基于移動(dòng)圖書(shū)館平臺(tái)的知識(shí)挖掘研究
2019-08-29 03:45:46孔慶祝
孔慶祝
(泰州職業(yè)技術(shù)學(xué)院 圖書(shū)館,江蘇 泰州 225300)
1 知識(shí)挖掘組成要素
1.1 數(shù)據(jù)集成
在邏輯或物理上將不同來(lái)源、格式、特點(diǎn)性質(zhì)的數(shù)據(jù)的關(guān)系與實(shí)體提煉出來(lái)集中后,在邏輯上或物理上有機(jī)地集中,經(jīng)關(guān)聯(lián)和聚合處理后成為統(tǒng)一定義的標(biāo)準(zhǔn)的數(shù)據(jù)并加以存貯,這也是應(yīng)對(duì)紛繁冗余大數(shù)據(jù)的有效方式。數(shù)據(jù)倉(cāng)庫(kù)、聯(lián)邦數(shù)據(jù)庫(kù)和基于中間件模型等方法都是目前較好的數(shù)據(jù)集成手段。面對(duì)清洗數(shù)據(jù)保證質(zhì)量與粒度過(guò)細(xì)難免過(guò)濾有效信息矛盾,需要仔細(xì)考量,在質(zhì)與量之間尋找一個(gè)最佳結(jié)合點(diǎn),權(quán)衡利弊[1]。
1.2 數(shù)據(jù)存儲(chǔ)
大數(shù)據(jù)時(shí)代的數(shù)據(jù)量是單機(jī)存貯難以承受的,再想依靠傳統(tǒng)結(jié)構(gòu)化存儲(chǔ)模式顯然不合適了,并且實(shí)際數(shù)據(jù)處理過(guò)程往往都由幾種數(shù)據(jù)存儲(chǔ)方式混合使用,采用分布式存儲(chǔ)方式就是自然而然的事。分布式存儲(chǔ)的典型代表有NoSQL(Not Only SQL)和Hadoop。NoSQL 泛指非關(guān)系型數(shù)據(jù)庫(kù),這類(lèi)數(shù)據(jù)庫(kù)存儲(chǔ)數(shù)據(jù)的是鍵值對(duì),因此不存在固定的結(jié)構(gòu),元組中的字段可以不同,根據(jù)需要可以調(diào)整元組鍵值對(duì)。Hadoop 由數(shù)據(jù)庫(kù)(Cassandra)、數(shù)據(jù)處理(MapReduce)及文件系統(tǒng)(HDFS)等模塊組成,它是從模仿GFS(Google File System)、MapReduce 開(kāi)始不斷發(fā)展成為現(xiàn)在的大數(shù)據(jù)處理平臺(tái)的,甚至在業(yè)內(nèi)Hadoop已經(jīng)成為大數(shù)據(jù)處理的首選工具。
1.3 數(shù)據(jù)分析
大數(shù)據(jù)處理中最關(guān)鍵的業(yè)務(wù)就是數(shù)據(jù)分析,它包含分類(lèi)和聚類(lèi)量方面的功能。但是現(xiàn)有的聚分類(lèi)技術(shù),在應(yīng)對(duì)大數(shù)據(jù)的超高維度問(wèn)題時(shí),常常顯得力不從心。EM、SVM、k-means、決策樹(shù)等經(jīng)典算法都很難滿(mǎn)足應(yīng)用大數(shù)據(jù)分析的需要。就連Google 最早采用的應(yīng)用于批處理大數(shù)據(jù)處理的計(jì)算模型MapReduce,處理超高維度分聚類(lèi)計(jì)算時(shí)由于自身局限也不得不加以改進(jìn)算法,調(diào)整自己的計(jì)算模型。