大數據處理與挖掘在智能交通系統中的應用
2019-09-10 13:34:59劉勇良
河南科技 2019年4期
劉勇良
摘 要:當前,互聯網及通信技術的廣泛應用為智能交通系統提供了大量的實時數據,亟需對其進行管理、交換、譯制、匯聚和分析研判。互聯網及通信技術大大提高了智能交通系統的用戶友好度及有效性,提供了可觀的經濟和社會影響。在物聯網和云技術的大背景下,軟件架構的需求和智能交通系統新特性需要真實的應用場景來推導。本文主要闡述大數據處理與挖掘技術的應用對智能交通系統所產生的有利影響,并指出智能交通系統下大數據挖掘和處理領域新的工作方向。
關鍵詞:智能交通;云計算;數據挖掘;計算統計
中圖分類號:U495;TP311.13 文獻標識碼:A 文章編號:1003-5168(2019)04-0138-06
Big Data Processing and Mining Techmology which applied
in Modern Intelligent Transportation System
LIU Yongliang
(Henan Traffic and Communication Center, Zhengzhou Henan 450000)
Abstract: At present, the wide application of Internet and communication technology provides a large amount of real-time data for ITS, which needs to be managed, exchanged, translated, aggregated, analyzed and judged urgently. Internet and communication technology have greatly improved the user friendliness and effectiveness of ITS, and provided considerable economic and social impact. Under the background of Internet of Things and cloud technology, the requirement of software architecture and the new features of ITS need real application scenarios to derive. This paper mainly expounded the beneficial influence of the application of big data processing and mining technology on ITS, and pointed out the new direction of work in the field of big data mining and processing under ITS.
Keywords: intelligent transportation system;cloud computing;data mining;computational statistics
