基于鄰域最小生成樹的半監督極化SAR圖像分類方法
2019-08-07 00:42:22滑文強郭巖河
雷達學報 2019年4期
滑文強 王 爽 郭巖河 謝 雯
①(西安郵電大學計算機學院 西安 710121)
②(西安郵電大學陜西省網絡數據分析與智能處理重點實驗室 西安 710121)
③(智能感知與圖像理解教育部重點實驗室 國際智能感知與計算聯合研究中心西安電子科技大學 西安 710071)
1 引言
極化SAR圖像分類作為極化SAR圖像理解與解譯的重要研究內容,近年來受到越來越多研究者的關注,并廣泛應用到各個領域,如土地覆蓋類型判別、地面目標檢測、地質勘探、植被種類判別等[1-3]。根據分類方法中標記樣本和無標記樣本的利用方式,極化SAR地物分類方法主要可以分為3種類型:無監督分類方法[4,5]、監督分類方法[6,7]和半監督分類方法[8,9]。
對于極化SAR圖像分類問題,監督分類方法通常比無監督分類更容易獲得好的分類結果,但是監督分類方法通常需要充足的標記樣本作為訓練樣本,而實際中標記樣本的獲取是非常困難,需要耗費大量的人力物力。而無標記數據獲取相對容易,并且無標記的數據也能反映數據的某些信息,能夠有效地幫助學習分類器。因此,如何利用大量的無標記樣本對少量的標記樣本進行補充輔助訓練的半監督學習方法,引起了研究者的廣泛關注,成為了當前研究的熱點。近年來,很多半監督分類方法被提出來,如自訓練(Self-training)方法[10]、協同訓練方法(Co-training和Tri-training)[11,12]、標簽傳播聚類算法、基于圖的半監督分類算法[13,14]和基于半監督的神經網絡算法[15-17]等。然而針對極化SAR圖像分類問題的半監督方法研究較少,Hansch[18]提出了一種基于聚類算法的半監督極化SAR分類方法,將半監督思想同聚類方法相結合,通過被選擇未標記樣本對聚類中心進行約束,利用未標記樣本的約束影響聚類中心,獲得更好的分類結果。為利用極化SAR數據中的空間信息,Liu等人[19]提出了基于鄰域約束半監督特征提取的極化SAR圖像分類方法。為使半監督訓練中選擇的未標記樣本具有更高的可靠性和多樣性,Wang等人[20]提出了基于改進協同訓練的半監督極化SAR圖像分類方法,通過協同訓練的方式選擇多樣性的樣本,通過預選擇的方法增加被選擇樣本的可靠性。此外,結合深度學習方法和半監督學習思想,Geng等人[21]提出了基于超像素約束的深度神經網絡半監督極化SAR分類方法。但是這些半監督分類方法都需要一定的標記樣本,在標記樣本非常少,只有幾個標記像素的條件下,很難獲得較好的分類結果。因此,本文針對此問題,提出一種基于鄰域最小生成樹的半監督極化SAR圖像分類方法。該方法利用鄰域最小生成樹方法輔助半監督學習,在自訓練的過程中通過鄰域最小生成樹輔助的方式選擇更可靠的無標記樣本擴大訓練樣本集,改善分類器的性能。
