自然場景的識別及其理論模型*
2019-09-03 09:00:30
應(yīng)用心理學(xué) 2019年3期
(浙江大學(xué)心理與行為科學(xué)系,杭州 310028)
1 前 言
自然場景(nature scene)是指由空間分布合理的背景和離散的客體構(gòu)成的真實環(huán)境的連貫圖像(Henderson & Hollingworth,1999)。以往研究發(fā)現(xiàn),人類對場景圖片的信息提取和處理能力非常出色。我們既能夠?qū)焖俪尸F(xiàn)的自然場景圖片中的客體信息進(jìn)行辨認(rèn)和命名(Potter,1976;Thorpe,Fize,& Marlot,1996;LoBue & Deloache,2008),也能夠?qū)焖俪尸F(xiàn)的不同類別的自然場景圖片進(jìn)行分類(Torralbo et al.,2013),還能夠快速探測自然場景中的深度信息、場景功能等社會信息(Gajewski,Philbeck,Pothier,& Chichka,2010;Greene & Oliva,2009)。人類視覺系統(tǒng)如此高效快速的自然場景識別能力引起了相關(guān)領(lǐng)域研究學(xué)者們的廣泛興趣。
本文首先總結(jié)并詳細(xì)地闡述了人類視覺系統(tǒng)在處理自然場景時的主要特征,然后結(jié)合新近的認(rèn)知神經(jīng)科學(xué)研究,系統(tǒng)地介紹關(guān)于自然場景識別的特異性腦區(qū)及其簡要關(guān)系。在此基礎(chǔ)上,文章進(jìn)一步整理了以往研究者針對自然場景識別所提出的認(rèn)知模型和計算模型,論述各個模型對自然場景識別領(lǐng)域的貢獻(xiàn)和不足,以助于未來自然場景識別領(lǐng)域的相關(guān)研究。
2 自然場景識別的主要特征
2.1 自然場景識別的快速性
人們能夠從復(fù)雜的自然場景中準(zhǔn)確快速地提取場景的主題(gist)信息。
一方面,人類可以迅速準(zhǔn)確地從眾多干擾刺激中識別目標(biāo)刺激。早期研究發(fā)現(xiàn),當(dāng)場景圖像以每秒8張的速度進(jìn)行快速序列呈現(xiàn)(rapid serial visual presentation,RSVP)時,即使在序列開始呈現(xiàn)之前只給被試有關(guān)目標(biāo)場景主題的簡單文字描述,他們也能準(zhǔn)確地識別出目標(biāo)刺激(Potter,1975)。Potter等人(2014)將RSVP的實驗條件設(shè)置為每張場景圖像呈現(xiàn)13~80ms,連續(xù)呈現(xiàn)6或12張,然后要求被試判斷描述的目標(biāo)場景是否出現(xiàn)在呈現(xiàn)序列中。結(jié)果發(fā)現(xiàn),即使在呈現(xiàn)時間最短的13ms條件下,無論關(guān)于目標(biāo)場景的描述是出現(xiàn)在序列呈現(xiàn)之前還是全部呈現(xiàn)完成之后給出,被試對目標(biāo)檢測的準(zhǔn)確率都顯著高于隨機(jī)水平,說明即使刺激只呈現(xiàn)13ms,被試也能夠?qū)π蛄兄械乃写碳みM(jìn)行快速加工。
另一方面,人類能夠快速地提取自然場景中的有效信息,并做出正確選擇。Thorpe等人(1996)采用經(jīng)典的go/no-go動物分類范式,在場景圖像快速閃現(xiàn)20ms的條件下,讓被試判斷所呈現(xiàn)場景中是否包含動物,同時記錄被試的腦電活動。對有動物出現(xiàn)的場景,觀察者可能只需對動物出現(xiàn)的區(qū)域或動物的一些顯著特征進(jìn)行檢測,但對沒有動物出現(xiàn)的試次,觀察者必須加工整個場景之后才能做出正確的判斷。因此,相較于沒有動物出現(xiàn)的情況,沒有動物的目標(biāo)場景在150ms左右仍有劇烈的腦電活動,主要表現(xiàn)為額葉區(qū)域的負(fù)差異波(frontal negativity)。而Kirchner和Thorp(2006)則采用眼動追蹤的方法探究這一問題。他們要求被試完成掃視迫選任務(wù)(forced-choice saccade task),判斷并列呈現(xiàn)的兩個場景圖像中哪一個有動物出現(xiàn),眼動數(shù)據(jù)的結(jié)果顯示被試可以在刺激呈現(xiàn)后120ms內(nèi)做出正確的選擇。
