大數據流式計算框架Heron環境下的流分類任務調度策略
2019-08-01 01:54:12張譯天于炯魯亮李梓楊
計算機應用 2019年4期
關鍵詞:大數據
張譯天 于炯 魯亮 李梓楊

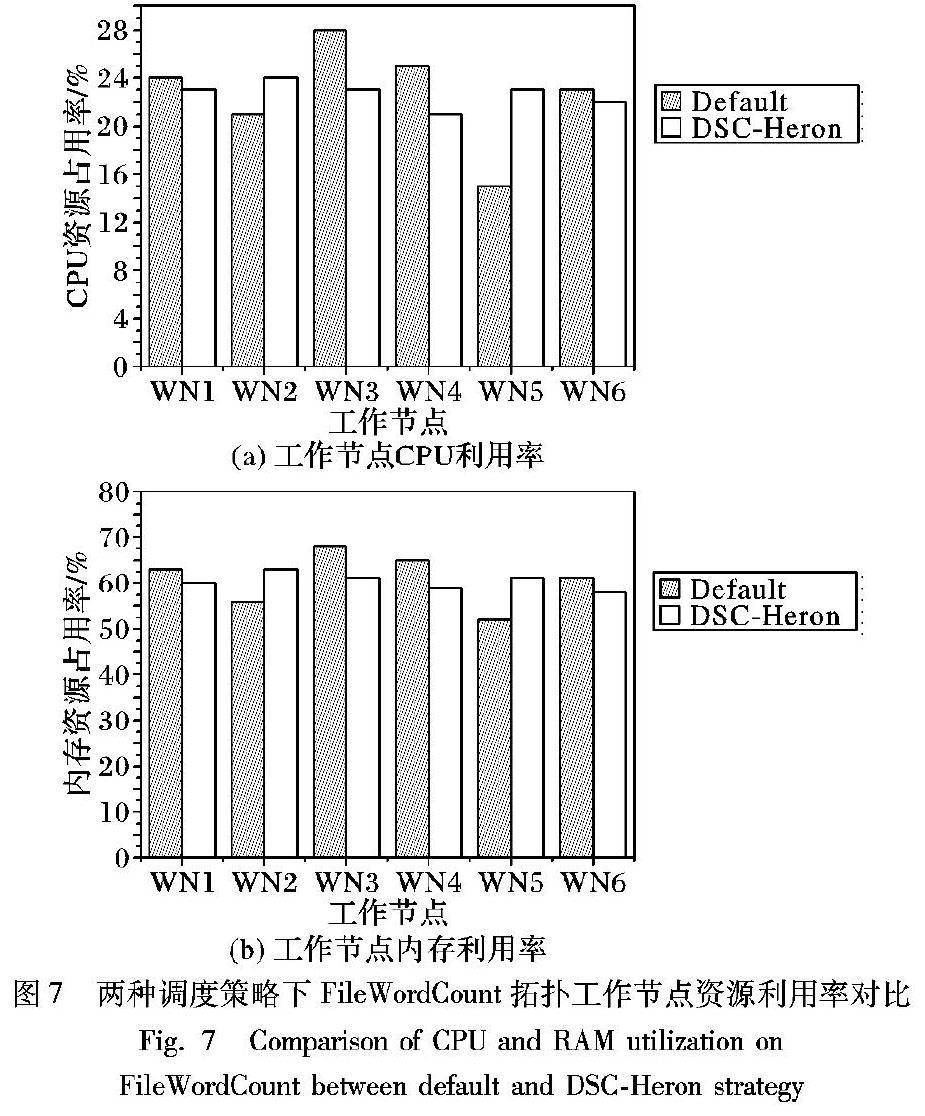
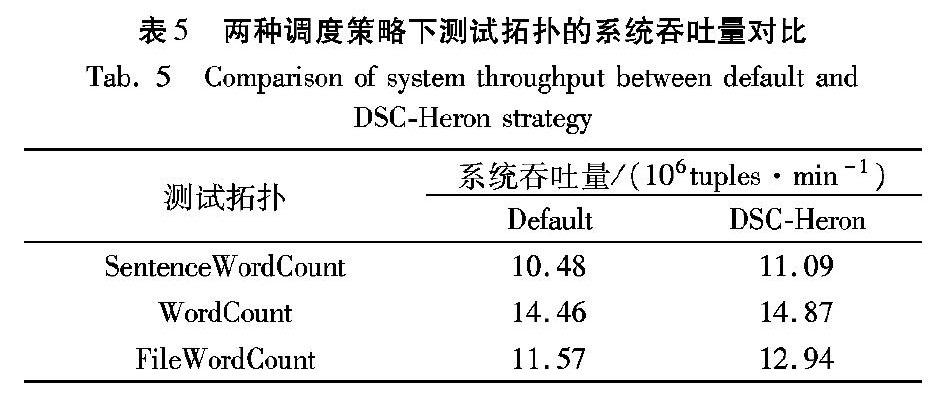
摘 要:新型大數據流式計算框架Apache Heron默認使用輪詢調度算法進行任務調度,忽略了拓撲運行時狀態以及任務實例間不同通信方式對系統性能的影響。針對這個問題,提出Heron環境下流分類任務調度策略(DSC-Heron),包括流分類算法、流簇分配算法和流分類調度算法。首先通過建立Heron作業模型明確任務實例間不同通信方式的通信開銷差異;其次基于流分類模型,根據任務實例間實時數據流大小對數據流進行分類;最后將相互關聯的高頻數據流整體作為基本調度單元構建任務分配計劃,在滿足資源約束條件的同時盡可能多地將節點間通信轉化為節點內通信以最小化系統通信開銷。在包含9個節點的Heron集群環境下分別運行SentenceWordCount、WordCount和FileWordCount拓撲,結果表明DSC-Heron相對于Heron默認調度策略,在系統完成時延、節點間通信開銷和系統吞吐量上分別平均優化了8.35%、7.07%和6.83%;在負載均衡性方面,工作節點的CPU占用率和內存占用率標準差分別平均下降了41.44%和41.23%。實驗結果表明,DSC-Heron對測試拓撲的運行性能有一定的優化作用,其中對接近真實應用場景的FileWordCount拓撲優化效果最為顯著。
關鍵詞:大數據;流式計算;Apache Heron;任務調度;數據流分類;通信開銷
中圖分類號:TP311
文獻標志碼:A
文章編號:1001-9081(2019)04-1106-011
0?引言
隨著云計算、物聯網、移動互聯、社交媒體和人工智能等新型信息技術和應用模式的不斷發展,數據正以前所未有的方式推動人類社會進入大數據時代[1]。國際數據公司(International Data Corporation, IDC)發布的白皮書《數據時代2025》中顯示,預計到2025年全球互聯網數據總量達162ZB,其中超過1/4的數據為實時數據,而物聯網實時數據將占這部分數據的95%以上[2]。面對實時大數據具有的實時性、易失性、突發性、無序性和無限性的新特征[3],傳統的MapReduce等批處理方式不再適用,分布式大數據流式計算應運而生。流數據處理摒棄了傳統批處理中對數據先存儲后計算的方式,將數據以數據流的形式在數據產生初期進行計算,使用可靠傳輸模式而不對計算中間結果進行存儲,在對數據分析實時性要求較高的場景中得到了廣泛的應用,并不斷融入實時圖像識別、智慧城市等人工智能的發展中。
目前,在典型的流數據處理系統(例如,Storm[4]、Flink[5])中,默認調度算法常采用靜態輪詢調度算法。該算法實現簡單,在拓撲提交時對拓撲進行任務分配,拓撲運行期間任務分配狀態不再發生改變;但靜態輪詢調度算法在進行任務分配時,僅考慮資源的可滿足性將任務均勻分配到各個工作節點,未考慮拓撲中任務間的關聯關系和節點間的通信開銷,會對集群性能產生一定影響。針對這一問題,國內外研究人員針對不同流式計算平臺提出在線調度算法,在拓撲運行過程中通過實時監測集群運行狀態,對已分配的任務進行重調度或調整,以使集群具有更高效的性能。針對Storm環境,文獻[6]提出自適應調度策略,分為離線調度和在線調度。其中在線調度通過實時監測拓撲運行過程中CPU負載和工作節點間數據流流量等數據,依次將通信開銷較大的一對任務調度到CPU負載較小的工作節點中。