一種基于目標優化學習的車標識別方法
2019-09-09 03:27:42朱文佳陳宇紅馮瑜瑾
圖學學報 2019年4期
關鍵詞:特征
朱文佳,陳宇紅,馮瑜瑾,王 俊,余 燁
一種基于目標優化學習的車標識別方法
朱文佳1,陳宇紅2,馮瑜瑾2,王 俊3,余 燁3
(1. 安徽百誠慧通科技有限公司,安徽 合肥 230009;2. 云南省公安廳交通警察總隊,云南 昆明 650224;3. 合肥工業大學計算機與信息學院,安徽 合肥 230009)
近年來,車標識別因其在智能交通系統中的重要作用,受到研究者的廣泛關注。傳統的車標識別算法多基于手工描述子,需要豐富的先驗知識,且難以適應復雜多變的現實應用場景。相比手工描述子,特征學習方法在解決復雜場景的計算機視覺問題時具有更優性能。因此,提出一種基于目標優化學習的車標識別方法,基于從原圖像中提取的像素梯度差矩陣,通過目標優化,自主學習特征參數。然后將像素梯度差矩陣映射為緊湊的二值矩陣,通過特征碼本的方式對特征信息進行編碼,生成魯棒的特征向量。基于公開車標數據集HFUT-VL1和XMU進行實驗,并與其他車標識別方法進行比較。實驗結果表明,與基于傳統特征描述子的方法相比,該算法識別率更高,與基于深度學習的方法相比,訓練和測試時間更少。
車標識別;目標優化;特征學習;碼本;像素梯度差矩陣
汽車保有量及駕駛人數量的快速增長給人類生活帶來諸多便利,同時也帶來了很多不容忽視的安全隱患,與車輛相關的交通事故、刑偵案件也越來越多。由于盜牌、無牌、污損車牌車輛的存在,使得基于車牌的相關識別方法[1-2]難以發揮應有的作用。而車標作為車輛制造商的標識,難以替換和偽裝,因此車標識別作為交通管理部門的重要工具和手段,在車輛查詢與跟蹤、道路管理、收費站自動收費等方面具有廣泛的應用價值。車標識別已成為智能交通系統領域的重要研究方向,受到越來越多研究者的關注。目前,車標識別的研究依然存在挑戰,如復雜應用場景、夜晚光線不足等情況下車標特征不明顯;實際應用中對車標的識別速度有較高要求,這些均增大了車標識別難度。
現有車標識別算法大多基于手工描述子,以LBP、HOG為代表的局部特征描述子在一些數據集上表現出良好的性能。文獻[3]提出HOG和SVM相結合的車標識別方案,實驗結果表明HOG特征對車標識別具有好良的性能。文獻[4]利用SIFT特征的旋轉、尺度不變性特征,以及反向傳播算法的特性,提出了一種車標識別方法,其對于光照變化具有一定的魯棒性。文獻[5]將多尺度與SIFT特征相結合,提取到更加密集的SIFT關鍵點,通過密集關鍵點匹配,進而顯著提高了算法的識別率。