除了人類,狒狒、恒河猴甚至是絨猴等靈長類也可以快速完成自然場景的分類任務(wù)(Roberts & Mazmanian,1988;Fabre-Thorpe,Richard,& and Thorpe,1998;Martin-Malivel & Fagot,2001;Minamimoto,Saunders,& and Richmond,2010)。在go/no-go動物分類任務(wù)條件下,猴子被試的準(zhǔn)確率雖然稍微低于人類被試,但反應(yīng)速度比人類更快。從生物進(jìn)化的角度來看,人類快速場景識別的能力可能是由于長期處理復(fù)雜多變的自然場景而慢慢演化來的。
2.2 自然場景識別的低耗能性
人類的注意資源是有限的(Chun,Golomb,& Turk-Browne,2011)。日常生活經(jīng)驗顯示,當(dāng)將注意資源集中在其它位置時,即使是場景中非常明顯的信息或變化,個體也會對其“視而不見”,而只有那些已經(jīng)達(dá)到自動化加工水平的信息才能在注意資源匱乏的條件下被注意到。Greene和Fei-Fei(2014)采用Stroop范式的變式,將文字呈現(xiàn)在場景圖片或物體圖片之上,文字所描述的含義可能與圖片內(nèi)容相同或相反,要求被試忽略背景圖片的內(nèi)容,判斷文字的含義所描述的是場景還是物體。結(jié)果發(fā)現(xiàn),當(dāng)圖片內(nèi)容與文字的含義類別不一致時,文字含義的分類任務(wù)受到干擾,從而推斷場景識別是自動化加工完成的。這也印證了之前的一些研究結(jié)果(Grill-Spector & Kanwisher,2005;Thorpe et al.,1996)。此外,F(xiàn)ei-Fei、VanRullen、Koch和Perona(2002)采用雙任務(wù)研究范式,要求被試在完成中央視覺的字符分類任務(wù)的同時,完成呈現(xiàn)在外周視覺的自然場景分類任務(wù)。實驗結(jié)果表明,自然場景圖像的快速視覺分類在雙任務(wù)條件下與單任務(wù)條件下相比并沒有顯著差異。因此,研究者推斷,完成場景識別的過程只需要很少甚至不需要中央視覺注意。然而,對于這一結(jié)果,Cohen、Alvarez和Nakayama(2011)認(rèn)為,在前述研究中,干擾任務(wù)(字符分類任務(wù))過于簡單,因此仍然有足夠的注意資源分配到場景識別任務(wù),因此后者的績效與單獨任務(wù)條件相似。他們結(jié)合多物體追蹤任務(wù)(multiple-object tracking,MOT)與RSVP范式,發(fā)現(xiàn)雙任務(wù)條件顯著影響了場景識別任務(wù)的績效,從而推斷快速場景識別過程仍然依賴于注意參與。為了進(jìn)一步探討這一問題,Sun等人(2017)也采用了雙任務(wù)范式,要求被試首先判斷左右呈現(xiàn)的一組詞匯是否為同一類別(詞匯判斷),然后判斷隨后出現(xiàn)在同一位置的一組圖片中哪張圖片中包含動物(快速場景識別)。結(jié)果發(fā)現(xiàn),相較于僅需要快速場景識別的情況(單任務(wù)),雙任務(wù)情況下被試對場景圖片的辨別力(d’)顯著降低,說明干擾任務(wù)對注意資源的占用還是會一定程度上影響場景識別。
總的來說,當(dāng)場景圖片刺激作為干擾刺激時,場景識別能夠自動化發(fā)生,從而影響實驗任務(wù)的績效。研究者通過雙任務(wù)范式進(jìn)一步發(fā)現(xiàn),當(dāng)高難度的干擾任務(wù)占用大量注意資源后,場景識別任務(wù)的績效也會受到影響,說明場景識別還是需要一定的注意資源的參與。
3 場景識別的特異性腦區(qū)及其神經(jīng)機(jī)制
為了進(jìn)一步理清人類的大腦是如何如此快速且低能耗地完成自然場景識別,相關(guān)領(lǐng)域的學(xué)者們展開了一系列認(rèn)知神經(jīng)科學(xué)研究,以此來了解場景識別的神經(jīng)基礎(chǔ)。研究發(fā)現(xiàn),人類大腦中與自然場景識別有關(guān)的特定腦區(qū)主要包括旁海馬位置區(qū)(parahippocampal place area,PPA)、枕葉位置區(qū)(occipital place area)和扣帶回的壓后皮層(retrosplenial complex,RSC)。fMRI研究顯示,位于旁海馬皮層(parahippocampal cortex,PHC)中的旁海馬位置區(qū)(PPA)是大腦皮層中對視覺場景信息反應(yīng)最強(qiáng)烈的區(qū)域(Epstein & Ward,2010),在場景識別過程中有著不可缺少的作用。這一區(qū)域的腦區(qū)受損,將會干擾病人對簡單場景的辨認(rèn)(Mendez & Cherrier,2003)。Dilks等人(2013)也發(fā)現(xiàn)枕葉位置區(qū)(occipital place area,OPA)也與場景識別有關(guān)(Dilks,Julian,Paunov,& Kanwisher,2013)。他們采用TMS技術(shù)分別干擾了被試右側(cè)OPA(rOPA)和負(fù)責(zé)面孔知覺的右側(cè)枕葉區(qū)(right occipital face area,rOFA),然后要求被試完成場景和面孔圖像的分類任務(wù)。結(jié)果發(fā)現(xiàn),對rOPA進(jìn)行干擾只會影響場景辨別任務(wù)而不會影響面孔識別任務(wù),說明rOPA僅與場景識別過程有關(guān)。