該策略可以較好地降低Storm的通信開銷,但實驗中使用的是自定義鏈式拓撲,缺乏一定的代表性。文獻[7]提出流量感知在線調度策略T-Storm,旨在最小化進程間和工作節點間通信開銷,同時實現了細粒度的任務分配控制,可以通過調整預設參數控制工作節點數量。但該策略忽略了直接通信的一對任務之間的數據流情況且調度執行開銷較大。文獻[8]提出資源感知調度策略R-Storm,通過將CPU、內存和網絡帶寬資源映射為三維空間向量,使用最小化向量距離的方法尋找任務和工作節點的分配關系,從而最大化資源利用并提高系統吞吐量。該策略充分考慮了集群資源的有效利用,但拓撲中各任務的資源需求由編程人員設定而非實時監測獲得,很難應用于資源需求變化較大的在線調度。文獻[9]提出一種異構環境下的任務遷移策略TMSH-Storm,將超出閾值節點中的阻尼線程細粒度地遷移至滿足條件的目標節點,避免了資源溢出后的任務重部署,可以較好地降低調度時延和節點間通信開銷。針對Flink環境,文獻[10]提出流網絡的流式計算動態任務調度策略。該策略通過建立流網絡模型,基于最大流算法使模型在滿足延遲約束前提下提高集群的實際吞吐量,能在一定程度上解決輸入速率增加階段出現的計算延遲升高問題。
但該策略僅關注集群輸入速率急劇上升階段的性能優化,且沒有考慮流網絡容量動態變化的問題。針對其他流式計算系統,文獻[11]從資源分配的角度出發,對多代分布式流處理系統的彈性資源調度機制進行對比并提出未來研究方向。文獻[12]基于拓撲任務與集群資源的分配與映射關系提出模型驅動的調度策略,為流處理系統提供高效的資源利用率和吞吐量。文獻[13-14]側重于流處理系統的穩定性,分別提出一種基于隊列的穩定性預測模型和一種穩定的在線調度策略以優化系統性能。
Heron[15-17]是Twitter為解決其上一代分布式流處理平臺Storm在可擴展性、可調試性、可管理性以及集群資源共享等方面問題,而構建的新一代分布式流處理平臺[15]。Heron在2015年已經取代Storm,成為Twitter實際使用的實時數據處理系統[17],現已進入Apache開源項目孵化器。Heron在設計層面對Storm進行多方面優化的同時,其默認調度策略仍使用輪詢(Round Robin,RR)算法進行任務實例分配。該算法根據拓撲中任務實例資源需求和容器資源需求,創建用于調度的任務分配計劃,然后交由Heron調度器(Aurora[18]、Mesos[19]、YARN[20]等)分配至工作節點。對于Twitter目前使用的Aurora調度器,Heron將一個拓撲對應于Aurora中一個工作(Job),一個容器與其中分配的任務實例作為Aurora的一個資源分配單元,由Aurora負責將這些單元分配至集群中滿足資源需求的工作節點中運行。在配置了Aurora調度器的Heron集群中,工作節點資源分配由Mesos負責進行,其采用DRF(Dominant Resource Fairness)資源分配策略為Aurora框架中提交的任務尋找集群中注冊的合適工作節點進行任務分配。
在Heron調度策略和任務分配過程中仍存在如下問題:1)任務分配沒有考慮任務實例間通信開銷,忽略了節點間通信和節點內通信的差異;2)任務分配僅考慮了任務實例和工作節點資源的約束關系,且算法采用資源最大化對齊的方式容易造成資源浪費;3)僅提供了靜態調度策略,無法針對運行狀態下的拓撲進行實時調度。
