熵權(quán)法并聯(lián)組合模型在大壩變形監(jiān)測(cè)中的應(yīng)用
2019-06-22 03:42:50鄭旭東陳天偉鄧捷利段青達(dá)
水力發(fā)電 2019年3期
鄭旭東,陳天偉,鄧捷利,段青達(dá),甘 若,王 雷
(1.桂林理工大學(xué)測(cè)繪地理信息學(xué)院,廣西桂林541004;2.廣西空間信息與測(cè)繪重點(diǎn)實(shí)驗(yàn)室,廣西桂林541004)
0 引 言
目前,大壩變形預(yù)測(cè)的方法主要有BP神經(jīng)網(wǎng)絡(luò)法、支持向量機(jī)法、相關(guān)向量機(jī)法、時(shí)間序列法等[1]。由于大壩工程的復(fù)雜性,以及外界條件的不確定性,決定了使用單一預(yù)測(cè)模型進(jìn)行變形預(yù)測(cè)時(shí),難以得到預(yù)測(cè)精度和預(yù)測(cè)期數(shù)都較為優(yōu)秀的預(yù)測(cè)結(jié)果。針對(duì)大壩變形預(yù)測(cè)中存在的種種問題,部分學(xué)者進(jìn)行了如下研究:王利等使用改進(jìn)灰色模型在大壩沉降預(yù)測(cè)中取得相對(duì)誤差小于2%的預(yù)測(cè)結(jié)果[2];何啟等使用改進(jìn)的加權(quán)馬爾可夫鏈模型得到了平均相對(duì)誤差為0.71%的預(yù)測(cè)結(jié)果[3];覃邵峰使用改進(jìn)的ARIMA模型在大壩變形預(yù)測(cè)中平均相對(duì)誤差為0.48%[4]。為了能在實(shí)際預(yù)測(cè)中盡可能地發(fā)揮單一模型的預(yù)測(cè)優(yōu)勢(shì),又能約束各自的缺陷,本文基于信息熵原理提出熵權(quán)法并聯(lián)組合模型。使用灰色—加權(quán)馬爾可夫鏈預(yù)測(cè)模型用于解決變形預(yù)測(cè)中“少數(shù)據(jù),貧信息”以及灰色模型預(yù)測(cè)周期短的問題,同時(shí)使用ARIMA模型來(lái)提高預(yù)測(cè)結(jié)果的精度,利用最大熵原理對(duì)兩模型合理組合,得到一個(gè)精度更高、更加合理的預(yù)測(cè)模型。
1 模型介紹
1.1 灰色—加權(quán)馬爾可夫鏈
1.1.1灰色預(yù)測(cè)模型GM(1.1)
灰色理論主要研究“小樣本,貧信息”的不確定系統(tǒng)的問題[5]。建立灰色模型時(shí),為了淡化原始數(shù)據(jù)隨機(jī)性誤差的影響,首先對(duì)原始數(shù)據(jù)進(jìn)行累加處理,再用微分方程進(jìn)行建模,最后對(duì)模型值進(jìn)行還原,得到預(yù)測(cè)值。由于該模型在其他文獻(xiàn)中出現(xiàn)較多,本文不再加以詳述。
1.1.2加權(quán)馬爾可夫鏈預(yù)測(cè)
對(duì)于一組隨機(jī)變量,在驗(yàn)證其滿足“馬氏性”后,通過(guò)各步長(zhǎng)的狀態(tài)轉(zhuǎn)移矩陣,以及其相對(duì)應(yīng)的狀態(tài)做出預(yù)測(cè)后,利用其各階自相關(guān)系數(shù)能夠描述出各種滯時(shí)指標(biāo)值相關(guān)關(guān)系的強(qiáng)弱這一特性[6],對(duì)各步長(zhǎng)的預(yù)測(cè)結(jié)果按照相依關(guān)系的強(qiáng)弱進(jìn)行加權(quán)平均,這就是加權(quán)馬爾可夫鏈預(yù)測(cè)法的基本思想。
