,qn}.
結點單詞集合.代碼圖G中的任一結點v,都有一個與之關聯的單詞集合,記為BOWv={s1,…,sm}.
2.3.2 產生候選結點
候選結點集合.問題Q所匹配到的候選結點集合是一個集族,記為CandidateQ={C1,…,Cn},其中,Ci(1≤i≤n)是單詞qi匹配到的代碼圖中結點的集合,其大小記為|Ci|.
對于 Query詞袋中的每個詞,我們都為之在圖上找到一系列的候選結點,這樣做是為了充分保留原問題中的語義信息.接下來需要明確對于每個單詞q,如何匹配到它所對應的候選結點.本文使用文本匹配的方法,主要考慮了如下5種匹配情形.
(1) 全名匹配.單詞q本身就是就是一個類或方法的全名,比如q=QueryParser.
(2) 部分匹配.單詞q被結點v所對應的詞袋所包含,即q∈BOWv,比如q=query.
(3) 詞根化匹配.單詞q與結點v所對應的詞袋中的詞經詞根化后相同.詞根化(stemming)能夠將語義上相同而由于語法等原因導致詞形不同的詞抽取出同樣的詞根,本文采用 Snowball(http://snowball.tartarus.org/)作為詞根化工具.比如q=parse,由于 parse和 parser詞根化后都是 pars,因此q會匹配到QueryParser這個結點.
(4) 縮略規則匹配.單詞q經過手工構造的一些規則轉換后,被結點v所對應的詞袋包含.這是為了解決自然語言的詞匯與代碼元素中的命名不一致的問題,代碼元素的命名為了方便,很可能只采取了自然語言單詞的縮寫,比如Document在代碼中的命名可能是Doc,Number在代碼中的命名可能是Num,等.
(5) 同義詞匹配.單詞q與結點v所對應的詞袋中的詞,經過相似度計算被判定為同義詞.同近義詞是自然語言處理領域的一個重要研究問題,在自然語言與代碼元素匹配的過程中也存在這個問題,比如問題中的詞是delete,但代碼中某個方法的名字可能是remove,這種情況也應該被考慮.為了解決這個問題,本文使用了在Wikipedia上預訓練的glove(https://nlp.stanford.edu/projects/glove/)詞向量.通過計算兩個詞向量的余弦相似度來表示語義的相近性,當大于特定閾值時,就認為這兩個詞是同義詞.

2.3.3 候選結點的度量
上一步驟為了保證對原問題中詞匯的覆蓋程度,產生了大量的候選結點.但這些結點不應該都是同等地位的,有的候選結點與問題語義更貼近,有的卻徒增了許多噪音,因此需要對結點與問題的文本相似程度進行度量.本文考慮兩種評價指標:一是該結點詞袋與問題中相關的詞越多越好;二是該結點引入的不相關的詞越少越好,即當結點與問題相關的詞數量相同時,BOWv越小的結點質量越好.可類比于信息檢索中的準確率與召回率,具體定義如下.
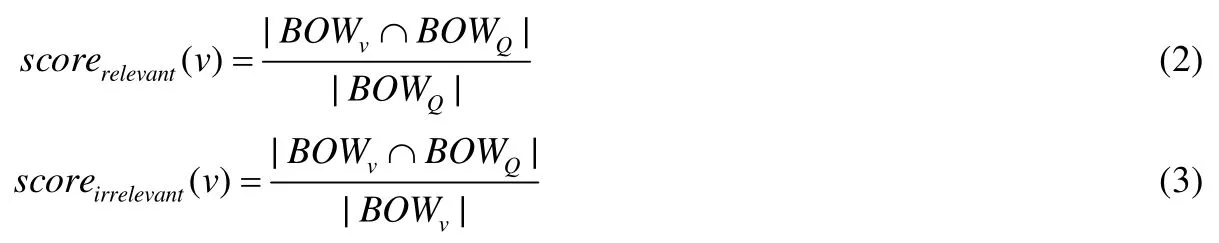
為了考慮同義詞的影響,在計算兩個詞袋的交集時,需要進行特殊處理.如果結點詞袋中的某個單詞不在Query詞袋中出現過,那么利用詞向量計算該單詞與Query中所有單詞的余弦相似度,取其中的最大值作為該單詞對交集的貢獻.因此,該交集的值不一定是整數.