1 研究背景
近年來,日益增加的交通量和規律性的擁堵要求從基礎設施和交通管理方面提出解決方案。隨著交通系統的組件變得更加自主和智能(例如,車輛和基礎設施的新通信能力),對運輸管理和環境監測的智能運輸系統之間的合作的需求日益增加,以便改進交通管理策略。此外,智能交通管理系統方面的投資量日益增加。在新一代的商業管理系統中,交通系統的管理與運輸企業的商業戰略緊密結合,使得企業在業務規劃、服務質量和適應客戶需求等方面的影響力不段增強。
所有智能交通系統的參與者作為數據的來源,會在短時間內產生大量可利用的、更新頻繁的數據。數據的增長主要來自人們對社交媒體及網絡的使用,如車輛和交通系統中新型傳感器的使用,云計算和物聯網等現代信息和通信技術的應用等。隨著移動設備、航空感應技術(遙感)、照相機、麥克風、射頻識別讀取器和無線傳感器網絡等信息設備被越來越多地用于收集數據,數據集的規模越來越大。機器生成的和非結構化的數據如照片、視頻、社交媒體提要等的比例也在不斷增加。在該背景下,智能交通系統中出現了大數據問題。大數據通常包括數據集,其大小超出了常用軟件工具在可容忍的時間內捕獲、策劃、管理和處理數據的能力。大數據能提供相關客戶及其行為的詳細信息,但應以分散(多代理)方式進行適當分析,同時避免傳輸大量信息。而云和網格計算基礎架構非常適合存儲、管理和處理大數據。
從本質上講,大數據在物理和邏輯上是分散的,但實際上是集中的。所有信息源/存儲都是互連的,原則上,任何信息都可以由系統的任一組件訪問。大數據量通常在物理層上以分散的方式創建和管理。這會增加訪問信息時的信息成本。
為了在分散的信息處理決策和數據傳輸決策協調之間尋找有效的平衡點,運用大數據處理和挖掘技術并提出相應的應用決策是必須的。這就需要采用創新的大數據處理及挖掘技術,并開發相應的決策算法,以支持智能交通系統應用程序查找、收集、聚合、處理和分析最佳決策制定所需的信息以及有效的用戶行為策略[1]。
基于高度可擴展的分布式計算資源的云計算技術為大數據處理及挖掘提供了大容量存儲和快速計算的能力。但是,實施交通云并非易事。從用戶的觀點來看,數據和算法的復雜性隱藏在云中。用戶(交通管理機構、司乘人員)期望通過移動或嵌入式設備在互聯網上使用相對簡單的應用程序和界面。這些設備是連接的,并且(理論上)可以使用其他用戶和系統元件提供的所有信息。
本文將從以下五個方面進行探討:第一,分析以云為基礎的結構和智能交通系統的應用場景;第二,考慮用于實施相應數據挖掘與處理技術的架構和用于運輸操作的決策策略;第三,討論三種情況下合適的算法;第四,對基于計算統計的分散式協同大數據處理與挖掘方法進行討論,并在真實的交通數據中對其效率進行評估;第五,指出并討論未來在智能交通系統中的大數據挖掘與處理領域的工作方向。
2 現狀分析
2.1 需求與應用
目前,大數據已成為世界范圍內信息與通訊技術領域主要的科研課題。智能交通系統研究與發展也與大數據處理技術緊密相連,因此智能交通系統也是大數據挖掘與處理的重要領域之一。從應用方面來看,智能城市物流運營對智能交通系統來講是較為重要的,其對城市貨物運輸有很大的影響。
2.2 未來信息和通訊技術在智能交通系統中的應用