文獻[6]提出一種增強的SIFT描述子(M-SIFT)算法,解決了車標識別當中的尺度問題。為了解決車標識別任務中的車標圖像像素較低,難以提取到充足密集的特征信息或關鍵點問題,文獻[7]提出一種基于圖像明暗對比關系的點對特征;文獻[8]提出一種車標圖像前背景骨架區域隨機點對特征,該方法將車標圖像分割成前景和背景2個部分,并隨機生成點對進行匹配進而提取圖像的特征信息。
傳統手工描述子雖然在某些數據集上有很好的識別率,或者在解決特定的問題上具有優勢,但其仍存在很大的弊端。首先手工描述子需要豐富的先驗知識,其次手工描述子在解決復雜場景下的識別問題缺乏魯棒性。因此,越來越多的人通過特征學習的方法解決車標識別問題。特征學習方法能夠通過監督、半監督和非監督的方式學習特征參數,提取特征信息,能夠適用于不同場景下的車標識別任務。文獻[9]通過學習一組圖像濾波器和軟采樣矩陣來提取有效的人臉特征。文獻[10]給出一種緊湊二值化人臉描述子(compact binary face descriptor, CBFD)的學習方法。CBFD通過學習特征參數將像素梯度差映射成緊湊有效二值化向量。文獻[11]將核分析算法(kernel discriminant analysis, KDA)和稀疏表達分類器(sparse representation classifier, SRC)結合學習得到一個在人臉識別任務中性能魯棒的核描述子。近年來以卷積神經網絡(convoluted neural network, CNN)模型[12-13]為代表的深度學習方法在計算機視覺任務當中取得了巨大的成果,例如目標分類任務當中的VGG、Inception和ResNet系列方法,以及目標檢測任務當中的R-CNN、Yolo和SSD系列方法。但是深度學習方法需要巨大的算力和海量的訓練樣本,這些弊端從一定程度上限制了深度學習方法在實際場景的應用。
本文提出了一種新的基于目標優化學習的車標識別方法,其通過目標優化,自主學習樣本圖像數據,進而提取樣本圖像的特征信息,避免了手工描述子需要先驗知識的問題。此外,該方法需要擬合的特征參數少,僅需少量訓練樣本便能夠快速擬合,避免了CNN模型計算量大、訓練樣本大、時間長的缺點,可以應用于實時車標識別系統之中。
1 基于目標優化學習的車標識別算法
本文給出了一組有效的目標函數和優化方法,通過自主學習,獲取特征參數,提取特征向量,進行車標識別。