知識(shí)挖掘的組合方法由訓(xùn)練數(shù)據(jù)確定一組基分類(lèi)器,通過(guò)對(duì)多個(gè)分類(lèi)器的結(jié)果聚集使得性能上遠(yuǎn)超單個(gè)分類(lèi)器。大數(shù)據(jù)中數(shù)據(jù)特點(diǎn)就是種類(lèi)多、體量大、干擾強(qiáng),最終可能導(dǎo)致分析結(jié)果的波動(dòng)性大,組合方法較好地解決了分類(lèi)器不夠穩(wěn)定的問(wèn)題,通過(guò)訓(xùn)練數(shù)據(jù)構(gòu)建一組基分類(lèi)器,在聚集多個(gè)分類(lèi)器獲得更好的性能,更重要的是,組合方法在并行處理比較方便,這就為提高大數(shù)據(jù)分類(lèi)時(shí)訓(xùn)練和測(cè)試速度奠定了基礎(chǔ)。組合多個(gè)分類(lèi)器的方法有裝袋和提升,裝袋又稱(chēng)自助聚集,受訓(xùn)練數(shù)據(jù)過(guò)分?jǐn)M合的影響較小,它首先隨機(jī)抽樣組成若干訓(xùn)練集,各訓(xùn)練集數(shù)據(jù)構(gòu)建各自基分類(lèi)器,通過(guò)這些分類(lèi)器對(duì)測(cè)試樣本的類(lèi)別進(jìn)行投票,根據(jù)最終得票最高的類(lèi)別判定該樣本的類(lèi)別;提升與裝袋思路有所不同,它通過(guò)對(duì)所有訓(xùn)練數(shù)據(jù)賦予權(quán)重值來(lái)實(shí)現(xiàn)樣本分布的自適應(yīng)處理,典型的提升方法Adaboost 操作是這樣的,首先賦予各訓(xùn)練數(shù)據(jù)相同的選取概率權(quán)重,在抽取訓(xùn)練數(shù)據(jù)構(gòu)建首個(gè)分類(lèi)器后,對(duì)誤分類(lèi)數(shù)據(jù)的選取概率權(quán)重適當(dāng)增加,接下來(lái)按新的概率重新抽取訓(xùn)練數(shù)據(jù),組建分類(lèi)器,依據(jù)最終的需要確定迭代次數(shù),不斷重復(fù)這一過(guò)程迭代得到若干分類(lèi)器,最終的輸出結(jié)果通過(guò)分類(lèi)器的加權(quán)投票得出。當(dāng)然,提升也有其局限,由于對(duì)誤分類(lèi)數(shù)據(jù)關(guān)注過(guò)大,分類(lèi)模型中存在數(shù)據(jù)過(guò)分?jǐn)M合的風(fēng)險(xiǎn)。總體而言,無(wú)論是裝袋還是提升比單個(gè)模型都大大提高了準(zhǔn)確率,只不過(guò)提升在準(zhǔn)確率提高方面功能更加強(qiáng)大而己。
1.4 語(yǔ)義處理
語(yǔ)義處理技術(shù)主要功能就是輔助機(jī)器,增強(qiáng)機(jī)器對(duì)數(shù)據(jù)的理解,從而提高各種知識(shí)挖掘算法的語(yǔ)義化能力的一種方法。它在對(duì)現(xiàn)有人工智能、自然語(yǔ)言處理、Web 技術(shù)等技術(shù)方法整合的基礎(chǔ)上,匯總生成語(yǔ)義知識(shí)庫(kù),在進(jìn)行深層的數(shù)據(jù)分析時(shí),通過(guò)增強(qiáng)語(yǔ)義理解減少知識(shí)挖掘的耗損,從而提高運(yùn)算的效率和性能。