未來的信息和通訊技術可以滿足用戶需求,增強智能交通系統并為高性能計算提供大規模的基礎架構,這些基礎架構具有“彈性”性質[2]。
無線傳輸、移動互聯網、移動傳感器等現代移動和通訊技術為智能交通系統提供了良好的技術支持。目前,車輛大多都配備了具有強大通信和數據處理能力的移動設備、傳感器等,以期為司乘人員提供環境信息。快捷、高質量的3G或者4G移動互聯網連接時刻提供廉價方便的服務,這意味著大多數交通參與者已經實現實時的互聯互通。而如何利用這些連接為交通參與者提供可靠有效的需求服務是當前亟待解決的問題。
環境智能這個術語是建立在普適計算、泛在計算分析、情境感知及以人為中心的計算交互設計。在計算機領域,環境智能(Ambient Intelligence,AmI)是指對一個人有感應和反饋的電子環境。
2.3 智能交通系統結構
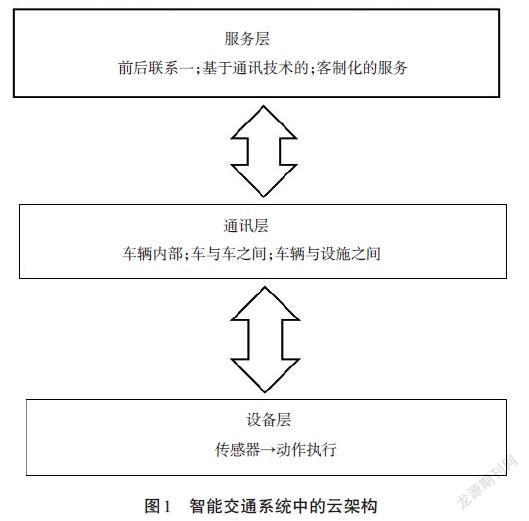
云計算是個經常被提及的問題,在智能交通系統中,主要從設備、通信和服務層的角度考慮云計算。在車輛駕駛員和外部車輛之的交互,同時考慮車輛到車輛(V2V)和車輛到基礎設施(V2I)的交互,以更有效的方式共享和利用外部資源。智能交通系統中的云架構如圖1所示。
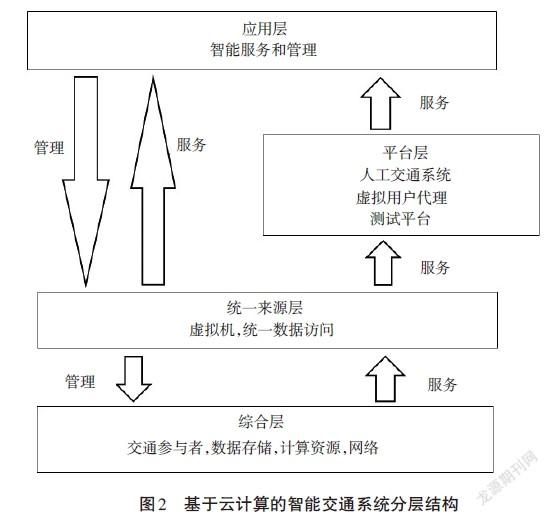
結構層包括云中可用的所有計算、存儲、數據和網絡資源。資源可通過資源服務訪問,用于云計算、管理和測試平臺。基于云計算的智能交通系統分層結構如圖2所示。
統一來源層通過使用虛擬機定義對結構層的原始計算資源的統一訪問來提供基礎架構即服務。
平臺層提供平臺即服務,包括在統一資源之上的專用工具、中間件和服務的集合,以創建部署平臺(例如,調度創建服務和人工測試床)。
應用程序層包含在云中運行的所有應用程序。云中的應用程序執行是分布式的:應用程序可以部分在客戶端上執行,部分在云中執行[3]。
3 智能交通系統中的大數據挖掘和處理技術
3.1 大數據挖掘和處理方法
經典的數據處理和挖掘方法是集中式的。為了應用這些技術,數據必須立即就地可用。但是,大數據不斷更新并收集在物理分布式存儲中,并且數據集中化是不可能的。
使用集中式的處理方法,系統無法實時快速地進行情景適配,并且通過網絡傳輸和存儲大數據,在統一位置管理和處理大數據將會非常困難或者不可能實現。因此,開發一種有效的、考慮數據時間和空間分布的分散式結構大數據挖掘及處理算法成為急需解決的問題。
現今,從技術和成本的角度來看,分析和處理大數據已經變得可行。很多大數據框架圍繞著商業交易、商業策略分析、識別價值且與結構的或非結構的數據息息相關。大數據處理和挖掘技術有助于將大數據以壓縮(集群)的方式進行存儲,并查找數據行為準則。接下來簡要介紹幾種主要的大數據挖掘及處理方法。
回歸分析是確定兩種或兩種以上變量間相互依賴的定量關系的一種統計分析方法。回歸分析按照涉及的變量的多少,分為一元回歸和多元回歸分析;按照自變量的多少,可分為簡單回歸分析和多重回歸分析;按照自變量和因變量之間的關系類型,可分為線性回歸分析和非線性回歸分析。如果在回歸分析中,只包括一個自變量和一個因變量,且二者的關系可用一條直線近似表示,這種回歸分析稱為一元線性回歸分析。如果回歸分析中包括兩個或兩個以上的自變量,且自變量之間存在線性相關,則稱為多重線性回歸分析。
