結(jié)合波段選擇的差分進(jìn)化高光譜圖像分類(lèi)
2019-09-16 02:27:50田洪晨王立國(guó)趙亮陳春雨
應(yīng)用科技 2019年5期
關(guān)鍵詞:分類(lèi)
田洪晨,王立國(guó),趙亮,陳春雨
哈爾濱工程大學(xué) 信息與通信工程學(xué)院,黑龍江 哈爾濱 150001
高光譜遙感是用數(shù)十至數(shù)百個(gè)連續(xù)且細(xì)分的光譜波段對(duì)地物持續(xù)遙感成像的技術(shù)。隨著高光譜遙感技術(shù)的不斷發(fā)展和成熟,高光譜遙感技術(shù)在軍事偵查,礦產(chǎn)勘探偵測(cè),農(nóng)業(yè)、林業(yè)病蟲(chóng)害監(jiān)測(cè),漁業(yè)、畜牧業(yè)養(yǎng)殖等方面都取得了很大突破[1]。高光譜遙感具有波段多、獲得的數(shù)據(jù)量大、相鄰波段間相關(guān)性強(qiáng)的特點(diǎn),導(dǎo)致數(shù)據(jù)之間冗余量大,從而給高光譜遙感圖像分類(lèi)帶來(lái)了很大的困難[2]。基于這些難點(diǎn),國(guó)內(nèi)外學(xué)者就如何快速、準(zhǔn)確地對(duì)高光譜遙感圖像地物目標(biāo)分類(lèi)進(jìn)行了一系列的研究[3-5]。常用的高光譜遙感圖像分類(lèi)按照對(duì)于地物分類(lèi)時(shí)是否需要訓(xùn)練樣本,可以大致分為無(wú)監(jiān)督分類(lèi)[6]、監(jiān)督分類(lèi)[7]與半監(jiān)督分類(lèi)[8]。對(duì)于無(wú)監(jiān)督分類(lèi),其優(yōu)點(diǎn)為不需要標(biāo)記與訓(xùn)練。這使得無(wú)監(jiān)督分類(lèi)在對(duì)于數(shù)據(jù)處理上比較快速。但是由于高光譜數(shù)據(jù)波段間相關(guān)性強(qiáng),只進(jìn)行無(wú)監(jiān)督分類(lèi),會(huì)造成高光譜數(shù)據(jù)所含大量信息未被完全使用,分類(lèi)效果并不理想。而監(jiān)督分類(lèi)需要的標(biāo)記訓(xùn)練樣本較多,并且標(biāo)記過(guò)程繁瑣、耗時(shí),成本昂貴[9]。針對(duì)此類(lèi)問(wèn)題,半監(jiān)督分類(lèi)在已知類(lèi)別標(biāo)記的訓(xùn)練樣本不足的情況下,將未知類(lèi)別的樣本引入訓(xùn)練過(guò)程,自動(dòng)地利用未標(biāo)記樣本提升分類(lèi)性能[10]。
就分類(lèi)器而言,支持向量機(jī)(support vector machine,SVM)[11]是基于統(tǒng)計(jì)學(xué)習(xí)理論的基礎(chǔ)上于1995年提出的,其效果得到廣泛好評(píng)。SVM的核心思想是把樣本通過(guò)非線性映射方式將其投影到高維特征空間,以結(jié)構(gòu)風(fēng)險(xiǎn)最小化原理為其原則,在高維特征空間中構(gòu)造一個(gè)最優(yōu)分類(lèi)超平面。最小二乘孿生支持向量機(jī)算法(least squares twin support vector machines,LSTSVM)[12]是在 SVM的基礎(chǔ)上發(fā)展起來(lái)的分類(lèi)工具,打破SVM類(lèi)別邊界平行分布的限制,尋找2個(gè)不平行的分類(lèi)超平面,并使用等式代替不等式,分類(lèi)效果得到進(jìn)一步提升。
高光譜圖像維數(shù)高、數(shù)據(jù)計(jì)算量大,給后續(xù)的分類(lèi)處理造成困難。針對(duì)此問(wèn)題,本文提出了一種融合波段選擇和半監(jiān)督分類(lèi)的分類(lèi)算法GADE_LSTSVM,使用LSTSVM作為分類(lèi)工具,并在分類(lèi)前加入波段選擇過(guò)程,減少樣本冗余波段,從而能夠更快地從無(wú)標(biāo)記樣本中選取信息量豐富的樣本。該算法使用遺傳算法(genetic algorithm,GA)全局搜索最優(yōu)波段組合,再使用差分進(jìn)化算法(differential evolution,DE)選取未標(biāo)記樣本內(nèi)信息量豐富的樣本添加標(biāo)記。波段選擇方法減少冗余波段,提高了無(wú)標(biāo)記樣本中信息量豐富的樣本的選取速率;輔助差分進(jìn)化算法選取出的信息量豐富的未標(biāo)記樣本放入訓(xùn)練樣本集,進(jìn)而提高整個(gè)算法的分類(lèi)精度。
1 LSTSVM算法
LSTSVM算法是在SVM的基礎(chǔ)上找出2個(gè)相對(duì)較小且不相互平行的分類(lèi)超平面,并使得每個(gè)超平面各與其中一類(lèi)樣本盡可能近,與另一類(lèi)樣本盡可能遠(yuǎn)。把2個(gè)凸優(yōu)化問(wèn)題轉(zhuǎn)變?yōu)?個(gè)線性方程問(wèn)題,降低算法復(fù)雜度,減少計(jì)算量:

