融合詞匯特征的生成式摘要模型
2019-06-11 08:27:47江躍華丁磊李嬌娥杜皓晅高凱
河北科技大學學報 2019年2期
江躍華 丁磊 李嬌娥 杜皓晅 高凱


摘要:為了能在摘要生成過程中利用詞匯特征(包含n-gram和詞性信息)識別更多重點詞匯內容,進一步提高摘要生成質量,提出了一種基于sequence-to-sequence(Seq2Seq)結構和attention機制的、融合了詞匯特征的生成式摘要算法。算法的輸入層將詞性向量與詞向量合并后作為編碼器層的輸入,編碼器層由雙向LSTM組成,上下文向量由編碼器的輸出和卷積神經網絡提取的詞匯特征向量構成。模型中的卷積神經網絡層控制詞匯信息,雙向LSTM控制句子信息,解碼器層使用單向LSTM為上下文向量解碼并生成摘要。實驗結果顯示,在公開數據集和自采數據集上,融合詞匯特征的摘要生成模型性能優于對比模型,在公開數據集上的ROUGE-1,ROUGE-2,ROUGE-L分數分別提升了0.024,0.033,0.030。因此,摘要的生成不僅與文章的語義、主題等特征相關,也與詞匯特征相關,所提出的模型在融合關鍵信息的生成式摘要研究中具有一定的參考價值。
關鍵詞:自然語言處理;文本摘要;注意力機制;LSTM;CNN
中圖分類號:TP319文獻標志碼:A
Abstract: In order to use lexical features (including n-gram and part of speech information) to identify more key vocabulary content in the summarization generation process to further improve the quality of the summarization, an algorithm based on sequence-to-sequence (Seq2Seq) structure and attention mechanism and combining lexical features is proposed. The input layer of the algorithm combines the part of speech vector with the word vector, which is the input of the encoder layer. The encoder layer is composed of bi-directional LSTM, and the context vector is composed of the output of the encoder and the lexical feature vector extracted from the convolution neural network. The convolutional neural network layer in the model controls the lexical information, the bi-directional LSTM controls the sentence information, and the decoder layer uses unidirectional LSTM to decode the context vector and generates the summarization. The experiments on public dataset and the self-collected dataset show that the performance of the summarization generation model considering lexical feature is better than that of the contrast model. The ROUGE-1, ROUGE-2 and ROUGE-L scores on the public dataset are improved by 0.024, 0.033 and 0.030, respectively. Therefore, the generation of summarization is not only related to the semantics and themes of the article, but also to the lexical features.The proposed model provides a certain reference value in the research of generating summarization of integrating key infromation.