針對Heron默認調度策略中存在的上述問題,本文提出流分類調度策略(task scheduling strategy based on Data Stream Classification in Heron, DSC-Heron),主要工作如下:1)提出Heron作業模型,將拓撲中任務實例通信方式劃分為節點間、容器間和實例間通信,明確不同通信方式間的通信開銷差異。
2)以Heron作業模型為基礎,提出資源約束模型、最優通信開銷模型和流分類模型,作為提出DSC-Heron任務調度策略的理論依據。
3)提出流分類調度策略,包括流分類算法、流簇分配算法和流分類調度算法。該策略首先根據數據流實時大小對數據流進行分類,然后以高頻數據流關聯的高頻流簇為單位進行任務調度,使得拓撲的任務分配在滿足資源約束條件的同時最小化節點間通信開銷。
4)使用Heron示例拓撲和自定義拓撲對流分類調度策略進行性能評估。實驗結果表明,相較于Heron默認調度策略,DSC-Heron在系統完成時延、節點間數據流大小和吞吐量方面均有一定的優化效果。
1?Heron作業模型
在Heron中,拓撲是用戶定義流式作業的抽象,使用有向無環圖(Directed Acyclic Graph, DAG)表示,由組件和數據流構成。組件分為Spout和Bolt兩類:Spout為數據源編程單元,可以從Kafka[21]、DistributedLog[22]或HDFS(Hadoop Distributed File System)中不間斷地讀取數據,以數據流的形式傳遞給下游組件;Bolt為數據流處理單元,用于實現數據處理邏輯。數據流是對組件間以元組形式進行數據傳遞的抽象,可以通過不同的流組模式定義元組的傳遞和分組方式。由此定義拓撲邏輯模型如下。
Heron中為提高系統并行度和數據處理速度可以為拓撲中每個組件定義運行并行度,并在拓撲提交時為每個組件創建相應數量的任務實例。每個任務實例運行一個Java進程且運行在一個JVM中。由此定義拓撲實例模型如下。
根據實例分配模型可知,Heron任務實例之間的通信需要經過所在容器中的SM進行路由。集群中各個SM彼此連接形成一個全連接網絡,將復雜度為O(N(N-1)/2)的N個任務實例間通信,通過M個SM簡化為O(M(M-1)/2),其中NM。因此,在Heron集群中存在三種不同的通信方式:1)工作節點間通信,即集群不同物理工作節點間任務實例的通信方式。這種通信方式中,數據流需要經過源任務實例、源任務所屬SM、目的任務所屬SM和目的任務實例進行傳輸,會占用大量的網絡帶寬資源,是集群中通信開銷最大的一種通信方式。如圖3中,任務實例Ia和Id1間的通信即屬于工作節點間通信。
2)容器間通信,即同一工作節點、不同容器中任務實例之間的通信方式。這種通信方式不占用網絡帶寬,數據流在同一節點的不同任務間進行傳遞,但仍需要經過源任務實例、目的任務實例以及各自所屬的SM,屬于進程間通信且通信開銷較小。如圖3中,任務實例Id2和Ic間的通信即為容器間通信方式。
3)實例間通信,即同一工作節點且同一容器中任務實例間的直接通信。這種通信方式在一個容器中進行,數據流只經過一個SM進行傳輸,是三種通信方式中通信開銷最小的一種。由于在Heron中每個任務實例都是一個Java進程,因此這種通信方式也屬于進程間通信,但由于減少了數據流經過的SM數量,因此通信開銷較容器間通信開銷小。如圖3中,任務實例Ib和Ig間即屬于實例間通信方式。
2?問題建模與分析
本章在Heron作業模型的基礎之上提出資源約束模型、最優通信開銷模型和流分類模型。其中資源約束模型為任務分配的基礎條件;最優通信開銷模型論證了節點間和節點內通信開銷的相互關系,為最小化通信開銷的任務調度過程提供依據;流分類模型定義了拓撲中數據流分類的理論基礎。
2.1?資源約束模型