自訓練學習方法是一種典型的半監督學習方法,該方法利用現有的標記數據訓練得到的模型對無標記的樣本進行預測,選擇可靠性高的樣本以及其被賦予的標簽加入到標記樣本集中,通過不斷循環的自訓練,逐漸增加訓練集中的樣本數量并逐步改善分類器性能,該方法的框架圖如圖1所示。由圖1可以看出,自訓練方法的關鍵是選擇可靠性的樣本,如果選擇的樣本不正確,使錯誤的樣本加入到訓練集中,不僅不能使分類器性能得到改善反而會降低分類器的性能。因此,如何選擇高置信度的樣本成為自訓練算法的關鍵。而在極化SAR圖像分類中,由于只有少量的標記樣本,在少量標記樣本下訓練的分類器是一個弱分類器,直接在弱分類器的結果中選擇的樣本很難保證其可靠性。如果將錯誤標記的樣本加入到標記樣本集中,反而會使分類器的性能下降。因此,為增加被選擇樣本的可靠性,結合極化SAR圖像像素間的空間信息,本文提出了基于鄰域最小生成樹的樣本選擇方法,通過鄰域最小生成樹輔助選擇的方法增加被選擇樣本的可靠性。
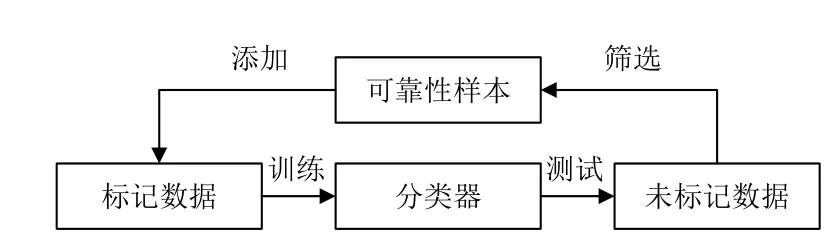
圖1 自訓練方法Fig. 1 Self-training method
因此,本文算法的主要貢獻為:(1)針對極化SAR圖像分類中標記樣本非常少的問題,提出了一種新的基于鄰域最小生成樹的半監督極化SAR圖像分類方法,該方法同時利用未標記樣本和標記樣本的信息有效地提高分類正確率;(2)為增加自訓練過程中被選擇樣本的可靠性,結合極化SAR圖像像素間的空間信息,在最小生成樹的基礎上針對極化SAR圖像分類的特性,提出了基于鄰域最小生成樹樣本選擇方法。
2 極化SAR數據
在極化SAR數據中,每個像素點都可以表示為一個相干矩陣T或協方差矩陣C
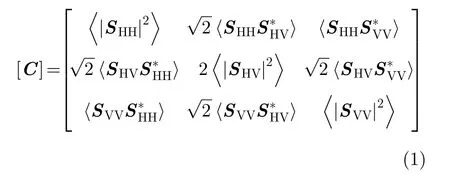
其中,HH表示水平發射水平接收,VV表示垂直發射垂直接收,HV表示水平發射垂直接收。由協方差矩陣C的矩陣表示形式可以看出,協方差矩陣是一個對角線為實數的復共軛對稱矩陣,并且由協方差矩陣轉換的9維特征向量通常可以作為極化SAR數據特征的一種表示,并在極化圖像處理中取得良好的效果[9],該向量表示為
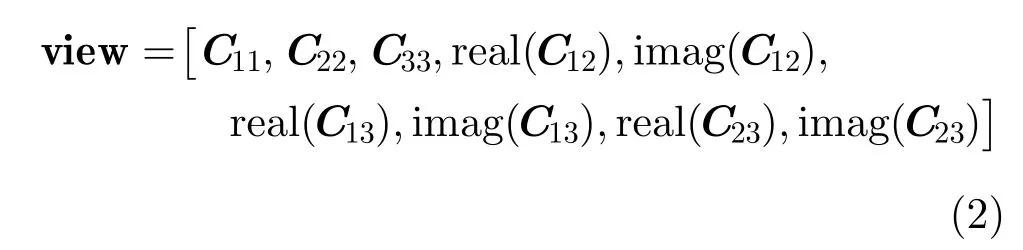
其中,real()表示實部,imag()表示虛部。
圖2(a)為美國舊金山地區的極化SAR數據,圖2(b)-圖2(j)為由該數據的協方差矩陣轉化的9維特征向量中每一元素增強10倍的灰度圖。由9維特征向量每一元素的灰度圖可以看出,每一元素都可以基本描述原始圖像的大致信息,并且不同元素的灰度圖都不相同,具有一定互補性,因此可以直接做為極化SAR圖像的特征信息來描述極化SAR圖像。