結點權重.以scorerelevant和scoreirrelevant的F1值作為該結點與問題的相關度的度量,稱為該結點的權重,記為w(v),其計算公式如下所示.
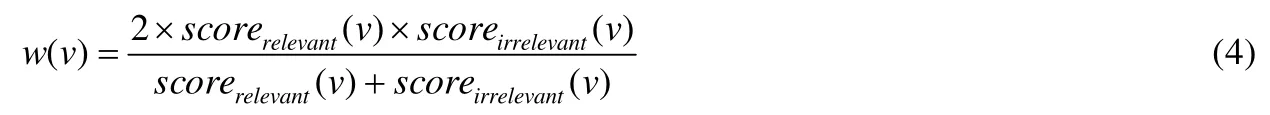
2.4 子圖的生成與推薦
得到候選結點集合之后,需要從中挑選合適的結點來構成能夠反映問題語義的子圖.從大量的候選結點中構成子圖的搜索空間非常巨大,如何高效地生成子圖并度量其優質程度是問題的重中之重.最后,將生成的子圖擴展成為連通的子圖返回給用戶.因此,本階段可分為兩個部分:子圖的生成與度量,子圖的擴展與推薦.
2.4.1 子圖的生成與度量
本文從兩個方面來評價子圖的質量:一是子圖中的結點與問題之間的文本相似程度盡可能地高,每個結點的文本相似程度即結點的權重w(v);二是子圖中結點之間的距離越近越好,這將起到消除歧義的作用.比如子圖中的一個結點是Document類,現在有兩種同名的方法add,它們的文本相似程度是相同的,那么距離Document類更近的那個方法更可能是相關的,而距離遠的結點可能是一個屬于其他類的方法,與本問題無關.
首先,我們定義如何從候選結點的集合中選擇子圖的頂點集.
頂點集.CandidateQ={C1,…,Cn}構成的子圖G′的頂點集V′={Ci,j|xi,j=1},其中,xi,j是二元變量,表示Ci中的第j個結點是否被選中,滿足約束條件.
這里的第1個約束條件是為了使問題中的每個詞所對應的候選結點集合中至少有1個結點被選中,以此保證對原問題語義的覆蓋度.另外,同一個結點可能在不同的集合中重復出現,因此只要該結點在某個集合中被選中,則其他集合中也必須選中它,這就由第2個約束條件保證.
接下來,我們定義一個子圖G′的度量函數:

其中的距離dist(u,v)即第 2.2節中所述的使用圖嵌入向量計算的歐氏距離.子圖的生成過程即求解這個優化問題 minscore(G′),這可以看成一個二次優化問題.為了方便求解,本文提出一種基于柱狀搜索(beam search)的方法.柱狀搜索可以看作對貪心法的一種優化,每次將保留前k個最佳的候選結果.具體如算法1所示.
算法1.柱狀搜索子圖.
輸入:候選結點集合CandidateQ={C1,…,Cn}.
輸出:排名最高的一個子圖.


對于輸入的候選結點集合,按權值排序后取最高的k個結點作為起始結點,其中,參數k就代表著柱狀的大小(beam size).第7行~第10行是先根據公式(5)中的度量函數計算加入當前結點后增加的代價,然后生成一個新的子圖加入候選集合中,并計算累積的代價.第13行、第14行仍是只保留列表中排序靠前的k個結果.最后,我們返回排名最高的一個子圖.
2.4.2 子圖的擴展與推薦
利用圖嵌入的向量來計算距離,帶來了計算的便利和速度的提升,但由于在選擇結點的過程中我們并沒有考慮實際存在的邊,因此到目前為止,我們只得到了子圖的頂點集.為了給用戶提供更形象地理解,我們應該將這些結點是如何連接起來的一同展示給用戶,即從頂點集擴展成一個連通的子圖.
本文利用將這個問題定義成給頂點集V′構造一棵最小生成樹(minimum spanning tree,簡稱MST),將V′中任意兩個頂點之間的最小跳數定義為它們之間的邊的權重,這樣做就意味著用盡可能少的邊將所有頂點連接起來.具體算法如下表的算法2所示,其中,第5行的FindShortestPath函數即尋找結點集合X和Y之間最短路徑,而每兩個結點之間的最短路徑可以通過Cypher語句在代碼圖中進行查詢;第8行、第9行是將這條路徑上所經過的結點和邊都加入到擴展后的子圖中.直到所有結點都被包含進來,該算法便得到了一個連通的子圖.