在Heron應用環境中,為使各個工作節點不會出現滿負荷運行狀態以影響集群運行性能,需要為每個工作節點預留少量的計算資源。因此,在上述資源約束中,α、 β、γ分別為集群管理人員為CPU、內存和網絡帶寬資源設定的資源閾值參數,該參數可根據集群資源情況進行設置。
2.2?最優通信開銷模型
2.3?流分類模型
3?流分類調度策略
本章基于上述模型提出流分類調度策略(DSC-Heron),包括流分類算法、流簇分配算法和流分類調度算法。其中流分類算法以流分類模型為基礎,以數據流實時大小為依據對數據流進行分類;流簇分配算法以高頻流簇為基本單元進行任務分配;流分類調度算法對不同類別的數據流依次進行調度,最終完成目標任務分配計劃的構建。
3.1?流分類算法
通過使用3.4節提出的負載監測模塊對集群中任務實例以及實例間數據流大小進行監測,實時獲取拓撲中任務實例間數據流大小,得到拓撲的數據流集合S={s1,2,s1,3,…,sI-1,I}作為輸入;然后根據流分類模型將集合S劃分為高頻數據流集Hf、中頻數據流集Mf和低頻數據流集Nf。具體算法如算法1所示。
算法1?流分類算法。
輸出?高頻數據流集Hf;中頻數據流集Mf;低頻數據流集Nf。
步驟1?根據S中各個數據流大小vij,kl,使用式(8)計算數據流總量V;使用式(9)計算數據流平均值;使用式(10)計算sij,kl的絕對偏差值;使用式(11)計算數據流總絕對偏差ΔV;使用式(12)平均偏差Δ。
步驟2?根據vij,kl大小降序排序S并進行遍歷,進行如下判斷:若數據流sij,kl滿足式(13),將其加入高頻數據流集Hf;若滿足式(14)或式(15),將其加入中頻數據流集合Mf;若滿足式(16),將其加入低頻數據流集合Nf。
步驟3?返回Hf、Mf和Nf。
流分類算法步驟1中包括兩次對數據流集合S的遍歷。第一次遍歷數據流集合S,計算出拓撲數據流總量V,進而可以計算數據流平均值。第二次遍歷數據流集合S,由數據流平均值計算各個數據流的絕對偏差值,同時累加計算所有數據流的總絕對偏差值ΔV和平均偏差值Δ。算法步驟2~3根據流分類模型中的式(13)~(16),使用步驟1計算所得值,對數據流集合遍歷的同時進行數據流的分類并返回分類所得不同數據流集合。由此可知,該算法的時間復雜度為數據流集合S的大小,即O(S)。
3.2?流簇分配算法
由定義4可知,DSC-Heron將高頻數據流關聯的高頻流簇作為調度的基本單元,盡可能得將同一高頻流簇相關的任務實例調度到同一工作節點。在調度的過程中,需要根據當前高頻數據流關聯的任務實例在高頻流集合Hf中遞歸搜索與之關聯的流簇,然后對該流簇中的任務實例進行分配,由此得到流簇分配算法。具體算法如算法2所示。
算法2?流簇分配算法。
輸入?數據流sij,kl關聯的任務實例Iij和Ikl;高頻數據流集合Hf;目標節點nk;原始任務分配計劃PPold;當前目標任務分配計劃PPnew。
輸出?更新后的目標任務分配計劃PPnew。
步驟1?根據Iij和Ikl在Hf中搜索關聯的高頻數據流sgh,ij和skl,mn,若不存在相關聯高頻數據流或存在任務實例Igh、Imn且均已分配則遞歸結束。若存在且未分配,根據PPold判斷Igh和Imn是否分別位于目標節點nk中:如果是,判斷將該任務實例仍分配至nk中是否滿足資源約束條件:若滿足則進行分配,更新PPnew并進行步驟2;若不滿足則查找當前PPnew中負載最小的工作節點進行調度。
如果否,判斷將未分配任務實例調度到nk節點之后是否滿足資源約束條件:若滿足進行調度,更新PPnew并進行步驟2;若不滿足則查找當前PPnew中負載最小的節點進行調度。
步驟2?在Hf中遞歸查找Igh和Imn關聯的高頻數據流sef,gh和smn,op,若存在任務實例Ief,Iop未分配,重復步驟1直至遞歸結束。