語(yǔ)義處理的基礎(chǔ)是語(yǔ)義知識(shí),很多機(jī)構(gòu)為此構(gòu)建了很多語(yǔ)義知識(shí)庫(kù),像中英文的知網(wǎng)HowNet,英文語(yǔ)義知識(shí)庫(kù)詞網(wǎng)WordNet、FrameNet等等都是業(yè)內(nèi)知名的語(yǔ)義知識(shí)庫(kù)。這些語(yǔ)義知識(shí)庫(kù)規(guī)范化和標(biāo)準(zhǔn)化都比較高,但由于成本高昂,更新就不夠及時(shí),很多現(xiàn)代新的詞匯都未收錄。有鑒于此,有學(xué)者從大數(shù)據(jù)理念自動(dòng)構(gòu)建語(yǔ)義知識(shí)獲得靈感,通過(guò)收錄不同來(lái)源的詞語(yǔ)對(duì)象,結(jié)合各種詞語(yǔ)關(guān)系形成具有語(yǔ)義關(guān)聯(lián)的語(yǔ)義知識(shí)庫(kù),這種新語(yǔ)義知識(shí)庫(kù)較以往的語(yǔ)義知識(shí)庫(kù)效率更高、成本更低、更新速度更快,又足以支持語(yǔ)義處理。比如,從谷歌、百度、維基或其他網(wǎng)絡(luò)中的海量數(shù)據(jù)中抽取語(yǔ)義知識(shí),結(jié)合基于統(tǒng)計(jì)合計(jì)規(guī)則的方法進(jìn)行重組,由于網(wǎng)絡(luò)數(shù)據(jù)通常含有人工標(biāo)注、結(jié)構(gòu)化程度較高的語(yǔ)義信息,這樣我們?cè)诔槿≌Z(yǔ)義知識(shí)時(shí)效率將大大提升,語(yǔ)義表達(dá)也會(huì)更加清晰明確,這樣因語(yǔ)義稀疏帶來(lái)的分析性能損失問(wèn)題就會(huì)得到有效控制。這對(duì)我們處理短文本尤其是微博、論壇等的知識(shí)挖掘有重要意義。
1.5 可視化知識(shí)挖掘
所謂可視化知識(shí)挖掘就是將知識(shí)挖掘的結(jié)果以圖形或表格的形式直觀(guān)顯示出來(lái)。在海量數(shù)據(jù)的環(huán)境中,挖掘結(jié)果之間往往具有極其復(fù)雜關(guān)聯(lián)關(guān)系,這就大大影響了數(shù)據(jù)可視化的效果。社會(huì)網(wǎng)絡(luò)總是復(fù)雜和多向鏈接的,盡管有可視化的網(wǎng)絡(luò)結(jié)構(gòu)圖的輔助,多數(shù)用戶(hù)仍不容易挖掘出自己感興趣特征。知識(shí)數(shù)據(jù)可視化、挖掘結(jié)果與過(guò)程可視化和人機(jī)交互是可視化知識(shí)挖掘的三個(gè)組成部分。可視化知識(shí)挖掘是通過(guò)用戶(hù)可視、交互地方式進(jìn)行知識(shí)挖掘的一種方法,在圖形圖表的輔助,用戶(hù)實(shí)際上對(duì)具體的數(shù)據(jù)分析有所了解甚至是參與,只不過(guò)這種參與離不開(kāi)交互式的數(shù)據(jù)分析過(guò)程引導(dǎo),并且程度上也不可能太深入,畢竟太過(guò)深入的知識(shí)挖掘用戶(hù)缺乏理解。但在分析過(guò)程中通過(guò)數(shù)據(jù)立方體、趨勢(shì)圖、標(biāo)簽云等圖形圖標(biāo)等可視化方式,確實(shí)增加了讓用戶(hù)對(duì)分析過(guò)程和結(jié)果理解,再加上人機(jī)交互,這對(duì)用戶(hù)定制處理任務(wù),理解挖掘結(jié)果也是很幫助的,限制社會(huì)圖中節(jié)點(diǎn)的數(shù)量,顯示用戶(hù)指定的高權(quán)重節(jié)點(diǎn)就是知識(shí)挖掘中用戶(hù)參與互動(dòng)的具體實(shí)例。