Keywords:natural language processing; text summarization; attention mechanism; LSTM; CNN
近年來,由于互聯網技術的迅猛發展以及用戶規模的爆發式增長,互聯網的數據呈現指數級增長。文本是目前形式多樣的信息數據中最主要的存在形式。如何能從海量的文本數據中挖掘出重要而且是用戶關心的話題和信息,對于提升閱讀效率、消化海量信息是非常有幫助的。文本摘要是文本信息自動抽取的主要任務之一,它追求以更加精簡、精確的方式,用少量文本盡可能地表述原文含義。按照產生方式的不同,文本自動摘要可分為抽取式和生成式摘要。其中,抽取式摘要主要是指從原文中抽取出和文章主題相關的內容,在不超過一定字數的限制下,盡可能地讓抽取的句子覆蓋到原文所有含義,并按順序排列生成一段摘要文本;生成式摘要則是通過讓模型學習原文中所表達的含義,推斷所需要生成的摘要內容,由模型自動生成一段摘要文本。根據任務的不同,文本摘要也可分單文檔摘要和多文檔摘要。通常,人們在閱讀文章時,一方面要保留句子的大部分信息,另一方面要關注句子中重要的詞匯信息。在生成摘要時,應對原文中的短語按照詞性做不同的處理,例如對名詞、動詞等有實際意義的詞匯信息,在生成摘要時保留信息;對于介詞、虛詞等無明顯含義的詞匯應保留較少的信息。
在Seq2Seq框架和attention機制的基礎之上提出了使用卷積神經網絡提取詞匯特征,并將其融合在上下文中的方法,對原文的詞匯特征進行提取,并和基礎框架所提取的句子特征一起構成上下文特征矩陣,目的在于使用上下文信息時既要保留文本的序列信息,同時也要保留重點詞匯特征信息。
1相關工作
在生成單文檔摘要時,可通過深度學習的方式實現,即使用大規模的數據集,以數據驅動的方式訓練神經網絡,學習原文淺層語義并生成摘要。在相關工作中,RUSH等[1]和CHOPRA等[2]使用Seq2Seq框架,在編碼器端給定輸入的句子,在解碼器端輸出摘要的每個詞,并以局部注意力機制提升效果。NALLAPATI等[3]融入傳統的TF-IDF,POS、命名實體等特征來提升效果,引入Pointer解決未知詞和低頻詞。HU等[4]提供了一個新的中文短文本摘要數據集(數據來源為新浪微博),并根據正文和摘要之間的相關性進行了人工評分。YAO等[5]總結了近幾年文本摘要領域的新方法,從抽取式和生成式、單文檔和多文檔這幾方面進行評價,包括數據集和評價方法等。摘要生成時,其輸出句子的長度較難把控,為解決這個問題,KIKUCHI等[6]提出在解碼器端,將原摘要的長度信息輸入到LSTM中進行控制,取得了較好的結果。ZENG 等[7]考慮到人工編寫摘要時通常需要先對全文內容通讀以了解文章主題,提出將全文信息通過RNN編碼為一個向量,再進行解碼。SEE等[8]通過在輸出端對下一個詞的生成或復制的概率進行預測,解決OOV(out-of-vocabulary)和低頻詞的問題。GEHRING等[9]將編碼器和解碼器用卷積神經網絡替代,達到了接近state-of-the-art的表現。CHANG等[10]在生成中文摘要時,當編碼器輸入詞時可使模型獲得較多的信息,解碼器輸出字時可壓縮并精簡文章的內容。MA等[11]在訓練時將摘要內容進行自編碼,監督生成的原始內容編碼,使編碼器生成的內容更加接近參考摘要。PAULUS等[12]提出內注意力機制解決重復詞語的問題,訓練方法中融合了監督學習和強化學習以提升效果。WANG等[13]以convolutional sequence to sequence(ConvS2S)為基礎,將主題信息融入其中,使用強化學習訓練方法優化。FAN等[14]根據用戶寫作摘要的風格,包括摘要長度、用詞等特征生成摘要。GAO等[15]提出了讀者感知生成摘要的任務,設計了一個名為讀者感知摘要生成器(RASG)的對抗性學習模型,將讀者的評論納入生成式摘要。針對PECH(產品感知答案生成)任務,GAO等[16]設計了一種基于對抗性學習的模型PAAG,提出一種基于注意力機制的閱讀審查方式,用來捕獲給定的問題中與評論相關度最高的詞語。
和上述工作不同的是,筆者提出基于Seq2Seq的框架,在上下文特征中加入由卷積神經網絡提取的詞匯特征,根據詞性信息判斷詞匯的重要性,進而保留文章的重點內容,完成文本摘要的生成。
2融合詞匯特征模型
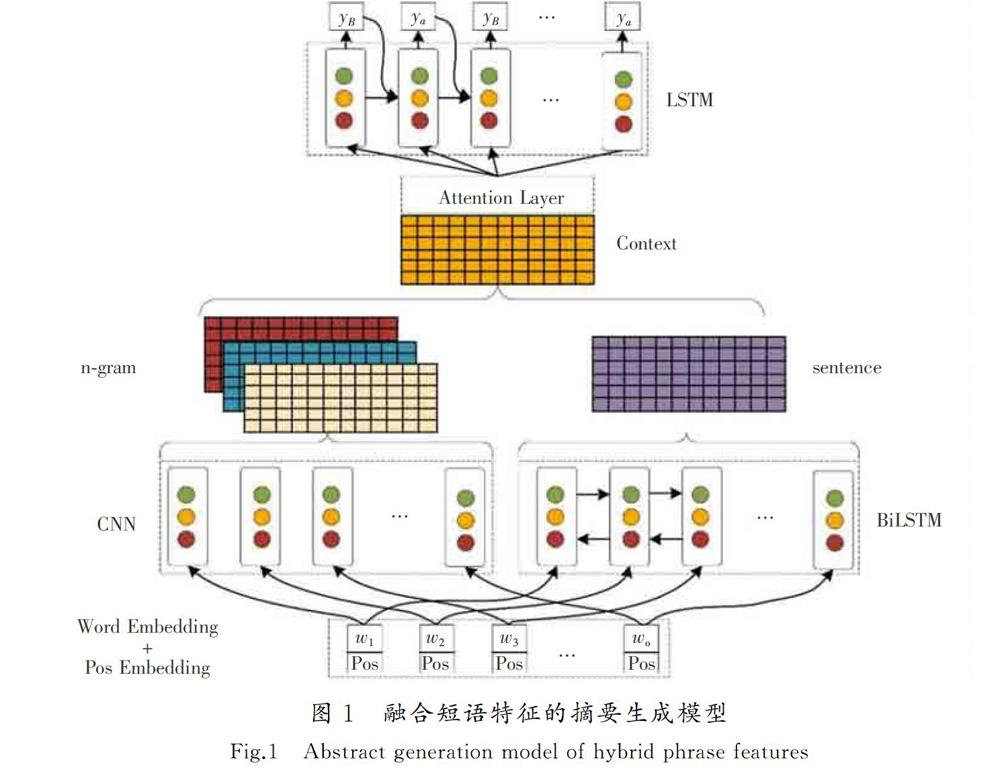
