循證醫(yī)學數(shù)據(jù)庫信息模型中證據(jù)強度模塊的構(gòu)建及驗證
2019-10-14 06:00:08
中華醫(yī)學圖書情報雜志 2019年6期
關(guān)鍵詞:數(shù)據(jù)庫評價
近30年來,循證醫(yī)學從其最初關(guān)注點——教育臨床醫(yī)生如何理解并使用文獻以及系統(tǒng)綜述科學,逐漸發(fā)展為強調(diào)證據(jù)評價與患者價值觀和意愿選擇相結(jié)合。其中,循證醫(yī)學證據(jù)的質(zhì)量對醫(yī)學決策成功與否起著決定性的作用。證據(jù)質(zhì)量越高,對診斷性質(zhì)、預后和健康干預效果的估計就越接近事實[1]。因此,如何對證據(jù)進行評價和在爆炸式的醫(yī)學文獻中找出最佳臨床證據(jù),是醫(yī)務人員進行循證醫(yī)學的關(guān)鍵步驟,能夠幫助醫(yī)務工作者更高效地進行臨床決策。
循證醫(yī)學數(shù)據(jù)庫能夠有效幫助臨床醫(yī)務人員快速定位最佳臨床證據(jù),是獲取最佳臨床證據(jù)、更新臨床知識、解決臨床問題的重要信息源,而且證據(jù)強度信息對臨床醫(yī)生快速獲取最有價值的信息至關(guān)重要。國外知名的循證醫(yī)學數(shù)據(jù)庫DynaMed不僅提供循證醫(yī)學證據(jù)信息,還對證據(jù)信息來源進行分級評估。我國循證醫(yī)學數(shù)據(jù)庫建設尚處于起步階段,目前還未建立起一個權(quán)威的、可靠的循證醫(yī)學數(shù)據(jù)庫。根據(jù)筆者之前的研究結(jié)果[2],筆者認為一個好的循證數(shù)據(jù)庫信息模型應具備文獻特征、診療過程和證據(jù)強度3個頂層結(jié)構(gòu)模塊,并且能夠直接對證據(jù)進行分級和推薦強度信息,能夠提供對證據(jù)強度方面的檢索或分類功能。在徐維的研究中[3]還探索建立了表達臨床證據(jù)的循證醫(yī)學數(shù)據(jù)元,但是研究中證據(jù)強度模塊的構(gòu)建依據(jù)和反映證據(jù)強度的數(shù)據(jù)元還比較單一。本文根據(jù)國際上已有的隨機對照試驗報告撰寫標準及嚴格評價標準,從循證醫(yī)學數(shù)據(jù)庫信息模型的證據(jù)強度模塊入手,進一步細化該模塊的信息模型,并探討證據(jù)強度模塊中數(shù)據(jù)元反映文獻證據(jù)質(zhì)量的效果,對證據(jù)強度進行初步判斷。
1 證據(jù)強度模塊的構(gòu)建
1.1 報告標準的選取