本文算法分為特征參數的學習和特征信息的提取2個部分。首先提取像素梯度差矩陣(pixel difference matrix, PDM),然后以為輸入數據,通過對目標函數的學習優化,獲取特征參數,以無監督學習的聚類算法生成特征碼本;然后,基于學習好的特征參數和特征碼本提取特征向量用于分類。分類算法采用經典的SVM來實現。整個算法流程如圖1所示。
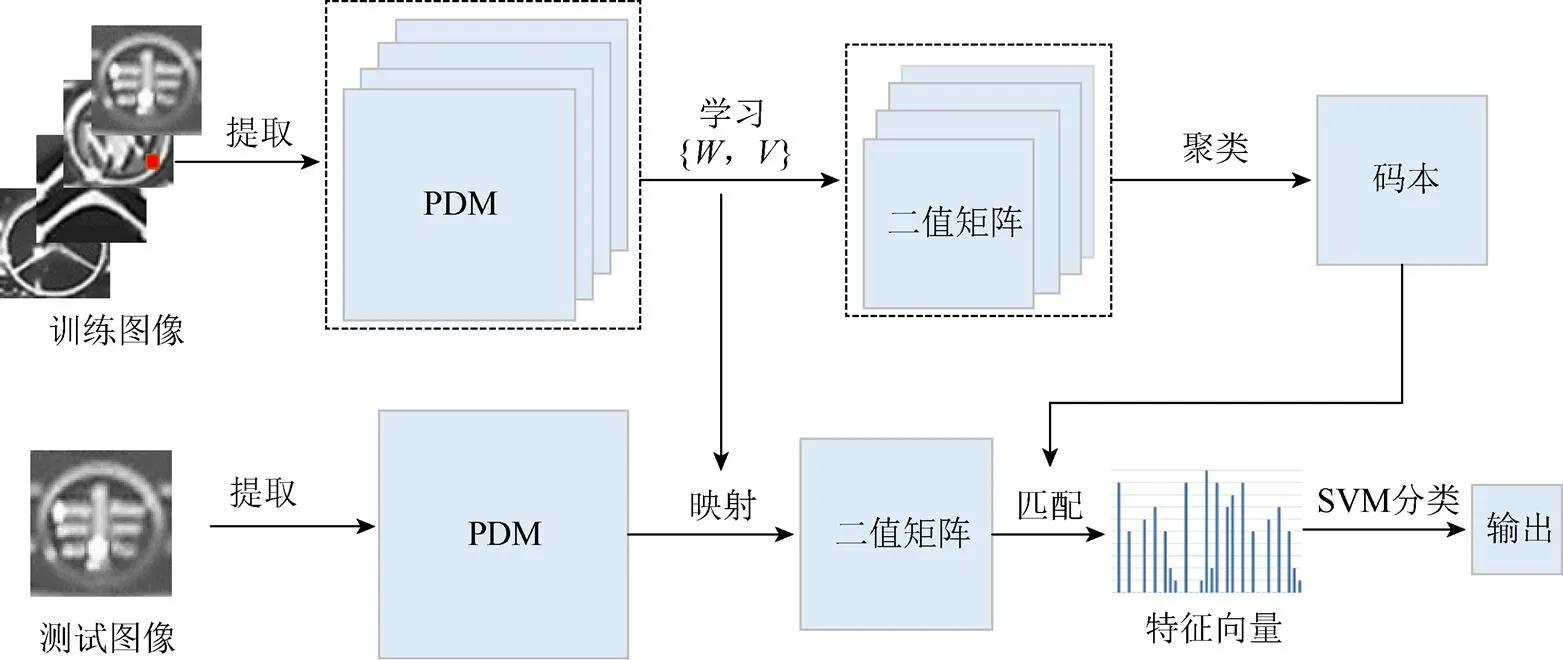
圖1 本文算法流程圖
1.1 像素梯度差矩陣(PDM)提取
與現有的大多數特征學習方法直接使用原像素值作為輸入數據不同,本文使用作為學習的輸入數據。相比原始像素值,能夠更好地反映圖像的梯度信息,對于車標識別而言,梯度信息尤為重要。
的提取過程如圖2所示。首先將完整的車標圖像分割成個區域塊,每一個區域塊對應一個;其次對區域塊當中的任意一像素點提取像素梯度差向量(pixel difference vector, PDV)。以該像素點為中心,定義一個半徑的鄰域區間,鄰域像素點為鄰域區間((2×+1)×(2×+1))內除之外的所有像素點。按照順時針方向,計算鄰域像素點與中心像素點的差值,該差值序列即為。為鄰域像素點與中心像素點的梯度差,包含了車標圖像的梯度信息。相較于原素值,使用有助于特征信息提取,加速特征參數的學習,文獻[9-10]也證明了其的有效性。最后將所有得到的連接生成。
因此,對于含有個像素點的區域塊提取到的可表示為:(1,2,···,, ···,)。
對于包含類,且每類有張的車標圖像訓練集中,在位置的區域塊則可以生成×個,記為=(11,12,···,1N,21,···,)。
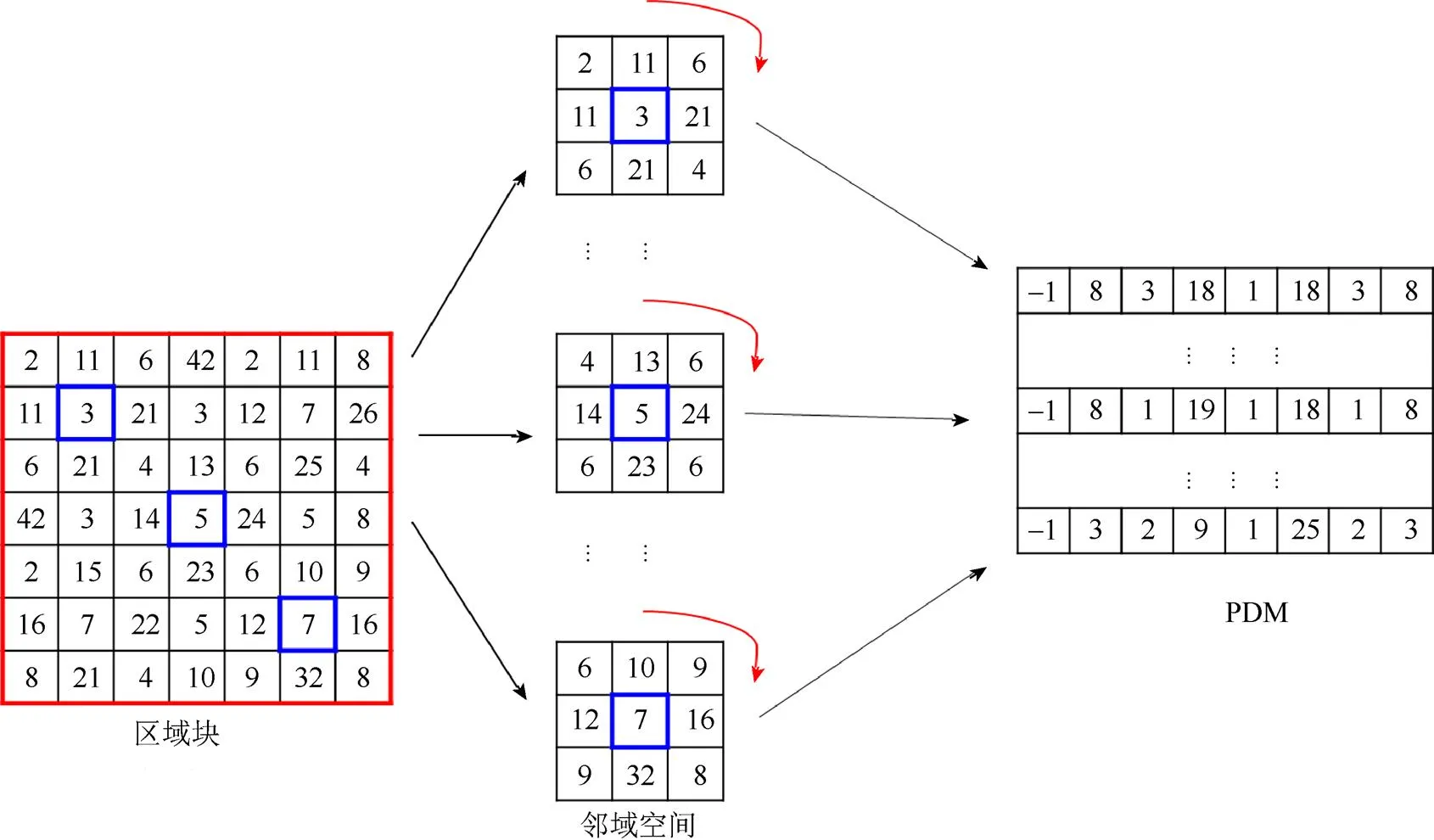
圖2 PDM提取過程示意圖
1.2 特征參數學習
特征參數的學習過程即為目標函數的優化過程,通過構建一個目標函數,并對其進行優化,進而學習特征參數。
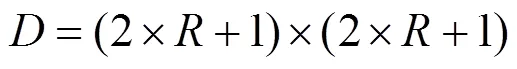
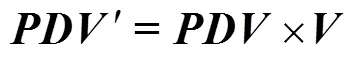
其中,為映射矩陣,在基于映射轉換之后,被映射為更緊湊和表達效果更好的,當將向量形式的拓展到矩陣形式的時,式(1)可以被重寫為
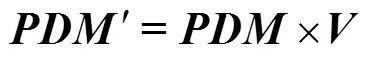
為了有效去除冗余信息,加強有用特征信息的目的,特給出一個約束條件:映射轉換之后,目標矩陣的類內散度最小化,類間散度最大化。這樣保證了同類車標圖像之間的特征信息距離更近,不同類車標圖像的特征信息距離更遠,進而有助于對車標圖像進行分類識別。為此,給出目標函數