算法2.擴展為連通子圖.
輸入:頂點集V′.
輸出:擴展后的子圖Ge.

3 實驗與實例
基于上述方法,本文設計并實現了基于圖嵌入的軟件 API檢索工具原型.下面我們通過一些實驗來驗證本文所提出方法和工具的有效性.這些實驗主要用于回答下列研究問題.
· 研究問題1:本文所提出的方法是否能夠有效地定位用戶所需要的API?
本文方法將源代碼組織成代碼結構圖的形式而非僅視為純文本來處理,其中利用了圖嵌入技術,定義了子圖的度量函數,并使用基于柱狀搜索的算法進行代碼子圖的檢索.我們希望本文所提出的方法在回答開發者提出的實際自然語言問題時,能夠有效提升軟件項目API檢索的效果.為了驗證這一點,我們選擇了兩個著名的開源項目以及與它們相關的自然語言問題進行了驗證,并與傳統基于文本匹配的方法進行了對比.
· 研究問題2:本文中所提出的圖嵌入方法與現有其他檢索方法相比效果如何?
在本文所提出的方法中,我們使用了圖嵌入方法來挖掘代碼圖的結構信息,在度量結點之間的距離時,使用圖嵌入向量之間的距離,并由此定義了子圖的度量函數.我們關心圖嵌入方法是否能夠有效地表達代碼結構圖中蘊含的語義信息,從而改進代碼檢索的效果.因此,我們設計了相應的實驗,將本文所使用的圖嵌入方法與現有的基于最短路徑的方法進行了對比,以驗證圖嵌入方法的有效性.
3.1 實驗設計
我們選取了兩個著名的開源軟件項目——Apache Lucene和Apache POI作為實驗對象,自動構造了這兩個項目的代碼圖,并分別對其進行了基于自然語言的代碼檢索實驗.實驗設計的細節列舉如下.
3.1.1 代碼圖構造
對于每個軟件項目,我們基于它的源代碼中構建一個代碼結構圖.Lucene和POI項目的源代碼都可以通過其官網的連接或 Github直接下載.一個軟件項目往往會有很多個不同的版本,我們選取了這兩個項目其中被廣泛使用版本進行代碼結構圖的提取.與代碼結構圖相關的統計信息在表2中進行了展示,包括源代碼版本、類或接口的結點數量、方法的結點數量、關聯關系的數量以及構造時間.我們在一臺3.40GHz雙核處理器、8GB內存的服務器上,解析生成兩個項目的代碼結構圖的時間開銷分別為39min和31min.

Table 2 Information of code graphs for experimental projects表2 實驗所用項目的代碼圖信息
在Chan等人的工作中,他們實驗所使用的源代碼數據是JSE,它是一個非常通用的底層函數庫.本文所關注的問題是在軟件項目復用時如何有效進行 API檢索,我們實驗中使用的 Lucene和 POI是領域特定的函數庫/軟件項目.基于功能實現的需要,其API之間的關聯往往非常緊密,使得這類領域特定的軟件項目在實際中的進行代碼檢索和復用的難度更大.從表2中可以看出,Lucene項目代碼圖中,結點(類和方法等)數量是39 000左右,但它們之間的關聯關系數量達到了255 000.同時,在POI項目的代碼圖中結點數和關聯關系的數量關系也與此類似.
3.1.2 API檢索問題
進行 API檢索的自然語言提問多種多樣,為了保證問題的真實有效性,本文使用了2種客觀的方式來獲得實驗所需的問題.
· 對于 POI項目,我們通過其官方網站上提供的用戶指南(https://poi.apache.org/spreadsheet/quick-guide.html),抽取了20個問題作為第1組Query.每一個問題在用戶指南中都有對應的示例代碼,我們將這些示例代碼中涉及的API標注為該問題的groundtruth.