時間序列預測分析就是利用過去一段時間內某事件時間的特征來預測未來一段時間內該事件的特征。時間序列數據具有自然的時間順序,這與典型的數據挖掘/機器學習應用程序不同,其中每個數據點是要學習的概念的獨立實現,并且數據集內的數據點的排序無關緊要。
聚類分析是一組用于對對象進行分類的統計方法,這些對象將不同的組分成較小的相似對象組,其相似性的特征事先是未知的。由于不使用訓練數據,這是一種無監督學習。
分類分析是基于包含其類別成員資格已知的觀察(或實例)的訓練數據集來識別新觀察所屬的一組類別(子群體)中的哪一個的問題。
3.2 云計算基礎設施和大數據挖掘及處理
云計算架構的特點是用戶與系統緊密集成,并根據物聯網創建虛擬代理。由于數據與每一個用戶緊密相連且數據在云上存儲,因此,云計算系統會將數據自動進行分配。虛擬用戶完全接入系統且對每一條數據都有訪問權限。
云系統的用戶通常具有有限的計算能力,因為其經常使用移動設備連接到云。因此,大數據的處理及挖掘部分在本地執行,部分由其他代理執行,其收集用戶信息并將信息存儲在云中。大數據挖掘及處理的主要問題是工作量和通訊費用。由于數據代理/中心的高連接性,云計算的實施處理了大量此類工作負載。
大數據挖掘與處理技術在云計算基礎架構中應用時仍保持分布狀態。然而,信息可用性的問題被信息成本問題所取代,信息成本問題將以下因素考慮在內,如信息位置、提取速度、質量、可靠性等。對云計算系統有大量的類似但不完全相同的需求用戶有很多。為此,應建立不同級別的數據處理以及預先計算的特征,然后有效地與實際用戶數據相結合。
在云環境中使用大數據挖掘及處理技術有以下優點:①在沒有物理集成的情況下將數據源虛擬集成到系統中;②促進基于成本的選擇性大數據挖掘及處理技術;③基于多目標大數據挖掘及處理技術的刺激;④支持多階段大數據挖掘與處理技術和不同級別的數據處理。
3.3 大數據挖掘及處理技術的未來發展趨勢:計算統計
云計算平臺有助于數據收集和為計算統計運作提供必要的資源。計算統計是統計學與計算機科學之間的接口,其是統計學數學科學特有的計算科學領域,旨在設計用于計算機實現統計方法的算法,包括在計算機時代之前不可想象的算法(例如,引導,模擬),以及應對分析上棘手的問題。計算統計假設通過使用不同組合的可用數據來應用迭代計算而不是復雜的分析模型。由此產生的問題的解決方案是近似的,然而,在許多實際情況下(大量可用信息,分析系統的復雜和層次結構及數據的依賴性),其可能會比經典方法提供更穩健和精確的結果,甚至可以在經典方法不可行的情況下工作。此外,計算統計應用很簡單,不需要復雜的分析或符號程序。
在大數據挖掘及處理方法中,廣泛應用計算統計方法,如重采樣、引導程序和內核密度,以便在分散式架構中進行回歸分析和聚類。
4 交通運輸中的大數據處理及挖掘參考架構
在前面章節中,筆者討論了大數據處理及挖掘在基于云計算的智能交通系統中的應用。接下來,主要分析基于云計算的智能交通系統架構,并對其主要數據流進行解釋。此外,筆者還還展示了如何使用大數據處理及挖掘技術處理數據流,并提供足夠的信息來滿足用戶請求。
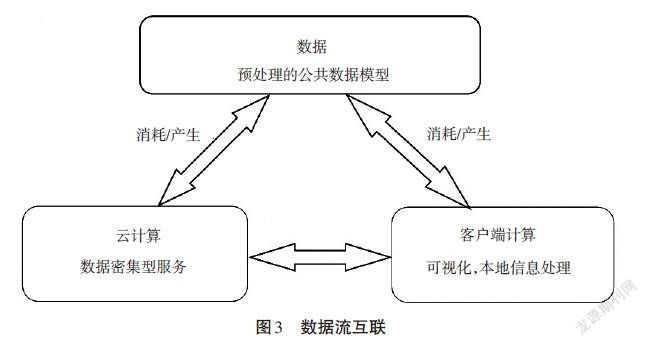