式中:A為訓(xùn)練樣本集內(nèi)正樣本集;B為訓(xùn)練樣本集內(nèi)負(fù)樣本集;C為正樣本與負(fù)樣本的組合;e1、e2為單位向量;r1,r2為偏移量;ξ為松弛變量;c為懲罰因子。K(·)為映射到高維空間的高斯徑向基核函數(shù):

問(wèn)題的解為:

2 本文算法
在本文所提GADE_LSTSVM算法中,首先利用遺傳算法從高光譜圖像的全部波段中優(yōu)選出信息量豐富的波段,然后再使用差分進(jìn)化算法將用于訓(xùn)練的無(wú)標(biāo)記樣本中信息量豐富樣本篩選出來(lái),最終與用于訓(xùn)練的有標(biāo)記樣本集相結(jié)合,使用LSTSVM進(jìn)行訓(xùn)練。
由于高光譜圖像的已標(biāo)記樣本數(shù)量較少,所以在高光譜圖像分類(lèi)中,需要將無(wú)標(biāo)記信息利用起來(lái)。因?yàn)楦吖庾V圖像所含波段較多,使用全部波段來(lái)選取信息量豐富的無(wú)標(biāo)記樣本所需時(shí)間較長(zhǎng),且易造成過(guò)擬合現(xiàn)象。所以我們需要去除冗余信息,將信息量豐富的波段選出并加以應(yīng)用。為了有效利用無(wú)標(biāo)記樣本信息,本文采用差分進(jìn)化算法對(duì)來(lái)自無(wú)標(biāo)記樣本的有價(jià)值樣本進(jìn)行過(guò)濾,以擴(kuò)充有限的帶標(biāo)簽樣本集,構(gòu)造具有代表性的訓(xùn)練集,極大減少人工標(biāo)記的成本。
遺傳進(jìn)化與差分進(jìn)化都是啟發(fā)式隨機(jī)搜索算法,并且原理簡(jiǎn)單易于操作,容易求得全局最優(yōu)解。經(jīng)過(guò)波段選擇后,差分進(jìn)化算法再利用LSTSVM算法進(jìn)行分類(lèi),有效地解決了由于標(biāo)簽不足造成的欠擬合問(wèn)題。因此,DE算法結(jié)合LSTSVM算法是本文算法的關(guān)鍵。
2.1 波段選擇中的遺傳算法
遺傳算法利用種群進(jìn)化來(lái)搜索最優(yōu)解,且具有全局收斂性[13]。在本算法中,處理高光譜數(shù)據(jù)主要分為五步。
1)編碼
對(duì)于高光譜圖像所含有的所有已剔除噪聲的波段進(jìn)行編碼。對(duì)于高光譜圖像來(lái)說(shuō),其所含有的波段數(shù)多,使用常規(guī)的二進(jìn)制編碼得到的編碼位數(shù)會(huì)很大,之后再將這個(gè)編碼進(jìn)行遺傳交叉變異的時(shí)候會(huì)十分復(fù)雜,對(duì)計(jì)算量造成影響。所以用四進(jìn)制編碼代替二進(jìn)制編碼對(duì)高光譜圖像的波段進(jìn)行編碼,減少編碼長(zhǎng)度。將編碼設(shè)為L(zhǎng)位,并且將高光譜圖像的每個(gè)波段與L位四進(jìn)制數(shù)一一對(duì)應(yīng)。
2)初始化
控制參數(shù):設(shè)初始種群中共有m1個(gè)染色體,其上各有n1個(gè)基因(n1是L的整數(shù)倍);交叉、變異概率分別設(shè)為Pc、Pm;終止迭代次數(shù)設(shè)為N1。
初始種群:隨機(jī)生成m1×n1位四進(jìn)制數(shù),每一行中從起始位置順次L位即為一個(gè)單位,并對(duì)應(yīng)高光譜中的一個(gè)波段。該L位四進(jìn)制數(shù)轉(zhuǎn)換成的十進(jìn)制數(shù)即為高光譜圖像的的波段序號(hào)。
3)適應(yīng)度函數(shù)
因?yàn)镴effries-Matusita(JM)距離可以得到各類(lèi)別樣本之間的可分離性,所以在對(duì)高光譜圖像中的兩類(lèi)進(jìn)行距離統(tǒng)計(jì)時(shí)能發(fā)揮很好的作用[14]。因此,將JM距離Jij作為使用遺傳算法進(jìn)行波段選擇的適應(yīng)度函數(shù)。計(jì)算高光譜圖像各類(lèi)樣本間的平均JM距離需要使用第i類(lèi)和第j類(lèi)樣本在波段組合上的度量均值矢量μi、μj和第i類(lèi)和第j類(lèi)樣本在波段組合上的協(xié)方差矩陣進(jìn)行計(jì)算。