3 鄰域最小生成樹
為增強自訓練過程中被選樣本的可靠性,在訓練過程中逐步優化基分類器,結合極化SAR圖像像素間的空間鄰域信息,本文提出了基于鄰域最小生成樹的樣本選擇方法。
3.1 最小生成樹
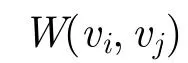
由圖3(a)可以看出任意兩個節點都通過帶權重的邊相連,對于無向圖G來說,可以由不同的節點出發得到不同的生成樹模型。圖3(b)為由權重最小的邊遍歷所有節點得到的最小生成樹,對于無向圖G來說,圖3(b)是其唯一的最小生成樹。

圖2 極化SAR協方差矩陣中9個元素的灰度值Fig. 2 The gray value of 9 elements in PolSAR covariance matrix
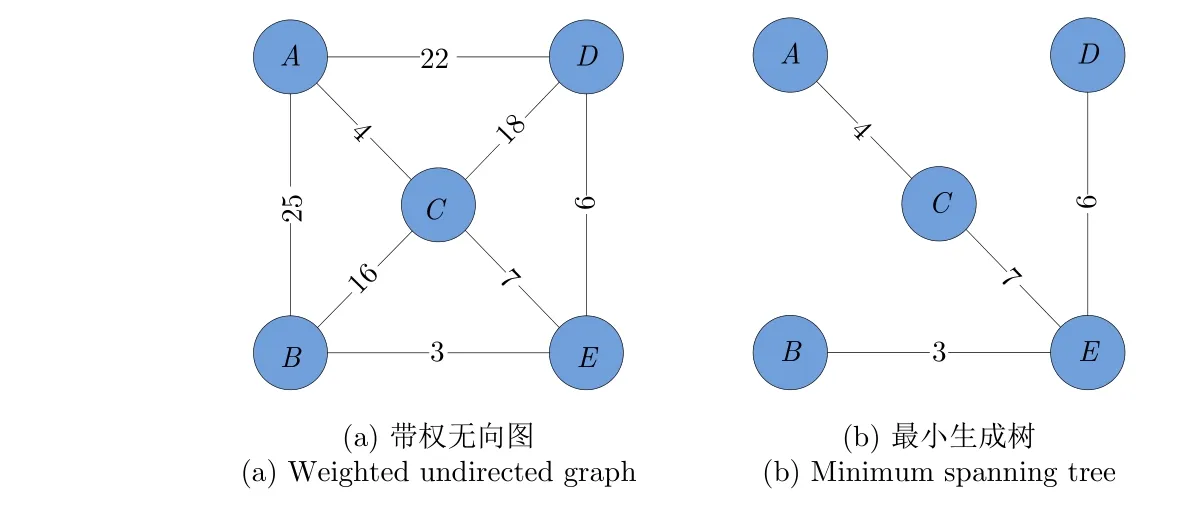
圖3 帶權無向圖G及其最小生成樹Fig. 3 Weighted undirected graph G and its minimum spanning tree
本文采用Prim算法[23]計算最小生成樹,該算法是一種產生最小生成樹的算法。該算法從給定的頂點開始,每次選擇一個與當前頂點最近的一個點,將該點與頂點之間的邊加入到樹中。其形式描述如下:
步驟1 輸入:在一個加權無向圖G中,頂點集合為V,權值邊的集合為E;
3.2 基于空間鄰域信息的最小生成樹

步驟1 構建無向圖G(V,E),其中V為頂點(已標記像素點),用式(3)計算每一頂點于其8鄰域邊的集合E;
步驟2 選擇頂點其8鄰域內與其邊的權值最小的邊,并對與其權值最小的像素點進行標記,然后將其作為標記樣本加入到頂點集合V中;
步驟3 重復步驟1-步驟2過程直到選擇完整幅圖像中所有的像素點。
該方法中需要計算各個頂點之間邊的距離,由于極化SAR數據服從復Wishart分布,因此在極化SAR圖像中,兩個像素點之間的相似距離通常采用Wishart距離[24]表示
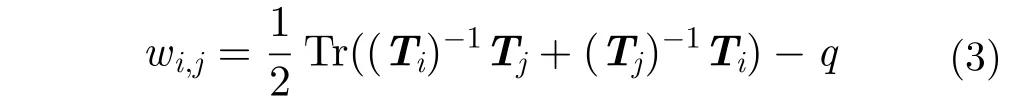
圖4為該算法的生成過程,圖中綠色的矩形表示初始的頂點,灰色的矩形表示其鄰域的頂點,矩形中的數字表示中心像素點與鄰域像素點的距離,距離越小越相似。第1次學習過程,選擇初始頂點鄰域邊最小的頂點,距離為‘1’的點,如圖4(b)所示,然后再在新的頂點集合的鄰域內選擇邊最小的頂點,如圖4(c)所示,添加到以初始頂點為根的樹的集合中,依次循環,直到選擇完所有的頂點為止。
4 本文所提方法