在云中執行的應用程序是數據密集型的。通過云提供的服務需要處理、匯總和分析大量數據。
綜上所述,計算是云計算的瓶頸。因此,大數據處理及挖掘的一個非常重要的挑戰是本地數據源(客戶端)和云之間數據處理的合理平衡。如果客戶端擁有足夠的計算能力,則可將數據進行本地預處理,并將已處理的數據提供給云端,以減少云計算壓力、節省網絡資源。然而,如果客戶端的計算能力不允許進行信息處理,則原始數據被提供給云端處理。數據流互聯如圖3所示。
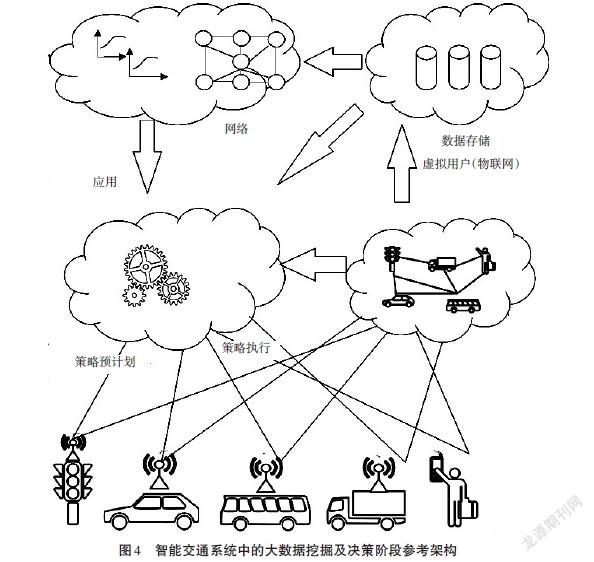
接下來,筆者考慮用大數據處理及挖掘的參考架構和智能交通系統中的決策階段。在這個架構中,筆者專注于說明數據流及其處理,以及使用結果來優化參與者策略并滿足其要求。圖4顯示了大數據處理及挖掘的主要架構和智能交通系統中的決策階段。
需要注意的是,可以使用來自不同提供商的多種云。一些問題對他們來說可能是相似的,他們之間的合作是可能的。智能交通系統的使用者(交通參與者,例如,車輛或行人,商業用戶如物流提供商、公共交通工具或出租車,數據提供者如攝像機或探測器,以及交通管理員如交通管理中心或交通管制元件),使用穩定和永久的互聯網通訊與云端連接。這創建了一個虛擬用戶網絡,實際上其是云中現實的鏡像。該虛擬現實包含分布式用戶數據(部分存儲在用戶設備中,部分存儲在由云提供的虛擬存儲中,但仍與用戶相關聯)。需要注意的是,斷開用戶與云的連接并不意味著消除其虛擬表示,這僅表示本地存儲的數據在云中不可用。
在第一階段,應對數據進行預處理。原始傳感器數據需要非常大的存儲空間,并且不能長時間存儲。此數據可以在本地處理或上傳到云端并在那里進行預處理。預處理的結果存儲在用戶配置文件中,并且可以在此階段上載到云。
第二階段是組織虛擬云信息存儲。云數據挖掘是由代理商進行的,云數據挖掘代理收集信息,將其部分復制到云存儲中,部分地引用用戶配置文件(若其在云中可用)。這些代理商特別關注信息的成本,包括其可用性、可靠性和精確性。
基于云的系統擁有大量用戶,應該快速響應其請求。由此,創建人工點對點網絡,其面向具體的問題,由云系統解決。例如,可以創建面向最短路徑計算、交通燈調節或乘客過境。在人工網絡中解決了兩個重要問題:估計其參數和預先計算用戶策略。
對點對點網絡參數的預估是大數據挖掘及處理過程中的主要階段。其包括估計網絡參數以獲得網絡的實際狀態。基于虛擬存儲器中的信息,執行參數估計,考慮數據成本并在必要時從物理存儲器接收數據。這些參數可以是網絡節點上的行程時間,交叉口上的隊列或公共交通站點之間的行程時間。一個非常重要的方面是將信息的動態變化考慮在內,這是由數據挖掘客戶端提供的。
5 智能交通系統中的決策支持
筆者考慮三種智能交通系統應用場景:第一,合作交叉路口控制,通過調節交叉路口控制器來優化交通網絡中的車輛流量;其次,個人旅行伴侶,為旅行者、水面駕駛員和運輸操作員提供多式聯運的動態規劃和監控;最后,物流服務伙伴,為受城市環境影響或依賴于貨物運輸的客戶和利益相關者提供福利。
5.1 交叉路口虛擬化控制
此方案使用托管在云中的自適應,半分布式流量管理策略來監控交叉路口控制器,并在車輛集群和流量管理基礎架構之間的云中創建點對點網絡。其建議駕駛員使用保持交通流量平穩的最佳速度,并根據實時交通情況協助調整交通信號燈、標志。該服務使用實時交通信息和路線數據收集服務來制定優化網絡運營策略。