2 具體實(shí)踐
我館移動(dòng)平臺(tái)是在超星數(shù)字圖書(shū)館基礎(chǔ)上開(kāi)發(fā)的,依靠數(shù)據(jù)分析、數(shù)據(jù)倉(cāng)儲(chǔ)、知識(shí)挖掘、文獻(xiàn)計(jì)量學(xué)模型等相關(guān)技術(shù),完成了本地館藏和超星網(wǎng)絡(luò)資源數(shù)據(jù)庫(kù)群的資源整合,初步建立起本地資源數(shù)據(jù)庫(kù)、匯文圖書(shū)館系統(tǒng)、超星遠(yuǎn)程資源庫(kù)等復(fù)雜異構(gòu)數(shù)據(jù)庫(kù)的關(guān)聯(lián),進(jìn)而通過(guò)聚類(lèi)分類(lèi)、引文分析、知識(shí)關(guān)聯(lián)分析等實(shí)現(xiàn)高價(jià)值學(xué)術(shù)文獻(xiàn)發(fā)現(xiàn)、縱橫結(jié)合的深度知識(shí)挖掘、可視化的全方位知識(shí)關(guān)聯(lián),為廣大師生教學(xué)科研提供信息資源支撐。超星系統(tǒng)除了具有一般搜索引擎的信息檢索功能外,其最大的功能是提供了深達(dá)知識(shí)內(nèi)在關(guān)系的強(qiáng)大知識(shí)挖掘和情報(bào)分析功能。為此,發(fā)現(xiàn)的檢索字段大大增加,更具備大到默認(rèn)支持全庫(kù)數(shù)據(jù)范圍的空檢索,細(xì)到可以通過(guò)勾選獲取非常專(zhuān)指主題的分面組合檢索,從而實(shí)現(xiàn)了對(duì)學(xué)術(shù)宏觀(guān)走向、跨學(xué)科知識(shí)交叉及影響和知識(shí)再生方向的判斷,具備了對(duì)任何特定年代,或特定領(lǐng)域,或特定人及機(jī)構(gòu)的學(xué)術(shù)成果態(tài)勢(shì)進(jìn)行大尺度、多維度的對(duì)比性分析和研究。超星系統(tǒng)是學(xué)者準(zhǔn)確而專(zhuān)業(yè)地進(jìn)行學(xué)術(shù)探索和激發(fā)創(chuàng)新靈感的研究工具[2]。
2.1 移動(dòng)圖書(shū)館平臺(tái)中的知識(shí)挖掘?qū)W(xué)生的作用
學(xué)生利用移動(dòng)圖書(shū)館平臺(tái)進(jìn)行知識(shí)挖掘?qū)懻撐暮涂荚嚕趯?xiě)論文時(shí),就拿選題來(lái)說(shuō),以前甚至沒(méi)用我們系統(tǒng)的學(xué)生現(xiàn)在選題大部分都是憑感覺(jué)。那么我們?cè)趺礃硬拍苓x一個(gè)恰當(dāng)?shù)恼n題去做呢?首先就是要找適合自己的,其次就是要選擇導(dǎo)師擅長(zhǎng)的。如果自己不適合如何發(fā)揮到極致?如果導(dǎo)師不擅長(zhǎng)怎么給你做很好的指導(dǎo),所以選題是要有依據(jù)的。
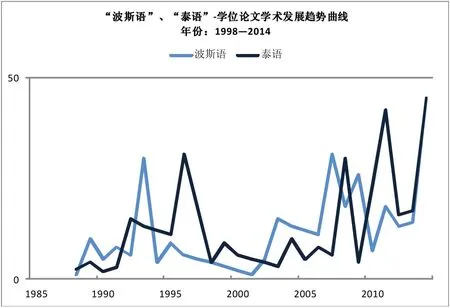
圖1 “波斯語(yǔ)”、“泰語(yǔ)”-學(xué)位論文學(xué)術(shù)發(fā)展趨勢(shì)曲線(xiàn)圖