本文針對極化SAR圖像分類中只有少量標記樣本的問題,為在少量標記樣本的條件下獲得較高的分類正確率,在傳統自訓練方法的基礎上提出了基于鄰域最小生成樹的半監督極化SAR圖像分類方法。該方法的核心是在自訓練的過程中由大量的無標記樣本中選擇可靠的樣本,將其添加到標記樣本中,擴大標記樣本的數量,逐漸優化分類器性能,最終實現提高分類正確率的目的。為此,結合最小生成樹方法和極化SAR圖像中像素點的空間信息,提出了基于鄰域最小生成的樣本選擇方法,增加被選擇樣本的可靠性。本文所提方法的整個框架圖如圖5所示,具體步驟如下:

圖4 基于鄰域的最小生成樹生成過程Fig. 4 The spanning process of neighborhood minimum spanning tree
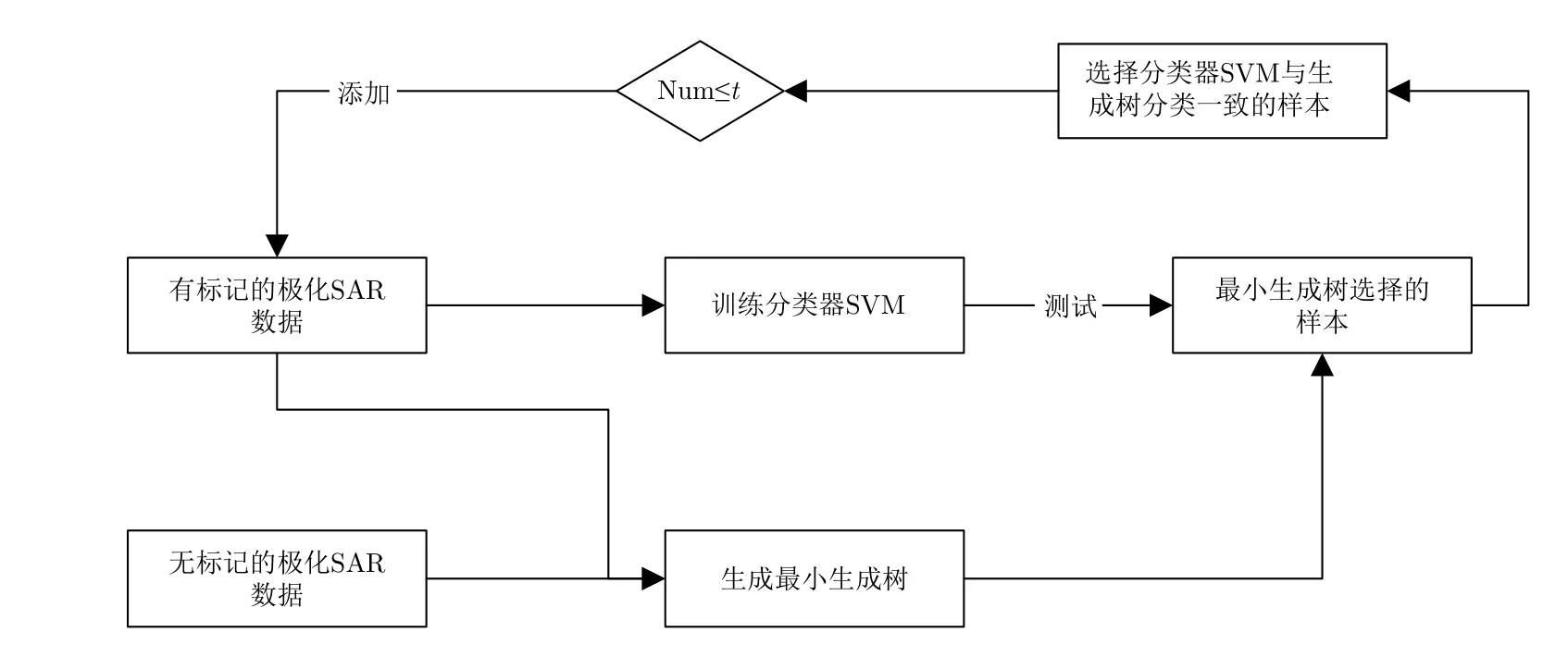
圖5 基于鄰域最小生成樹的半監督極化SAR分類方法Fig. 5 Semi-supervised PolSAR classification based on the neighborhood minimum spanning tree
步驟2 以初始的標記像素點為初始頂點,構建無向圖G,生成多個鄰域最小生成樹,每一個樹中的像素點具有相同的標記;
步驟3 利用初始的標記樣本點,以view為每一個像素點的特征信息訓練SVM分類器,并用訓練好的SVM分類器對鄰域最小生成樹標記的樣本進行測試;
步驟4 挑選由分類器測試得到的結果中與鄰域最小生成樹生成的結果中標記一致的樣本,添加到初始的標記樣本集中,更新標記樣本集;
步驟5 重復步驟2到步驟4過程t次,直到得到滿意的分類器;
步驟6 用訓練好的分類器對剩余樣本進行測試。
5 實驗結果與分析
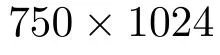
本文以SVM為基本分類器,采用徑向基核函數和5倍的交叉驗證,為了驗證本文算法的有效性,將本文方法與傳統的基于自訓練的半監督方法(Self-training)[10]、基于SVM分類器的監督分類方法(采用徑向基核函數和5倍的交叉驗證)[26]和監督Wishart方法[27]進行比較,并用總分類正確率和Kappa系數對實驗結果進行評估,所有的實驗進行10次,用平均值表示最終的分類結果。
5.1 AIRSAR L波段荷蘭地區的圖像分類
本實驗中每類別選擇不同數量的標記樣本(10,8, 6, 4)作為訓練樣本。圖6(a)為Pauli分解的RGB圖,圖6(a1)為真實地物。實驗結果如圖6,表1和表2所示。圖6(b)為本文方法的分類結果,圖6(c)為傳統Self-training算法的分類結果,圖6(d)為監督Wishart方法的分類結果,圖6(e)為SVM方法的分類結果。 表1為每類訓練樣本數量為10時不同方法的分類正確率。