加權(quán)馬爾可夫鏈預(yù)測(cè)的步驟:
(2)“馬氏性”檢驗(yàn)。
(3)計(jì)算各階自相關(guān)系數(shù)rk,k∈E
(1)
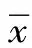
(2)
式中,wk為各個(gè)滯時(shí)(即步長(zhǎng))的馬爾可夫鏈的權(quán)重;m為預(yù)測(cè)的最大階數(shù)。
(4)根據(jù)步驟(1)所劃分的狀態(tài),統(tǒng)計(jì)出各步長(zhǎng)的狀態(tài)轉(zhuǎn)移概率矩陣。
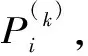
(6)將同一狀態(tài)的各預(yù)測(cè)概率加權(quán)求和作為該指標(biāo)值處于該狀態(tài)的預(yù)測(cè)概率,即
(3)
則最終該指標(biāo)值的預(yù)測(cè)狀態(tài),即max{Pi,i∈E}。
(7)求出級(jí)別特征值對(duì)預(yù)測(cè)值進(jìn)行估算[7]。待該指標(biāo)值預(yù)測(cè)完成后,將預(yù)測(cè)值加入到原始序列中,重復(fù)步驟(1)~(7)即可完成對(duì)下一指標(biāo)值的滾動(dòng)預(yù)測(cè)。
1.1.3灰色—加權(quán)馬爾可夫鏈
灰色預(yù)測(cè)模型的優(yōu)點(diǎn)是需要的數(shù)據(jù)信息較少,但其預(yù)測(cè)時(shí)間較短,而且對(duì)于波動(dòng)性較大的數(shù)據(jù),預(yù)測(cè)效果也不盡人意。而馬爾可夫鏈預(yù)測(cè)模型是通過(guò)統(tǒng)計(jì)原始序列得到狀態(tài)轉(zhuǎn)移概率矩陣進(jìn)行預(yù)測(cè),能夠在對(duì)變化較大的隨機(jī)序列的預(yù)測(cè)中取得不錯(cuò)的效果,但其需要足夠多的原始數(shù)據(jù)來(lái)統(tǒng)計(jì)出原始序列的內(nèi)在規(guī)律。故將兩模型進(jìn)行串聯(lián)組合,用馬爾可夫鏈預(yù)測(cè)模型對(duì)灰色模型的結(jié)果進(jìn)行改正,以提高預(yù)測(cè)精度。其具體步驟如下:
(1)將灰色模型的擬合值和實(shí)際觀測(cè)值進(jìn)行對(duì)比,求出相對(duì)誤差。
(2)用求出的相對(duì)誤差進(jìn)行馬爾可夫鏈建模,由馬爾可夫鏈預(yù)測(cè)模型預(yù)測(cè)出某時(shí)段的相對(duì)誤差。
(3)用馬爾可夫鏈預(yù)測(cè)模型預(yù)測(cè)出的相對(duì)誤差對(duì)灰色模型的預(yù)測(cè)值進(jìn)行改正。
1.2 ARIMA模型
ARIMA模型也寫作為ARIMA(p,d,q)模型,它的實(shí)質(zhì)是將ARIMA(p,q)進(jìn)行d階差分得到的。通過(guò)這樣的操作,把一個(gè)非平穩(wěn)的時(shí)間序列轉(zhuǎn)化成一個(gè)平穩(wěn)的時(shí)間序列,再通過(guò)觀察相關(guān)函數(shù)結(jié)尾和拖尾特征得到自回歸階數(shù)p和移動(dòng)平均階數(shù)q,對(duì)時(shí)間序列進(jìn)行ARIMA建模,達(dá)到預(yù)測(cè)的效果[8]。ARIMA模型為