圖1 顯示的是波斯語(yǔ)和泰語(yǔ)兩種學(xué)術(shù)趨勢(shì)曲線(xiàn),論文選題一目了然。再看圖2,在導(dǎo)師擅長(zhǎng)的問(wèn)題上,比如說(shuō)如果是這位丁老師學(xué)生的話(huà)肯定選擇建筑史會(huì)是很好的選擇,因?yàn)樗梢越o你更多的指導(dǎo)。但如果你選擇其他的方向,可能指導(dǎo)意見(jiàn)相對(duì)要少些了。
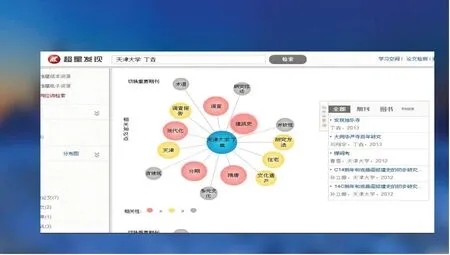
圖2 導(dǎo)師丁垚學(xué)術(shù)方向圖
論文寫(xiě)作查資料階段,看圖3 查找論文“知識(shí)產(chǎn)權(quán)融資法律問(wèn)題研究”,以前就是搜索知識(shí)產(chǎn)權(quán),融資,產(chǎn)權(quán)融資等;那么現(xiàn)在發(fā)現(xiàn)系統(tǒng)可以從除了這幾個(gè)關(guān)鍵詞以外的相關(guān)主題突破,比如資產(chǎn)證券化、風(fēng)險(xiǎn)投資等,這些詞都是和這個(gè)所搜索的關(guān)鍵詞關(guān)系很密切的一些領(lǐng)域。那么我們?cè)诓檎屹Y料以前基本是海底撈針,只能根據(jù)論文題目拆分查找,由圖4 所示,現(xiàn)在通過(guò)超星提供的分類(lèi)聚類(lèi)功能可以將相關(guān)的知識(shí)領(lǐng)域呈現(xiàn)出來(lái),檢索的路徑更多,最終更容易找到所需的資料。通過(guò)多種篩選取其精華,依據(jù)超星形成的可視圖可以很輕松地將某一領(lǐng)域的名家查出來(lái),再檢索他的作品。
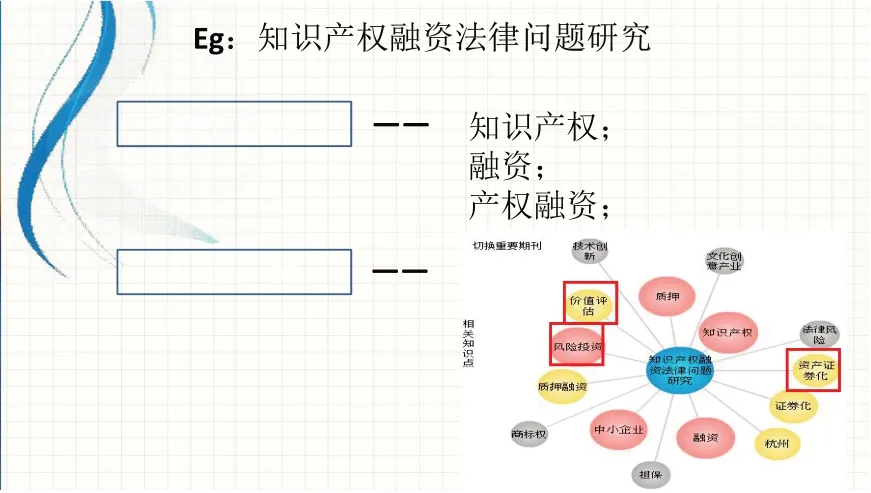
圖3 知識(shí)產(chǎn)權(quán)融資法律問(wèn)題資料查找圖
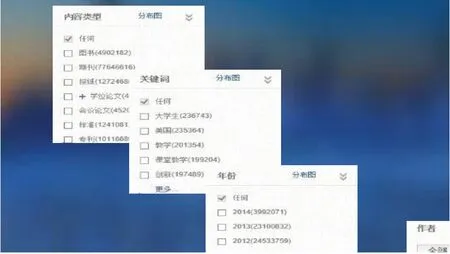
圖4 分類(lèi)聚類(lèi)示意圖
2.2 移動(dòng)圖書(shū)館平臺(tái)中的知識(shí)挖掘?qū)處煹淖饔?/h3>
老師可以實(shí)時(shí)了解所研究的課題目前研究現(xiàn)狀,如研究學(xué)者、已有研究成果、研究成果趨勢(shì)、數(shù)量及發(fā)展方向。對(duì)進(jìn)入一些新興學(xué)科或交叉學(xué)科,我們可以作一個(gè)發(fā)展趨勢(shì)研究,如3D打印技術(shù)現(xiàn)在很火,在我們的知識(shí)挖掘數(shù)據(jù)中也會(huì)顯示出來(lái),我們來(lái)看下具體的數(shù)據(jù),會(huì)發(fā)現(xiàn)一個(gè)什么事情呢?如果說(shuō)11年、12年就發(fā)現(xiàn)有會(huì)火的這個(gè)趨勢(shì),當(dāng)時(shí)我們?nèi)パ芯窟@個(gè),對(duì)您有什么價(jià)值。在做研究的過(guò)程中,都想知道在這個(gè)領(lǐng)域中,我們中國(guó)有誰(shuí)最早進(jìn)行研究的。在這里設(shè)置出版日期升序排序就可以看到這樣的一個(gè)搜索結(jié)果。比如埃博拉病毒在國(guó)內(nèi)研究最早的90年丁老師關(guān)于5000只大猩猩死于埃博拉病毒的報(bào)道。除了最早的,我們可能還想知道這個(gè)研究領(lǐng)域中最具影響力的人物是誰(shuí)啊?所以說(shuō)知識(shí)關(guān)聯(lián)圖譜就是為了發(fā)現(xiàn)人與人,知識(shí)與知識(shí),人與知識(shí)等的相互關(guān)系[3]。
