基于RFM模型的物流客戶價值研究
2019-08-01 03:43:20陳倩舒方曉平中南大學湖南長沙410075
物流科技 2019年7期
陳倩舒,方曉平 (中南大學,湖南 長沙 410075)
CHEN Qianshu,FANG Xiaoping (Central South University,Changsha 410075,China)
0 引言
隨著宏觀經濟穩定增長和消費升級下的電子商務發展,物流行業得以迅猛發展,同時行業之間的競爭也日益激烈。許多企業已從以產品為中心轉變為以客戶為中心的營銷策略,客戶關系管理成為企業管理的關鍵部分。客戶關系管理的核心問題是對不同類型的客戶進行價值分類,采用不同的定制化營銷策略,更好地服務顧客,以最大限度地實現企業的效益。由于表征客戶價值的特征信息的多維化,增加了客戶關系管理的難度。隨著大數據時代的來臨,大數據的商業價值已經顯現出來,大數據與挖掘技術為企業處理海量客戶數據與企業的經營決策提供了積極的幫助。
1 基于RFM模型分類原理
1.1 RFM模型介紹
RFM(Recency,Frequency,Monetary)模型是由Hughes AM于1994年提出的一種在企業角度方面考慮的可較全面分析客戶一般購買行為的客戶價值模型[1],模型包括3種指標:近度及額度分別表示最近的上次消費時間離樣本數據截止日的時間距離、研究期限內(樣本的時間跨度)的消費次數和消費總金額。消費近度越小,表示客戶在近段時間內有消費行為,并且消費近度越小和消費頻率越大,表示客戶忠誠度較高,下一次消費可能性較大;額度是企業衡量客戶利益價值的直接標準,額度越大說明客戶價值越高。Stahl H K(2003)提出一種多元行為特征分析,RFM模型及修正模型,來判斷客戶價值[2]。Fader P S(2005)通過提出“等值”曲線模型,將具有不同歷史行為,但未來價值相似的客戶聚集在一條等值線上,證明了RFM模型可擬合傳統現金流CLV模型[3]。