φ(B)(1-B)dYt=θ(B)et或
φ(B)dYt=θ(B)et
(4)
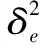
1.3 基于熵權(quán)法的組合模型
并聯(lián)組合模型的關(guān)鍵在于對(duì)單一模型的確定及單一模型權(quán)重的確定。本文采用熵權(quán)法確定各個(gè)單一模型權(quán)重,建立組合模型來(lái)預(yù)測(cè)大壩變形的數(shù)據(jù)。熵權(quán)法是根據(jù)評(píng)價(jià)對(duì)象的指標(biāo)值構(gòu)成的判斷矩陣來(lái)確定權(quán)重的一種方法。如果把信息熵理解為某種特定信息xi出現(xiàn)的概率p(xi),那么信息熵H(x)的定義為
(5)
根據(jù)信息熵的定義可知,我們將特定信息認(rèn)為是單項(xiàng)預(yù)測(cè)模型的誤差,如果單項(xiàng)模型的誤差的信息熵越小,其變異程度也就越大,則該單項(xiàng)預(yù)測(cè)模型的權(quán)重也越小。反之,模型誤差的信息越大,那么其變異程度越小,則模型的權(quán)重也就越大[9]。
因此,可以利用信息熵原理來(lái)確定單一模型的權(quán)重。具體步驟如下:
(1)計(jì)算單個(gè)模型對(duì)應(yīng)時(shí)刻的相對(duì)誤差權(quán)重
(6)
式中,eij為第i個(gè)模型第j時(shí)刻的相對(duì)誤差。
(2)計(jì)算第i個(gè)模型相對(duì)誤差的熵值
(7)
式中,k=1/lnn,其中,n為選擇的單一模型數(shù)量。
(3)計(jì)算第i個(gè)模型相對(duì)誤差序列的變異程度系數(shù)
di=1-Hi
(8)
(4)計(jì)算第i個(gè)模型的權(quán)重系數(shù)
(9)
(5)將單一模型的預(yù)測(cè)值和求得的權(quán)重加權(quán)求和,獲得組合模型的預(yù)測(cè)值
(10)
式中,yi為單一模型的預(yù)測(cè)值。
組合預(yù)測(cè)模型建模基本流程如圖1所示。
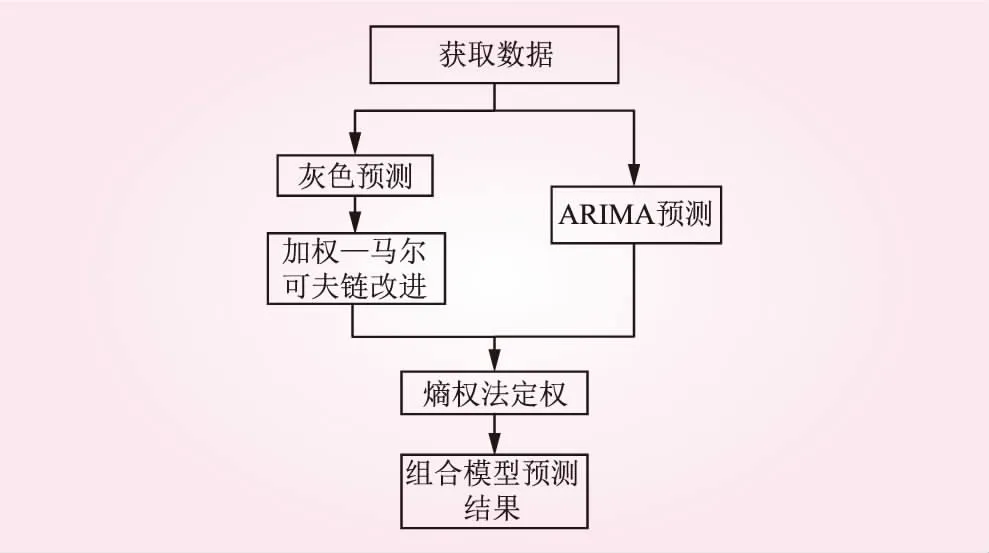
圖1 組合模型建模流程

表1 各模型預(yù)測(cè)值對(duì)比
2 具體實(shí)例
本文以某大壩水平變形監(jiān)測(cè)點(diǎn)水平徑向位移觀測(cè)值為例,數(shù)據(jù)來(lái)源于文獻(xiàn)[2,10]。這里取前16期的觀測(cè)值作為原始起算數(shù)據(jù),后4期數(shù)據(jù)和預(yù)測(cè)數(shù)據(jù)進(jìn)行對(duì)比。觀測(cè)原始數(shù)據(jù)如圖2所示。
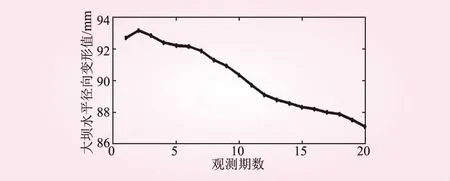
圖2 原始數(shù)據(jù)
2.1 單項(xiàng)模型預(yù)測(cè)
將灰色模型預(yù)測(cè)得到的前16期的擬合值與實(shí)際觀測(cè)值對(duì)比得到的相對(duì)誤差,對(duì)相對(duì)誤差進(jìn)行馬氏性檢驗(yàn),用馬爾可夫鏈模型進(jìn)行建模,預(yù)測(cè)得到后4期相對(duì)誤差,用此結(jié)果對(duì)灰色模型的預(yù)測(cè)值進(jìn)行改進(jìn),即可得到灰色—加權(quán)馬爾可夫鏈預(yù)測(cè)模型的預(yù)測(cè)值;將前16期數(shù)據(jù)進(jìn)行一階差分處理,對(duì)處理的數(shù)據(jù)進(jìn)行自回歸系數(shù)與偏回歸系數(shù)分析,確定ARIMA(p,d,q)模型的參數(shù)。經(jīng)分析,確定p=3,d=1,q=3。利用SPSS軟件進(jìn)行ARIMA建模,獲得預(yù)測(cè)值。其結(jié)果見表1。