式中:


式中s為類(lèi)別數(shù)。
4)遺傳算子操作
選擇操作:分別求出種群中的每個(gè)個(gè)體的JM距離并進(jìn)行對(duì)比,將JM距離大的波段保留,并復(fù)制到下一代。
交叉、變異操作:以一定概率(Pm),從個(gè)體中隨機(jī)選擇用于交叉的基因,并再以一定的概率(Pc)實(shí)施變異。
5)終止條件
設(shè)置終止條件為最大迭代次數(shù)N1。最后,得到一個(gè)波段組合成的矩陣M。
2.2 結(jié)合差分進(jìn)化算法的樣本選取
與遺傳算法不同的是,差分進(jìn)化算法根據(jù)父代個(gè)體間的差分矢量進(jìn)行編譯、交叉、選擇操作[15-16]。
在本算法中所選高光譜波段數(shù)D即為問(wèn)題維數(shù),經(jīng)過(guò)G次迭代后第i個(gè)種群向量為
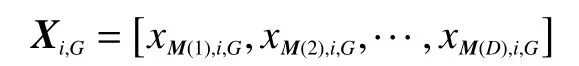
式中:i=1,2,···,N。其中N為種群規(guī)模。
2.2.1 差分變異
基本變異方式的基本方程為:

由式(1)可以看出差分進(jìn)化算法中差分變異的基本方式。將種群中的某一個(gè)體疊加經(jīng)縮放后另外2個(gè)的差分向量。為了使變異更加多樣,本文算法將2個(gè)個(gè)體縮放因子F、λ加入到差分操作中,對(duì)式(1)加以改進(jìn)得到:

2.2.2 交叉操作
與遺傳算法的交叉變異有所不同,差分進(jìn)化算法的交叉操作是通過(guò)在種群內(nèi)隨機(jī)選擇個(gè)體來(lái)進(jìn)行的。

式中:jrand∈M為隨機(jī)波段;為交叉概率;uj,i,G的集合即為Ui,G。
2.2.3 選擇
在本算法中將經(jīng)過(guò)差分變異與交叉操作后的向量Ui,G與原向量通過(guò)比較適應(yīng)度,留下適應(yīng)度較高的個(gè)體。