一方面,現代營銷表明,從企業角度來看的客戶價值更高的是頻率和額度更大的客戶群,這類客戶在未來的時間段內很有可能產生消費行為,具有較高的預測效果;另一方面,RFM模型計算所需的客戶消費數據簡單易得且模型計算方便,在企業實踐應用中較為普遍。因此,企業可以使用RFM模型測量客戶價值,并使用RFM模型指標對客戶進行分類。RFM模型計算客戶價值公式如下所示:

在大多數的RFM模型應用時,識別客戶價值時各指標的權重相同,評估模型的關鍵在指標和權重兩個方面。在近度、頻率和額度3個因素中,近度和頻率是描述客戶行為的指標。有研究表明近度、頻率是忠誠度的良好指針,如Stone B(2008)、Wu J和Lin Z(2005)發現在信用卡消費領域,近度和頻率對客戶下一次消費有重要影響,因而給予近度最高權重,頻率、額度最小[4-5]。然而這并不表示額度不重要,畢竟從消費額度可以判斷客戶的交易規模與意愿。如果針對一個非高頻率、非消費型行業,或者客戶分層不是特別明顯的行業,則又另當別論了。所以很多學者認為還是應當根據行業競爭性、客戶類型(機構還是消費者)以及客戶的一致性等特點設定指標權重。所以有學者認為三者必須結合、不可偏廢才具有更好的判斷價值,如Hughes AM(2005)就認為在同一問題研究時,各指標對企業判斷客戶價值而言地位同等重要,故各指標權重可設為相同[1]。林盛、肖旭(2006)建議采用AHP方法與專家咨詢法相結合確定指標權重以便更好地考慮評估對象的具體情況[6]。學術界對各指標權重意見不一,是考慮到具體問題應當具體分析。因此在實際情況下,在識別物流客戶價值時,應考慮指標權重對物流客戶的價值的影響程度,本文應用層次分析法確定指標權重。
1.2 基于RFM模型分類