在蘇格蘭校際指南網(wǎng)(The Scottish Intercollegiate Guidelines Network,SIGN)標準,牛津大學循證醫(yī)學中心(Center for Evidence-Based Medicine,CEBM)標準,推薦分級的評估、制定與評價(Grading of Recommendations Assessment,Development and Evaluation,GRADE),以及中國循證醫(yī)學中心分級標準等國際上使用范圍較廣的循證醫(yī)學證據(jù)標準中,高質(zhì)量的隨機對照試驗及與其相關(guān)的系統(tǒng)性綜述、Meta分析均屬于最高等級證據(jù)類型,被看作臨床證據(jù)的“金標準”[4-7]。因此,為更好地評價隨機對照試驗,幫助醫(yī)務人員判斷證據(jù)質(zhì)量,筆者對比分析了國際上權(quán)威的隨機對照試驗報告質(zhì)量標準CONSORT 2010(CONsolidated Standards Of Reporting Trials)[8]以及部分權(quán)威的循證醫(yī)學網(wǎng)站提供的嚴格評價工具,包括牛津大學循證醫(yī)學中心制定的隨機對照試驗嚴格評價工作表(CEBM)[9]、牛津大學所屬公司Better Value Healthcare Ltd(BVHC)開發(fā)的嚴格評估技術(shù)項目(Critical Appraisal Skills Programme,CASP)[10]、蘇格蘭校際指南網(wǎng)制定的隨機對照試驗嚴格評價說明和工作表(SIGN)[11]、澳大利亞Joanna Briggs Institute(JBI)循證衛(wèi)生保健研究中心制定的隨機對照試驗的嚴格評價工具(JBI)[12]。
1.2 數(shù)據(jù)元的提取
對以上隨機對照試驗的報告標準及嚴格評價工具進行對比分析,統(tǒng)計其中共同出現(xiàn)的評價標準及其次數(shù),其結(jié)果如下。
在CONSORT、CEBM、CASP、JBI及SIGN中均提及隨機/順序產(chǎn)生、分配隱蔽機制,兩組樣本是否相似或基線資料,除被分配的治療外各組是否接受相同的處置、失訪比例,是否將失訪患者納入ITT(Intention To Treat)分析、盲法等評價項目。CEBM、CASP及SIGN中均出現(xiàn)了“PICO是否明確”這一要求,在CEBM、CASP及CONSORT中均出現(xiàn)了對于置信區(qū)間的要求,在JBI和SIGN中均出現(xiàn)了結(jié)果統(tǒng)計方法標準、合理、可信的要求。