由表1可以看出,本文分類方法的分類正確率為89.92%,高于Self-training分類方法12.73%,高于SVM分類方法19.62%,高于監督Wishart方法10.52%,而且本文方法中大部分類別的分類正確率都高于其它的對比方法。這主要是因為本文所提出半監督分類算法能夠有效地利用標記樣本和無標記樣本的信息,并采用鄰域最小生成樹的策略輔助選擇高可靠性的樣本,改善了基分類器的性能。但是本文方法在Rapeseed的分類正確率只有59.58%,低于Self-training方法7.56%。由圖6(b)可以看出,在本文方法中一部分Rapeseed被分為了Wheat 2和Wheat 3,這主要是這幾種農作物的葉子形狀非常相近,很難區別。對比圖6(c)可以看出,在Selftraining方法中一部分Wheat 2和Wheat 3被錯分為Rapeseed,因此雖然在Self-training方法中Rapeseed的分類正確率高,但是Wheat 2和Wheat 3分類正確率要低于本文方法的分類結果。此外本文方法在Bare soil區域的分類正確率雖然低于Wishart方法的分類正確率,但是分類正確率也已經大于96%。而且由圖6(d)可以看出,Wishart方法將很大一部分Water區域錯劃分為Bare soil區域,使Water區域的分類正確率只有46.85%,遠低于本文方法在該區域的分類正確率93.35%。由表2可以看出不同標記樣本時本文方法的分類正確率都要高于對比方法的分類結果;本文方法的Kappa系數也高于對比方法的Kappa系數,而且通過對比圖6中本文方法和對比方法的分類結果表示,也可以看出本文方法的分類結果的區域一致性也比其它的對比方法好。

圖6 Flevoland地區AIRSAR L波段數據不同方法的分類結果Fig. 6 Classification results of the Flevoland data acquired by AIRSAR
5.2 Radarsat-2 C波段荷蘭地區的圖像分類
本實驗中分別選擇每類別為不同數量的標記樣本(10, 8, 6, 4)作為訓練樣本。圖7(a)為Pauli分解的RGB圖,圖7(a1)為真實地物。實驗結果如圖7,表3和表4所示。圖7(b)為本文算法的分類結果,圖7(c)為Self-training方法的分類結果,圖7(d)為監督Wishart方法的分類結果,圖7(e)為SVM方法的分類結果。 表3為每類選10個標記樣本時,不同方法的分類正確率。