· 對于Lucene項目,由于其官方網站上沒有相關教程和示例代碼,我們使用StackOverflow上關于Lucene項目的問答帖子作為來源,采取隨機抽樣的方法,直到挑選出 20個與源代碼檢索相關的問題作為第 2組Query.具體抽取方法是:首先,從StackOverflow上2008年~2016年的數據中找出帶有Lucene標簽的問題,并按照問題的投票為正,問題有被接受的答案,答案中含有代碼片段的條件進行篩選,得到了923個問題,再從這些候選問題中進行無放回的隨機抽取,人工閱讀是否屬于源代碼檢索相關的問題,直到挑選出20個相關問題;其次,由于這些問題在StackOverflow上分為標題和內容兩部分,且標題基本上都可以作為其內容概括,本文就以問題的標題作為代碼檢索工具的查詢輸入,即 Query.針對這 20個Query,我們還需要確定其對應的目標API.為此,我們組織了3名熟悉Lucene項目的研究生,分別閱讀了這些Query在StackOverflow上的問題和答案,結合帖子的答案和源代碼的相關知識,在代碼圖上進行標注.具體的標注過程是:開發人員以該問題答案中出現的代碼片段為基準,并結合源代碼的相關文檔,利用代碼圖數據庫的查詢結果,最終確定該Query對應的API集合.
本文實驗所使用的問題是開發者在實際開發過程中遇到的、真實存在的、用自然語言表述的問題,其中部分問題及其標注見表3,問題之中可能含有代碼元素的名稱,比如lengthNorm,也可能沒有.因此我們認為,對這些問題的解答,可以很好地反映各種方法的實際效果.

Table 3 Examples of query and annotated API表3 問題與標注API示例
3.1.3 比較對象
為了考察本文工作的實際效果,我們首先分析比較了本文方法在檢索過程中選擇第1個結果和選擇前3個結果的情況;其次,我們將這兩種情形與其他兩種典型的代碼檢索方法進行了對比.實驗方法包括以下幾種.
(1) 本文方法(Top 1).這一檢索方法只采用了本文基于圖嵌入的代碼檢索方法的第1個結果.
(2) 本文方法(Top 3).這一檢索方法采用了本文基于圖嵌入的代碼檢索方法的前3個結果.
(3) 基于文本匹配的方法.這一檢索方法只考慮問題與結點的文本相似度進行匹配,而不考慮結點之間的距離因素,即第2.4.1節中子圖的度量函數公式(5)中只含權重部分而沒有距離部分.
(4) 基于最短路徑的方法.這一檢索方法來源于 Chan等人的工作,其采用最短路徑來計算兩個結點之間的距離,而非本文方法中使用的圖嵌入向量之間的距離.
3.1.4 評價指標
為了評價檢索結果的好壞,本文使用了準確率(precision)、召回率(recall)和F1-值(F1-score)作為評價指標.準確率和召回率的計算與真陽性(true positive)等概念有關,其定義見表4.

Table 4 Metrics for search results表4 檢索結果的度量指標
在本文的實驗中,準確率和召回率的定義如公式(6)、公式(7)所示.

其中,VH標注結果的結點集合,VG本文工具返回結果的結點集合.這里的True positives即兩個集合的交集,F1值即準確率和召回率的調和平均數.
3.2 檢索實例
針對表3中的實驗問題1“how to set document boost attribute in Lucene?”,本文在Lucene軟件項目的代碼圖上進行了檢索實驗.首先,這個問題被預處理后的單詞集合為{set,document,boost,attribute},對于集合中每一個單詞,根據第 2.3.2節中提到的匹配方法,分別得到了{1623,1101,63,122}個對應的候選結點,可以看出,候選結點的規模相當龐大.接著,我們針對每個候選結點計算與問題相關程度作為該結點的權重,比如setBoost結點的權重為0.75,Attribute結點的權重為0.4,在這些候選結點的基礎上,按照第2.4節中的算法構造問題檢索對應的子圖.這里分為兩個部分.
1)子圖的生成:基于離線完成的圖嵌入向量的結果可以計算兩個結點之間的距離,比如Document結點和setBoost結點之間距離為13.47,根據本文定義的目標函數,通過柱狀搜索算法可以得到子圖中應該包含的候選結點為{Document,Attribute,setBoost}.
2)子圖的擴展:采用基于最小生成樹的方法將子圖中的結點擴展為連通的代碼子圖,得到的結果如圖4(a)所示,最終的連通子圖共包含了8個結點.