在場景識別過程中,特別是針對場景中主要客體的識別,對于兩張同時出現(xiàn)的物體圖片(如茶壺),我們能夠快速準(zhǔn)確地判斷它們是否為同一物體。即使兩張圖片是同一物體的鏡像圖像,我們也能輕松地判斷它們兩張圖片呈現(xiàn)的是同一物體。研究發(fā)現(xiàn),RSC和OPA兩個區(qū)域?qū)鼍皥D片的鏡像關(guān)系非常敏感,而PPA則對這樣的場景結(jié)構(gòu)信息并不敏感(Dilks,Julian,Kubilius,Spelke,& Kanwisher,2011)。而且,OPA對于場景信息中的客體信息加工還有更加獨特的作用。OPA主要負(fù)責(zé)某一客體是否存在,以及有多少客體出現(xiàn)在當(dāng)前場景中,而RSC和OPA則對場景圖片中的這些客體信息并不敏感,它們對整個場景的整體布局的敏感性更高(Kamps,Julian,Kubilius,Kanwisher,& Dilks,2016)
我們在現(xiàn)實生活中一直會利用周邊的環(huán)境信息提取有效的導(dǎo)航線索,從而指導(dǎo)自己的行動。研究表明,PPA、OPA以及RSC一起承擔(dān)了場景中導(dǎo)航信息的提取和加工(Epstein,2008;Marchette,Vass,Ryan,& Epstein,2014)。為了進(jìn)一步理清三個區(qū)域在導(dǎo)航信息加工過程中的相互關(guān)系,Persichetti和Dilks(2016)發(fā)現(xiàn)RSC和OPA能夠很好地幫助我們處理以自我為中心的距離信息(egocentric distance information)的處理,使得我們對其他物體之間的距離有一個較好的心理預(yù)估,而PPA則并不負(fù)責(zé)這方面的信息加工。PPA更多地與導(dǎo)航信息的動態(tài)處理有關(guān)系(Kamps,Lall,& Dilks,2016)。研究發(fā)現(xiàn),相較于一組隨機(jī)排列的場景信息圖片,一組按事件發(fā)生順序呈現(xiàn)的圖片會使得被試的PPA區(qū)域的活動更加強(qiáng)烈,說明PPA區(qū)域?qū)鼍靶畔⒌膶崟r加工有著重要作用。
4 自然場景識別的理論模型
為了更好地理解自然場景識別的機(jī)制,加深對自然場景識別的理解,本節(jié)分別從認(rèn)知模型與計算模型兩個層面總結(jié)了當(dāng)前場景識別的一些理論和模型。
4.1 自然場景識別的認(rèn)知模型:前饋模型與反饋模型
由于完成場景識別加工過程中所需的時間非常短,因此很多研究者認(rèn)為在對自然場景的快速加工時,人類的視覺系統(tǒng)依賴由刺激驅(qū)動的前饋加工(feed-forward processing)。為了進(jìn)一步理清自然場景識別過程中各階段的加工差異,國內(nèi)外學(xué)者針對自然場景識別的不同階段進(jìn)行了一系列研究(Wyatte,Jilk,& O’Reilly,2014)。
視覺場景信息需要經(jīng)過多層次神經(jīng)元的加工,每一階段都需要一定的時間(Serre,Oliva,& Poggio,2007)。生理學(xué)研究顯示,在場景識別的早期階段,視覺信號從刺激呈現(xiàn)并投射到視網(wǎng)膜開始,經(jīng)過40~60ms的時間到達(dá)初級視覺區(qū)域(V1區(qū))(DiCarlo,Zoccolan,& Rust,2012;Tapia & Beck,2014),再經(jīng)由腹側(cè)通路分別通過V2、V4區(qū),在刺激呈現(xiàn)后100ms左右的時間到達(dá)下顳葉皮層(inferior temporal cortex,IT)區(qū)域(如圖1中a~c所示)。研究表明,下顳葉皮質(zhì)能夠完成初步的特征整合(Serre,Oliva,& Poggio,2007)。上文提到的眼動研究顯示,在刺激呈現(xiàn)后120ms內(nèi),觀察者已經(jīng)可以完成對快速場景的分類(Kirchner & Thorpe,2006)。