因此,結(jié)合隨機對照試驗報告質(zhì)量標準CONSORT 2010及以上嚴格評價標準等要求,并考慮證據(jù)的表達性、標引和可讀性等因素后,選用了Patients/Problems-Intervention-Comparison-Outcome(PICO)、順序產(chǎn)生、分配隱蔽機制、樣本一致、干預一致、失訪比例、盲法、置信區(qū)間、結(jié)果、樣本量、流程圖等數(shù)據(jù)元,構(gòu)成了循證醫(yī)學數(shù)據(jù)庫證據(jù)強度模塊。其本體結(jié)構(gòu)如圖1所示。
將PICO這一元素細化為“疾病”“干預”“結(jié)局”3個數(shù)據(jù)組或數(shù)據(jù)元。其中“疾病”數(shù)據(jù)組可細化為“疾病名稱”和“疾病對象”2個數(shù)據(jù)元,“干預”數(shù)據(jù)組又可分為“干預(試驗)”和“干預(對比)”數(shù)據(jù)組并進一步細化為“手術(shù)名稱”和“藥物名稱”2個數(shù)據(jù)元,“疾病”數(shù)據(jù)組和“干預”數(shù)據(jù)組均可復用在信息模型的診療過程模塊。另外將“樣本一致”和“干預一致”組成為“一致性”數(shù)據(jù)組。
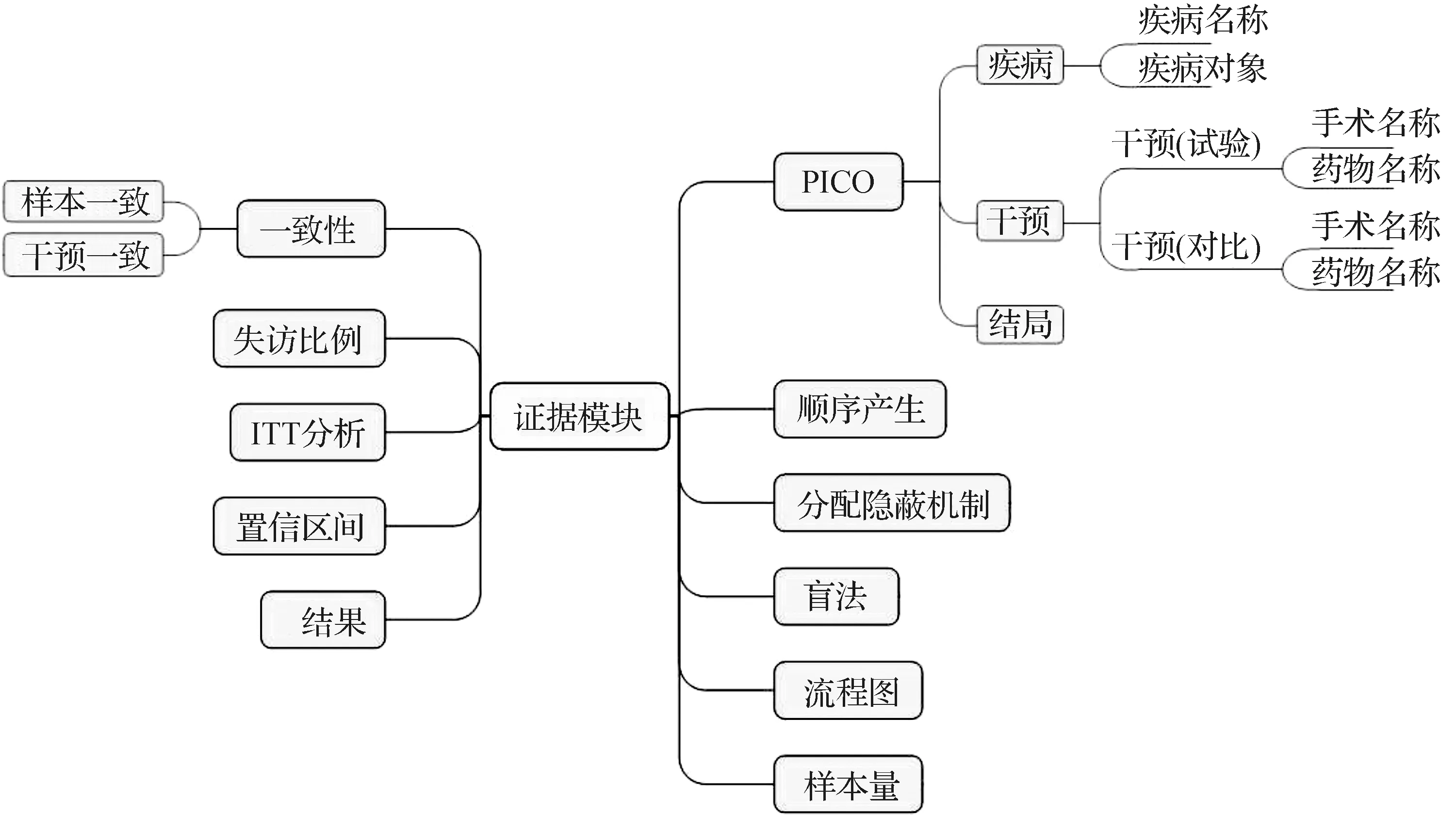
圖1 循證醫(yī)學數(shù)據(jù)庫證據(jù)強度模塊的本體結(jié)構(gòu)
2 證據(jù)強度數(shù)據(jù)元滿足度排序
在證據(jù)強度數(shù)據(jù)元中選出順序產(chǎn)生、分配隱蔽機制、盲法、樣本一致、干預一致、失訪比例、ITT分析、置信區(qū)間、流程圖等元素,作為質(zhì)量評判以及排序的主要依據(jù)。雖然PICO、結(jié)果、樣本量等數(shù)據(jù)元重要,但不便于質(zhì)量評判,因此暫不評判。對選出的9個數(shù)據(jù)元進行相應的滿足度計算,滿足為1,不完全滿足為0.5,不滿足為0,共計9分。將該分值作為隨機對照試驗的主要排序依據(jù),若分值相同則按照樣本量進行降序。具體滿足度評判依據(jù)如表1所示。

表1 證據(jù)強度模塊各元素分值
3 證據(jù)強度模塊的驗證