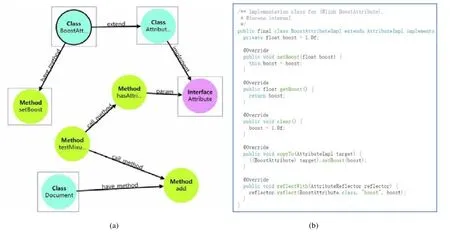
Fig.4 Search result for query “how to set document boost attribute”圖4 問題“how to set document boost attribute”的檢索結果
根據問題的檢索結果,我們可以計算對應的準確率、召回率和F1值.在圖4中,用方框標出的5個結點是該問題被人工標注的API,而其余3個結點則不屬于被標注的.所以該檢索結果的準確率為5/8.而由于方框的5個結點剛好覆蓋了全部標注的API,因此該結果的召回率為1,最終得到的F1值為10/13.
本文的檢索結果是一個子圖,不僅展示了用戶需要的目標 API,還展示了其與相關代碼元素的關聯.在此基礎上,用戶可以通過點擊圖中的 API結點顯示其對應的代碼片段.如圖4(b)所示,就是在上述結果中點擊結點BoostAttributeImpl后,能夠看到對應的代碼體.由此,該檢索結果能為用戶理解和復用API提供有效支持.
3.3 實驗結果
針對上述得到的兩組各20個問題,本文對比了上述4種方法檢索結果的平均準確率、召回率和F1值等評價指標,實驗結果見表5.實驗環境是在Windows 10系統,2.30GHz的雙核處理器,8GB內存,Java版本是1.8.實驗中,圖嵌入向量的維度設置為200,柱狀搜索中的柱大小(beamsize)設置為8.

Table 5 Experimental results analysis表5 實驗結果分析
3.3.1 方法效果對比
從表5中可以看出,在Lucene和POI這兩個項目中,本文方法的Top3都同時獲得了最高的平均準確率、召回率和F1值.而本文方法Top 1與Top 3的結果相差很小,說明對于大部分問題本文方法的Top 1就是最佳的結果.
基于文本匹配的方法在兩個項目中都獲得了最低的平均準確率、召回率和F1值,表明單純利用問題與結點的文本相似度而忽視代碼結構圖中的語義信息,難以取得很好的效果.而本文引入圖嵌入技術挖掘代碼圖結構的方法之后,檢索結果得到了顯著的提升.
基于最短路徑的方法在檢索過程中也利用到了代碼結構圖的信息,只是在計算結點之間的距離時使用的最短路徑,而非本文方法中使用的圖嵌入向量之間的距離.該方法的效果與純文本匹配方法相比有了較大提升,但仍然顯著低于本文方法的結果.本文方法檢索結果的F1值比基于最短路徑的方法提高了10%,表明了圖嵌入方法的有效性,能夠比最短路徑方法挖掘到更全面的圖結構信息.
此外,我們還對比了不同方法的平均響應時間和最長響應時間.從表5中可以看出,純文本匹配方法的效率最高,平均響應時間和最長響應時間都非常短,因為其計算十分簡單,然而其檢索效果也是最不令人滿意的.而最短路徑方法的平均響應時間則非常長,超過了1min,這對于實際的用戶交互而言難以接受.這是因為該方法每次計算距離都需要在線查詢兩個結點之間的最短路徑,使用廣度優先搜索的算法最壞情況下也需要O(N)的復雜度,這里的N表示所有結點的數量.圖嵌入過程由于離線已經完成在線計算兩個向量的距離時只需要常數時間,所以本文方法在改進檢索效果的同時也大大提升了運行的效率.
Chan等人提出的方法是基于最短路徑方法,他們使用的子圖度量函數與本文有所差別,他們在論文中報告的實驗結果為準確率0.53、召回率0.56、F1值0.54,與本文實驗中最短路徑方法的結果十分接近.我們使用的數據集并不相同,他們的實驗中所使用的問題是從KodeJava網站上挑選的關于使用JSE編程的20個示例,并且將問題抽取為多個詞組的形式作為輸入.而本文實驗中使用的Lucene和POI則是領域特定的函數庫,輸入也直接是自然語言的問題.