腦電研究結(jié)果也顯示,快速的場景識別與判斷最早可在刺激呈現(xiàn)后150ms內(nèi)完成(Thorpe,Fize,& Marlot,1996)。因此,很多研究者認(rèn)為,在這么短的時間內(nèi),自上而下的反饋信息應(yīng)該還未形成,即刺激呈現(xiàn)之后的最早一波進(jìn)入視覺系統(tǒng)的前饋(feedforward sweep)信息已經(jīng)足以完成對場景的快速識別(Fabre-Thorpe,2011;Romeo & Supèr,2014)。Serre、Oliva和Poggio(2007)據(jù)此提出前饋模型(feedforward architecture)來解釋快速場景識別,該模型認(rèn)為視覺信號通過腹側(cè)通路中自下而上的前饋過程已足以完成對場景的快速識別。
支持早期場景識別前饋模型的研究者認(rèn)為,在快速視覺分類任務(wù)中存在一個最小反應(yīng)時(minimal reaction time,MinRT),即個體剛好能做出正確反應(yīng)所需要的最短時間(Fabre-Thorpe,2011)。如果早期場景識別受到自上而下的經(jīng)驗和預(yù)期等因素的影響,那么通過學(xué)習(xí)和訓(xùn)練等操作來增加觀察者對場景刺激的熟悉度,應(yīng)該能夠縮短MinRT。而實驗結(jié)果顯示,MinRT在不同的刺激類型和不同任務(wù)條件下表現(xiàn)非常穩(wěn)定,即使被試經(jīng)過反復(fù)訓(xùn)練,對刺激材料非常熟悉的情況下,MinRT也沒顯著減小(Fabre-Thorpe,Delorme,Marlot,& Thorpe,2001)。因此,這一結(jié)果支持早期場景識別的前饋模型。
圖1 前饋與反饋過程中視覺信息傳遞的時間進(jìn)程(Wyatte,Jilk,& O’Reilly,2014)
場景識別的前饋模型也得到了來自神經(jīng)生理學(xué)、計算視覺與行為認(rèn)知實驗等許多研究的支持。相關(guān)研究認(rèn)為,注意和策略等反饋(feedback)信息是從較高級的前額葉(prefrontal cortex,PFC)區(qū)域自上而下地影響較低級視覺區(qū)域的加工過程的。但是,這一自上而下的信號最早需要在刺激呈現(xiàn)后150~170ms才能傳回早期視覺區(qū)域(如圖1中的f所示)。一些研究甚至認(rèn)為這一時間需要200~300ms(Wyatte,Jilk,& O’Reilly,2014)。因此,這些研究均表明,自上而下的反饋信息在傳遞回較低視覺區(qū)域之前,被試可能已經(jīng)完成了早期的場景識別過程,如場景的特征整合。
然而,除了從高級區(qū)域發(fā)起的反饋傳遞之外,Dehaene、Changeux、Naccache、Sackur和Sergent(2006)以及Lamme(2006)的研究均發(fā)現(xiàn),在腹側(cè)通路中存在一些局部范圍內(nèi)、距離較短的往復(fù)循環(huán)加工過程(local recurrent processing,如圖1中的d~e所示),這些局部反饋加工過程無論是在出現(xiàn)的時間還是在功能上,都與后期反饋信號不同(Wyatte et al.,2014)。雖然有許多研究認(rèn)為快速場景識別可能僅通過刺激驅(qū)動的前饋過程就足以完成,但是并不能完全排除局部反饋過程在早期場景識別中的作用。Camprodon、Zohary、Brodbeck和Pascual-Leone(2010)采用TMS技術(shù)在不同的時間點干擾枕葉部位(V1)的活動,同時要求被試完成視覺分類任務(wù),結(jié)果分別在100ms和220ms兩個時間點上對被試產(chǎn)生了顯著的影響,研究者當(dāng)時認(rèn)為100ms時干擾的是前饋加工過程,而220ms時干擾的是局部反饋過程。隨著對局部反饋過程研究的深入,以及結(jié)合以往研究者的成果(Corthout,Uttl,Walsh,Hallett,& Cowey,1999;Corthout,Uttl,Ziemann,Cowey,& Hallett,1999),Wyatte等人(2013)認(rèn)為,100ms左右剛好是IT加工完成的時間點,這時干擾的可能是自然場景分類的局部反饋過程,而220ms時的反饋干擾則來自于高級皮層。Koivisto、Railo、Revonsuo、Vanni和Salminen-Vaparanta(2011)采用fMRI與TMS相結(jié)合的方法,發(fā)現(xiàn)在較高層視覺區(qū)域被激活之后,V1/V2等較低級視覺區(qū)域的活動仍然會對場景分類產(chǎn)生影響,因此V1/V2在完成視覺信號的前饋傳遞之后,可能還承擔(dān)了接收反饋信號的功能。另外,在功能上,視覺初級皮層只能完成朝向、顏色等簡單特征的處理,而下顳葉皮質(zhì)能夠完成初步的特征整合(Serre,Oliva,& Poggio,2007)。