流簇分配算法是一個遞歸的集合搜索過程,它將一個高頻數據流關聯的源任務實例、目的任務實例和高頻數據流集合作為輸入,分別對源任務實例和目的任務實例在高頻數據流集合中搜索相關聯的高頻數據流,并依次對搜索結果中包含的未分配任務實例進行調度,以更新目標任務分配計劃。同時,該搜索過程也是構建該數據流高頻流簇SC的過程。若一條高頻數據流在高頻數據流集合中不存在關聯的高頻流或存在且均已經分配完成則遞歸結束,返回對該條數據流構建完成的目標任務分配計劃。流簇分配算法將每個高頻數據流的關聯的流簇集合整體作為任務調度對象,旨在最大化節點內任務間數據流,根據最優通信開銷模型即等價于最小化節點間數據流,以減少拓撲整體通信開銷。根據該遞歸算法可知,其時間復雜度為:O(Hf·SC)。其中,由于SC的最大值等于拓撲關鍵路徑長度,因此該算法的運行時間與拓撲的層數以及高頻數據流集合規模有關。
3.3?流分類任務調度算法
流分類調度算法整合了流分類算法和流簇分配算法,將流分類算法中得到的高頻流集合作為輸入,通過遍歷數據流集合S,首先對其中高頻數據流進行分配并對該數據流調用流簇分配算法進行任務調度,直至所有的高頻數據流分配完成,然后對未分配的中頻數據流和低頻數據流分別調度,完成構建目標任務分配計劃。具體算法如算法3所示。
算法3?流分類調度算法。
輸出?目標任務分配計劃PPnew。
初始化?由負載監測模塊獲取當前各數據流大小vij,kl和各任務實例CPU負載wIij以初始化數據流集合S與任務實例負載集合W;使用流分類算法得到各數據流分類集合Hf、Mf、Nf;初始化PPnew為空。
步驟1?根據數據流vij,kl的大小對集合S進行降序排序,遍歷集合S中各數據流sij,kl。
步驟2?如果sij,kl屬于高頻數據流集合Hf,進行如下步驟:①判斷數據流sij,kl關聯的兩個任務實例Iij和Ikl是否在PPnew中已經重新分配,若都已經重新分配則對該數據流的調度結束。
②若僅其中一個任務已分配,這里以Iij已分配至工作節點nk且Ikl未分配為例,進行如下步驟:(a)根據PPold判斷Iij和Ikl是否位于同一節點。若在同一節點nk,更新PPnew并調用流簇分配算法,分配sij,kl關聯的其他高頻數據流,調度結束。
(b)若Iij和Ikl位于不同節點,根據資源約束模型判斷Ikl調度到工作nk后是否滿足資源約束,若滿足則將Ikl調度到工作節點nk,更新PPnew并調用流簇分配算法,分配sij,kl關聯的高頻數據流,調度結束。若不滿足,則根據W查找當前PPnew中負載最小節點分配任務Ikl。
③若任務實例Iij和Ikl均未分配,進行如下步驟:(a)根據PPold判斷Iij和Ikl是否位于同一節點,若在同一節點nk,更新PPnew并調用流簇分配算法,分配sij,kl關聯的高頻數據流,調度結束。
(b)若Iij和Ikl位于不同節點ni和nk中,計算當前分配計劃PPnew中ni和nk已分配任務的負載,將Iij和Ikl分配到負載較小的節點中,并根據資源約束模型判斷調度過程中是否滿足資源約束,若滿足則逐個調度任務,更新PPnew并調用流簇分配算法,分配sij,kl關聯的高頻數據流,調度結束。若在調度任務實例Ikl時已不滿足資源約束條件,則將其調度至當前負載最小的節點。
步驟3?如果sij,kl屬于中頻數據流集合Mf,則重復步驟2中的①~③,但不再調用流簇分配算法,此時高頻數據流已經調度完成。
步驟4?結束數據流集合S的遍歷,對剩下低頻數據流集合Nf中sij,kl計算當前PPnew中各個節點的任務負載情況,優先將任務Iij、Ikl調度到負載較輕的節點中并保證滿足資源約束條件,直到全部任務調度完成。