3.3.2 準確率與召回率分析
從實驗結果來看,本文方法檢索的召回率比較高,但準確率比較低.也就是說,代碼子圖中除了與Query相關的結點之外,還包含了較多無關的結點.特別是對于 Lucene項目而言,準確率和召回率的差別比較大,因此我們對Lucene項目的20個問題做了進一步的分析.
首先,我們對每個問題的準確率進行了具體分析,結果如圖5所示.其中,斜線底色的柱形表示檢索結果中所有的結點(API)數量,純色柱形表示檢索結果中正確的結點數量.可以看到,在我們的檢索結果中,通常更多的API被返回和推薦出來,大部分子圖的規模(結點數)都在 5~8之間,只有兩個問題的子圖大小達到了 10.經分析發現,導致這個問題的主要原因是基于最小生成樹的子圖擴展算法.由于很難斷定哪種類型邊更加有益,我們將所有邊的權值都設為相同,從而產生了大量相同長度的路徑,因而在擴展路徑上很可能引入沒有被標注的結點.雖然我們不能確定這些更多的 API是必要的,但從召回率較高的事實出發,也就是在保證能夠返回用戶所需API的情況下,我們相信,提供更多的信息對用戶理解和使用這些API仍然是有益的.而對子圖擴展算法的優化,可以作為本文的進一步工作.
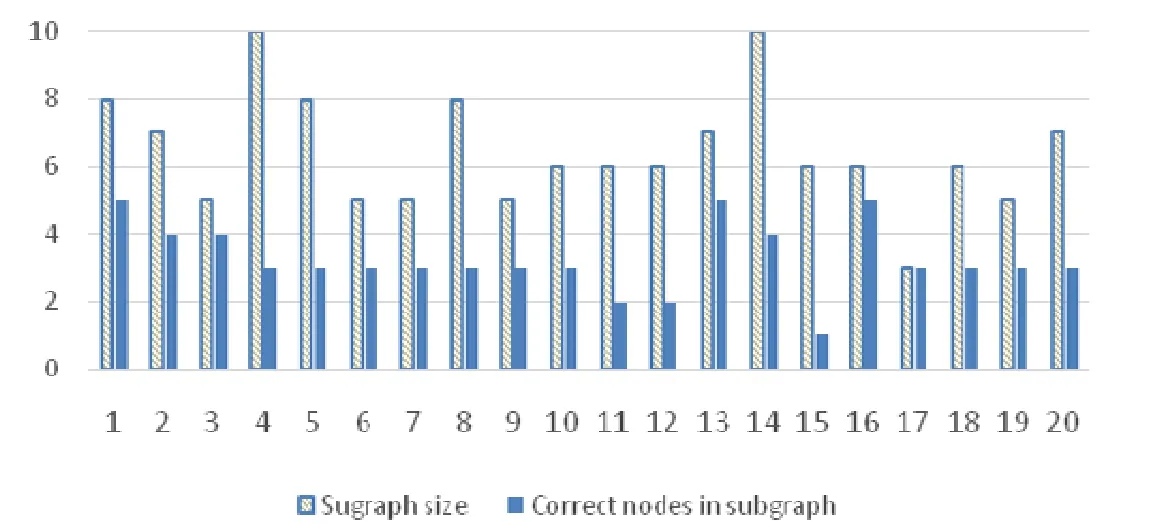
Fig.5 Precision of each question圖5 每個問題的準確率
我們對每個問題的檢索召回率也進行了具體分析,結果如圖6所示.其中,斜線底色的柱形表示人工標注時的API結點數量,純色柱形表示檢索結果中正確的結點數量.從圖中可以看出,兩種柱形高度十分接近,表明整體的召回率很高.對于其中的10個實驗示例而言,召回率都達到了100%,而召回率比較低的只有編號為13和15的兩個問題,柱形高度之差為2.我們對這些召回率偏低的問題進行了分析,比如編號為15的問題“How to query document have any term in a set?”,這里影響其實驗效果的因素是自然語言的歧義性,問題中的set是指集合的意思,而源代碼中則存在大量將 set作為動詞使用的方法名.由于本文在解析問題時只采用了簡單的詞袋模型,目前尚無法很好地解決這類歧義問題.本文工具最終匹配到的是setTerm方法,因為該方法含有兩個與問題相同的詞,結點的權重就很高.在未來工作中,我們將考慮利用代碼結構圖和圖嵌入技術來盡可能地消除自然語言歧義,進一步提升代碼檢索的效果.