式中f(X)為適應(yīng)度函數(shù),在高光譜圖像中即為個(gè)體距離LSTSVM超平面的距離。
對(duì)于高光譜圖像的多分類(lèi)問(wèn)題,由于SVM是一個(gè)二分類(lèi)器,所以常通過(guò)組合的形式將其加以應(yīng)用。應(yīng)用的方法主要有一對(duì)多和一對(duì)一兩種策略。本算法中LSTSVM屬于SVM的改進(jìn)算法,所以也通過(guò)一對(duì)多將之轉(zhuǎn)化為多個(gè)二分類(lèi)問(wèn)題。
2.3 算法流程
1)使用遺傳算法從高光譜圖像的所有波段中選取出信息量較為豐富的20個(gè)波段參與訓(xùn)練;
2)選取有標(biāo)記樣本集ML和不參與測(cè)試的無(wú)標(biāo)記樣本集Up;
3)利用差分進(jìn)化算法從Up中篩選出一定量信息量豐富的樣本,樣本記為UpDE;
4)對(duì)UpDE進(jìn)行標(biāo)記,加入到有標(biāo)記樣本集中,訓(xùn)練LSTSVM分類(lèi)模型;
5)利用已經(jīng)訓(xùn)練好的LSTSVM分類(lèi)器開(kāi)始對(duì)測(cè)試樣本進(jìn)行標(biāo)記,測(cè)評(píng)該分類(lèi)器的分類(lèi)精度。
3 實(shí)驗(yàn)部分
3.1 實(shí)驗(yàn)數(shù)據(jù)
為驗(yàn)證算法有效性,本文選取2個(gè)高光譜圖像數(shù)據(jù),分別是Indian pines數(shù)據(jù)集和Pavia大學(xué)數(shù)據(jù)集,從中選取8個(gè)主要類(lèi)別參與分類(lèi)實(shí)驗(yàn)。2個(gè)數(shù)據(jù)集的地物圖如圖1所示。為了更好地進(jìn)行比較,2個(gè)高光譜圖像的大小均設(shè)為144×144,其中,Indian pines原始數(shù)據(jù)集包含總波段數(shù)為200個(gè),Pavia大學(xué)原始數(shù)據(jù)集包含125個(gè)波段,去除噪聲后的波段數(shù)為103。

圖1 監(jiān)督信息
Indian pines數(shù)據(jù)集中地物的分布比較規(guī)則,每類(lèi)地物的分布整體性好;而Pavia大學(xué)數(shù)據(jù)集中的同類(lèi)地物分布較為分散,涉及區(qū)域較大。
3.2 實(shí)驗(yàn)仿真
本實(shí)驗(yàn)中用于仿真的電腦其處理器為Intel(R)Core(TM)i7-4720HQ,RAM大小為8 GB,采用64位的windows10系統(tǒng)作為操作系統(tǒng),具體用于仿真的軟件為matlab2018a。
將總體分類(lèi)精度(overall accuracy,OA)、平均分類(lèi)精度 (average accuracy,AA)、Kappa系數(shù)作為評(píng)價(jià)高光譜圖像分類(lèi)精度的準(zhǔn)則。
設(shè)N是樣本總數(shù),mii是第i類(lèi)正確分類(lèi)的樣本數(shù),Ai為第i類(lèi)的分類(lèi)精度。
總體分類(lèi)精度的值OA為:

第i類(lèi)分類(lèi)精度為:

平均分類(lèi)精度的值為AA:

Kappa系數(shù):

在實(shí)驗(yàn)中,遺傳進(jìn)化設(shè)置的參數(shù)為NP=20、四進(jìn)制染色體編碼長(zhǎng)度為L(zhǎng)=4、最大進(jìn)化代數(shù)N1=200、交叉概率Pc=0.75、變異概率Pm=0.01。同理,差分進(jìn)化算法的參數(shù)為NP=20、F=0.5、λ=0.5、Cr=0.8。并將LSTSVM作為基分類(lèi)器,設(shè)置LSTSVM的核函數(shù)為高斯核函數(shù),其懲罰因子C、核參數(shù)σ通過(guò)交叉驗(yàn)證法從中選取最優(yōu)值。多分類(lèi)方法選取一對(duì)余方法。
3.3 仿真結(jié)果及其分析
通過(guò)實(shí)驗(yàn)對(duì)比標(biāo)準(zhǔn)SVM、DE_LSTSVM、SVM_MS(SVM_margin sampling)和本文算法4種分類(lèi)算法的優(yōu)劣。實(shí)驗(yàn)隨機(jī)選取10%的樣本作為訓(xùn)練樣本,其中10個(gè)為已標(biāo)記樣本,其他為無(wú)標(biāo)記樣本;其余90%的樣本作為測(cè)試樣本。首先對(duì)Indian pines數(shù)據(jù)集高光譜圖像進(jìn)行分類(lèi)。表1給出了AA、OA、Kappa系數(shù)以及運(yùn)行時(shí)間。