2.2 單項(xiàng)模型熵權(quán)計(jì)算
根據(jù)前文介紹的熵權(quán)計(jì)算公式以及兩個(gè)單一模型的變形值的預(yù)測(cè)結(jié)果,可得到灰色—加權(quán)馬爾可夫鏈預(yù)測(cè)模型,ARIMA預(yù)測(cè)模型在并聯(lián)組合模型中所占的權(quán)重分別為:ω1=0.75,ω2=0.25;再由式(10)求得最終大壩水平徑向位移的預(yù)測(cè)值Y={87.837,87.555,87.196,86.862}。
2.3 結(jié)果分析
為了更加直觀的表現(xiàn)出3種模型的預(yù)測(cè)效果,把3種模型的預(yù)測(cè)結(jié)果與實(shí)測(cè)值的對(duì)比用折線圖的形式表現(xiàn),如圖3所示。
表中,模型一是指灰色—加權(quán)馬爾可夫鏈模型,模型二是指ARIMA模型,模型三是指基于熵權(quán)法的組合模型。
從表1、圖3分析相對(duì)誤差可得,組合模型預(yù)測(cè)效果最好,平均相對(duì)誤差約為-0.26%,其次為ARIMA預(yù)測(cè)模型,平均相對(duì)誤差約為0.27%;加權(quán)馬爾可夫鏈預(yù)測(cè)模型相對(duì)較差,平均相對(duì)誤差為0.46%。單就平均誤差而言,組合模型和ARIMA模型差別不大。為了進(jìn)一步分析3種模型的平穩(wěn)性以及精確度,按照整體評(píng)價(jià)預(yù)測(cè)方法的原則,引入以下評(píng)價(jià)
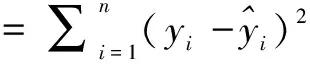
(10)

表3 預(yù)測(cè)結(jié)果對(duì)比
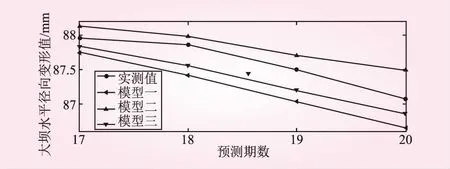
圖3 各模型預(yù)測(cè)值與真實(shí)值對(duì)比
(11)
根據(jù)以上兩種評(píng)價(jià)指標(biāo),得出預(yù)測(cè)評(píng)價(jià)結(jié)果見表2。

表2 模型的評(píng)價(jià)指標(biāo)對(duì)比
實(shí)例分析表明,組合模型的預(yù)測(cè)精度最好,與實(shí)際觀測(cè)數(shù)據(jù)相比較,Theil不等系數(shù)和誤差平方和均優(yōu)于單一的預(yù)測(cè)模型,顯示出它在大壩變形預(yù)測(cè)精度上的優(yōu)越性;其次,組合預(yù)測(cè)模型可以有效的彌補(bǔ)單一預(yù)測(cè)模型實(shí)際預(yù)測(cè)中存在的不足。對(duì)于現(xiàn)有的大壩變形預(yù)測(cè)模型而言,并聯(lián)加權(quán)模型可以合理的結(jié)合各單一模型的優(yōu)點(diǎn),提高預(yù)測(cè)結(jié)果精度。為避免其偶然性,筆者使用文獻(xiàn)[3]中的數(shù)據(jù)再次進(jìn)行實(shí)驗(yàn),求得的模型一和模型二的權(quán)重為ω1=0.14,ω2=0.86。由于篇幅限制,在此只對(duì)結(jié)果進(jìn)行呈現(xiàn)。其結(jié)果見表3、4。
