基于機器視覺的OCR自動識別系統的研發
2019-08-31 13:05:26沈臻韓震宇
科技與創新 2019年8期
沈臻 韓震宇


摘要:研發了一種基于機器視覺的OCR識別技術,以滿足某半導體芯片公司的批量生產的需求,極大地提高了其生產線的自動化、無人化程度。使用工業相機對芯片料盒的字符部分進行采圖,得到了原始圖像后,對圖像進行二值化、圖像分辨率更改以適應顯示器、膨脹腐蝕等操作。預處理完成后,利用已訓練完成的yml格式的文件進行字符的識別,并對識別結果進行控制。在現場使用后表明,該OCR識別技術具有很高的響應速度和可靠性,綜合檢測成功率高達gg%.
關鍵詞:機器視覺;OCR;圖像二值化;機器學習
中圖分類號:TP391.41
文獻標識碼:A
DOI:10.15913/j .cnki.kj ycx.2019.08.063
1 前言
1.1 背景
OCR(光學字符識別)技術的概念是在1929年由德國科學家Tausheck首次提出的,20世紀六七十年代,世界各國開始有OCR技術的研究,研究初期,多以文字識別方法為主[1]。隨著我國改革開放后生產力的快速發展,計算機已成為必不可少的物品,OCR技術也逐漸發展到了實際應用階段。一個OCR系統的好壞由以下幾個指標組成,包括字符識別的準確率、識別的速度、識別的穩定性和上手難度等,其中字符識別的準確率是最重要的指標。目前,OCR技術得到了極大的發展,國內外都有一些比較成熟的商用OCR識別軟件,比如abbyy、漢王等。此系統并沒有采用Google的Tesseract開源OCR引擎,而是獨自制作了標簽與樣本,主要考慮的是此系統需要識別的字符比較簡單和單一,不需要Tesseract也能滿足系統需求。
1.2 設計需求
某半導體芯片公司為了提高生產線的自動化程度和減少操作員的人數,需要一套識別芯片料盒的OCR系統。芯片料盒上通過激光打標標注出此次需要加工的芯片批號的索引碼,此索引碼和芯片批號是一一對應的。生產線分為上料位和下料位;在使用此OCR識別系統之前,在上料位,操作員通過文字記錄下芯片料盒的索引碼,再去數據庫中尋找此索引碼對應的芯片批號;在下料位,操作員與數據庫交互,此批次加工完成。原先的工作方式工作效率低下、繁雜,且因為操作員長時間工作的原因,錯誤頻發,很有必要研發一項OCR自動識別的技術,以適應公司的自動化發展要求。
此系統在上料位通過工業相機獲取芯片料盒上的索引碼,直接傳遞給數據庫,從數據庫中得到此批次芯片的批號。在下料位,同樣進行一次字符識別,以保證上、下工位之間加工的是一個批次的芯片;同時將此批次的索引碼和批號解除綁定。
2 系統設計
2.1 系統的硬件選擇
本系統采用大華華睿的12MG-E工業相機,此相機體積較小,長時間的工作對其性能的影響很小,大華公司提供的SDK開發包也便于二次開發。工業鏡頭為MH1220M,工作距離為250 mm;因為涉及到對兩個相機的控制,采用了一塊intel的LREC9224PT的雙路網卡,以滿足相機的高速傳輸需求。光源采用的是JA-RL180-A30-W的環形LED光源,顏色采用為紅色。
2.2 系統軟件的整體設計
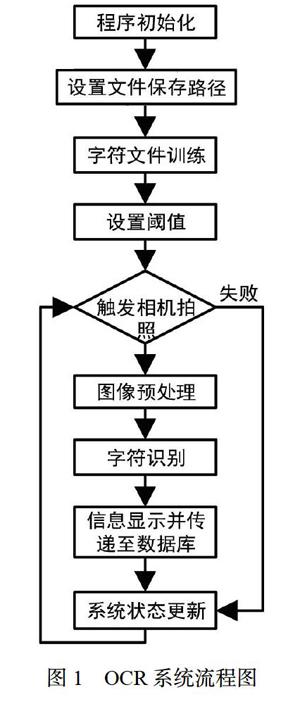
此系統加裝在原芯片加工的機器平臺之上,相機的外觸發源為控制芯片加工平臺的PLC,當運送芯片料盒的機構到達指定位置時,PLC就給相機一個觸發信號,告知相機應該在此處進行采圖;采圖完成后,芯片繼續移動到下一工位進行加工,而系統根據采集的圖像進行識別,將識別到的信息以文字形式顯示在系統屏幕上;同時顯示的還有根據此信息尋找到的產品批次碼,批次碼和索引碼一一對應。系統的開發平臺為Visual studi02010,加以運用openCV2.4.10,流程圖如圖1所示。
2.3 影像預處理
據統計,成像的質量至少對整個機器視覺有70%的影響。而影像預處理是把采集而來的圖像進行一系列的圖像操作以服務于后續的程序,同時預處理也是OCR識別的必需步驟。預處理的質量對識別準確率起著舉足輕重的作用。可以說,整個系統的成敗就在于成像和預處理的優劣。
系統的原圖像背景為黑色,字符為白色,字體為黑體,這給我們識別處理帶來了一些便利。現場的傳送芯片料盒的裝置具有較高的穩定性,可以把料盒每次推送到相對固定的位置,但是出于OCR識別的可靠性考慮,將ROI(感興趣的區域)設置得稍大,以保證每次料盒的字符區域都處于ROI范圍內。原圖的ROI區域如圖2所示。
圖像處理對采圖的環境非常敏感,環境的變動會對圖像的質量帶來不可估量的影響,比如光源亮度的變動,高亮度和低亮度采集的圖可能是兩幅質量完全不相同的圖。基于此,進行濾波操作也就顯得相當有必要。均值濾波是一種使用很頻繁的濾波函數,它可以消除圖像中的噪聲,以便凸顯出需要的部分,剔除無用的部分。均值濾波的輸出圖像的每一個像素是核窗口內輸入圖像對應像素的平均值[2]。濾波后的圖像如圖3所示。