由表3和表4可以看出,本文方法的分類結果明顯高于傳統的Self-training方法,SVM方法和Wishart分類方法。由表4可以看出當每類訓練樣本數量10時,本文分類方法的分類正確率為84.03%,高于Self-training分類方法4.58%,高于SVM分類方法10.08%,高于監督Wishart方法5.22%。由表3可以看出本文方法在Urban和Cropland區域的分類正確率都要高于對比方法,但是在Forest區域的分類正確率低于監督Wishart方法的分類正確率。由圖7(d)可以看出,這主要是因為Wishart方法中一部分Cropland區域被分為了Forest類,雖然Wishart方法的Water區域分類正確率高,但是Cropland區域的分類正確率只有55.27%,明顯低于本文所提方法,而且本文方法Forest和Cropland區域總的分類正確率也要高于Wishart方法。而由表4可以看出選擇不同數量的標記樣本時,本文方法的分類正確率都要高于對比方法;同時本文方法的Kappa系數也高于對比方法的Kappa系數,而且通過對比圖7中本文方法和對比方法的分類結果圖,也可以看出本文方法的分類結果的區域一致性也比其它的對比方法要好。因此可以得出相同的結論,本文所提方法要明顯優于傳統的分類方法,尤其是在標記樣本較少的情況下。
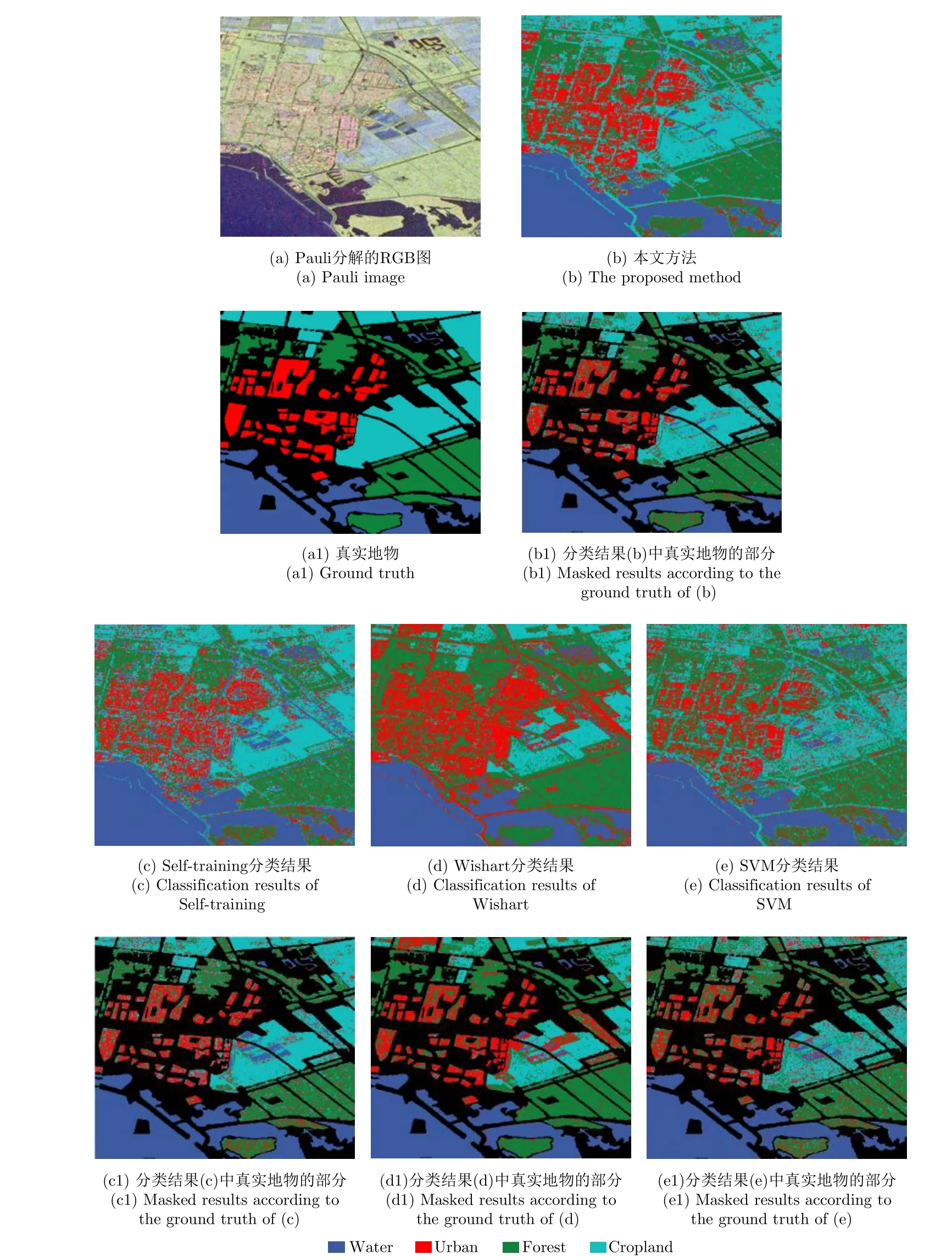
圖7 Flevoland地區Radarsat-2 C波段數據不同方法的分類結果Fig. 7 Classification result of the Flevoland data acquired by Radarsat-2

圖8 舊金山地區Radarsat-2 C波段數據不同方法的分類結果Fig. 8 Classification result of the San Francisco data acquired by Radarsat-2
5.3 Radarsat-2 C波段美國舊金山地區的圖像分類
本實驗分別選擇每類別為不同數量的標記樣本(10, 8, 6, 4)作為訓練樣本。圖8(a)為Pauli分解的RGB圖,圖8(a1)為真實地物。實驗結果如圖8,表5和表6所示。圖8(b)為本文方法的分類結果,圖8(c)為Self-training方法的分類結果,圖8(d)為監督Wishart方法的分類結果,圖8(e)為SVM方法的分類結果。表5為每類選10個標記樣本時,不同方法的分類正確率。