以Seq2Seq為基礎框架模型,結構如圖1所示。在輸入層,使用詞性向量和詞向量進行疊加,構成整個網絡的輸入向量。在編碼器端,分為2部分:一部分使用雙向LSTM[17]模型,對分詞后的源文本內容進行句子級別的淺層表征學習;另一部分使用卷積神經網絡對所有詞匯提取n-gram和詞性特征,最后將2部分學習到的特征矩陣融合在一起,構成上下文向量。在輸出摘要時使用單向的LSTM,每個時間步都需要對上下文特征矩陣進行注意力權重的分配,進而生成詞匯。
2.1構建輸入層向量
融合短語特征的自動摘要模型的輸入由2部分構成,第1部分將分詞后的源文本轉換成詞向量,使用xw={xw1,xw2,…,xwn}來表示;第2部分將源文本的詞性轉換為向量,用xp={xp1,xp2,…,xpn}表示,其中n表示輸入詞性的索引。最后,對輸入序列的詞向量和詞性向量連接,得到帶有詞性特征的輸入向量wp,如式(1)所示。wpn=∑ni=1[xwi;xpi]。 ????????????????????????????(1)2.2Seq2Seq模型
編碼器使用雙向LSTM模型,輸入的是帶有詞性特征的向量,通常將編碼器所有輸出的隱藏狀態作為原始句子的淺層語義表示,在解碼器端對該向量進行解碼。由于模型所使用的是雙向LSTM,每個時間步都接收來自前一時刻或后一時刻的隱層狀態,所以在每個時間步需要對前向和后向的各個隱層狀態向量進行連接,得到包含前后語義的隱藏狀態。式(2)中t,t+1表示后一時刻的隱層向量,式(3)中t,t-1表示前一時刻的隱層向量,式(4)中t表示當前時刻融合前向和后向的隱層向量,對于解碼器同樣使用LSTM神經網絡進行解碼。t,t=LSTM(wpi,t+1,t+1),(2)
t,t=LSTM(wpi,t-1,t-1),(3)
t=[t:t]。(4)式(5)中st表示解碼器端的隱藏向量,ct表示LSTM中的狀態向量。式(6)中yt表示每個時間步輸出的摘要序列詞匯。st=LSTM(ct,yt-1,st-1),(5)
yt=softmag(g[ct;st])。(6)2.3融合詞匯特征
借鑒LIN 等[18]的工作內容,依據其設定的卷積神經網絡結構,卷積核的大小依次設定為k=1,k=3,使卷積神經網絡能提取詞匯的n-gram的特征。在卷積層,將包含詞性的詞性序列作為基本單位輸入到網絡中,使用多個與輸入向量維度相一致的卷積單元學習詞匯特征。假設整個輸入序列的長度為n,對于每個卷積單元,經過一次卷積后,生成與輸入矩陣大小相同的特征矩陣,最后將多個卷積結果和編碼器的隱層狀態連接,使用全連接層學習多種特征融合。h=(W[g1,g2,g3,]+b)。(7)式(7)中h為最終的編碼器隱層向量,維度為m×n,m代表輸入向量的維度,n表示輸入序列的長度,其中g1,g2,g3表示由卷積層輸出的特征矩陣。表示激活函數GLU[19]。得到融合詞匯特征和句子特征的隱層向量后,引入注意力機制[20]來捕獲輸出內容與上下文向量的關聯程度。ct=∑Ni=1αtihi, ???????????????????????????????(8)
αt=exp(eij)∑Tk=1exp(eik),(9)
eij=α(si-1,hj)。(10)式(8)—式(10)中,ct表示當前時刻的上下文向量,eij表示解碼器端隱層狀態st-1和編碼器隱層狀態hj之間的相關系數。當輸出摘要時,需要將得到上下文的向量ct輸入到解碼器的LSTM單元中。
2.4損失函數
本文訓練的模型采用反向傳播方式,目標函數(代價函數)為交叉熵代價函數,將yt作為輸出生成的摘要詞匯,X為源文本輸入序列,模型訓練的目標是在給定輸入語句的情況下最大化每個輸出摘要詞的概率。式(11)中k表示同一個訓練批次句子的索引,t表示句中輸入詞匯的索引。Δ=-1N∑Nk=1∑Tt=1log[p(y(k)t|y(k) 3實驗 3.1數據集描述 本文模型所使用的第一個數據集是大規模的中文短文本摘要數據集LCSTS[4],主要是收集自新浪微博的內容,總共包含超過240多萬條摘要文本內容。每對摘要文本中,其原始內容少于140個字,摘要則由人工編寫。數據集共分為3部分,第1部分約240萬對,第2部分約1萬對,第3部分約1千對,其中第2部分和第3部分由人工方式對標題和正文之間的相關度按照1至5進行評分,得分越高相關度越高。按照HU等[4]的工作內容,將數據集分割為訓練集、驗證集和測試集。另外,還使用第2個數據集,以人工方式收集并整理20條微博內容供模型測試使用,參考摘要和原文內容的抽取方式與LCSTS[4]數據集的抽取方式相同。 3.2實驗參數設置 模型中詞向量的維度為512,詞性向量的維度為50,經過網絡合并輸出后的特征維度為562。以每64個樣本為一個批次的方式進行模型訓練,設置Adam[21]的學習率為 0.001,設置代價函數的懲罰項為0.001。同時設置編碼器的LSTM神經網絡層數為3層,解碼器的LSTM神經網絡為1層,每個卷積層的輸出維度與輸入向量維度保持一致。