表1 Indian pines高光譜圖像分類(lèi)精度
從表1可以看出DE_LSTSVM算法與SVM_MS算法的分類(lèi)性能明顯好于SVM。與DE_LSTSVM算法相比,本文的GADE_LSTSVM算法分類(lèi)速度提升了62.742 0 s,而分類(lèi)精度只有略微降低。與SVM_MS算法相比,本文算法在分類(lèi)精度上有明顯提高,OA提高了5.91%,AA提高了4.76%,Kappa提高了0.069 6。GADE_LSTSVM算法通過(guò)GA算法進(jìn)行波段選擇,DE算法又對(duì)信息量豐富的無(wú)標(biāo)記樣本進(jìn)行篩選引入到已標(biāo)記的訓(xùn)練樣本集中,明顯提高了分類(lèi)速度。圖2為4種算法分類(lèi)結(jié)果的灰度圖表示。

圖2 Indian pines數(shù)據(jù)集高光譜圖像4種算法的分類(lèi)結(jié)果
我們可以觀察出圖2(b)、(c)、(d)的錯(cuò)分樣本數(shù)量與圖2(a)有明顯差別。由圖可知,本文算法以損失小部分分類(lèi)精度為代價(jià),使高光譜圖像的分類(lèi)速度有了顯著提高。
用Pavia大學(xué)數(shù)據(jù)集高光譜圖像再次驗(yàn)證。選取10%的樣本作為訓(xùn)練樣本,其中10個(gè)為已標(biāo)記樣本,其他為無(wú)標(biāo)記樣本;其余90%的樣本作為測(cè)試樣本。表2記錄了4種算法的仿真結(jié)果,從表2可以看出本文所提出的算法比DE_LSTSVM算法的分類(lèi)速度提高了26.442 0 s,而分類(lèi)精度基本一致;比SVM_MS算法OA提高了7.24%,AA提高了3.99%,Kappa系數(shù)提高了0.092 4。
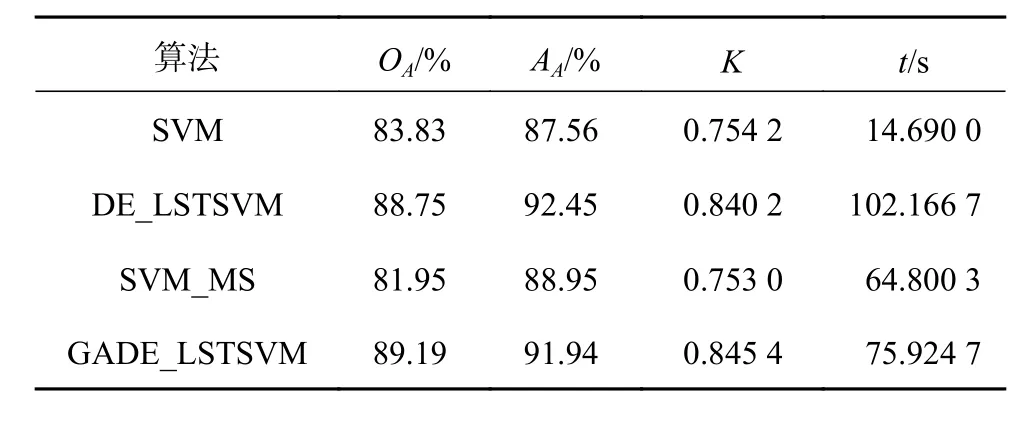
表2 Pavia大學(xué)高光譜圖像分類(lèi)精度
標(biāo)準(zhǔn) SVM、DE_LSTSVM算法、SVM_MS算法和本文算法的仿真結(jié)果灰度圖如圖3所示。