利用RFM模型對客戶進行細分有兩類方法,第一類是加權求和獲得價值評判值,再分段劃分類別。設置指標權重,使權重與RFM模型各指標的計算結果相乘得到各指標的加權指標值,讓最終的加權指標值相加以獲得RFM指標的總值,最后設置閾值以獲得客戶分類結果,并且大于閾值的為高價值客戶,小于閾值的為低價值客戶[4]。第二類是使用Sung(1998)提出的自組織特征映射網絡(SOM)來對客戶RFM指標進行分類,將每個客戶的RFM各指標值與RFM各指標平均值進行比較[7],可得到2*2*2=8種分類結果,其分類表示如表1和圖1所示:
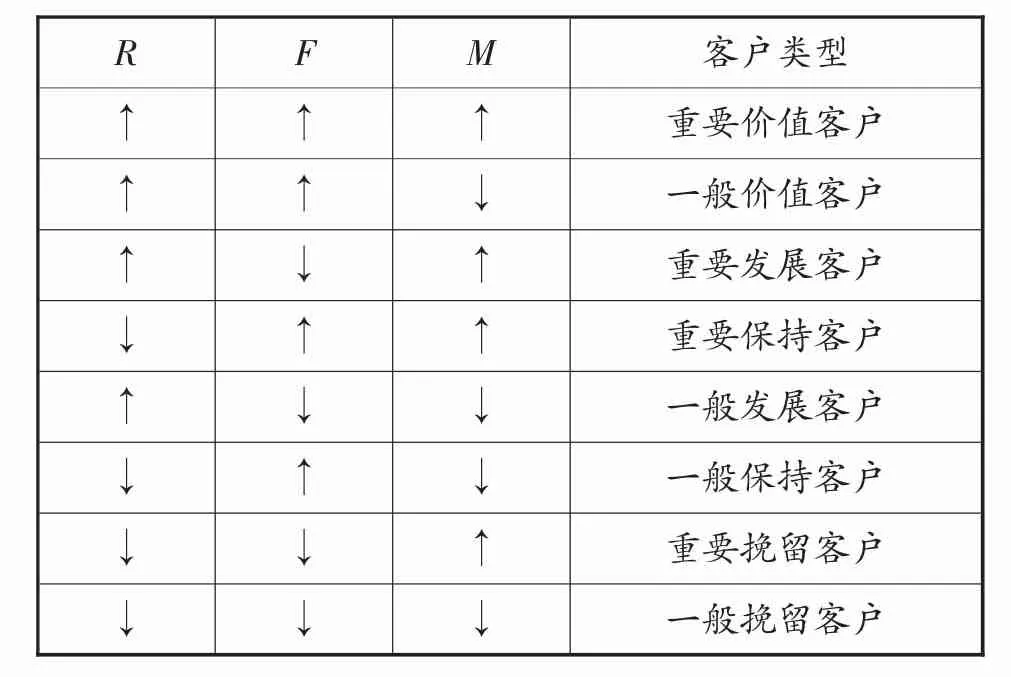
表1 依據RFM模型指標客戶分類結果
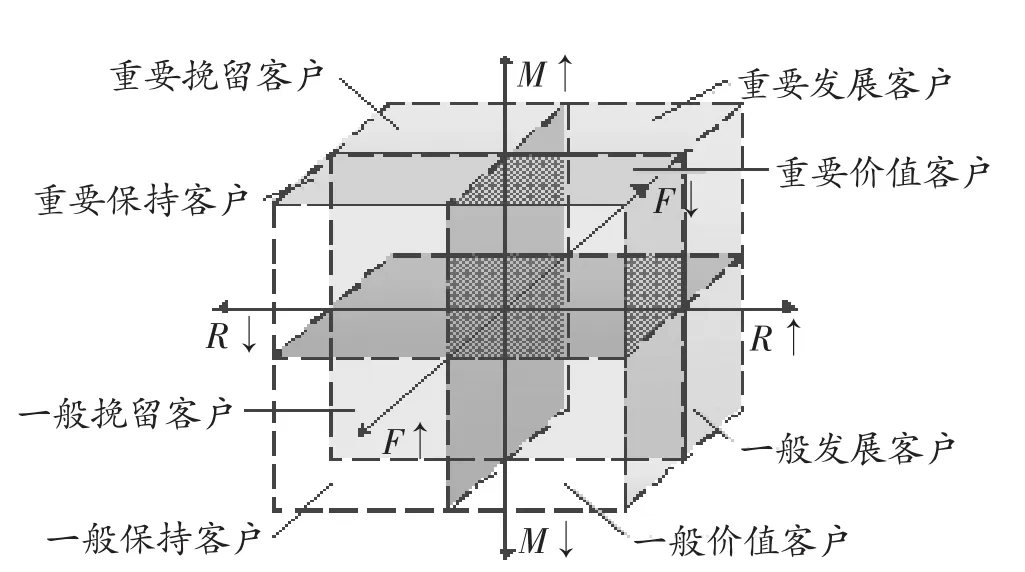
圖1 RFM模型分析
RFM模型是計算客戶價值并進行客戶細分的重要方法,使企業和客戶能夠相互進行個性化與精準化的管理服務,并且RFM模型能夠使企業快速的計算出客戶的潛在價值及客戶的生命周期價值。
面對不斷增長的客戶群,數據挖掘技術在客戶管理方面的應用日趨增加[8]。其中,聚類分析方法是一種屬于非監督型(unsupervised)機器學習的數據挖掘方法,這種分析方法適用于較大數據樣本和較多變量分析的任務[9]。聚類分析是以分類對象的具體特征為依據進行劃分,在數據樣本間的差異性和相似的基礎上進行分組,使同一組之間的數據樣本盡可能相似,不同組內的數據樣本盡可能有差異,劃分的原則是組內樣本最細、組外距離最大化,如圖2所示:
聚類分析是進行客戶細分的一個重要手段,因此在使用RFM模型時,有必要進行聚類分析[10]。聚類作為獨立的工具獲得數據分布情況,可作為其他算法的預處理步驟,簡化計算工作,提高分析效率[11],其中K-means聚類算法常于客戶細分。綜上,本文在基于RFM模型的基礎上利用K-means聚類算法對物流客戶進行細分識別。
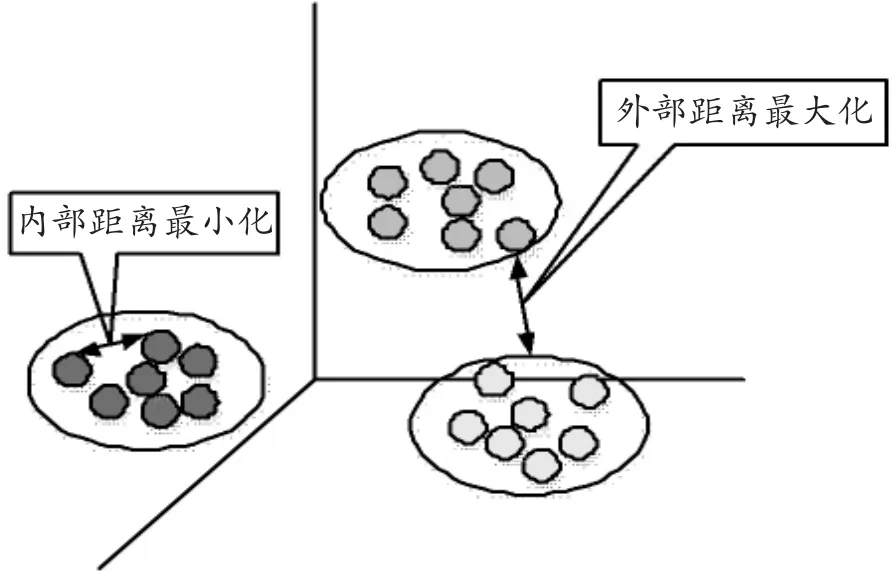
圖2 聚類分析建模原理
2 案例分析