該摘要生成模型運行在Ubuntu 16.04系統,運行環境為PyTorch0.4和NVIDIA GTX 1080ti顯卡。 3.3評價指標設定 實驗借鑒RUSH等[1]的工作內容,使用自動文本摘要的相關評測標準ROUGE[22]。該評測方法基于生成摘要和參考摘要中n-gram的共現信息來評價摘要質量,現在被廣泛應用于DUC評測任務。評測標準包括ROUGE-N,ROUGE-L等。其中N表示N元詞,而L表示最長公共序列。ROUGE-N的計算方式為ROUGE-N=∑S∈sumref∑gramn∈Scountmatch(gramn)∑S∈sumref∑gramn∈Scount(gramn),(12)式中:sumref表示參考摘要;countmatch(gramn)表示由模型生成的摘要和標準參考摘要中共同出現的n元詞個數,count(gramn)則表示標準參考摘要中出現n元詞的個數。ROUGE-L表示模型生成摘要與標準參考摘要之間,最長的公共序列長度與參考摘要長度之間的比值。ROUGE-L相比于ROUGE-N考慮了摘要中詞語的次序,評價更為合理。 4實驗結果及分析 本文所使用的對比模型是RNN[14]和RNN content[14]。其中,RNN content使用了上下文向量Content,將所有的編碼器輸出作為解碼器的輸入;RNN(W)使用的是jieba分詞后的文本進行訓練;RNN(C)使用基于詞的方法訓練模型。Seq2Seq是本文所實現的基于Seq2Seq并結合注意力機制的模型,其編碼器和解碼器使用的分別為雙向LSTM和單向LSTM。 表1給出的是不同模型的ROUGE測度值。本文所提出的融合詞匯特征的摘要生成模型與其他4種模型相比,性能有所提升。從表1中可以看出,使用雙向LSTM作為解碼器的Seq2Seq模型,要比單向的RNN作為編碼器的模型在ROUGE-1,ROUGE-2和ROUGE-L上分別提升0.013,0.020,0.019,說明使用雙向LSTM更能捕捉文章特征信息。融合詞匯特征的模型(HN)在基于Seq2Seq框架的基礎上,增加詞匯特征的融合要比不使用詞匯特征的模型在ROUGE-1,ROUGE-2和ROUGE-L上的指標均有所提升。實驗效果證明融合詞匯特征的模型比無詞匯特征的模型效果要更好一些。 這里給出另一組與圖2中的實驗結果樣例。源文本是:昨晚,南車、北車陸續發布公告。據一財記者多方了解,公告所提到的“籌劃重大事項”,正是醞釀將南北車合并,合并一事由國務院要求推進,并由國務委員王勇負責督辦,而合并背后的導火索,是兩家公司在海外市場競相壓價的“惡性競爭”。生成的摘要內容:避免海外惡性競爭國務委員牽頭推南北車合并。圖2縱軸代表生成的摘要內容,橫軸代表原文內容,由于篇幅所限,只截取具有代表性的內容。從圖2中可以看到,在生成的摘要詞匯和原文詞匯間注意力權重的不同,如原文內容中的“合并一事由國務院要求推進”與摘要中的“國務委員牽頭推南北車合并”,這兩段文本間色塊的深度明顯大于其他部分,表示這兩段內容間有較強的關聯性。但圖2中也有一些注意力權重未能達到預期效果,如原文中的“由國務院”的“由”字和摘要中“南北車”的“車”字相關性最高,導致權重分配錯誤的原因可能是因為在模型訓練過程中,對一些頻繁出現的搭配進行了錯誤的學習,解決途徑之一是增加訓練集,以降低某些錯誤固定搭配的比例。 表3所示的為本文所實現的HN模型和Seq2Seq模型在測試集2上的ROUGE分數。從表3中可看到HN模型生成摘要的ROUGE分數比Seq2Seq的要更高一點。說明本文所實現的模型在其他測試集上,也比單純的結合注意力機制的Seq2Seq模型更優。但測試集1的ROUGE分數明顯高于測試集2上的分數,主要由于測試集2為人工收集的數據集,考慮到成本問題,只有20條,數據不具有廣泛的代表性,僅作為比較模型的優劣程度的指標。 5結語 筆者提出的融合詞匯特征的模型應用卷積神經網絡從原文本中提取詞匯特征,采用雙向LSTM提取句子特征,然后將詞匯特征與句子特征相融合,以達到利用詞匯特征尋找文章中重點內容的需求。通過與其他模型相比較,證明了融合詞匯特征的模型是有效的。 雖然所提出的模型達到了預期效果,但仍然有較大的提升空間,首先本文的模型只是通過非線性函數融合句子特征和詞匯特征,未對詞匯特征的權重進行進一步優化,以后可考慮使用多層次注意力機制,對詞匯特征進一步提取。其次在做摘要任務時,需要考慮文章的主題信息,而且如果文章內容較長時,在模型的訓練過程中通常會出現梯度爆炸或梯度消失等問題,也不利于模型提取重要信息。未來可進一步考慮在長文本內容中,使用劃分文章段落和句子的層次結構的方法縮短序列,達到分塊提取重要信息的需求,同時可加入文章主題信息作為監督,保證模型生成的摘要和文章主題相一致。 