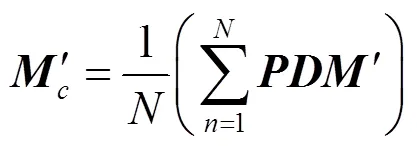

其中,1,2分別為類內散度和類間散度;為樣本的類別數;為每類樣本的數量;1,2分別為權重系數。
當使用式(2)進行替換時,式(3)~(5)可以重寫為
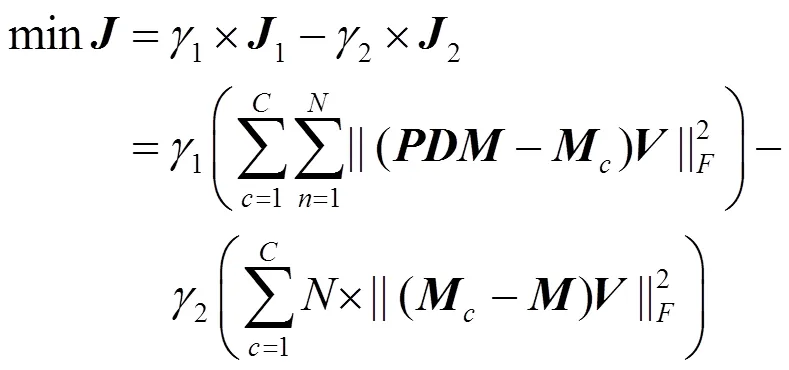
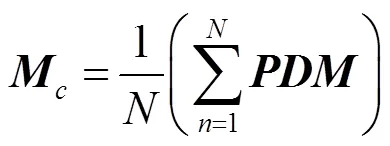
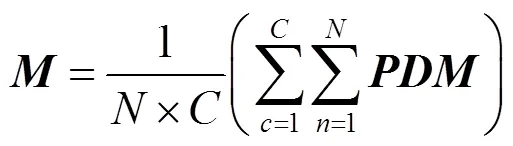
通過對目標函數式(6)的最優化,可以學習得到特征參數×d,基于特征參數,可以將×D映射轉換為更加緊湊有效的?×d。
對于包含個像素點的區域塊,通過鄰域空間可以生成相對應的個,并將其連接起來生成。在特征提取過程中,每個所起的作用是不同的,為了提取到更加有效的特征信息,需給各賦予不同的權重。加強有用的權重,減弱或消除無用的權重。傳統手工描述子中通常使用圖像濾波來達到此目的,如LGBP使用了Gabor濾波器,但是手工設計出一個廣泛且有效的圖像濾波器十分困難。因此,本文希望通過特征學習的方式,學習得到一個廣泛而有效的濾波器×p,將?×d映射為?×d即
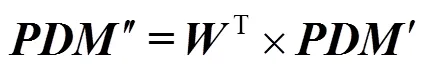
若將?使用式(2)進行替換時,式(9)可以寫為
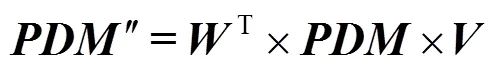
當對濾波器給出同樣的散度約束條件時,目標函數式(6)可以被改寫為
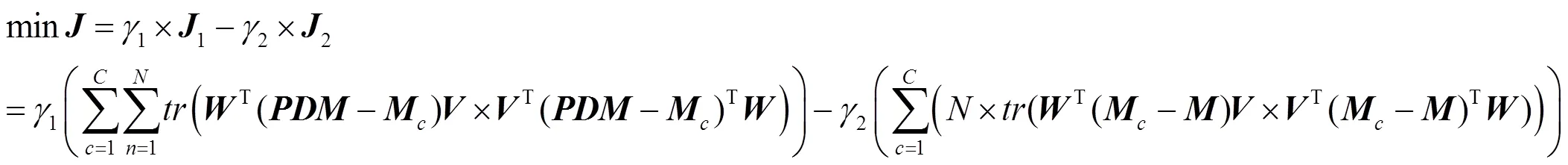
通過對式(11)的求解,可以學習得到一個特征參數對(),通過式(10),×D可以被映射為?×d(<,<)。到?不僅僅是維度被壓縮的過程,更是特征提取的過程。
對式(11)的優化求解,首先需分別計算關于和的偏導
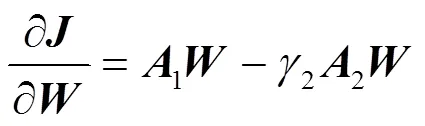
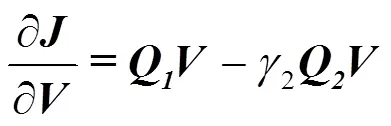
其中,
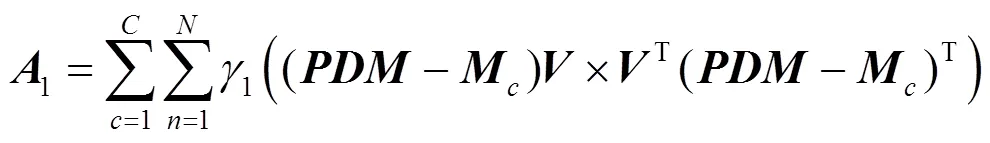
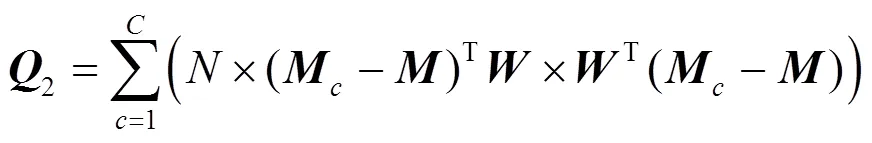
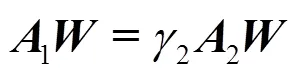
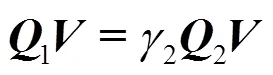