為驗證本文中證據(jù)強度模塊及其評分量表的可行性,由1名研究人員在知名循證醫(yī)學數(shù)據(jù)庫DynaMed中篩選合適的隨機對照試驗文獻,并由2名著錄人員按本證據(jù)強度模塊對其進行標引。本文選取了世界衛(wèi)生組織(WHO)全球健康觀察(GHO)數(shù)據(jù)中死亡原因前3位的疾病,即缺血性心臟病(Ischaemic heart disease)、中風(stroke)、慢性阻塞性肺疾病(chronic obstructive lung disease)[13]。在DynaMed中查看對應的主題“Coronary artery disease (CAD)”“stroke(acute management)”“COPD”,并選擇其中有明確證據(jù)分級和文獻鏈接的隨機對照試驗,篩選近10年來用手術(shù)或藥物治療以上疾病的相關(guān)文獻29篇。將這29篇文獻發(fā)給2名著錄人員進行著錄和評分。為對滿足度分值與DynaMed的證據(jù)等級進行對比,以90%、70%作為1、2、3級之間的區(qū)分比例,初步設定分值大于或等于8.1為1級,分值大于或等于6.3且小于8.1為2級,分值低于6.3為3級。以“Acute Effects of Acu-TENS on FEV1 andBlood β-endorphin Level in Chronic ObstructivePulmonary Disease”[14]一文為例,著錄結(jié)果如圖2所示。
結(jié)果顯示,22篇文獻中的證據(jù)等級與DynaMed一致,另7篇文獻與DynaMed不一致。具體評分結(jié)果如表2所示。通過SPSS軟件對兩組等級數(shù)據(jù)進行kappa檢驗,結(jié)果為0.510,為一般一致性。
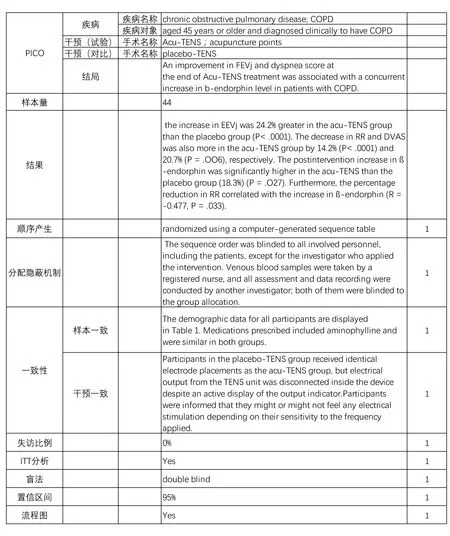
圖2著錄樣例
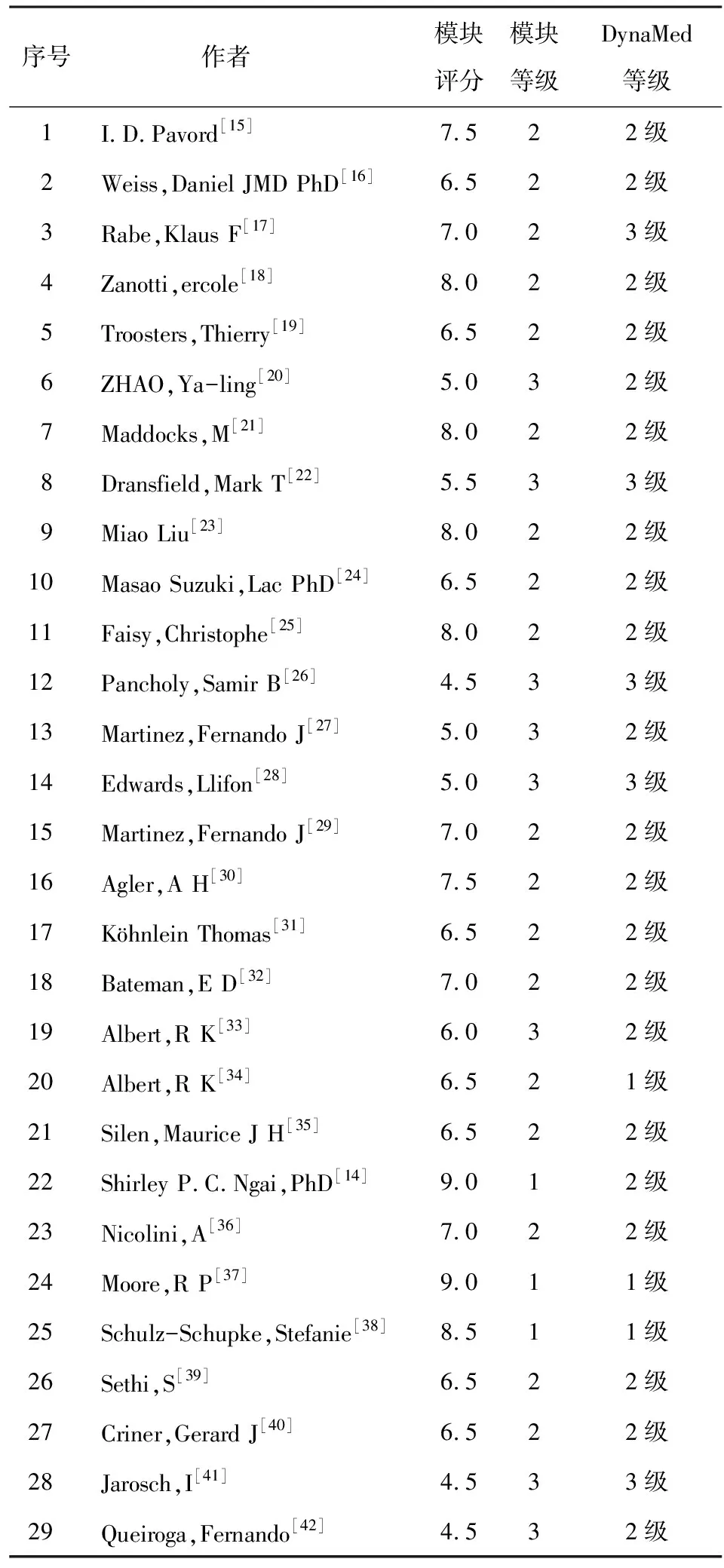
表2 29篇隨機對照試驗的評分與比較
4 討論與結(jié)論
循證醫(yī)學數(shù)據(jù)庫信息模型的證據(jù)強度模塊由疾病名稱、疾病對象、手術(shù)名稱、藥物名稱、結(jié)局、順序產(chǎn)生、分配隱蔽機制、盲法、樣本一致、干預一致、失訪比例、ITT分析、置信區(qū)間、結(jié)果、樣本量、流程圖等數(shù)據(jù)元構(gòu)成。其中對部分與證據(jù)評價密切相關(guān)的數(shù)據(jù)元進行滿足度評價,如順序產(chǎn)生、分配隱蔽機制、盲法、樣本一致、干預一致、失訪比例、ITT分析、置信區(qū)間、流程圖,并通過DynaMed數(shù)據(jù)庫中的隨機對照試驗進行驗證。由表2可知,該模塊中對于證據(jù)強度的評判與DynaMed基本一致,這些數(shù)據(jù)元的滿足度能夠在一定程度上反映證據(jù)質(zhì)量。