2.1 數據抽取
由于與客戶在物流企業消費的行為方式,關于客戶的消費信息的基礎數據較容易獲得。客戶消費數據源自于企業A,全部數據都將進行脫敏處理,企業和客戶的信息不會泄露。企業A客戶歷史消費數據是2018年1~4月國內31個大區的營業數據,一共2 674 258條。每條數據包含44個屬性,包括客戶編號、購買時間、購買區域、發貨區域、發貨日期、消費額及運輸重量等。
2.2 數據預處理
因為企業在登記、保存客戶消費數據時可能小部分客戶消費數據存儲不完整,導致物流企業采集的數據不一致、重復及不規則等質量不高問題,最終使處理后的結果有偏差。所以為了確保后續計算步驟正確,有必要在使用RFM模型和K-means聚類算法之前預處理客戶消費數據。數據預處理主要包含數據清洗、指標規約、數據變換這3個方面的過程。
(1) 數據清洗
據統計,企業的數據一般存在1%~30%的誤差,忽略數據質量問題易導致研究結果錯誤[12]。由于企業在輸入客戶消費信息時存在錯誤的地方,因此數據中存在無效值和缺失值,需要使用數據清洗技術來適當的處理“臟數據”,數據清洗是按照一定的規則對數據進行再一次查看和校正的過程,主要是用于刪除重復數據、校正已有的錯誤及保證數據的一致性。
在企業A的2 674 258條客戶歷史消費記錄中,有525 815位客戶只有1次消費記錄,將其定義為偶然客戶,不列入分析。本文主要對有2次及2次以上有效消費記錄的客戶的2 148 443條記錄進行分析,占企業A原始數據的80.34%。
選擇與RFMS模型指標相關的客戶編號、購買時間、消費額3個屬性并刪除與其弱相關或冗余的屬性。在清洗數據發現此物流企業在采集客戶消費數據時存在小部分的缺失值,由于原始數據量大,且只存在291條異常數據,對研究影響不大,本文予以剔除處理。具體剔除操作規則如下:
①剔除客戶編號、購買時間與消費額為空的數據;
②剔除“*”和“—”等無效字符的記錄。
(2) 指標規約