圖3 Pavia大學(xué)數(shù)據(jù)集高光譜圖像4種算法的分類(lèi)結(jié)果
此外為了更直觀地展現(xiàn)用于訓(xùn)練的帶標(biāo)簽樣本數(shù)目s與總體分類(lèi)精度和分類(lèi)速度之間的關(guān)系,圖4、5將代表精度的折線圖與代表速度的柱狀圖相結(jié)合進(jìn)行對(duì)比。帶標(biāo)簽樣本數(shù)目s取3、5、10、15、20、25。從曲線圖部分可以看出,本文所提算法在樣本數(shù)目很少的情況下分類(lèi)精度的優(yōu)勢(shì)更為明顯。從柱狀圖部分可以看出,本文所提算法具有明顯的分類(lèi)速度優(yōu)勢(shì)。
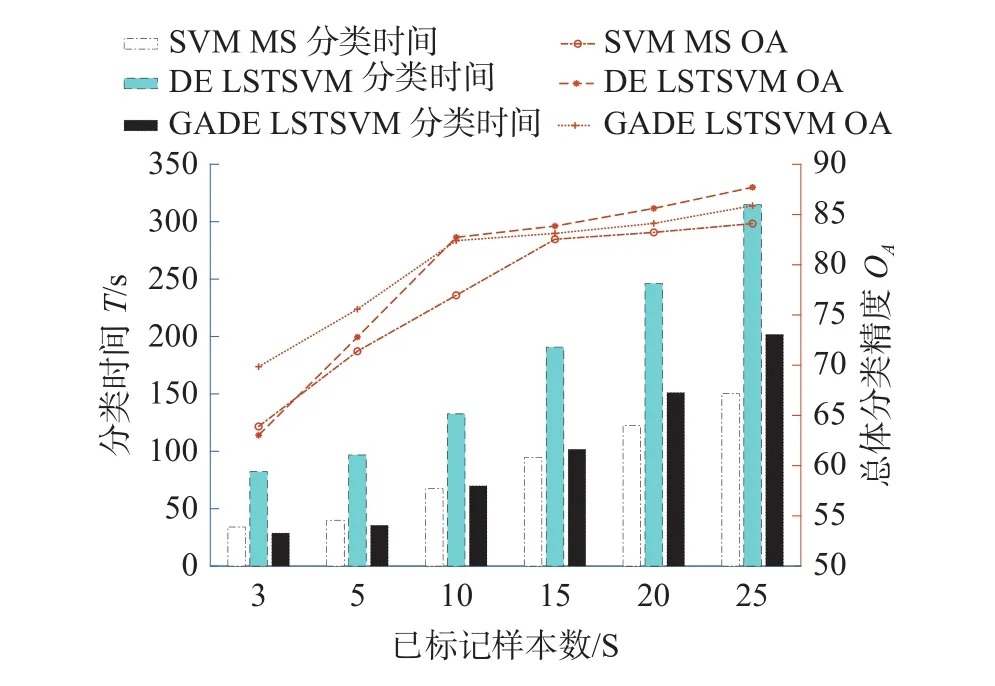
圖4 帶標(biāo)簽樣本數(shù)與OA的關(guān)系曲線(Indian pines數(shù)據(jù)集高光譜圖像)

圖5 帶標(biāo)簽樣本數(shù)與OA的關(guān)系曲線(Pavia大學(xué)數(shù)據(jù)集高光譜圖像)
4 結(jié)論
1)本文算法在分類(lèi)之前進(jìn)行波段選擇,有效地減少有標(biāo)簽樣本中的冗余信息對(duì)學(xué)習(xí)過(guò)程造成的計(jì)算量。
2)在帶標(biāo)記樣本少的情況下,本文算法能夠快速地選取信息量豐富的無(wú)標(biāo)簽樣本擴(kuò)充入訓(xùn)練樣本集中,有效地提升了分類(lèi)器的性能。
3)本文算法在已標(biāo)記樣本數(shù)量較少時(shí)優(yōu)勢(shì)十分明顯。
今后的研究工作可以集中在嘗試?yán)靡褬?biāo)記樣本的空間信息提高對(duì)小樣本數(shù)據(jù)分類(lèi)性能的改善方面。
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