算法步驟1中根據集合中數據流的大小對數據流集合S進行降序排序,這樣可以保證在對集合S進行遍歷時,對高頻數據流進行優先處理。
步驟2對集合S進行遍歷,對屬于高頻數據流集合的當前數據流進行調度。該步驟中包含的①~③分別是對當前高頻數據流關聯的兩個任務實例是否在目標任務分配計劃中分配完成進行判斷,目的是為了避免對可能出現在不同高頻數據流中的同一任務實例進行重復調度。步驟①中,如果當前的兩個任務實例均已經在目標任務分配計劃中分配完成,則不再進行重復調度。步驟②中,當前兩個任務實例中僅有一個任務實例已經分配,則優先將未分配的任務實例調度到已分配任務實例當前所在的工作節點中,此舉是為了最大化節點內任務實例間的直接通信以最小化節點間的通信開銷。但在這種調度的過程中,需要判斷調度發生后目標節點是否滿足資源約束條件:若滿足則可以進行調度,完成最大化節點內通信開銷;若不滿足,則需要使用當前目標任務分配計劃PPnew和任務負載集合W尋找當前集群中負載最小的工作節點分配該任務,目的是為了在未能滿足最小化通信開銷的情況下,盡量平衡集群各工作節點負載從而在負載均衡的角度優化集群性能。步驟③中為當前兩個任務實例均未重新分配,需要依次對兩個未分配任務實例進行調度。首先根據原始任務分配計劃PPold判斷兩個任務實例是否位于同一節點,并優先將兩個任務調度到其中當前負載較輕的工作節點中,以最小化通信開銷的同時均衡集群負載。但在對兩個任務進行依次調度時,均需要對目標工作節點計算調度完成后的資源約束情況,若不滿足資源約束,則同步驟②中的方法相同,將該任務實例分配至當前集群中負載最小的工作節點。
通過步驟1~2,算法將數據流集合S中包含的高頻數據流及其關聯高頻流簇調度完成,因此步驟3對中頻數據流集合中的數據流進行調度時,不需要考慮高頻流簇的分配,僅對中頻數據流本身繼續調度。
算法步驟4進行之前,前序算法步驟已經對數據流集合S中高頻數據流和中頻數據流調度結束,此時只剩下低頻數據流,而低頻數據流在拓撲中對整體通信開銷的影響最小,因此僅對其進行負載均衡處理,依次將低頻數據流調度至集群當前負載較小的工作節點中,最終完成全部數據流的調度。根據該算法步驟可知,該算法在對數據流集合S遍歷的同時分別將屬于各個類別的數據流調度至符合條件的工作節點中,因此算法時間復雜度為O(S·N)(其中N為工作節點數量)。
3.4?算法部署與實現
Heron為編程人員提供了可擴展的Custom Scheduler[23]實現。為實現自定義調度器,需要實現與Heron調度器相關的IPacking、ILauncher、IScheduler和IUploader四個Java接口。在本文實驗中,DSC-Heron基于Heron中默認AuroraScheduler進行部署和實現,Uploader仍使用HDFS不作修改,但分別實現了以下三個接口:1)DSCPacking。實現IPacking接口,用于部署DSC-Heron以構建目標任務分配計劃,為調度控制模塊對拓撲任務的重調度提供依據。
2)DSCLauncher。實現ILauncher接口,替換原有的AuroraLauncher。用于在拓撲提交后創建DSCScheduler對象實例并調用其onSchedule方法啟動自定義調度器。
3)DSCScheduler。實現IScheduler接口,替換默認AuroraScheduler,拓撲提交后將由該調度器完成拓撲的初次調度。其中部署調度觸發模塊和調度控制模塊,用于重調度的觸發以及使用DSCPacking創建的目標任務分配計劃更新拓撲,完成重調度過程。
