基于進化粒子群算法的軍事訓練計劃智能優化
2019-08-22 06:55:32杜尚華樊率軍趙玉建
指揮控制與仿真 2019年4期
杜尚華,樊率軍,趙玉建
(國防大學聯合作戰學院,河北石家莊 050000)
軍事訓練中的補差訓練計劃生成與優化是基層部隊日常組訓的難點,其核心問題在于解決對薄弱訓練課目、組訓者和參訓人員的最優化分配,以保證在有效時間內最大限度利用訓練場地和裝備器材資源,達成訓練效益最大化,提升官兵整體訓練水平。補差訓練計劃優化問題可看做是經典排課問題的延伸,其在20世紀70年代已被證明屬于NP完全問題[1]。隨著計算機運算能力的日益提升,眾多智能優化算法被設計提出,為補差訓練計劃優化問題提供了技術可行解法。智能優化算法的發展可分為經典公式階段和實踐應用階段,前期的優化算法主要有拉格朗日松弛法[2]、切割平面法[3]、整數規劃法[4]等,其原理是通過公式演算找到局部極值,用以模擬全局最優值,算法約束條件較為苛刻,必須具備線性連續、可微等函數特點;應用階段的優化算法則通過模擬生物種群習性設計算法框架,代表性的優化算法有遺傳算法[5]、蜂群算法[6]、蟻群算法[7]、蛙跳算法[8]、螢火蟲算法[9]、魚群算法[10]、粒子群算法[11]等,其原理是通過偽隨機變量模擬生物某項生理特征,通過多代演化使局部最優解逼近全局最優解。此類算法突破了線性約束條件限制,為工程應用奠定了技術基礎,但也普遍存在收斂效率低、收斂時間不確定、易于陷入局部最優陷阱等問題。本文在總結前人研究基礎上,通過對比分析粒子群算法和遺傳算法的異同,提出融合了生物進化特征的進化粒子群算法,并將其應用于補差訓練計劃優化工程實踐中,實現了訓練計劃的自動生成和智能優化。
1 問題描述
補差訓練計劃智能優化問題可劃歸排課問題,但又有其獨立特征,區別主要在于:1)組訓者只在前日制定當天的補差訓練計劃,而排課通常為未來數日課程進行統一編排;2)補差訓練課目和組訓者由組訓者手工輸入,而排課通常由規則限制自動生成課目和授課人;3)補差訓練計劃以參訓人員歷史成績作為優化依據,而排課通常以參訓人員選課情況作為優化依據。基于此,補差訓練計劃優化問題描述如:算法輸入為組訓者手工選定當日的訓練課目、訓練時間段、組訓者。設組訓課目集合為K,訓練時間段集合為T,參訓人員集合為R。定義補差訓練計劃的評估指標如下:
1)平均分:用以衡量訓練計劃下所有參訓人員在該訓練課目此前1個月內的平均成績,記為T1。
2)參訓率:用以衡量訓練計劃下所有參訓人員在該訓練課目此前1個月內參加訓練天數占該課目訓練總天數的比例,記為T2。