2.3 移動(dòng)圖書(shū)館平臺(tái)中的知識(shí)挖掘?qū)W(xué)校的作用
超星可視化圖譜是一個(gè)強(qiáng)大的知識(shí)挖掘工具,集知識(shí)挖掘、知識(shí)關(guān)聯(lián)分析與可視化技術(shù)于一體,能夠?qū)l(fā)現(xiàn)數(shù)據(jù)及分析結(jié)果以表格、圖形等方式直觀(guān)展示出來(lái)。如果我們學(xué)校想和兄弟院校做一些學(xué)術(shù)研究對(duì)比,自己學(xué)校科研成果發(fā)布等等,都可以直觀(guān)的表現(xiàn)在我們的學(xué)術(shù)發(fā)展趨勢(shì)圖里。比如說(shuō)我不知道我們學(xué)校具體哪個(gè)專(zhuān)業(yè)強(qiáng),但通過(guò)這個(gè)餅狀圖就可直觀(guān)的看到,最強(qiáng)專(zhuān)業(yè)肯定是偏文化、科學(xué)中的。再如我們學(xué)校中各個(gè)老師發(fā)表作品的數(shù)量都一目了然。
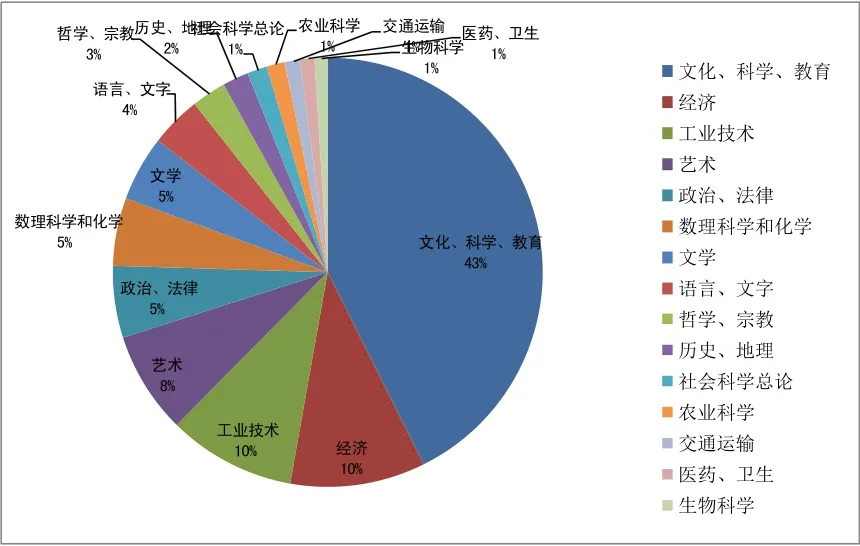
圖5 泰州職業(yè)技術(shù)學(xué)院教師發(fā)表作品類(lèi)目分類(lèi)表
3 風(fēng)險(xiǎn)控制
3.1 網(wǎng)站安全是移動(dòng)圖書(shū)館平臺(tái)知識(shí)挖掘結(jié)果準(zhǔn)確的前提
移動(dòng)圖書(shū)館平臺(tái)的知識(shí)挖掘是基于圖書(shū)館網(wǎng)站本身的數(shù)據(jù),若網(wǎng)站防衛(wèi)漏洞過(guò)多,經(jīng)常遭受入侵和篡改數(shù)據(jù),那么該網(wǎng)站數(shù)據(jù)顯然不能作為決策的依據(jù)的。圖書(shū)館網(wǎng)站經(jīng)常會(huì)遭受不知意圖的探訪(fǎng),這些探訪(fǎng)可能是善意的人為測(cè)試,也可能是惡意攻擊、網(wǎng)上爬蟲(chóng)等,這些事情都會(huì)影響網(wǎng)站數(shù)據(jù)的真實(shí)性。一方面,我們要加大防范力度,及時(shí)查漏補(bǔ)缺;另一方面,我們數(shù)據(jù)驅(qū)動(dòng)決策不能簡(jiǎn)單依靠網(wǎng)站流量數(shù)據(jù)來(lái)決策,對(duì)反映訪(fǎng)問(wèn)用戶(hù)行為的指標(biāo)也應(yīng)加大重視力度,如獨(dú)立訪(fǎng)問(wèn)者統(tǒng)計(jì)、頁(yè)面停留時(shí)間、訪(fǎng)問(wèn)時(shí)長(zhǎng)、訪(fǎng)問(wèn)頻率、訪(fǎng)問(wèn)深度、用戶(hù)產(chǎn)生的閱讀行為和使用資源、用戶(hù)的忠誠(chéng)度等都是重要的數(shù)據(jù)分析指標(biāo)[4]。
3.2 嚴(yán)格把控知識(shí)挖掘的各個(gè)環(huán)節(jié)是數(shù)據(jù)分析結(jié)果準(zhǔn)確的保證