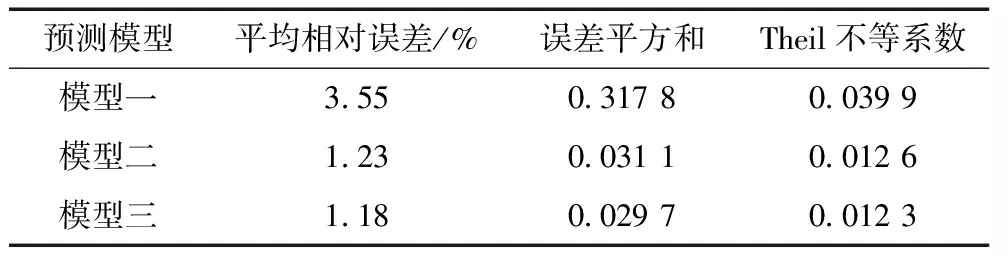
表4 預(yù)測(cè)結(jié)果精度指標(biāo)對(duì)比
由表3、4結(jié)果可知,對(duì)文獻(xiàn)中的大壩水平位移分別進(jìn)行灰色—加權(quán)馬爾可夫鏈模型,ARIMA模型和組合模型的預(yù)測(cè),得到的預(yù)測(cè)結(jié)果從平均相對(duì)誤差,誤差平方和,以及Theil不等系數(shù)來(lái)看組合模型均為最優(yōu),由此可見基于熵權(quán)法的并聯(lián)組合模型對(duì)于大壩變形預(yù)測(cè)來(lái)說(shuō)是一種行之有效的預(yù)測(cè)方法。
3 結(jié) 論
本文針對(duì)有限的觀測(cè)數(shù)據(jù),結(jié)合灰色理論適用于“小樣本、貧信息”的特點(diǎn);馬爾可夫鏈能夠準(zhǔn)確擬合波動(dòng)性較大的數(shù)據(jù)的特點(diǎn);ARIMA模型能夠挖掘非平穩(wěn)時(shí)間序列的內(nèi)部信息,擬合出變化趨勢(shì),從而實(shí)現(xiàn)預(yù)測(cè)目的,具有建模簡(jiǎn)單的特點(diǎn);并且結(jié)合最大熵的原理對(duì)模型進(jìn)行合理的組合,建立了基于最大熵原理的混合預(yù)測(cè)模型,通過(guò)實(shí)例驗(yàn)證了該模型對(duì)于小樣本序列預(yù)測(cè)精度較高。具體結(jié)論如下:
(1)基于信息熵原理,建立并聯(lián)組合模型來(lái)預(yù)測(cè)大壩的形變量,該方法在精度上較單一模型有所提高,并且平衡了單一模型的實(shí)測(cè)數(shù)據(jù)和樣本數(shù)據(jù)之間在質(zhì)量和數(shù)量上的需求,同時(shí)能夠平衡各單一模型的擬合及預(yù)測(cè)精度以及普適性等方面的優(yōu)點(diǎn)及缺點(diǎn)。
(2)基于信息熵原理,可對(duì)在真實(shí)值上下浮動(dòng)的單一模型的預(yù)測(cè)值進(jìn)行合理組合,減少了人為因素,使得組合模型在預(yù)測(cè)結(jié)果上更加接近真實(shí)值,從而提高了預(yù)測(cè)模型的預(yù)測(cè)精度以及合理性,為數(shù)據(jù)處理以及大壩變形預(yù)測(cè)提供了一條新的途經(jīng)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
中華詩(shī)詞(2020年1期)2020-09-21 09:24:52
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
小學(xué)生作文(中高年級(jí)適用)(2018年5期)2018-06-11 01:22:56
數(shù)學(xué)小靈通·3-4年級(jí)(2017年10期)2017-11-08 08:42:59
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2017年11期)2017-04-23 07:18:00
數(shù)學(xué)大王·中高年級(jí)(2016年12期)2016-12-26 21:37:36
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