在今后的循證醫(yī)學數(shù)據(jù)庫構(gòu)建中,可憑借隨機對照試驗的滿足度對文獻進行初步證據(jù)評價,按滿足度由大到小的順序?qū)⒆罴炎C據(jù)推薦提供給醫(yī)務人員,幫助醫(yī)務人員用最少的時間獲取最有價值的證據(jù),支持臨床循證的實施。在驗證過程中,有少數(shù)文獻的證據(jù)評價與DynaMed不完全一致。筆者分析后發(fā)現(xiàn),有以下原因。首先,本模塊評級只針對隨機對照試驗,而DynaMed的評級包括除隨機對照試驗在內(nèi)的其他類型文獻,因此在內(nèi)容及標準上存在一定偏差;其次,DynaMed評價中考慮到樣本量因素,多篇評價中提及“small sample size(小樣本)”。筆者認為樣本量的計算及評價較為復雜,“樣本量”這一數(shù)據(jù)元暫不納入目前的質(zhì)量評價而是作為次要排序依據(jù),在滿足度相同時進行二次排序。
由于已經(jīng)過評級的隨機對照試驗全文較難獲取,本文中能夠獲取到的文章有限,進行驗證的樣本量不夠大。下一步的研究將增加著錄和評價的文獻數(shù)量,并進一步使用更科學的統(tǒng)計學方法對該模塊進行驗證。在元素提取方面只針對隨機對照試驗這類文獻不夠完善,今后可增加系統(tǒng)綜述的PRISMA標準與其他嚴格評價標準,提取與系統(tǒng)綜述或Meta分析相對應的數(shù)據(jù)元,對證據(jù)強度模型進行補充和調(diào)整,并制定相應的評判標準,以充實和完善循證醫(yī)學數(shù)據(jù)庫的信息模型及其證據(jù)評價標準。
對于循證醫(yī)學證據(jù)的評價需要循證醫(yī)學實踐者通過各種嚴格評價工具進行綜合判斷,這一點循證醫(yī)學數(shù)據(jù)庫本身還不能完全實現(xiàn)。希望本文的證據(jù)強度模塊能夠為整個循證醫(yī)學數(shù)據(jù)庫的構(gòu)建打下基礎(chǔ),為醫(yī)務人員提供高質(zhì)量的證據(jù)。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2021年10期)2021-03-02 05:52:06
財經(jīng)(2017年15期)2017-07-03 22:40:49
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
中國教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