3)優秀率:用以衡量訓練計劃下所有參訓人員在該訓練課目的成績達到優秀成績的比例,記為T3。
4)訓練強度:用以衡量訓練計劃下所有參訓人員在訓練當日的累計疲勞程度,參訓課目越多越疲勞,則訓練強度指標越大,記為T4。
5)同班率:用以衡量訓練計劃下每個訓練課目的參訓人員來自相同班級的程度,班級越多人員越零散,則同班率指標越低,記為T5。
設補差訓練計劃的綜合評分為F,則建立數學模型如下
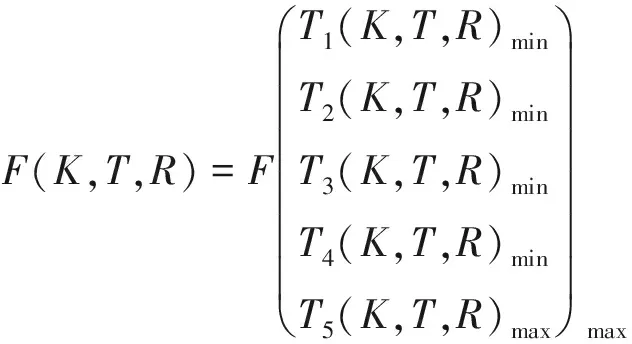
(1)
模型描述為:在(K,T)輸入限制條件下,合理調整R范圍,使T1-4取得最小值,T5取得最大值,并使綜合評分F(K,T,R)達到全局最大值。考慮到補差訓練計劃的工程應用性,還應引入如下硬約束條件:
1)訓練時間段有沖突的組訓課目內不得有重復人員出現。
2)同一組訓課目內不得有重復人員出現。
3)從未參加過某課目訓練的人員記為不參訓該課目。
2 算法構建
根據問題描述,算法要實現當日訓練課目、訓練時間段、組訓者的手工輸入,通過進化粒子群算法實現參訓人員的智能優化。即要設計3個子算法:1)課目、組訓者排序算法;2)訓練計劃綜合評分算法;3)智能優化算法。算法流程如圖1所示。
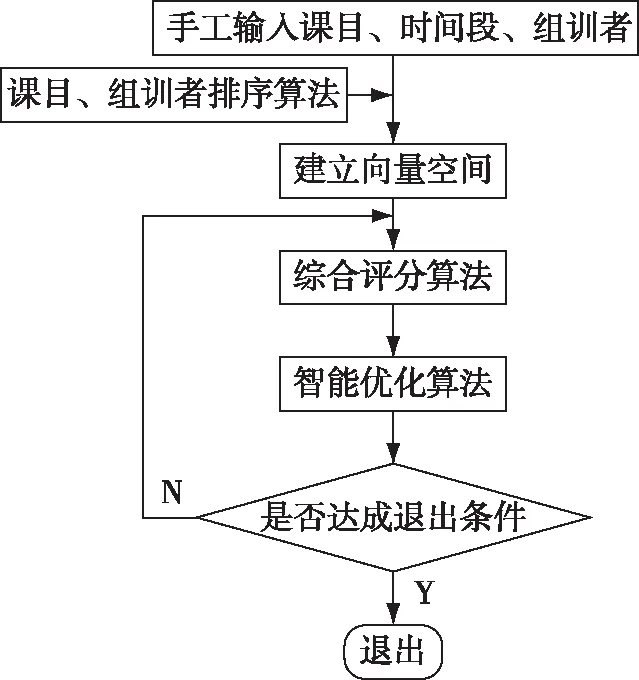
圖1 補差訓練計劃優化算法流程圖
2.1 課目、組訓者排序算法
該算法計算目的在于為組訓者提供手工輸入量化排序結果,便于找到訓練薄弱課目和與該課目對應的最高成績所在班班長(組訓者默認從各班班長中優選)。課目排序參照指標為此前1個月該參訓課目的平均優秀率,組訓者排序參照指標為此前1個月各班人員在該參訓課目的平均分。設此前1個月內共有m個課目參訓,參訓人員總數為n,其中第i個人在第j個訓練課目的平均成績為fij,則其優秀率yij計算公式為
(2)
課目j的優秀率Yj計算公式為
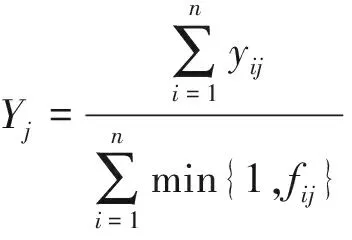
(3)
設第k個班級內共有r個人,則該班平均分Pkj計算公式為
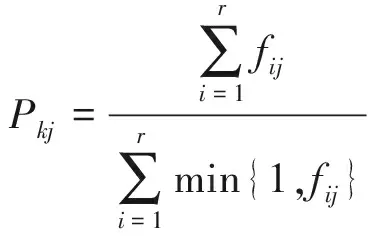
(4)
2.2 綜合評分算法
本文設計使用熵權法和理想點法融合的熵權理想點方法作為多指標融合評分算法,將補差訓練計劃的平均分、參訓率、優秀率、訓練強度、同班率指標合并為綜合評分結果代入智能優化。
2.2.1 評估指標計算