Fig.6 Recall of each question圖6 每個問題的召回率
3.4 有效性討論
· 實驗評估的合理性.
本文工作的目標是提高軟件項目 API檢索與復用的效率,檢索結果是一個代碼子圖.我們關注該子圖中的API及其關聯結點是否能夠解決開發者的問題.本文參考Chan等人的實驗指標,使用準確率、召回率和F值作為主要評價,而非信息檢索中的 MRR等排名相關指標.而在進行問題答案的標注過程中,我們從該問題對應的示例代碼中提取 API,并通過交叉驗證等方式保證標注結果的正確性和客觀性.由于實驗的問題都對應有被接受的代碼片段,因此,如果檢索的子圖中包含了其中的 API,那么我們認為它的確能夠幫助開發者解決問題.在未來工作中,我們也將考慮進行用戶研究(UserStudy),以進一步定量探討給開發者帶來的提升效果.
· 影響實驗結果的內部因素.
關于檢索實例:本文針對Lucene和POI項目,分別通過兩組代碼檢索實例進行了實驗,共40個問題.盡管問題數量有限,但我們相信這些問題具有很好的代表性,不會影響實驗結論:首先,我們選取的實驗問題源于實際,一組問題來源于項目官網的用戶指南,另一組問題來源于StackOverflow的帖子,這些問題都是開發過程中真實存在的,并且都有相應的代碼片段,能夠保證問題的較高質量,而對于帖子的篩選和隨機抽取,也能夠保證其代表性;其次,問題的數量對實驗效果沒有明顯影響,在第 3.3.2節的實驗中可以看到,單個檢索實例的評價指標結果與所有實例的結果差異不大.在相關工作中,檢索實例的數量基本與本文相似.比如,CodeHow[6]使用了 34個問題,Chan[10]使用了40個問題.
· 影響實驗結果的外部因素.
關于實驗對比方法:由于本文不僅需要定位目標API,還需要展示其與相關代碼元素的關聯,為此,檢索結果是一個子圖.返回代碼片段或API列表的相關工作不適合與我們直接進行比較.Chan等人的工作是目前與本文場景最接近的工作,其方法的本質是基于最短路徑的.因此,本文實驗中以最短路徑方法作為比較,能夠驗證本文方法的有效性.
4 相關工作
本文的相關工作主要包括對源代碼API檢索和圖嵌入技術兩部分,圖嵌入技術已在第 1節進行了介紹.本節主要介紹源代碼檢索與API推薦的相關技術,重點關注的場景是針對源代碼的基于自然語言問題檢索.
早期的源代碼檢索工作主要是將源代碼視為純文本,考慮查詢問題與代碼之間的文本相似度進行匹配,利用了TF-IDF,BM25等信息檢索技術.Krugle,Ohloh和Sourcerer[4]就是其中的典型代表.Sourcerer將解析后的源代碼存儲在本地的關系型數據庫中,并利用Lucene進行索引.這些方法的查詢方式通常是基于關鍵詞,返回結果是包含查詢中關鍵詞或正則表達式的代碼片段.然而,由于其缺乏對問題語義的理解,這些工具的實際效果往往不夠令人滿意.