由表5和表6可以看出,本文方法的分類結果明顯高于傳統的Self-training方法,SVM方法和Wishart分類方法。由表6可以看出當每類訓練樣本數量10時,本文分類方法的分類正確率為78.71%,高于Self-training分類方法10.29%,高于SVM分類方法16.31%,高于監督Wishart方法4.94%。由表5可以看出本文方法在大部分區域的分類正確率都要高于對比方法,但是在Low-Density Urban區域的分類正確率低于監督Wishart方法的分類正確率。由圖8(d)可以看出,這主要是因為Wishart方法中Low-Density Urban區域和High-Density Urban區域沒有被有效地區分開,一部分的High-DensityUrban區域被錯分為Low-Density Urban,導致雖然Wishart方法的Low-Density Urban區域分類正確率高,但是High-Density Urban區域的分類正確率只有42.58%,明顯低于本文所提方法,而且在本文方法中這兩個區域總的分類正確率也要高于Wishart方法。而由表6可以看出當標記樣本數量不同時,本文方法的分類正確率都要高于對比方法;對比本文方法的Kappa系數和對比方法的Kappa系數,可以發現本文方法的Kappa系數要明顯高于對比方法的,而且通過對比圖8中本文方法和對比方法的分類結果圖,也可以看出本文方法的分類結果的區域一致性也比其它的對比方法要好。因此我們可以得出相同的結論,本文所提方法要明顯優于傳統的分類方法,尤其是在標記樣本較少的情況下。
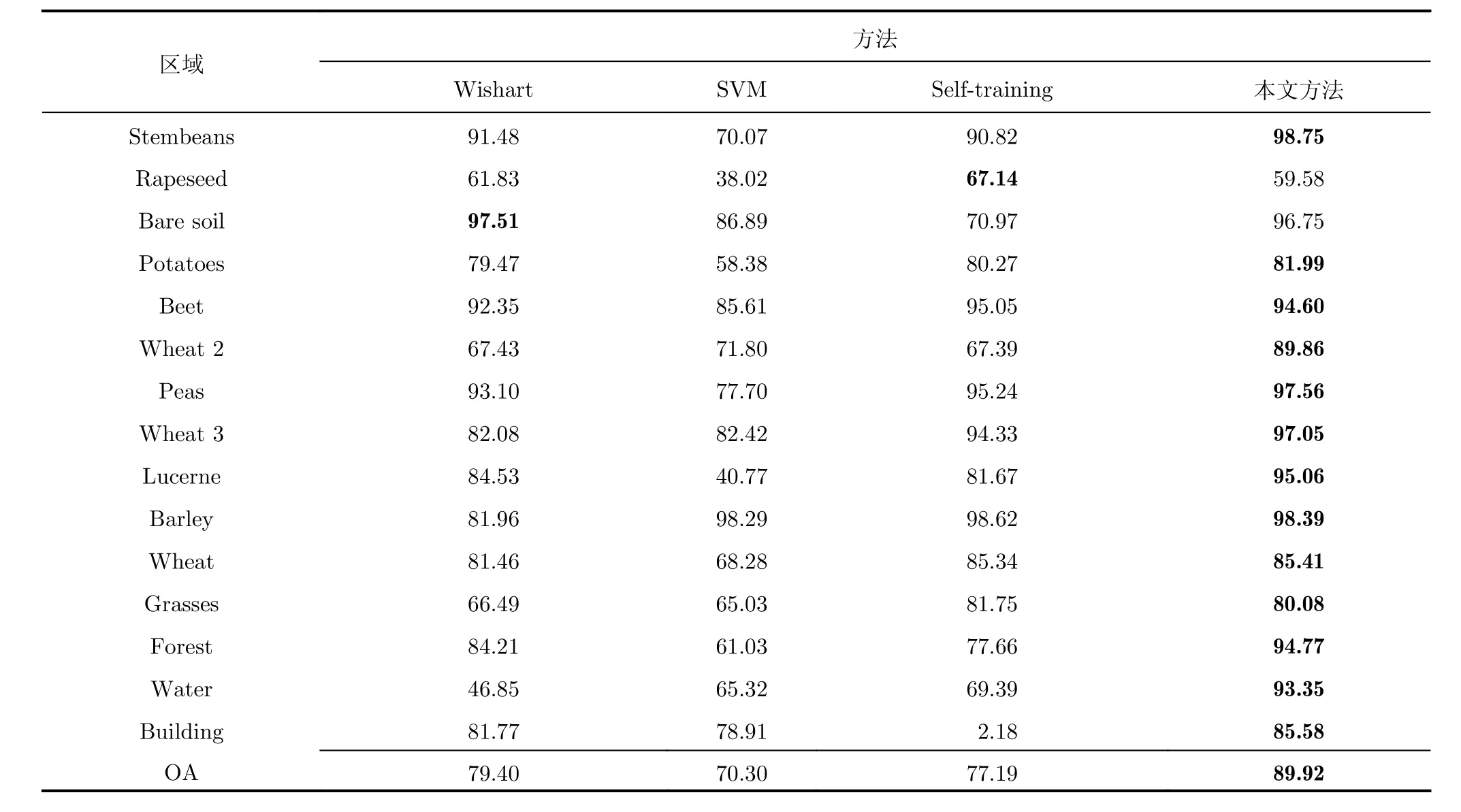
表1 AIRSAR L波段的Felvoland地區不同分類算法的分類精度(%)Tab. 1 Classification accuracy of the Flevoland area acquired by AIRSAR L band (%)
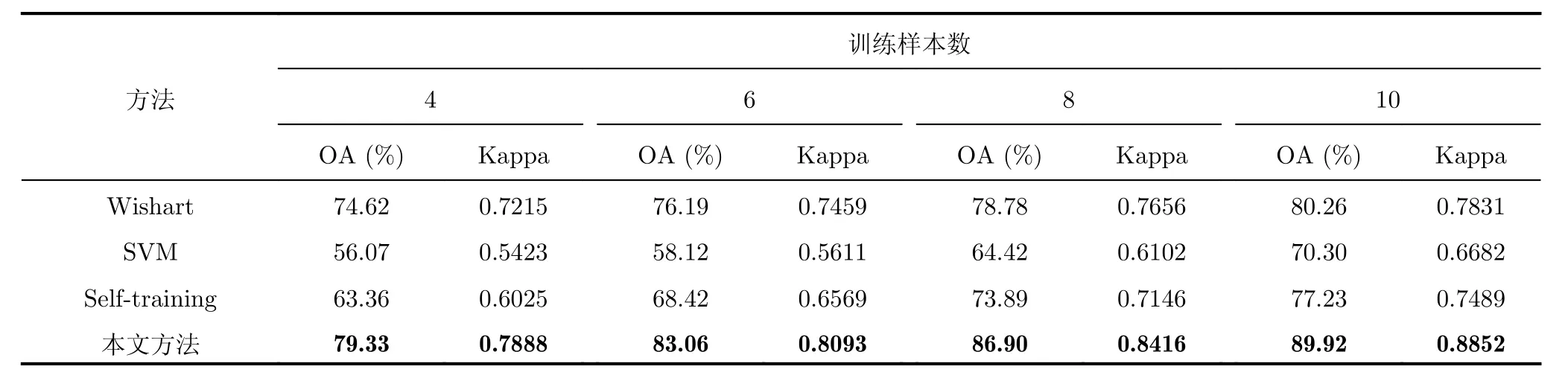
表2 AIRSAR L波段的Felvoland 地區不同訓練樣本的分類結果Tab. 2 Classification results of the Flevoland area acquired by AIRSAR L band with different number of training samples
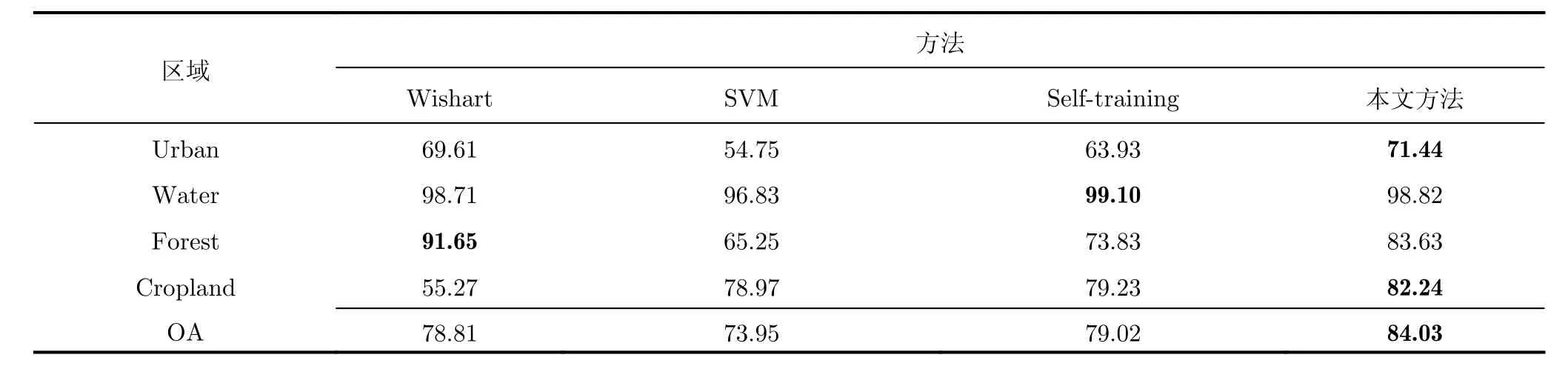
表3 Radarsat-2 C波段的Felvoland地區不同分類算法的分類精度(%)Tab. 3 Classification accuracy of the Flevoland area acquired by Radarsat-2 C band (%)

表4 Radarsat-2 C波段的Felvoland 地區不同訓練樣本的分類結果Tab. 4 Classification results of the Flevoland area acquired by Radarsat-2 C band with different number of training samples