參考文獻/References: [1]RUSH A M, CHOPRA S, WESTON J. A neural attention model for abstractive sentence summarization[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon:[s.n.], 2015:379-389. [2]CHOPRA S, AULI M, RUSH A M. Abstractive sentence summarization with attentive recurrent neural networks[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. San Diego:[s.n.], 2016: 93-98. [3]NALLAPATI R, ZHOU B, SANTOS C N D, et al. Abstractive text summarization using sequence-to-sequence rnns and beyond[C]//Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. Berlin:[s.n.],2016:280-290. [4]HU Baotian, CHEN Qingcai, ZHU Fangze. LCSTS:A large scale Chinese short text summarization dataset[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon:[s.n.],2015: 1967-1972. [5]YAO Jinge, WAN Xiaojun, XIAO Jianguo. Recent advances in document summarization[J]. Knowledge and Information Systems, 2017, 53(2): 297-336. [6]KIKUCHI Y, NEUBIG G, SASANO R, et al. Controlling output length in neural encoder-decoders[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin:[s.n.], 2016:1328-1338. [7]ZENG Wenyuan, LUO Wenjie, FIDLER S, et al. Efficient summarization with read-again and copy mechanism[C]// Proceedings of the International Conference on Learning Representations.[S.l.]:[s.n.],2017:1-13. [8]SEE A, LIU P J, MANNING C D. Get to the point: Summarization with pointer-generator networks[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. [S.l.]:[s.n.],2017:1073-1083. [9]GEHRING J, AULI M, GRANGIER D, et al. Convolutional sequence to sequence learning[C]//Proceedings of the 34th International Conference on Machine Learning. [S.l.]:[s.n.],2017: 1243-1252. [10]CHANG C T, HUANG C C, HSU J Y J, et al. A hybrid word-character model for abstractive summarization[EB/OL]. https://arxiv.org/pdf/1802.09968v2.pdf, 2018-02-28. [11]MA Shuming, SUN Xu, LIN Junyang, et al. Autoencoder as assistant supervisor: Improving text representation for Chinese social media text