在拓撲重調度的過程中,需要實時獲取各工作節點以及工作節點內各任務實例的CPU負載。對于各任務進程的CPU資源占用信息,可以通過Java API中ThreadMXBean類的getThreadCpuTime(long id)方法獲取,其中id為各Java進程中運行任務實例的線程ID。對于各工作節點的CPU負載,可以通過對運行在該工作節點中的任務實例CPU負載進行累加求得。此外,工作節點中相關硬件參數可通過/proc目錄下的相關文件獲得。在代碼編寫完成后,使用Maven創建自定義調度器的jar文件,將其放置到${HERON_HOME}/lib/scheduler目錄下,并在${HERON_HOME}/conf/aurora目錄下的scheduler.yaml文件中進行配置DSCScheduler和DSCLauncher類名后即可使用。
改進后的Heron系統結構如圖4所示。其中,在Heron系統結構中新增的四個自定義模塊分別是:
1)負載監測模塊。部署在各個工作節點中,負責在一定時間窗口內監測工作節點中運行的任務實例CPU負載、任務間數據流大小和內存資源占用等信息,并將監測信息實時寫入數據存儲模塊。使用該模塊,需要在拓撲中各Spout的open()和nextTuple()方法以及各Bolt的prepare()和execute()方法中調用該模塊。
2)調度觸發模塊。部署在DSCScheduler中并在該調度器對象實例化時啟動。負責在滿足重調度觸發條件時調用調度控制模塊中重調度方法完成DSC-Heron的重調度過程。
3)數據存儲模塊。存儲并實時更新負載監測模塊獲取的任務實例監測信息,這里使用MySQL數據庫實現。
4)調度控制模塊。完成流分類調度策略的核心模塊,通過調度觸發模塊調用。根據原始任務分配計劃獲取由DSC-Heron構建的目標任務分配計劃,更新拓撲任務分配以完成任務調度過程。該模塊采用與DSCScheduler松耦合的設計范式,便于未來部署其他在線重調度算法。
4?實驗
4.1?實驗環境
實驗環境采用硬件配置相同的PC搭建一個9節點的Heron集群。其中一個主控節點運行Heron、Heron Tracker、Heron UI、Mesos Master和Aurora Scheduler;一個協調節點運行ZooKeeper和MySQL等服務;一個節點運行Heron自動創建的拓撲管理進程(Topology Master)用于管理拓撲整個生命周期;其余節點為工作節點分別運行Mesos Agent、Aurora Observer和Aurora Executor,負責實際運行拓撲的任務實例。此外,集群中各節點共同運行HDFS作為Heron的Uploader系統組件并負責共享Heron Binaries文件。實驗集群的軟硬件配置如表1所示。
實驗采用Heron Github開源項目[24]提供的Sentence WordCount和WordCount示例拓撲以及自定義FileWordCount拓撲,三種拓撲中采用不同的結構和數據源以評估DSC-Heron在不同場景中的表現。其中SentenceWordCount拓撲包含三層結構:
第一層Spout組件隨機創建一個長度為128×1024的句子數組并隨機發射;
第二層Bolt組件(名為Split)通過空格字符分割句子產生單詞;
第三層Bolt組件(名為Count)接受Split中發送的單詞并進行計數。
WordCount為兩層結構,Spout組件(名為word)隨機生成單詞并發射,由Bolt(名為consumer)組件進行統計。FileWordCount拓撲結構與SentenceWordCount相同,但數據源來自原版英文歷史小說《雙城記》,格式為txt。SentenceWordCount拓撲相對于WordCount的兩層結構,包含的數據流數量和流簇規模較大,兩者對比有利于評估系統性能的優化效果。