針對上述問題,近來有許多研究工作結合了自然語言處理技術,從深化問題語義理解的角度提出了一系列的查詢精煉(query refinement)技術應用于代碼檢索,包括查詢擴展(query expansion)、查詢重構(query reformulation)等.典型地,COCAB[18]從 StackOverflow 帖子含有的代碼片段中提取結構化信息來增強用戶的查詢,以此解決自然語言與代碼元素的詞匯不匹配問題.SNIFF[19]先為代碼片段中的 API尋找到相應文檔作為其注解,繼而在這些被注解過的代碼上進行自然語言的查詢.CodeHow[6]則是通過搜索在線文檔識別出一些與問題相關的潛在API,然后使用擴展布爾模型將這些API的信息結合到代碼檢索的過程中去,從而提高準確度.還有一些方法通過加入語義上相似的詞來擴展用戶的自然語言查詢,這些相似的詞可以來源于對網頁[20]或者軟件項目[9,21]的挖掘.DERECS[22]就預先構造了一個包含大量代碼-描述對的語料庫,利用它對缺少注釋的代碼進行描述增強.然而有研究表明:如果在擴展查詢時引入了一些不合適的詞,將會導致更為糟糕的結果[23].另一些方法則擴展了用戶的查詢方式,Gu等人[24]的工作中,用戶除了可以使用關鍵詞進行查詢,還可以加入代碼的語法和語義約束條件,從而實現更精確地檢索.Wang等人[25]提出了一種動態的檢索方法,能夠結合用戶的反饋信息來優化查詢.Haiduc等人[26]提出了一個名為Refoqus的工具,能夠預測用戶查詢的質量,并自動推薦查詢重構的策略.BIKER[27]從StackOverflow上抽取了相似的問題和 API,并利用詞嵌入(word embedding)來計算文本描述的相似度.基于機器學習的代碼檢索和 API推薦工作也是目前的一個研究熱點,比如,ROSF[28]先通過信息檢索的方法生成候選集,再利用有監督學習為候選結果進行重排序.DEEPAPI[29]使用RNN Encoder-Decoder模型,將自然語言問題翻譯到API調用序列.Function Assistant[30]則利用語義解析的技術,從代碼-文本對中提取特征學習翻譯模型.APIRec[31]從細粒度的代碼修改庫中訓練統計學習的模型,基于上下文上進行 API推薦.RecRank[32]則引入路徑相關的特征對APIRec的結果進行重排序,從而提升了Top 1推薦的準確率.雖然這些技術很大程度上提高了API定位的準確度,但其需要積累和利用大量的輔助信息,在上述信息缺乏的情況下,往往不能達到預期效果.在本文工作中,我們尤其關注了在沒有輔助文檔信息和大量查詢歷史的前提下,如何借助代碼自身蘊含的語義信息來輔助提升代碼檢索的效果.
由于現有代碼檢索工具往往返回問題相關的代碼片段,缺乏對關聯 API的說明與展示,不便于用戶理解目標API調用背后的邏輯關聯,如調用鏈、類圖等,來理解整體的概念[33,34].為此,一些工作開始關注如何在定位與問題相關API的同時,整合、利用和展示代碼元素之間的關聯信息.典型地,McMillan和Chan等人的工作就將代碼組織成有向圖的結構,將代碼檢索問題轉化為圖上的搜索問題.McMillan等人提出的工具 Portfolio[9],利用了PageRank和SAN(spreading activation network)算法,返回圖上與問題相關的前k個結點作為答案.而Chan等人的工作[10]則更進一步地保證了返回結果是一個連通的子圖,從而能夠清晰地展現出各個結點之間的連接關系.RACS[35]針對 JavaScript框架,構建方法之間的調用關系圖,并將自然語言問題也抽取為圖形式,尋找與問題的圖結構相似的代碼片段.許多其他工作也將同樣地思想用于文檔檢索、特征定位等諸多場景[36,37].受這些工作的啟發,本文也將源代碼組織為有向圖的結構,利用了圖嵌入技術來挖掘圖結構的深層信息,能夠更充分地考慮代碼圖的上下文信息;同時,由于圖嵌入可以離線完成,提高了在線查詢算法的效率.
5 總結與展望
為了幫助用戶更好地檢索和復用軟件項目 API,本文提出了一種基于圖嵌入的軟件項目源代碼檢索方法.圖結構能夠很好地反映軟件項目源代碼中 API之間的關聯,幫助用戶理解軟件項目;圖嵌入技術能夠更充分地挖掘圖結構的深層信息,并且可以離線完成,有效地提高檢索過程中生成子圖的效率.基于上述方法,我們設計并實現了相應的軟件項目API檢索工具,并以開源項目ApacheLucene和POI為例,通過相關實驗驗證了本文方法的有效性.
在未來的的工作中,我們將在圖嵌入技術的基礎上進一步改進問題與結點的匹配方法,利用詞性、句法等自然語言處理技術更好地挖掘問題的語義;同時,在匹配過程中增加對邊的類型的分析,在擴展子圖時考慮路徑上其余結點與問題的相關度,以減少不相關結點的引入,從而提升檢索的準確率.此外,我們將進一步探討在實際過程中用戶與搜索結果之間的交互會面臨的問題,增強搜索結果的可讀性.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