算法1. 輸入:訓練樣本集(PDM11,···,PDM1N,PDM21,···, PDMcn,···, PDMCN),其中,C為類別數目;N為每個類別包含的數目;PDMcn=RP×D 輸出:WRP×p和VRD×d 步驟1. (初始化)W=I,V=I,I為單位矩陣,基于式(11)計算J的值 步驟2.do: Jold=J 分別計算A1和A2,計算A2–1A1的前p個最大特征值對應的特征向量所組成的矩陣W0,令W=W0 分別計算Q1和Q2,計算Q2–1Q1的前d個最大特征值對應的特征向量所組成的矩陣V0,令V=V0 While (Jold>J),基于式(11)計算J的值 步驟3.返回W和V
通過算法1,可以學習得到特征參數(,),通過特征參數將映射成?,進而將冗余信息去除,加強有用的信息。
1.3 特征碼本生成與特征向量提取
為控制特征向量的維度,可采用聚類的方法生成特征碼本(codebook),然后通過與特征碼本的匹配生成特征向量。通過聚類方式生成特征碼本的方法,被廣泛地應用于LQP[14]、DFD[9]和CBFD[10]等特征學習算法之中,說明了該方法的有效性。
為降低聚類算法的計算和存儲負擔,提高算法的計算速度,可將學習得到的?使用式(16)進行二值化映射,得到二值化矩陣,即

以矩陣的每一行作為無監督訓練的輸入數據,通過聚類算法生成個聚類中心,保存生成特征碼本。
對于從測試圖像提取生成的二值化矩陣,以其每一行為單位與特征碼本進行最鄰近匹配,獲取特征碼,過程如圖3所示。對特征碼進行頻率統計,生成頻率直方圖。若測試圖像被分割成個區域塊,對應提取到個,進而對應生成個頻率直方圖 (1,2,···,h),將其連接則生成整張圖片的特征向量。

圖3 特征碼生成過程
2 實驗結果與分析
2.1 實驗數據集
采用本團隊自行構建的數據集HFUT-VL1[15],其包含16 000張采集于高速公路實時卡口系統的車標圖像。HFUT-VL1共包含80類車標,每類200張,圖像分辨率為64×64,如圖4所示。此外,還采用了廈門大學公開車標數據集XMU[13]對本文算法進行評估。XMU數據集包含10類車標圖像,每類1 150張,其中訓練集圖像1 000張,測試集圖像150張,圖像分辨率為70×70,如圖5所示。

圖4 HFUT-VL數據集樣例

圖5 XMU數據集樣例
2.2 參數評估
從1.2節可以看出,影響算法效果的主要因素在于的維度,參數矩陣和的維度。本文對上述參數,做了相關實驗以進行評估。