第一步,處理數據流(歷史和實時)。
第二步:創建點對點網絡,其是用于解決特定問題的虛擬抽象網絡(交叉口和區域流量模型、綠波模型、公共交通優先級、阻塞避免等)、估算網絡參數(流量通量、密度和速度、行程時間估算等)。
第三步:制定交叉路口控制的靜態策略(如增加流量、天氣條件的改變、群體活動等)。
第四步:將動態實時信息與靜態策略相結合,以便做出最新的控制決策(根據當前條件校正信號周期,協調信號控制器以解決諸如堵塞、事故等)。
5.2 動態多模式行程規劃
此方案可幫助旅行者實時規劃和調整多模式、門到門的行程。其通過識別最佳運輸工具和強大的實時定位,為日常通勤者和其他旅行者提供改進的(即更快、更舒適、更便宜和更環保)的移動性。這種多模式旅程的規劃考慮了當前的交通方式、旅行者的背景和偏好、城市交通規則及當前的要求和約束。旅程計劃需要獲得旅行持續時間的總體指示及適應資源的早期預訂(火車或機票)。
第一步:處理數據流(歷史和動態)。
第二步:創建點對點網絡(中轉站、公共交通協調、乘客運輸選擇等)和網絡參數評估(不同運輸方式的旅行時間取決于各種因素,如等待時間、乘客到達站點、價格模型等)。
第三步:基于歷史數據和預期條件的多模式路線預先規劃(熱門路線的預先規劃、預訂路線的預先規劃、預期事件的預先規劃)
第四步:實際多模式旅程的預先計劃路線的動態更新(實際旅行時間估計,在多模式鏈中先前行程延遲的情況下重新計劃,重新規劃其他旅行可能性或取消多模式旅程的一部分),以及公共交通時間表的動態更新(按需變更,不同交通方式的協調)。
5.3 行程預訂和實時優化路線導航
這種情況有助于物流提供商基于最新信息以低成本保證快速(特別是按時)交付,實現每個車輛和車隊效率最大化。優化物流車輛的運動,避免交通堵塞,并盡可能采用最短路線。
第一步:處理數據流(歷史和動態)。
第二步:創建點對點網絡(交付模型,物流提供商-客戶交互模型等),根據網絡參數估計(不同路段的行程時間、延遲概率,下降過程時間分布、概率)事故。
第三步:預計劃(車輛的初步良好分配,每個車輛的客戶的初步訂單,每個車輛的初步路線,每個客戶的初步時間窗口等)。
第四步:根據最新信息動態更新預先計劃的路線(根據當前交通狀況重新規劃路線,在發生事故或交通擁堵時重新規劃,剩余時間的預估等);物流車輛之間的合作;與客戶的動態協議(關于下車地點的協商取決于車輛和客戶的當前位置)。
6 未來的工作和結論
本文主要對基于云架構和智能交通系統的場景進行分析,并探討用于實施相應數據挖掘與處理技術的架構和用于運輸操作的決策策略,討論三種智能交通系統情景采用適當的數學方法,以反映智能交通系統對企業和社會的需求和潛在影響。
參考文獻:
[1]何曉群,劉文卿.應用回歸分析[M].北京:中國人民大學出版社,2015.
[2]張春陽,周繼恩,劉貴全,等.基于數據倉庫的決策支持系統的構建[J].計算機工程,2002(4):249-252.
[3]劉智勇.智能交通控制理論及其應用[M].北京:科學出版社,2003.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