至于與后期反饋密切相關(guān)的前額葉皮質(zhì),則還會牽涉到更高級的記憶、經(jīng)驗、期望等自上而下的因素。人類的視覺預(yù)期分為兩類:結(jié)構(gòu)性預(yù)期(structural expectation)和上下文預(yù)期(contextual expectation)(Seriès & Seitz,2013)。結(jié)構(gòu)性預(yù)期主要反映個體長期處在真實自然場景中所積累下來的知識經(jīng)驗,或者是天生具備的某些傾向性的特質(zhì)。例如,當(dāng)觀察一幅場景圖片時,個體會默認(rèn)圖片中的光線是來自位于上方的光源(Kerrigan & Adams,2013)。上下文預(yù)期則反映空間或時間上相鄰近的環(huán)境信息使個體對其他刺激產(chǎn)生預(yù)期。經(jīng)驗與預(yù)期對知覺過程主要會影響影響知覺加工的績效和視覺刺激的主觀感知。在非最佳觀察條件下,如目標(biāo)刺激被遮擋(Wyatte,Curran,& O’Reilly,2012),或目標(biāo)與觀察者之間的距離太遠(yuǎn)(Serre et al.,2007),此時對目標(biāo)場景的快速知覺則需要借助于反饋信息。研究發(fā)現(xiàn),由詞匯傳遞的類別信息能夠提升個體對快速呈現(xiàn)的原始自然場景圖片的辨別(Stein & Peelen,2015,2017)。進(jìn)一步的研究發(fā)現(xiàn),即使目標(biāo)場景圖片的低空間頻率信息或者高空間頻率信息被刪除,這一啟動效應(yīng)依然存在(Sun,Zhang,& Wu,2017)。Greene、Botros、Beck和Fei-Fei(2015)讓被試主觀描述的方法,比較了對“不可能”場景(如一場水底的記者發(fā)布會)與正常場景之間主觀描述的差異。結(jié)果發(fā)現(xiàn),兩組圖片盡管從低水平的視覺特征上無法被區(qū)分,但“不可能”場景圖片更難被描述出來,也更難將其分類,同時在有噪音存在的條件下更難被覺察到。這些結(jié)果說明,人類快速知覺場景的能力存在一定的限制,早期知覺過程會受先前視覺經(jīng)驗的影響。除此之外,研究還發(fā)現(xiàn),自上而下的反饋信息會導(dǎo)致個體在場景識別過程中由于任務(wù)不同產(chǎn)生不同的知覺加工方式(Wu,Wick,& Pomplun,2014),而那些與任務(wù)無關(guān)的區(qū)域,即使擁有更多突顯的特征,也很少受到關(guān)注(Borji & Itti,2013)。
4.2 自然場景識別的計算模型
除了從認(rèn)知和生理學(xué)的角度探究場景識別的機(jī)制外,以往研究者也提出了許多計算模型(computational model),試圖解釋場景識別這一信息加工過程背后的算法(DiCarlo et al.,2012)。
場景識別的計算模型從應(yīng)用的角度大致可以分為兩類:一類用于輔助場景識別的認(rèn)知與生理學(xué)研究,擬合和驗證認(rèn)知模型或者生理學(xué)研究的結(jié)果,從而模擬人類大腦對場景識別的加工方式和過程;另一類主要是從計算視覺(computational vision)以及實際應(yīng)用的角度出發(fā),試圖用計算的方法理解自然場景,并最終讓場景識別的計算模型通過圖靈測試(Turing test for scene understanding)。場景識別的圖靈測試是指:針對一張描繪自然場景的圖片,人類測試者提出關(guān)于這一場景的若干問題,由機(jī)器(場景識別的計算模型)作出回答,如果測試者無法根據(jù)回答的內(nèi)容區(qū)分出回答者是機(jī)器還是人類,則認(rèn)為該機(jī)器通過圖靈測試(Xiao et al.,2013)。雖然研究者提出各種計算模型的出發(fā)點不同,但最終的目的都是為了更好地理解場景識別的原理及機(jī)制,而本文則主要闡述自然場景識別的計算模型是如何處理認(rèn)知模型中所涉及的自上而下和自下而上的信息加工過程。