從圖6(a)可以發現,隨著鄰域半徑的增大,維度參數的值隨之增大,算法的識別率也逐漸提升。該結果說明,在一定范圍內,增大鄰域半徑可以提高識別效果,但也存在瓶頸。如圖6(a),當鄰域半徑增加到4和5時,對識別率的提高并不明顯,但是相比=3會使的維度增加,帶來更大的計算負擔,因此綜合考慮選擇=3。此外,當鄰域半徑一定,參數矩陣的維度參數存在一個峰值,當的大小為的3/4時,識別率達到最高。
從圖6(b)可以看出,隨著區域塊半徑的增大,區域塊當中的像素值增加,算法效果呈下降趨勢,綜合考慮選擇=3。當區域塊半徑一定,的大小為的3/4時,算法效果達到最好。
因此,當樣本圖像分辨率為64×64時,鄰域半徑與區域半徑分別設置為3時,識別率達到最高。此時,參數矩陣和的維度參數和分別為和的3/4大小。
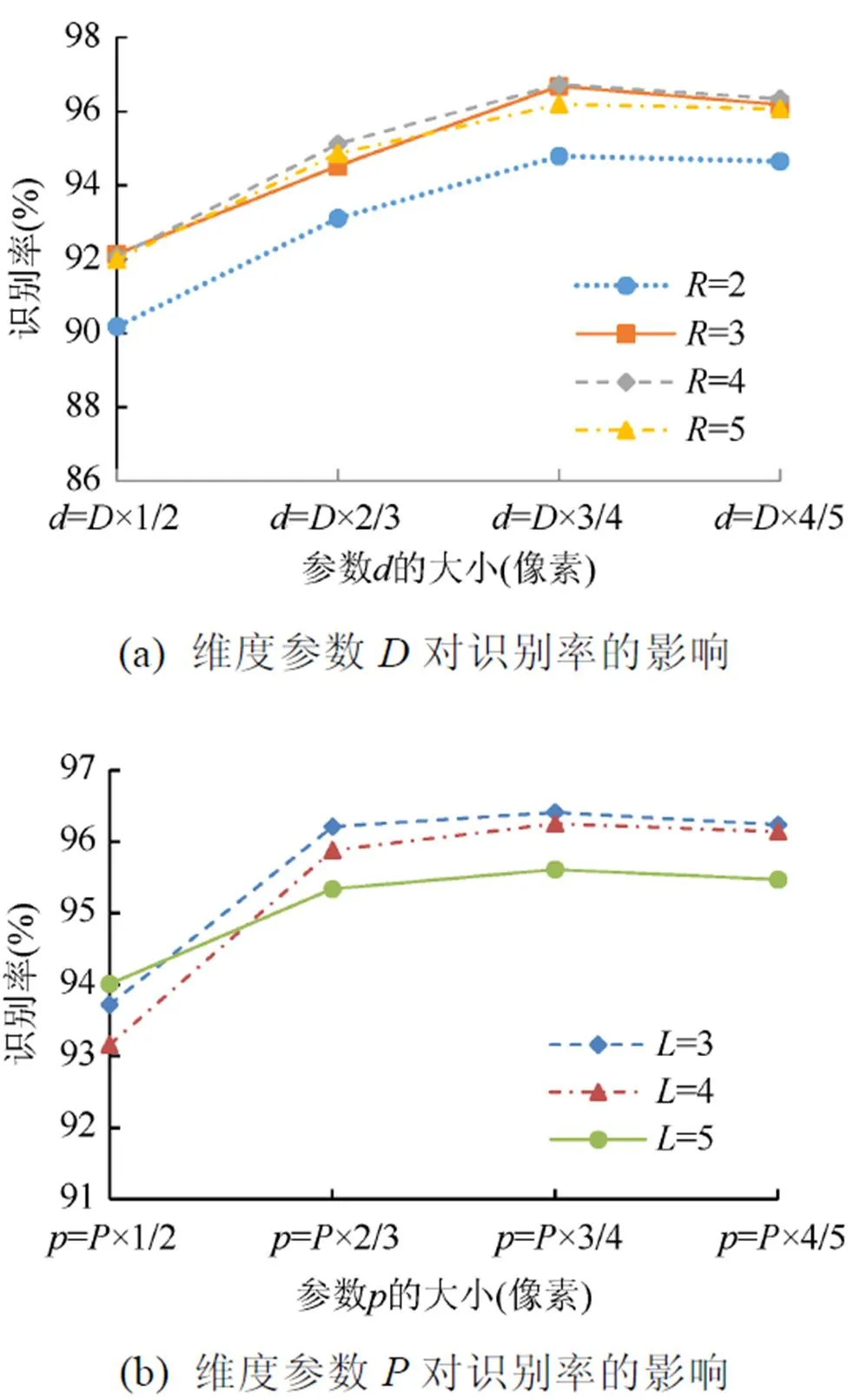
圖6 參數對識別率的影響
2.3 實驗結果比較
本文提出基于目標優化學習的車標識別方法的目標為:①在小樣本訓練時,能夠保持較好的性能;②相比其他特征學習算法時間復雜度更低,滿足車標識別任務的實時性。
為了驗證小樣本訓練的效果,本文基于HFUT-VL1數據集,從80類車標中每類提取5張,共400張圖像作為訓練集,其余15 600張作為測試集,對本文算法的效果進行評估,實驗結果見表1。手工描述子方法的優點在于小樣本訓練下性能優良,從表1可以看出,本文算法具有優異的識別效果,其識別率遠遠高于其他算法,表明本文算法適用于小樣本訓練情況下的車標識別任務。
近年來,CNN的相關算法在計算機視覺領域快速發展。本文也對經典的CNN分類算法進行了相關實驗,以便更加全面地評估本文算法的效果。實驗在HFUT-VL1數據集上進行,使用2個80類車標圖像,每類100張,總計8 000張車標圖像作為訓練集及測試集進行實驗。CNN算法直接調用了MXNet框架下的GluonCV庫當中的標準模型,并且都使用了GPU加速,實驗結果見表2。由表2可見,本文算法識別率達到了98.33%的效果,雖然略低于基于CNN的分類算法,但是本文算法的訓練時間和測試時間遠遠低于其他算法,訓練時間比CNN算法當中最快的MobileNet快了8.6倍,測試速度快了4.3倍,更加能夠適應于車標識別任務的實時性要求。
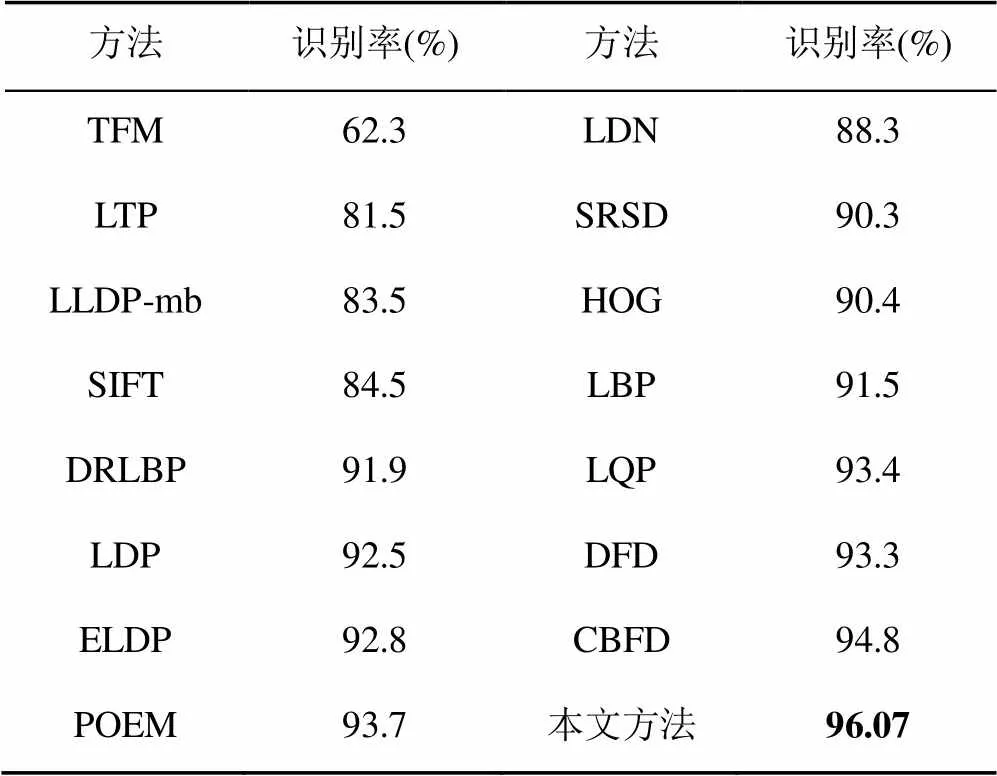
表1 本文算法與手工描述子算法識別效果對比*
(*:80類,訓練張數每類5張,測試張數為每類195張)

表2 本文算法與CNN算法性能比較*
(*:80類,訓練張數每類100張,測試張數每類100張)