FileWordCount拓撲數據源采用真實文本文檔,其中各單詞出現的頻率不盡相同,在實際的應用場景中有一定代表性。
實驗拓撲中設置了各組件的并行度和資源需求,數據流在各組件間的傳遞模式,可用的容器數量以及資源需求,詳細的測試拓撲運行參數配置如表2所示。
表2中:topology.max.spout.pending(簡稱為pending)的值為Spout緩存隊列的最大容量,當隊列長度達到設置的容量時Spout停止發送數據,當隊列長度小于設定值時Spout持續發送數據,從而實現對拓撲數據傳輸速率的控制。topology.message.timeout.secs(簡稱為timeout)的值配合ATLEAST_ONCE可靠性語義模式和Acknowledgement[25]機制使用。實驗拓撲在Bolt組件中設置ack機制,唯一標識標記的元組從Spout中發射,在timeout設定的時間內經過各個組件處理完成后由Spout中ack方法進行確認,若沒有在該參數規定的時間內接受到指定元組,Heron則會重新發送以保證ATLESAT_ONCE的有效進行。
對于參數pending和timeout的取值,在默認調度策略下使用SentenceWordCount拓撲經過多次實驗得到表3所示參數取值對拓撲元組失敗率的影響,在表2所示參數下其他測試拓撲實驗結果與此類似。其中, pending的值設置為100且timeout值設置為60s時,雖然拓撲運行前5min的失敗率較低,但由于pending的值較小無法正常發揮集群運行性能且無法體現真實應用場景;當pending的值設置為1000且timeout的值設置為60s時,拓撲提交后前5min內的元組失敗率為6.6%,相對于相同pending值但timeout值為30s時拓撲運行的20%失敗率,元組失敗率明顯降低并且有少量拓撲出現重新發送的情況,該場景較符合真實應用場景且集群能夠快速地趨于穩定。而當pending的值設置為10000且timeout的值為60s時,元組失敗率較高,此時雖然提高timeout參數值可以降低元組失敗率,但會導致CPU負載過高從而使集群運行情況不可預測。因此, pending的值設置為1000,timeout的值設置為60s,在當前集群的配置下能夠較好地滿足實驗的需要。
此外,由于集群中主控節點獨立運行,拓撲管理器單獨運行于一個工作節點的容器中,ZooKeeper和MySQL等服務進程占用一個節點資源,因此集群中可分配任務實例的工作節點數量為6。在表2中將topology.stmgrs的數量設置為6,即容器數量與集群中工作節點的數量相同,意味著每個工作節點中僅運行一個容器,從而消除容器間通信帶來的開銷,重點關注節點間通信和節點內實例間通信的轉換對集群性能的影響。
為驗證DSC-Heron的有效性,本文與Heron默認的輪詢調度策略進行了對比,表4中列出了DSC-Heron的參數設置,其中主控節點根據reschedule.timeout參數觸發重調度。工作節點中α、 β和γ為資源約束模型中設置的資源閾值參數,為避免節點滿負荷運行影響集群性能,α值設置為0.7,由于Heron容器中已為系統級進程留有內存資源,因此β和γ的值設置為1。time.window.length和time.window.count為負載監測模塊中設置的數據統計窗口大小和數量,即使用長度為5s的時間窗口對數據采樣3次統計平均值。此外Heron集群的其他配置參數與默認輪詢調度算法的參數均取默認值。
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
