基于Jetson TX1的目標檢測系統*
2019-09-19 08:56:30張雯婷孫旭澤
沈陽工業大學學報 2019年5期
葛 雯, 張雯婷, 孫旭澤
(1. 沈陽航空航天大學 電子與信息工程學院, 沈陽 110136; 2. 國家電網遼陽供電公司 信息通信分公司, 遼寧 遼陽 111000)
計算機視覺領域中,目標檢測一直是工業應用中比較熱門且成熟的應用領域,它涉及場景中目標分類和目標定位的結合,比如人臉識別、車牌識別及行人檢測等.因為近年來硬件計算能力變得越來越強,所以在卷積神經網絡基礎上進行深度學習的研究也得到了不斷發展,特別是在機器視覺方面已有不錯的成果.劉文生等提出了SSD(單鏡頭多箱檢測器)算法,采用回歸方法進行檢測,并將定位和分類集成到一個網絡中.SSD算法基于VGG-16網絡結構,將VGG-16中的全連接層替換為卷積層[1],然后將各個卷積層分別輸出到各自的特征映射,作為特征圖預測的輸入,最后生成一個多尺度的特征映射進行回歸.而YOLO算法是將目標檢測轉換成一個回歸問題,使檢測速度得到了極大的提升,不過仍存在一些不足,即檢測小目標所得的結果無法達到較高精度[2].通過各路學者不斷的努力,YOLO算法得以一次次升級,現在已經升級為YOLOv3,它采用K-means聚類的方法在數據集中得出其邊界框最佳的初始位置.為了提高小目標的檢測精度,算法采用了多尺度融合[3],但上述算法的速度還達不到實時效果.對于無人駕駛問題,在提高檢測精度的同時,也需要提高實時性能,為了平衡速度與精度兩者之間的利弊,本文中改進了YOLOv3網絡,使其更適合在硬件上運行.
1 目標檢測系統
將自動駕駛應用到實際中,既要提高計算能力,又要考慮實物的成本以及大小等問題,若要滿足這些需求,則需使用高性能并具有GPU的多核平臺.本文使用了NVIDIA公司開發的嵌入式視覺計算系統Jetson TX1,TX1以256核Maxwell架構GPU為主,在性能上十分節能高效并且外觀小巧[4].以Jetson TX1作為核心開發板,將前置攝像頭采集到的圖像信息輸入到TX1中,再通過目標檢測算法,檢測、識別多種目標,并將讀取的信息存儲至數據庫,同時通過顯示屏顯示,系統硬件原理框圖如圖1所示.目前,應用在TX1上的圖像檢測計算的幀速率雖然很可觀,但對于實際應用來說,還有一定差距,因此本文選用最新的YOLOv3算法在此平臺上進行改進、提速.