某項補差訓練計劃中,設同班率為T,平均分為F,優秀率為Y,訓練強度為Q,參訓率為C;共安排了p個訓練課目,其中第j個補差班級內的人員數為nj;此前1個月內,課目j共組織考核m次,其中人員i的該課目平均分為fij,則優秀率yij計算公式同公式(2),參訓率cij的計算公式如下
(5)
設人員i在補差訓練中共參與訓練xi次,則人員i的訓練強度qi計算公式為
qi=exi-xi
(6)
則補差訓練計劃的各評估指標計算公式為:
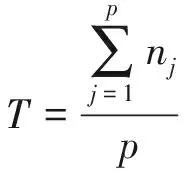
(7)
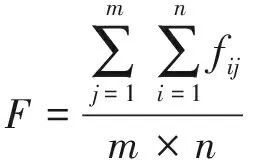
(8)
(9)
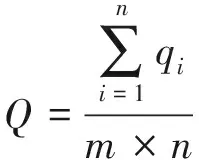
(10)
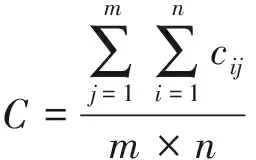
(11)
2.2.2 多指標融合計算
熵權法借鑒了自然界熵的概念,引入熵權重作為各評估指標的權重,使個體區分度大的評估指標獲取更大權重[12]。設平均分、參訓率、優秀率、訓練強度、同班率分別對應T1至T5評估指標,共有n個補差訓練計劃參與綜合評分計算,則構建出評估指標矩陣X,對應的子項xij表示第i個計劃中的第j項評估指標值。熵權重計算步驟如下:
1)歸一化處理矩陣X,生成歸一化矩陣P。
(12)
2)計算熵值ej。
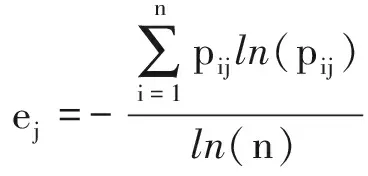
(13)
式中,若pij=0,則ej=0。
3)計算熵權重tj。
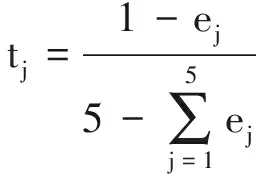
(14)
理想點法構思利用評估指標建立多維空間,每個參評對象映射為多維空間中的向量,將最優的評估指標值匯總生成正理想點位,最差評估指標值匯總生成負理想點位,通過計算每個參評對象和正負理想點位之間的距離,獲取綜合評分[13]。融合熵權重的熵權理想點法計算步驟如下:
1)生成正負理想點位A+和A-。設歸一化矩陣P值為pij,則最優評估指標值pj+和最差評估指標值pj-計算公式為:
(15)
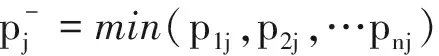
(16)
2)計算第i個補差訓練計劃距離A+和A-的距離d+和d-。考慮到各評估指標區分度差異,將熵權重tj代入,熵權理想點法計算公式為:
(17)
(18)
3)計算各補差訓練計劃的綜合評分Mi。計算公式為
(19)
2.3 粒子群算法
粒子群算法由Kennedy和Eberhart在1995年提出,借鑒生物界中鳥群的覓食行為,算法建立多維空間,向空間釋放多個隨機個體,將綜合評分結果看作食物,則參評個體會根據空間中各位置的綜合評分高低自發向食物豐沛區游走,并在多代游走后找到全局最優位置[14]。具體算法如下:
Step1:建立D維空間,設補差訓練計劃共參訓m個課目,第j個課目參訓人數為nj,則D的維度計算公式如下
(20)
Step2:設置初始種群。設種群中包含1 000個個體,個體內部存儲當前位置和歷史最優位置及其對應分值,其結構體如表1所示。

表1 粒子群個體結構表
Step3:計算每個個體下一步的游走位置。設個體當前位置為Xi,Pi為個體第i次游走遍歷到的最優位置,Qi為種群經過i次游走的最優位置,Vi為個體第i次游走的步長;r1和r2為[0,1]之間的隨機實數。則個體第i+1次游走的步長Vi+1計算公式為
Vi+1=0.5Vi+0.3r1(Pi-Xi)+0.3r2(Qi-Xi)
(21)
個體的第i+1次游走位置Xi+1計算公式為
Xi+1=Xi+Vi+1
(22)
Step4:調用熵權理想點法計算該位置的綜合評分。
Step5:使用冒泡法更新個體的歷史最優評分位和種群的當前最優綜合評分位。
Step6:重復Step3-Step5。并判斷是否滿足退出條件:種群最優評分的多代差值到達收斂閾值。滿足退出條件則退出算法,輸出種群最優位置及其對應綜合評分。其算法流程如圖2所示。
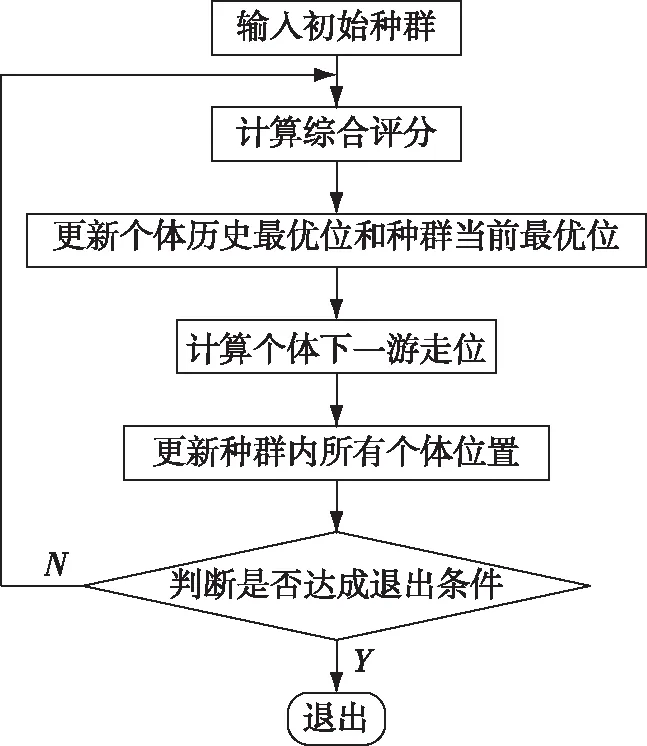
圖2 標準粒子群算法流程圖
2.4 量子粒子群算法
粒子群算法雖然在多代游走后能夠使最優位置趨向于全局最優,但也易于陷入局部最優陷阱,為解決上述問題,Sun等人提出量子粒子群算法,將量子遷移思想引入個體位置計算中,使個體具備全空間遷移能力,一定程度上解決了全局尋優問題[15]。與標準算法相比,量子粒子群算法的步長Vi+1計算公式為
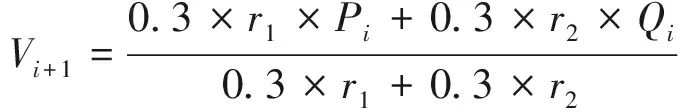
(23)
設種群內個體數目為n,Pij表示種群內第j個個體在第i次游走后的歷史最優位。引入第i次游走的遷移系數Mi計算公式為
(24)
設u為[0,1]之間的隨機實數。位置Xi+1計算公式為
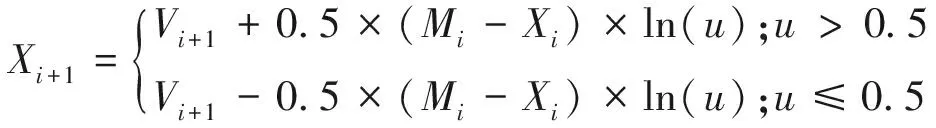
(25)
算法其余部分同標準粒子群算法。
2.5 遺傳算法
遺傳算法借鑒自然界物種優勝劣汰的進化機制,通過構建生物種群,模擬出生物的繁殖、變異、適應和淘汰進程,通過多代進化使后代個體具備更強的適應度,取得更高的綜合評分[16]。具體算法如下:
Step1:設置初始種群。種群中包含隨機產生的1000個個體。