利用清洗好的企業A的客戶歷史消費數據,根據客戶編號、購買時間與消費額3個屬性計算每位客戶的R指標、F指標及M指標原始值:
R:以天為單位,計算2018年1~4月各個客戶最后一次購買日期至2018年5月1日的天數,為R指標值;
F:在2017年1~4月這一時間段內客戶消費的總次數,為F指標值;
M:在2017年1~4月這一時間段內客戶消費的總金額,為M指標值。
經過指標規約后的數據如表2所示:
(3) 數據變換
通過指標規約后,對每個指標的數據分布情況進行分析,其數據的取值范圍如表3所示。從表3中數據可以發現,R指標、F指標及M指標取值范圍數據差異較大。
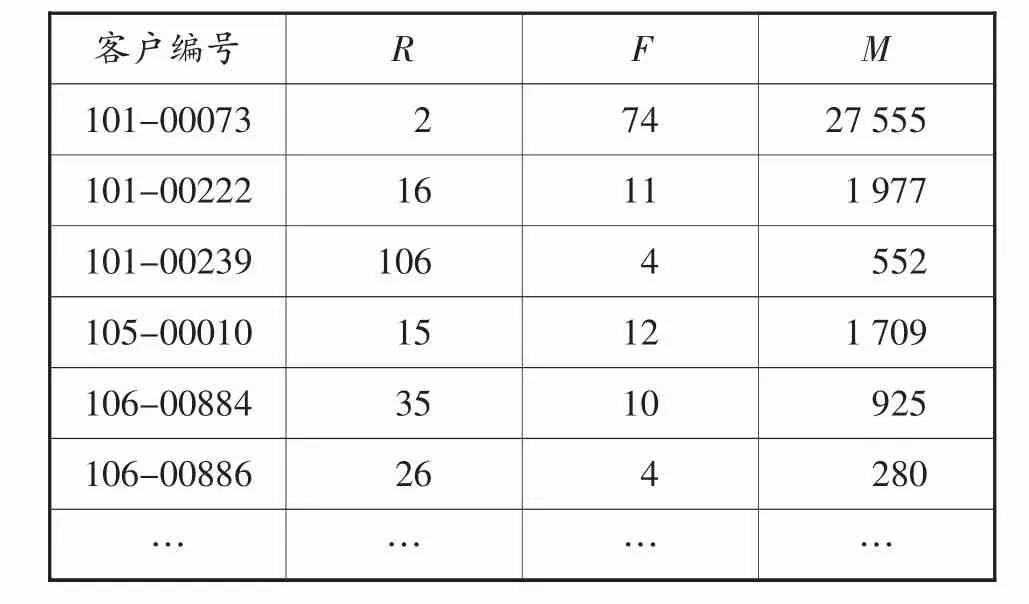
表2 物流企業的RFM模型指標規約
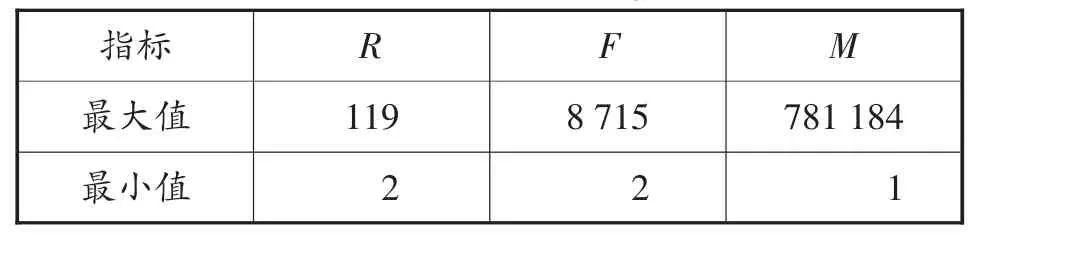
表3 RFMS模型特征取值范圍
在利用K-means聚類算法分析數據之前,一般需要將數據進行標準化變換,數據變換是指需要將數據轉換成“適當的”格式,以適應挖掘任務及算法的需要。上述標準化處理之后,將原始數據均轉換為無量綱化指標評估值,即各指標值都處于相同的數量級別,進行綜合評估分析。
考慮到RFMS模型各特征的計量單位對聚類分析產生差異化影響,為消除數量級帶來的影響,因此對RFMS模型中各特征值進行Z分數(Z—score)標準化變換。在以上討論的界定下,R、F及M標準化變換計算公式如式(2)~式(4)所示:指R、F及M的團體平均數;σR、σF、σM及指R、F及M的標準差。

對數據進行Z-score標準化變換后,得到284 125位客戶的RFM模型各指標變換計算大小如表4所示:
其中:T指樣本數據截止日;Ti指客戶上一次消費日;Mid指客戶i在區域d消費額度
2.3 層次分析法確定指標權重