濾波后需要將字符與背景分割開來,因為在此應用中字符的白色和背景的黑色有很大的差異性,所以使用閾值分割。如圖4所示,分割后的字符已經非常清楚,為后續圖像的處理帶來了便利。觀察此時的閾值分割圖可以發現,由于光照的不均勻性和表面材質的不平整,會有一些孤立點的存在影響字符的識別,使用形態學的操作可以解決這一問題。開運算是一典型的形態學操作,簡單來說就是先腐蝕再膨脹,可以去除掉不明顯的“小白斑”。模板的選取上采用3×3的模板,防止過度腐蝕,進而影響圖像質量。如圖5所示,經過開運算后的圖4中的“白斑”已經消除了。
此外,在一些極端情況下,簡單的開運算并不能將所有的“白斑”全部消除,究其原因,是沒有腐蝕掉這些缺陷,經過膨脹后反而明顯了。這時,將所有經過函數findC ontours()提取到的輪廓進行面積的計算,將面積小于一定值的白色區域進行擦除,而保留面積較大的部分,此時保留下來的區域可以保證是需要的字符。
2.4 機器學習在OCR中的運用
機器學習是一門研究計算機如何模擬和實現人類的學習行為的學科,它通過學習以獲得新的知識和見解,不間斷地學習可以使其趨于完美。機器學習的魅力無窮,在很多領域已經有了廣泛的應用,如自然語言處理、搜索引擎、數據挖掘、計算機視覺等等。本課題中,同樣采用機器學習來幫助OCR識別系統提高準備率和穩定性。在openCV中,提供了ml( machine leaming)模塊,借助這個模塊可以使用一組統計分類、回歸分析、數據聚類與統計模式函數。
本課題使用了Knearest類,在正式識別之前,需要將樣本和標簽輸入以供學習,并通過train()函數將兩者之間建立一一對應的聯系。樣本的選取與生產線實際使用的字體相同,均為黑體,然后將A-Z,0-9-共36個字符打印出來,用相機采集,盡量模擬出與生產線相同的環境。與正式識別一樣,識別樣本同樣需要進行一定的預處理,濾波、閾值化、輪廓提取等等,將提取到的輪廓(也就是一個字符)就作為樣本;此時,將所提取到的字符通過鍵盤響應輸入一個相同的鍵盤符。36個字符都響應完成,將樣本數據和標簽數據都寫進yml格式的文件,正式識別的時候就可以讀取這些文件從而進行識別。
為了提高識別的準確率,考慮到生產線需要識別的字符都是5個一組,且前兩個字符為英文大寫,后三個字符為數字,如圖2所示,因此,提取的時候分兩組提取;第一組總是被認為是英文大寫,第二組總是被認為是數字。識別的時候,先通過對輪廓的外接矩形的生成來分割單個字符;Knearest類生成兩個對象,分別對應于英文大寫字符和數字,它們的樣本中分別只有英文大寫和數字。每個對象都通過find_nearest ( )函數在樣本數據中尋找K近鄰來確定需要識別字符的類別,所尋得的結果即為當前字符。基于此,第一組識別到的字符只可能是英文大寫,第二組識別到的字符只可能是數字。通過這種辦法,巧妙地解決了相似字符識別的難題,如大寫英文的0和數字0,大寫英文的I和數字1的識別就比較困難。這個問題的解決對提高系統的準確性和可靠性具有很大意義,識別效果如圖6所示,其中上料盒信息即為芯片的索引碼。
3 結束語
研究了一種基于機器視覺的編帶機料盒的OCR識別系統。首先利用圖像處理技術將原圖進行預處理,然后進行圖像的分割;為了解決識別不準確的問題,依據現場的實際環境和使用情況,將字符人為地分成兩組,對每一組單獨進行識別。經過生產線的試用,綜合識別成功率高達99%,程序運行可靠穩定,極大地減少了操作員的工作負擔,推動著企業的自動化高速發展。
參考文獻:
[1]秦守鵬.基于OCR的CRTSⅢ型軌道板類型和編號自動識別技術研究[J].軌道勘察,2017,43 (6): 24-26.
[2]毛星云,冷雪飛.openCV3編程入門[M].北京:電子工業出版社.2015.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
電腦知識與技術(2016年28期)2016-12-21 12:13:14
科技視界(2016年26期)2016-12-17 17:31:58
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科教導刊(2016年25期)2016-11-15 17:53:37
軟件工程(2016年8期)2016-10-25 15:55:22
科學與財富(2016年28期)2016-10-14 21:19:17
科技視界(2016年20期)2016-09-29 11:11:40
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