Step2:計算1 000個體的綜合評分。
Step3:個體淘汰。首先刪除壽命超過上限的個體,其次依據“高分個體淘汰概率小,低分個體淘汰概率大”的原則使用輪盤法優選個體,最終優選出100個個體。
Step4:種群繁殖變異。使用輪盤法挑選出高分個體作為父代個體,然后以千分之一的概率使其參訓人員發生變異,產生與父代個體相似的子代個體,最終使種群規模達到1 000。
Step5:重復Step2-Step4。并判斷是否滿足退出條件:種群最優個體綜合評分是否收斂。滿足退出條件則退出算法,輸出最優個體及其對應綜合評分。
通過上述算法分析可以發現,粒子群算法和遺傳算法作為智能優化算法具有較多相似點,如建立初始種群、設置隨機變量、隨機變異游走、以局部最優收斂至全局最優等。區別主要在于:1)遺傳算法可以在最優個體的基礎上不斷回溯變異,粒子群算法作為隨機游走算法無法回溯,這就造成了粒子群算法較遺傳算法更容易陷入局部最優陷阱;2)遺傳算法的變異是隨機行為,粒子群算法的變異受個體最優和全局最優解的制約,使隨機行為可控,這就造成了遺傳算法收斂效率相比粒子群算法更低。
2.6 進化粒子群算法
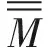

圖3 進化粒子群算法流程圖
具體算法如下:
Step1-Step4:同量子粒子群算法。
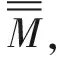
Step6:補充新個體。使用輪盤法挑選出高分個體的歷史最高分值位置,在此位置產生子代個體,最終使種群規模達到1 000。
Step7:更新個體和種群的最優評分位置。
Step8:重復Step3-Step7。并判斷是否滿足退出條件:種群最優位置評分值是否收斂。滿足退出條件則退出算法,輸出種群最優位置及其對應綜合評分。
3 仿真實驗
為了檢驗遺傳算法、粒子群算法、量子粒子群算法、進化粒子群算法等4種智能優化算法在補差訓練計劃智能優化中的性能,本文依托工程實例項目設計開發“軍事訓練分析系統”中的“補差訓練模塊”,模塊整體界面如圖4所示。
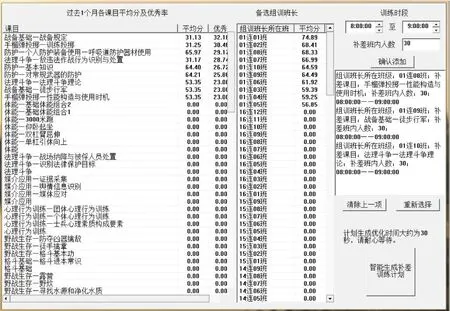
圖4 補差訓練智能優化模塊整體界面
計算機配置:Intel酷睿雙核T7300 2.0 GHz中央處理器;3 G內存;32位Win7操作系統;vc6.0系統開發環境。
3.1 各智能優化算法收斂性比較
實驗設計使用統一的補差訓練計劃評估指標(平均分、參訓率、訓練強度、優秀率、同班率)和綜合評分算法(熵權理想點法),演化相同代數(650代),各智能優化算法的各代最優個體綜合評分結果如圖5所示。