與自然場景識別的早期認(rèn)知研究領(lǐng)域類似,研究者最初常根據(jù)底層的物理屬性和特征來描述視覺過程,并據(jù)此建立對視覺場景的表征,然后將其運(yùn)用到復(fù)雜的決策判斷(Marr,1982)。因此,一直以來很多研究者提出的計算模型,其本質(zhì)都是從場景圖像中提取有用的特征或?qū)傩?描述符,descriptors),然后據(jù)此構(gòu)建場景識別的計算模型(表征),后者經(jīng)過機(jī)器學(xué)習(xí)(machine learning)等訓(xùn)練,最終達(dá)到對陌生場景圖像識別和分類的目的。
Oliva與Torralba(2001)提出了空間包絡(luò)模型(spatial envelope),認(rèn)為場景圖像由五種感知屬性構(gòu)成:自然度(naturalness)、開放度(openness)、粗糙度(roughness)、擴(kuò)展度(expansion)與平整度(ruggedness)。他們通過對這些全局結(jié)構(gòu)屬性(global configuration)的提取與應(yīng)用,可在不識別場景局部特征及所包含物體的含義的條件下,直接完成對場景的識別。Fei-Fei和Perona(2005)借鑒了自然語言處理(natural language processing,NLP)中用于提取文檔主題的詞袋模型(bag-of-words model,BoW),提出了另外一種特征描述符。這種詞袋模型將自然場景圖像看作是“文檔(document)”,而將組成圖像的局部色塊(local patches)看作是文檔中的“詞匯(words)”。在進(jìn)行場景識別時,通過提取場景的“特征詞匯(feature words)”,就可以得出場景所描述的內(nèi)容或主題信息。Walther和Shen(2014)也試圖考察人類為何能高效地完成對自然場景的知覺加工,即究竟依賴于場景中的哪些特征信息?他們采用行為實驗與計算模型相結(jié)合的方法進(jìn)行研究,提出對自然場景的識別依賴于邊緣曲度(curvature)和非偶然結(jié)點(nonaccidental junction)等特征屬性。通過將計算模型與行為實驗的結(jié)果相對比,他們發(fā)現(xiàn),當(dāng)場景圖像中的這些屬性受到干擾時,人類被試的行為與計算模型表現(xiàn)出相似的錯誤模式(error pattern)。
然而這些模型主要反映場景信息的物理特征,并沒有對自然場景識別過程中一些自上而下的反饋信息進(jìn)行研究。因此,另一些研究者還從場景的語義(semantic)角度進(jìn)行考察,認(rèn)為場景的主題或類別信息是由組成場景的物體所決定的。例如,當(dāng)場景中同時出現(xiàn)桌子、椅子和黑板時,則該場景屬于教室場景的概率就很高。
場景識別的概率推斷模型其理論基礎(chǔ)可追溯到赫爾姆霍茲所提出視知覺的“無意識推斷(unconscious inference)”理論。后者認(rèn)為,視知覺過程是個體根據(jù)過往經(jīng)驗對視網(wǎng)膜傳來的信息進(jìn)行補(bǔ)充,從而做出無意識推斷的過程(Westheimer,2008)。許多數(shù)學(xué)心理學(xué)家和計算機(jī)科學(xué)家都支持這一觀點,認(rèn)為對復(fù)雜自然場景圖像的理解就是一個基于貝葉斯概率模型進(jìn)行概率推斷的過程(Purves,Monson,Sundararajan,& Wojtach,2014)。
根據(jù)貝葉斯理論,后驗概率(posterior probability,P(H|D))是在當(dāng)前視覺輸入數(shù)據(jù)為D的情況下對場景做出假設(shè)H的概率。后驗概率的大小是個體對場景做出決策的依據(jù)。
根據(jù)貝葉斯公式,后驗概率為:
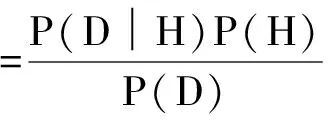
其中,P(D)是當(dāng)前場景圖像(視覺輸入數(shù)據(jù))出現(xiàn)的概率,通常為標(biāo)準(zhǔn)化常量;P(H)稱為先驗概率(prior probability),代表個體根據(jù)以往的知識經(jīng)驗對假設(shè)H出現(xiàn)可能性做出的估計;P(D|H)稱為相似度(likelihood),指假設(shè)H成立的條件下出現(xiàn)場景圖像D的概率。貝葉斯模型指出,個體對當(dāng)前場景的認(rèn)知是由以往知識經(jīng)驗和當(dāng)前場景信息共同決定的。
以往行為研究顯示,個體在自然場景中搜索物體時會盡量使用上下文信息,同時場景的語義內(nèi)容、場景中物體同時出現(xiàn)的統(tǒng)計規(guī)律以及任務(wù)限制等都會影響個體對自然場景識別和加工的方式。Torralba、Oliva、Castelhano和Henderson(2006)將場景整體特征(global features)與局部特征(local features)納入到同一個貝葉斯框架,并由此提出了背景引導(dǎo)模型(contextual guidance model),具體見圖2。