summarization[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers). Melbourne:[s.n.], 2018:725-731. [12]PAULUS R, XIONG Caiming, SOCHER R. A deep reinforced model for abstractive summarization[C]//Proceedings of Sixth International Conference on Learning Representations. [S.l.]:[s.n.],2017:1-13. [13]WANG Li, YAO Junlin, TAO Yunzhe, et al. A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI). [S.l.]:[s.n.], 2018: 4453-4460. [14]FAN A, GRANGIER D, AULI M. Controllable abstractive summarization[C]//Proceedings of the 2nd Workshop on Neural Machine Translation and Generation. Melbourne:[s.n.],2017:45-54. [15]GAO Shen, CHEN Xiuying, LI Piji, et al. Abstractive text summarization by incorporating reader comments[EB/OL]. https://arxiv.org/pdf/1812.05407v1.pdf, 2018-12-13. [16]GAO Shen, CHEN Xiuying, LI Piji,et al. Product-aware answer generation in e-commerce question-answering[C]//Proceedings of the 12th ACM International Conference on Web Search and Data Mining.[S.l.]:[s.n.],2019:07696. [17]HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. [18]LIN Junyang, SUN Xu, MA Shuming, et al. Global encoding for abstractive summarization[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics(Short Papers). Melbourne:[s.n.], 2018:163-169. [19]DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks[C]//Proceedings of the 34th International Conference on Machine Learning. Sydney:[s.n.], 2017: 933-941. [20]BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[C]// Proceedings of International Conference on Learning Representations.San Diego:[s.n.], 2015:14090473V6. [21]KINGMA D P, BA J L. Adam: A method for stochastic optimization[C]//Proceedings of International Conference on Learning Representations.San Diego:[s.n.], 2015:1412.6980V9. [22]LIN C Y, HOVY E. Automatic evaluation of summaries using N-gram co-occurrence statistics[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology.Stroudsburg:[s.n.], 2003:71-78.第40卷第2期河北科技大學學報Vol.40,No.2 2019年4月Journal of Hebei University of Science and TechnologyApr. 2019