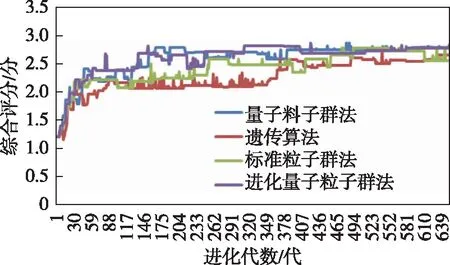
圖5 各智能優化算法各代綜合評分結果
實驗結果表明:在進化相同代數時,遺傳算法綜合評分效果最差,量子粒子群法和本文設計的進化量子粒子群法效果最好,標準粒子群法效果居中;相比較而言,本文設計的進化量子粒子群法能夠利用淘汰和繁殖時機達成個體分值的突變陡增,使群體綜合評分整體上升,該特性也存在于遺傳算法的統計圖中,標準粒子群法和量子粒子群法不具備此特性。
3.2 各智能優化算法結果比較
分析各智能優化算法達成綜合評分收斂的代數統計情況,對比分析如表2所示。
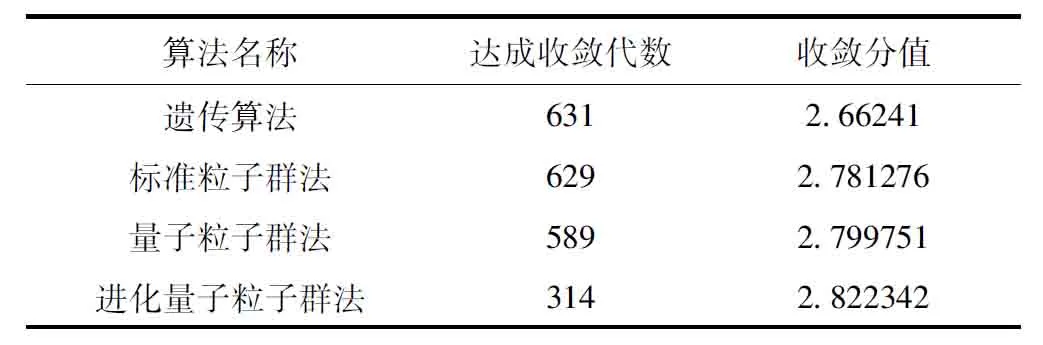
表2 各智能優化算法收斂代數統計表
實驗結果表明:相比較而言,進化量子粒子群法在收斂代數和收斂分值上均要優于主流智能優化算法。
3.3 各智能優化算法效率比較
在進化相同代數時,分別選取2-10個訓練課目,分析各智能優化算法的計算耗時如圖6所示。
實驗結果表明:遺傳算法的計算耗時最短,進化量子粒子群法的計算耗時最長,10課目時的耗時差異為14.75 s。相比于傳統的手工擬制補差訓練計劃,各智能優化算法的計算耗時都在可容忍范圍內。
3.4 補差訓練計劃結果分析
通過上述實驗分析,本文設計的進化量子粒子群法綜合性能較其他對比智能優化算法優化效果更顯著,將該算法代入補差訓練計劃智能優化模塊,得到補差訓練計劃如表3所示。
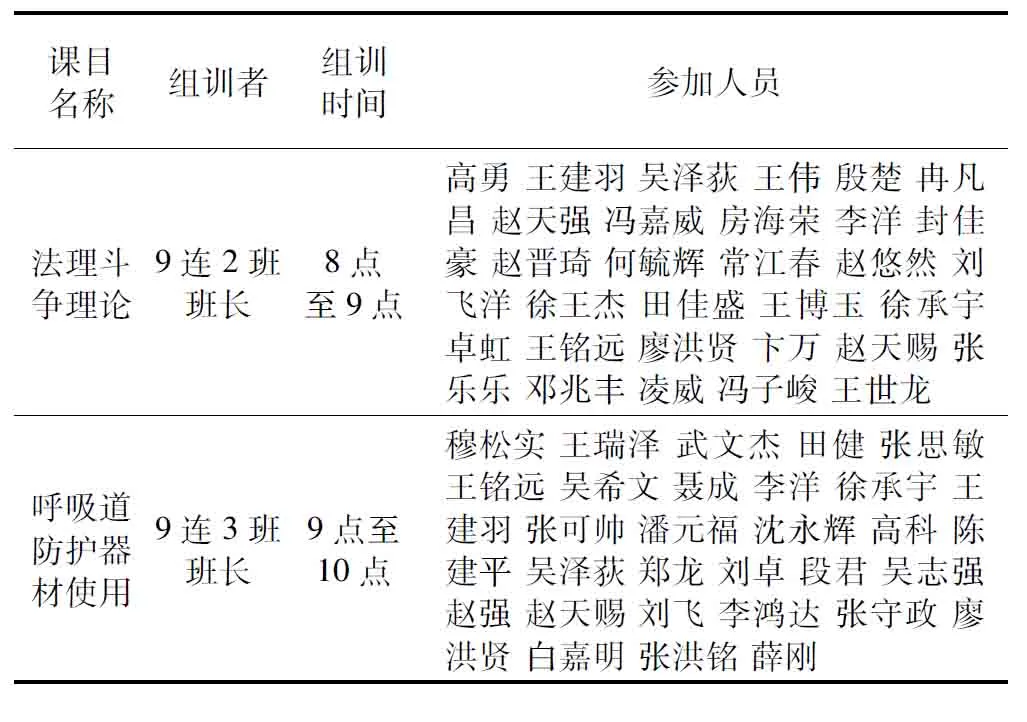
表3 補差訓練計劃示例
4 結束語
本文結合遺傳算法和粒子群算法的優化原理,設計出兼具遺傳算法優勢的進化粒子群算法,并將其引入補差訓練計劃工程應用中,通過和同類智能優化算法的綜合對比,驗證了該算法的有效性,并實現了補差訓練計劃的智能優化。創新點有:1)根據補差訓練計劃工程實際,設計了符合工程特點的熵權理想點法作為多指標融合評分算法;2)設計出兼具遺傳算法優勢的進化粒子群算法,通過實驗證明了該算法較標準粒子群算法和遺傳算法收斂效率更高,能有效避免個體在游走中陷入局部最優陷阱;3)將算法引入工程項目實踐中,使用效果相比于人工擬制訓練計劃提升明顯。進化粒子群算法作為智能優化算法,具有原理易懂、結構簡單的特征,不僅用于補差訓練計劃的智能優化,具有廣泛的智能優化應用前景。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