圖2 背景引導(dǎo)模型示意圖
該模型認(rèn)為,場景信息的加工存在兩條信息加工通道,分別加工局部特征和整體特征。其中,局部特征加工通道主要處理顏色和運(yùn)動方向等容易凸顯的視覺優(yōu)勢信息;整體特征加工通路主要提取場景的整體特征以激活已有的知識經(jīng)驗,并由此調(diào)節(jié)注意與視覺搜索的方向。該模型假設(shè),個體在搜索場景中的目標(biāo)時,會根據(jù)概率P(O,X│I)推斷目標(biāo)是否出現(xiàn)。其中,O=1表示有目標(biāo)出現(xiàn),O=0表示目標(biāo)刺激沒有出現(xiàn);X表示目標(biāo)刺激出現(xiàn)的位置;I代表場景特征,它由局部特征(L)和整體特征(G)所組成的。因此,目標(biāo)檢測的概率可通過P(O,X|L,G)進(jìn)行推導(dǎo)。
根據(jù)貝葉斯定律,可以將目標(biāo)檢測概率分解為:
Stansbury、Naselaris和Gallant(2013)認(rèn)為,在場景識別過程中,大腦所加工的是自然場景中所出現(xiàn)物體的統(tǒng)計概率,個體通過場景中同時出現(xiàn)物體的知識對自然場景進(jìn)行分類。例如,當(dāng)同時看到水、沙子和曬日光浴的游客時,個體會將其分類為“沙灘”,而這一類別標(biāo)簽又會激活對遮陽傘和沙灘城堡等物體的預(yù)期。Stansbury等人首先對場景材料中所有出現(xiàn)的物體進(jìn)行標(biāo)注和統(tǒng)計,把這些統(tǒng)計數(shù)據(jù)應(yīng)用到一個三層貝葉斯概率模型中(Blei,Ng,& Jordan,2003),并將所得到的不同類別的概率分布與fMRI所記錄的前部視覺區(qū)域(anterior visual cortex)的活動水平進(jìn)行擬合;然后,將這一過程反過來,根據(jù)fMRI記錄的活動水平推斷場景類別。結(jié)果發(fā)現(xiàn),大腦確實可以通過捕捉自然場景中物體同時出現(xiàn)的概率信息來對場景進(jìn)行表征。
5 總 結(jié)
本文基于以往的行為研究和認(rèn)知神經(jīng)科學(xué)研究,詳細(xì)闡述了自然場景識別的主要特征、神經(jīng)基礎(chǔ)及其認(rèn)知模型和計算模型。其中,認(rèn)知理論模型方面,本文詳細(xì)闡述了自下而上的前饋加工和自上而下的反饋加工兩種認(rèn)知加工方式在自然場景識別過程中的作用及其關(guān)系,而在計算模型方面,本文則著重闡述了計算模型如何處理人類自上而下和自下而上的信息加工過程,從而更好地與認(rèn)知模型相比較。然而,雖然目前自然場景識別領(lǐng)域的學(xué)者們達(dá)成了不少共識,但仍舊存在著很多不足和爭議的地方。
首先,由于自然場景所涵蓋的范圍非常廣,研究者所采用的范式也各不相同(王福興,田宏杰,申繼亮,2009),導(dǎo)致不同研究得到了不同甚至相反的結(jié)果。例如,F(xiàn)ei-Fei等人(2002)和Sun等人(2017)都是使用雙任務(wù)范式,但是在自然場景的快速視覺分類是否需注意參與的問題中出現(xiàn)了分歧。雖然兩者都是要求被試對出現(xiàn)在外周視野的自然場景圖片做出判斷(是否有動物),但是兩者的另一個任務(wù)(控制任務(wù))不同。一方面,控制任務(wù)的呈現(xiàn)方式不一樣,前者的任務(wù)刺激呈現(xiàn)在中央,而后者控制任務(wù)的刺激則出現(xiàn)在與場景圖片一樣的位置。另一方面,前者要求被試判斷中央呈現(xiàn)的五個字母是否相同,而后者則要求被試判斷出現(xiàn)在注視點左右的兩個詞匯是否為同一類別,兩者涉及的認(rèn)知加工程度、難度均不一樣。因此,在未來的研究中,我們要理清在當(dāng)前實驗條件下是否需要消耗注意資源,避免忽視由于不同實驗設(shè)計帶來的差異。