此外,為進一步將本文算法與其他車標識別算法進行比較,還在車標公開數據集,即XMU數據集進行了相關實驗,該數據集近幾年被車標識別算法廣泛使用。XMU數據集有10類車標,每一類車標1 150張,其中1 000張作為訓練集,150張作為測試集,實驗結果見表3。表3中其他車標識別算法的識別率,如CNN-PT,CNN+ZCA等直接引用了原文給出的實驗結果。從表3中可以發現,與其他車標識別算法相比,本文算法表現出了優異的性能,其識別率達到了99.92%,遠遠超過了其他車標識別算法的識別率,其中包括了2019年最新的CNN+ZCA車標識別算法。
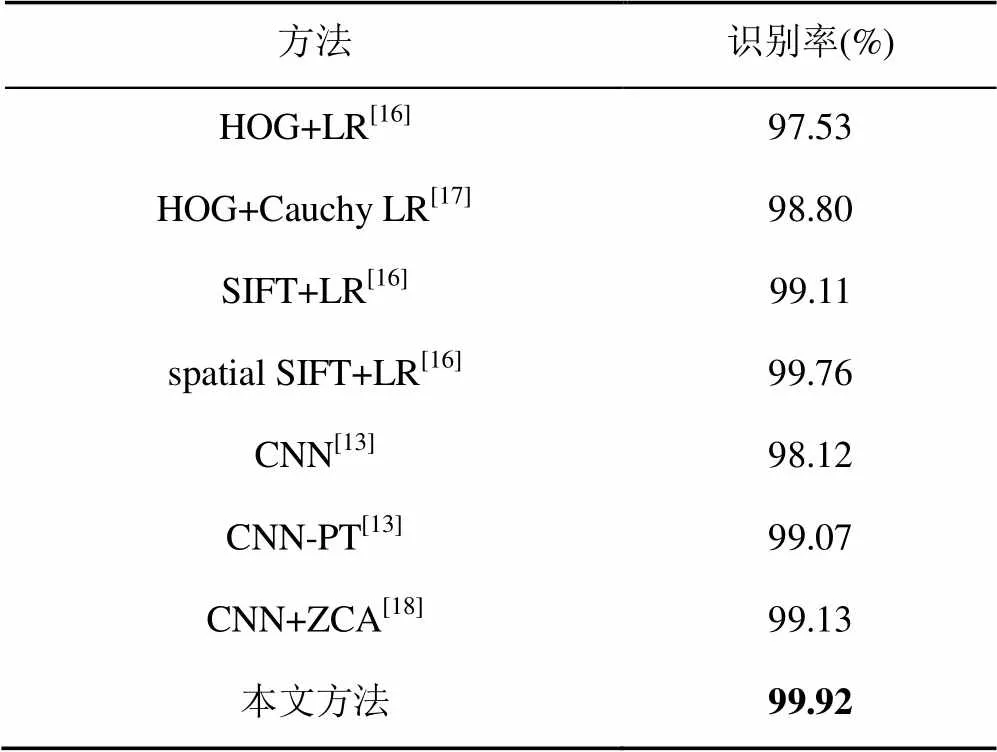
表3 本文算法與其他訓練模型的識別效果對比*
(*:10類,每類1 000張訓練,150張測試)
綜上,在HFUT-VL1和XMU2個數據集對本文方法進行了評估。在HFUT-VL1數據集中的小樣本訓練情況下,本文算法識別率達到了96.07%,超過同樣基于小樣本訓練的手工描述子,表明本文算法適用于小樣本訓練場景。此外,在HFUT-VL1數據集上進行大樣本訓練,本文算法雖然識別率不及CNN模型,但是訓練速度和測試速度遠超于CNN模型,更加適用于車標識別任務的實時性要求。在XMU數據集上,本文算法表現了優異效果,其99.92%的識別率遠超于其他車標識別算法在XMU數據集上的識別率。
3 結束語
本文提出了一種基于目標優化學習的車標識別方法,該方法首先對車標圖像提取作為輸入數據,然后通過目標函數的優化,學習得到一組特征參數,基于此參數生成特征矩陣,通過K-Means聚類生成特征碼本,提取特征向量,最后基于SVM分類器進行分類。實驗結果表明,本文提出的基于目標優化學習的方法可以提取到豐富全面的特征信息,獲得較好的識別效果。與基于傳統描述子的方法相比,本文算法的識別率獲得了很大的提升;與CNN分類算法相比,本文算法雖然識別率略低,但是算法的訓練速度與測試速度遠超于CNN相關分類算法,更加適用于車標識別任務。此外,與現存的車標識別相比,本文算法性能更好,識別率更高。因本文算法與CNN相關算法在識別率方面還是存在差距,未來將繼續深度研究,進一步提高本文算法的識別率,提高算法的性能。
[1] 謝永祥, 董蘭芳. 復雜背景下基于HSV空間和模板匹配的車牌識別方法研究[J]. 圖學學報, 2014, 35(4): 585-589.
[2] 王曉群, 劉宏志. 基于自適應數學形態學的車牌定位研究[J]. 圖學學報, 2017, 38(6): 843-850.