圖1 系統硬件原理框圖Fig.1 Block diagram of system hardware principle
2 YOLOv3及改進的檢測算法
2.1 YOLOv3算法
基于端到端YOLO系列算法的步驟為:首先輸入圖像并提取網絡特征,得到一定大小的特征圖(比如13×13),然后將輸入圖像劃分成13×13個單元格,接著進行邊界框預測.某個目標的中心坐標落在哪個單元格中,則由該單元格來預測該目標,每個單元格都會預測固定數量的邊界框(YOLOv1中是2個,YOLOv2中是5個,YOLOv3中是3個),這幾個邊界框中只有最大的邊界框才會被選定用來預測該目標[5].
相較于前兩代YOLO,第三代YOLOv3有了很大進步,各方面都復雜得多,而且無論是在速度方面還是結果的精度方面,對比其他深度學習算法(SSD、R-FCN等),YOLOv3的優勢都是最明顯的[6].YOLOv3首先對邊界框預測,采用K-means聚類的方式對Anchor Box進行初始化,得到多個Anchor Box的尺寸、位置信息[7],其次,采用多標簽分類,該操作是通過logistic分類器來實現的,取代了以往的softmax分類,這是YOLOv3的一大亮點,解決了重疊類別標簽檢測不出的問題.另外,類別預測中的損失函數采用二元交叉熵,特別針對小目標檢測,還采用了多尺度融合進行特征提取,采用Darknet-53特征提取網絡,包括53個卷積層和殘差結構.YOLOv3雖然改進了YOLO一直以來不擅長檢測小物體的缺點,并一直保證著高檢測速度,但平均準確率(mAP)并不高.
2.2 改進的YOLOv3檢測算法
2.2.1 激活函數的改進
YOLOv3中所采用的損失函數主要由激活函數sigmoid和二元交叉熵組成,其中輸入的連續實值經過sigmoid函數激活后,輸出值都會在0~1范圍內,但在深度神經網絡中梯度反向傳遞時,要對sigmoid求導,求導后兩邊趨向于0,也就意味著很大幾率會出現梯度消失的現象,甚至還有幾率發生梯度爆炸,而且sigmoid所輸出數據都大于0,那么收斂速度會受到相應的影響[8].本文結合sigmoid函數和ReLU函數存在的問題,將激活函數改進為
(1)
式中,參數α、β為可調整參數,神經網絡更新α的方式為
(2)
式中,μ、ε分別為激活函數通過反向傳播進行訓練得到的動量和學習率.本文采用αi=0.25作為初始值,β則控制著負值部分在何時飽和,最終通過不斷測試對比,選取β=0.5[9].改進后的激活函數其總體輸出接近0均值,這樣下一層的神經元得到0均值作為輸入,能夠提升收斂速度,還解決了梯度消失以及ReLU函數中的Dead ReLU問題.加入參數α、β后,可以避免引起某些神經元可能永遠不會被激活,導致相應的參數永遠不能被更新的情況.
2.2.2 采用多級特征金字塔網絡
YOLOv3中采用的多尺度融合(FPN)是通過自上而下的方式融合深層和淺層的特征來構造特征金字塔.雖然采用FPN后,大幅度提升了小物體的檢測能力,但對于一些大、中物體檢測能力偏弱,這是因為金字塔中的每個特征圖(用于檢測特定大小范圍內的對象)主要或甚至僅通過骨干網絡單層構建,即主要或僅包含單層信息.圖像中所包含的各個目標大小不一,所以應當根據相應的特征分別進行檢測,目標可大致分為簡單目標與復雜目標兩種,對于前者僅僅是淺層特征便可檢測到,其所包含語義信息不多,可優勢在于目標位置準確;對于后者,則需要較深層的特征,其語義信息相對更多,可不足在于目標位置較模糊[10].而多級特征金字塔網絡最后可以提取同一尺度在不同層內的特征,解決了FPN方法的局限性.
本文的多級特征金字塔網絡(MLFPN)結構如圖2所示,結構保留YOLOv3中的DarkNet-53并作為主要特征提取網絡.將MLFPN嵌入到DarkNet-53網絡后,首先將DarkNet-53網絡提取的3個層次特征(大小分別為13×13、26×26、52×52)通過特征融合模塊(FFM)融合,將融合后的特征圖(大小為52×52)作為基本特征,再依次由多個U形模塊(TUM)和FFM對基本特征進行處理,這樣所提取的特征代表性會更強.其中TUM用來產生多個不同尺度的特征圖,且不同TUM內解碼器層的深度基本一致,每個TUM由5個跨步卷積(編碼器)和5個上采樣組成,最終將輸出6種尺度的特征,本文輸出大小依次為52×52、26×26、13×13、7×7、3×3、1×1的特征圖.每一級的輸出可表示為
(3)


圖2 MLFPN結構圖Fig.2 MLFPN structure diagram
3 實驗結果
3.1 數據集及實驗環境
本文的實驗環境如表1所示,本文所用的數據集是公開的目標檢測標注對比數據集PASCAL VOC 2012.為了確定現有算法是否具備更高的性能,本文所建模型不管是在訓練時還是在測試時,都是通過開放數據集而實現.Pascal VOC 2007數據集共包含20個類別,11 540幅圖像,27 450個被標注的目標.設置召回率閾值等于0.5,最大邊框檢測數量是20個.