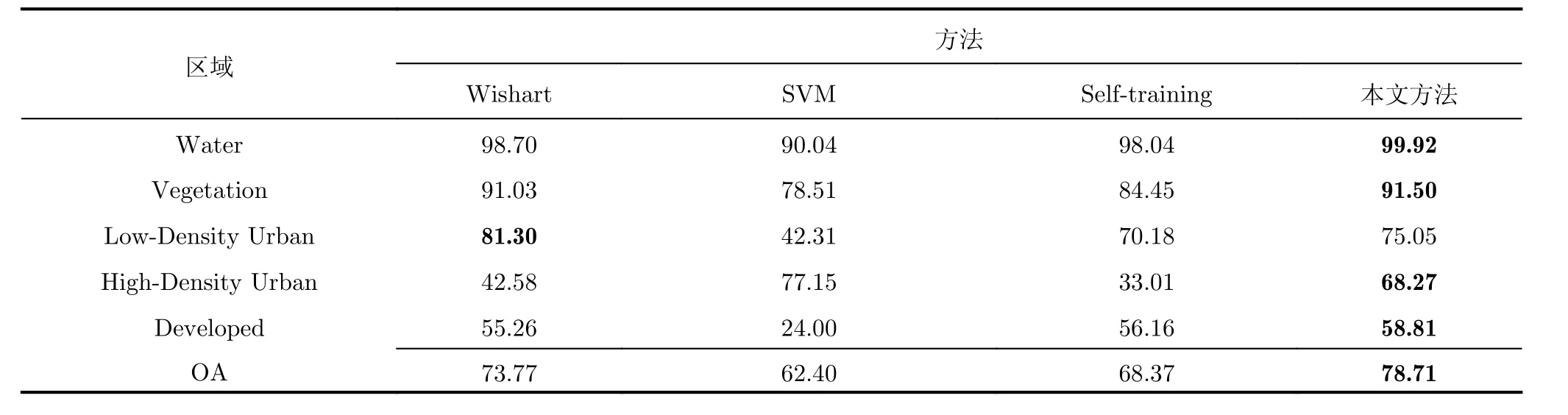
表5 Radarsat-2 C波段的舊金山地區不同分類算法的分類結果(%)Tab. 5 Classification accuracy of the San Francisco area acquired by radarsat-2 C Band (%)
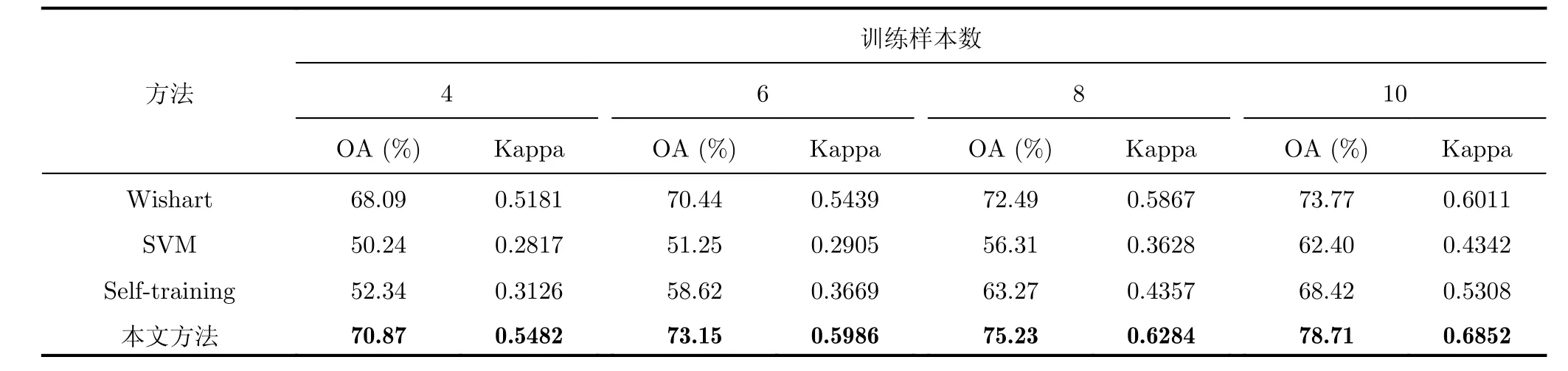
表6 Radarsat-2 C波段的舊金山地區不同訓練樣本的分類結果Tab. 6 Classification results of the San Francisco area acquired by Radarsat-2 C band with different number of training samples
5.4 自訓練次數對本文方法的影響
前面的實驗已經驗證了本文方法的有效性,本節分析迭代次數(自訓練次數)對實驗結果的影響。圖9(a)為迭代次數對分類正確率的影響,由圖9(a)可以看出隨著迭代次數的增加分類正確率逐漸增加,當迭代次數大于8次的時候分類正確率的增長逐漸減小趨于平滑。圖9(b)為迭代次數所消耗的時間成本,由圖9(b)可以看出隨著迭代次數的增加所耗費的時間迅速增加,這主要是因為隨著迭代次數的增加,標記樣本數量增加,最小生成樹的種子點數量增加,最小生成樹所需要的時間增加,自訓練分類器的時間也增加。

圖9 迭代次數對實驗結果的影響Fig. 9 The effects of number of iterations in the proposed method
6 結論
本文提出了一種基于鄰域最小生成樹的半監督極化SAR圖像分類方法。該方法能夠有效地利用標記樣本和無標記樣本,通過鄰域最小生成樹輔助學習的方式選擇高可靠性的樣本,添加到標記樣本集中,通過自訓練的方式不斷擴大標記樣本集,優化分類器,使在只有少量標記樣本時能夠獲得較高的分類正確率。并對3組真實極化SAR數據進行測試,實驗結果表明本文方法能夠獲得滿意的分類結果,尤其是在標記樣本非常少的情況下。而且通過選擇不同比例的訓練樣本實驗表明相較于傳統的方法本文方法獲得的分類精度更高。此外,通過分析迭代次數對實驗結果的影響實驗表明,本文方法選擇的無標記樣本是可靠的,通過添加被選擇的無標記樣本擴大標記樣本集逐漸改善分類器的性能。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