根據本文對R、F及M這3項指標權重的確定,邀請業內5位資深人士參與打分。首先對R、F及M這3項指標的重要程度進行兩兩比較,依據這5位資深人士的打分情況結果,得出以下的判斷矩陣A如表5所示:
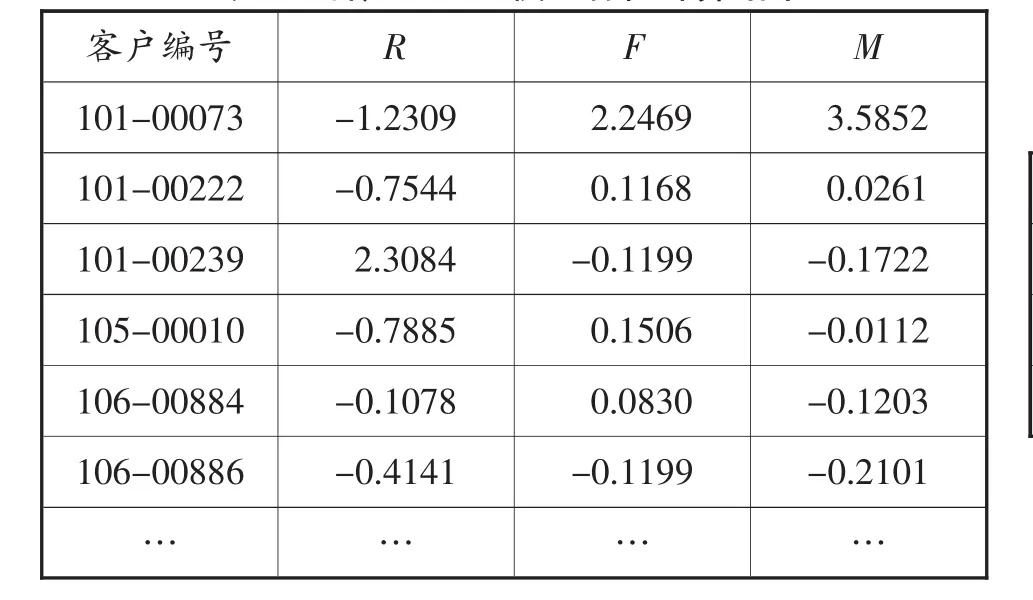
表4 客戶RFMS模型特征計算結果
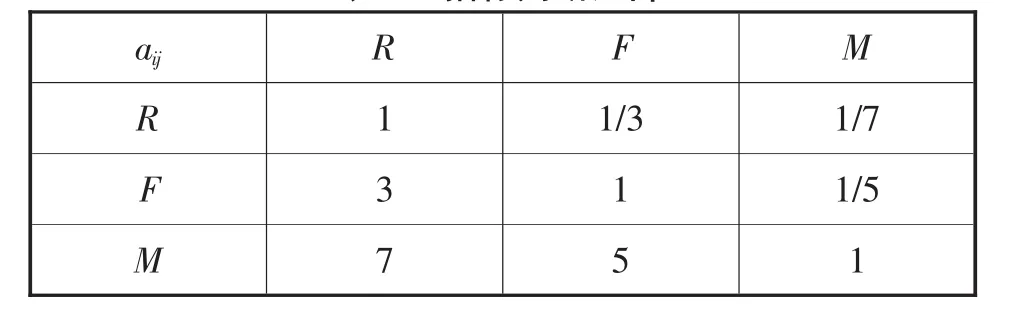
表5 指標判斷矩陣
判斷矩陣A通過一致性檢驗后得到RFM模型中各指標R、F及M權重分別為:wR=0.13;wF=0.23;wM=0.64。
2.4 基于RFM模型的K-means聚類
用K-means聚類算法中的有效性檢驗數發現,K=3時,聚類效果最佳,相應的聚類結果如表6所示。根據SOM對客戶RFM指標進行分類,第1類屬于一般價值客戶,第2類屬于一般發展客戶,第3類屬于重要保持客戶。

表6 聚類結果
3 結論
隨著物流行業的市場不斷擴大與發展,物流企業的發展前景也愈加廣闊,機遇與挑戰并存。在物流行業激烈競爭的背景下,客戶對物流服務商的服務質量要求也與日俱增,同時物流企業的發展離不開精細化的操作運營和管理。因此,根據客戶對企業的價值進行細分,挖掘企業的核心消費者,從而制定符合企業戰略的營銷與管理方法,最終提升客戶對企業服務的滿意度,保證企業的利潤率最大化,提高在物流行業的競爭力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
物流技術與應用(2019年8期)2019-09-04 03:29:56
汽車觀察(2018年12期)2018-12-26 01:05:44
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
光學精密工程(2016年6期)2016-11-07 09:07:19
現代企業(2015年2期)2015-02-28 18:45:09
商界(2014年12期)2014-04-29 00:44:03