其次,未來的研究仍需要進(jìn)一步探究自然場景識別過程中自下而上的前饋信息加工方式與各種自上而下的反饋信息加工之間的關(guān)系。在場景識別早期,研究者嘗試用自上而下和自下而上兩種加工方式去解釋整個場景識別過程。但隨著研究的不斷深入,越來越多研究者意識到,場景識別過程包含了多個加工階段,而多個加工階段中還會包含多種加工方式。因此很難用單一的理論模型解釋場景識別的整個過程,而更應(yīng)該探究在不同加工階段中哪種加工方式占有主導(dǎo)地位(王福興,田宏杰,申繼亮,2009)。后續(xù)的研究應(yīng)對不同加工階段中主導(dǎo)的加工方式與視覺系統(tǒng)整體的加工過程加以兼顧,從而更好地理解場景識別過程中不同加工方式的交互關(guān)系。另一方面,如圖1中所展示的,按照視覺加工或神經(jīng)傳導(dǎo)的時間進(jìn)程,可將場景知覺分為早期場景識別和后期的調(diào)控(Wyatte et al.,2014),后者屬于由注意、經(jīng)驗以及策略等參與的自上而下加工。另一方面,從發(fā)展的角度來看,個體在日常生活中對自然場景進(jìn)行加工識別的過程同時也是一個不斷學(xué)習(xí)、不斷積累經(jīng)驗的過程。根據(jù)Seriès和Seitz(2013)對預(yù)期的分類,教育文化經(jīng)驗及個體長期積累起來對周圍世界的規(guī)則性經(jīng)驗,更多屬于與長時記憶有關(guān)的結(jié)構(gòu)性預(yù)期;即使早期的前饋加工過程也會在長期適應(yīng)和學(xué)習(xí)種不斷發(fā)展。在知覺與學(xué)習(xí)同時進(jìn)行的過程中,哪些經(jīng)驗知識會保留下來變成個體的結(jié)構(gòu)性預(yù)期,而哪些又被當(dāng)作無關(guān)信息遺忘掉;這種外顯或內(nèi)隱的知覺學(xué)習(xí)過程,是與自下而上反饋加工有關(guān),還是與前饋、反饋之間的交互作用有關(guān);這種調(diào)節(jié)作用是否影響知覺學(xué)習(xí)的進(jìn)程,等等。這些問題仍然需要進(jìn)一步深入探究。
最后,在本文的計算模型介紹中,雖然心理學(xué)家與計算機(jī)科學(xué)家提出了許多關(guān)于場景識別的計算模型,某些模型與算法在特定的任務(wù)場景中甚至可能達(dá)到比人類被試更高的準(zhǔn)確率(Walther & Shen,2014),但仍然沒有哪種計算模型能夠真正“理解”場景的含義。一方面,有些模型更多關(guān)注將場景描述符應(yīng)用到分類器中能否得到更高的分類準(zhǔn)確率,將其作為判斷模型或描述符好壞的重要指標(biāo)。但是,這類模型的問題往往在于,不夠重視或忽略場景識別中自上而下和自下而上兩種加工過程的生理機(jī)制,同時過度追求分類器的準(zhǔn)確率又容易產(chǎn)生過度擬合(over fit)的現(xiàn)象,導(dǎo)致生態(tài)效度太低,無法推廣到更大的圖片庫或復(fù)雜的現(xiàn)實環(huán)境中。另一方面,雖然貝葉斯概率推斷模型除了在自然場景識別領(lǐng)域之外,在聽覺(Elhilali,2013)、規(guī)則學(xué)習(xí)(Endress,2013)、語法學(xué)習(xí)(Perfors,Tenenbaum,& Regier,2011)、概念學(xué)習(xí)與分類(Goodman,Tenenbaum,Feldman,& Griffiths,2008)等許多領(lǐng)域都取得了顯著的成果,但是它仍然受到多方面的質(zhì)疑。例如,概率推斷模型認(rèn)為,個體最終做出的認(rèn)知決策反映了其對最大概率的理性(rational)或最優(yōu)(optimal)選擇,而對此目前仍然存在較多的質(zhì)疑(Marcus & Davis,2013)。另外,也有研究者提出,貝葉斯概率模型本身太過靈活,似乎可以解釋所有可能出現(xiàn)的不同實驗結(jié)果(Bowers & Davis,2012)。除此之外,人類除了能夠快速識別場景的主題內(nèi)容和類別信息之外,還可以快速理解場景中的人物關(guān)系與情緒狀態(tài),推斷場景中正在發(fā)生的事件,判斷場景中物體位置排列的合理性甚至做出審美判斷,甚至還能由場景觸發(fā)情緒和記憶等。對這些復(fù)雜的相互關(guān)聯(lián)信息的處理,對于當(dāng)前的計算模型來說,都還是遙不可及的。當(dāng)然,這些復(fù)雜功能的認(rèn)知及生理機(jī)制大多也都還沒有明確的定論,因此未來場景識別研究中無論是認(rèn)知與生理學(xué)研究還是計算視覺模型的發(fā)展,都應(yīng)該更多綜合考慮這些方面的因素,而不應(yīng)該僅僅關(guān)注自然場景視覺分類這一簡單的結(jié)果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻(xiàn)通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機(jī)設(shè)計與研究(2019年4期)2019-05-21 07:21:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