表1 實驗環境Tab.1 Experimental environment
3.2 結果分析
本文分別用改進的YOLOv3網絡和Faster-rcnn、YOLOv3算法來檢測目標,通過數據集的樣本驗證訓練模型的檢測效果,最終檢測結果如圖3所示.由圖3可知,改進后的YOLOv3準確率超過80%,并且其檢測效果相比另兩種算法有較大的提升.
本文選取數據集中幾張圖片的檢測結果進行對比,對比結果如圖4所示.由圖4中標出的準確率和識別框數以及表2中各類別mAP對比可證明,無論是普通背景單目標圖像、多目標圖像,還是有遮擋目標圖像,改進的YOLOv3算法都展現了比YOLOv3更好的檢測能力,可以更為精準地檢測目標,降低了漏檢率.

圖3 檢測方法對比Fig.3 Comparison of detection methods

圖4 YOLOv3和改進的YOLOv3檢測結果圖Fig.4 Detection results of YOLOv3 before and after improvement
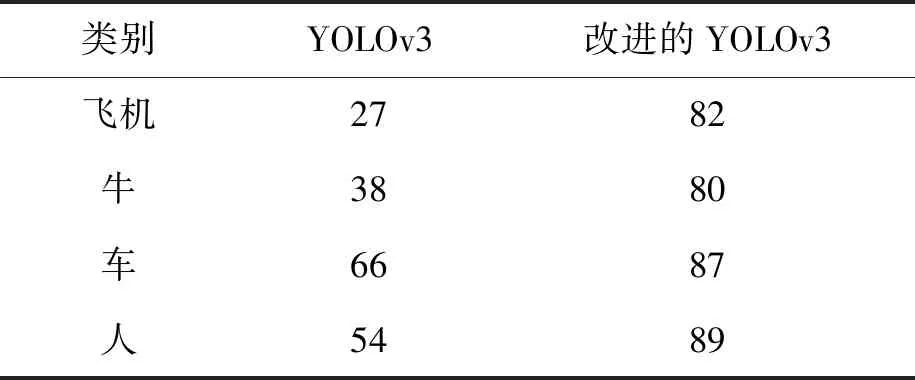
表2 各類別mAP對比表Tab.2 Comparison of different mAP %
將改進的YOLOv3算法應用到TX1開發板中的檢測結果如圖5所示.靜態圖像檢測結果如圖5中a、b、c、d所示;導入一段視頻后,動態視頻檢測結果截圖如圖5e、f、g、h所示.根據對比圖可以看出,改進后的算法可以將較遠的小目標和重疊的目標識別出來,漏檢率明顯降低.其中圖5e、f和圖5g、h分別為視頻中截取的第13幀和32幀,由圖5以及表3(對視頻進行目標檢測的速度及mAP對比表)可以看出,改進的YOLOv3相較于YOLOv3的mAP增長了1.47倍,且檢測速度提高了1.13倍.
4 結 論
文中將YOLOv3中的特征金字塔、激活函數改進后,利用嵌入式GPU平臺在Jetson TX1上實現目標檢測,借助CUDA編程進行并行算法,從而實現目標檢測,改進的YOLOv3可以更高速地提取精確結果.由于GPU硬件技術近年來不斷獲得發展,并且隨著研究進一步深入,將深度學習算法應用到具有實時處理能力的、帶有強大高性能運算能力的GPU設備中已經成為可能,屆時整個目標檢測與跟蹤過程可以更加高效、準確的實現.

圖5 TX1上的實驗結果圖Fig.5 Experimental results on TX1
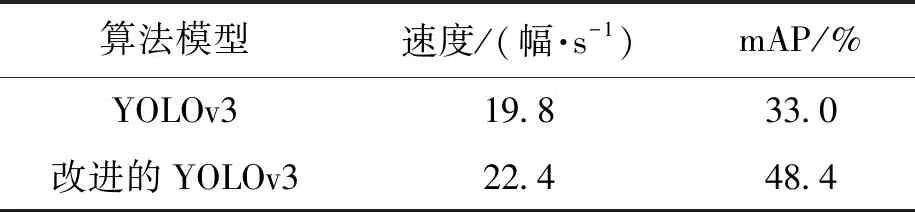
表3 實驗結果Tab.3 Experimental results
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