在數(shù)據(jù)產(chǎn)生收集到最終分析挖掘得出結(jié)果決策,各個(gè)環(huán)節(jié)都要專(zhuān)人負(fù)責(zé),認(rèn)真比對(duì),對(duì)影響后續(xù)環(huán)節(jié)的數(shù)據(jù)要多次驗(yàn)證,盡量將過(guò)程中出錯(cuò)率降到最低,為保證最終結(jié)果真實(shí)有效,必須嚴(yán)格把控所有環(huán)節(jié),以科學(xué)嚴(yán)謹(jǐn)公正客觀(guān)的態(tài)度來(lái)做知識(shí)挖掘,才能最終對(duì)決策有利,從而實(shí)現(xiàn)數(shù)據(jù)驅(qū)動(dòng)決策的目標(biāo)。
3.3 多渠道反復(fù)驗(yàn)證結(jié)果數(shù)據(jù)減少單一數(shù)據(jù)知識(shí)挖掘結(jié)果的風(fēng)險(xiǎn)
對(duì)于訪(fǎng)問(wèn)數(shù)據(jù)尤其是涉及驅(qū)動(dòng)決策的關(guān)鍵數(shù)據(jù),必須多渠道反復(fù)驗(yàn)證,從而保證數(shù)據(jù)的精準(zhǔn)性,如問(wèn)卷調(diào)查、在線(xiàn)反饋、實(shí)時(shí)互動(dòng)等,這些第一手?jǐn)?shù)據(jù)與通過(guò)數(shù)據(jù)挖掘分析處理的結(jié)果相互驗(yàn)證,保證最終結(jié)果更準(zhǔn)確,最終充分保障決策的科學(xué)性。
3.4 知識(shí)挖掘由以網(wǎng)站為中心向以用戶(hù)為中心轉(zhuǎn)化
一般的數(shù)據(jù)分析,只是對(duì)網(wǎng)站日常訪(fǎng)問(wèn)數(shù)據(jù)進(jìn)行分析處理,即憑借用戶(hù)訪(fǎng)問(wèn)形成LOG 數(shù)據(jù)分析,而LOG 文件只能對(duì)一些網(wǎng)站運(yùn)行和用戶(hù)訪(fǎng)問(wèn)做一個(gè)簡(jiǎn)單的統(tǒng)計(jì),這種統(tǒng)計(jì)數(shù)據(jù)對(duì)用戶(hù)行為缺少深度洞察和了解,局限性很大,單純依靠這些數(shù)據(jù)顯然不足以反映用戶(hù)需求和移動(dòng)圖書(shū)館運(yùn)行的真實(shí)狀態(tài),因此要加強(qiáng)對(duì)用戶(hù)行為收集并最終形成以用戶(hù)為中心的數(shù)據(jù)流。當(dāng)然,對(duì)用戶(hù)訪(fǎng)問(wèn)數(shù)據(jù)的挖掘,不能侵犯和擴(kuò)散用戶(hù)個(gè)人隱私,這些方面都要加強(qiáng)立法和規(guī)章制度進(jìn)行管理,保障用戶(hù)個(gè)人權(quán)利不受損害。
猜你喜歡
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
傳媒評(píng)論(2019年4期)2019-07-13 05:49:14
小太陽(yáng)畫(huà)報(bào)(2018年1期)2018-05-14 17:19:25
少年博覽·小學(xué)低年級(jí)(2016年10期)2016-11-24 06:48:23
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
漫畫(huà)月刊·炫版(2015年4期)2015-05-27 07:52:10
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