[3] LLORCA D F, ARROYO R, SOTELO M A. Vehicle logo recognition in traffic images using HOG features and SVM [C]//16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013). New York: IEEE Press, 2013: 2229-2234.
[4] LIPIKORN R, COOHAROJANANONE N, KIJSUPAPAISAN S, et al. Vehicle logo recognition based on interior structure using SIFT descriptor and neural network [C]//2014 International Conference on Information Science, Electronics and Electrical Engineering. New York: IEEE Press, 2014: 1595-1599.
[5] GU Q, YANG J Y, CUI G L, et al. Multi-scale vehicle logo recognition by directional dense SIFT flow parsing [C]//2016 IEEE International Conference on Image Processing. New York: IEEE Press, 2016: 3827-3831.
[6] PSYLLOS A, ANAGNOSTOPOULOS C N, KAYAFAS E. M-SIFT: A new method for vehicle logo recognition [C]//2012 IEEE International Conference on Vehicular Electronics and Safety. New York: IEEE Press, 2012: 261-266.
[7] PENG H Y, WANG X, WANG H Y, et al. Recognition of low-resolution logos in vehicle images based on statistical random sparse distribution [J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(2): 681-691.
[8] 余燁, 聶振興, 金強, 等. 前背景骨架區域隨機點對策略驅動下的車標識別方法[J]. 中國圖象圖形學報, 2016, 21(10): 1348-1356.
[9] LEI Z, PIETIKAINEN M, LI S Z. Learning discriminant face descriptor [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(2): 289-302.
[10] LU J W, LIONG V E, ZOU X Z, et al. Learning compact binary face descriptor for face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(10): 2041-2056.
[11] HUANG K K, DAI D Q, REN C X, et al. Learning kernel extended dictionary for face recognition [J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(5): 1082-1094.
[12] 王海瑤, 唐娟, 沈振輝. 基于深度卷積神經網絡的多任務細粒度車型識別[J]. 圖學學報, 2018, 39(3): 485-492.
[13] HUANG Y, WU R W, SUN Y, et al. Vehicle logo recognition system based on convolutional neural networks with a pretraining strategy [J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4): 1951-1960.
[14] UL HUSSAIN S, TRIGGS B. Visual recognition using local quantized patterns [M]//ComputerVision– ECCV2012. Heidelberg: Springer, 2012: 716-729.
[15] YU Y, Wang J, Lu J T, et al. Vehicle logo recognition based on overlapping enhanced patterns of oriented edge magnitudes [J]. Computers and Electrical Engineering, 2018, 71: 273-283.
[16] CHEN R, HAWES M, MIHAYLOVA L, et al. Vehicle logo recognition by spatial-sift combined with logistic regression [C]// 19th International Conference on Information Fusion (FUSION). New York: IEEE Press, 2016: 1228-1235.
[17] CHEN R, HAWES M, ISUPOVA O, et al. Online vehicle logo recognition using Cauchy prior logistic regression [C]//2017 20th International Conference on Information Fusion (Fusion). New York: IEEE Press, 2017: 1-8.
[18] SOON F C, KHAW H Y, CHUAH J H, et al. Vehicle logo recognition using whitening transformation and deep learning [J]. Signal, Image and Video Processing, 2019, 13(1): 111-119.
A Vehicle Logo Recognition Method Based on Objective Optimization
ZHU Wen-jia1, CHEN Yu-hong2, FENG Yu-jin2, WANG Jun3, YU Ye3
(1. Anhui BaiChengHuiTong Science and Technology Co. Ltd, Hefei Anhui 230009, China; 2. Traffic Police Headquarters of Yunnan Public Security Department, Kunming Yunnan 650224, China; 3. School of Computer and Information, Hefei University of Technology, Hefei Anhui 230009, China)
Vehicle logo recognition plays a more and more important role in intelligent transportation systems and has attracted extensive attention of researchers. Most traditional VLR methods are based on hand-crafted descriptors for which much heuristic knowledge is required, and thus are hard to adapt to complex and changeable realistic scenarios. Compared with hand-crafted descriptors, the feature learned methods perform betterin solving computer vision problems in complex environments. In the present study, a logo recognition method based on objective optimization learning is proposed to solve the VLR problem in this paper. First, feature parameters are automatically learned from pixel different matrix (PDM) extracted from raw images. Then, the PDMs are mapped into compact binary matrices with the learned feature parameters, and then the codebooks are learned from binary matrices with supervised learning. Finally, the feature vectors are extracted from test images with the learned feature parameters and codebooks. Experiments are carried out on open datasets HFUT-VL and XMU, and the results are analyzed and compared with other state-of-the-art methods. Experimental results show that our method can obtain higher recognition accuracy than hand-crafted descriptor based methods, and less training and testing time is required than deep learning based methods.
vehicle logo recognition; objective optimization; feature learning; codebook; pixel difference matrix
TP
10.11996/JG.j.2095-302X.2019040689
A
2095-302X(2019)04-0689-08
2019-02-28;
定稿日期:2019-05-10
安徽省重點研究和開發計劃項目(201904d07020010);安徽省自然科學基金項目(1708085MF158);合肥工業大學智能制造技術研究院科技成果轉化及產業化重點項目(IMICZ2017010)
朱文佳(1980-),男,安徽安慶人,工程師,碩士,技術總監。主要研究方向為智慧交通。E-mail:zwjnet@163.com
余 燁(1982-),女,安徽合肥人,副教授,博士,碩士生導師。主要研究方向為計算機視覺。E-mail:yuye@hfut.edu.cn
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
