融合領域特征向量的武器裝備名深度學習識別方法
2019-10-21 01:09:18雷樹杰邢富坤王聞慧
計算機應用與軟件 2019年10期
雷樹杰 邢富坤 王聞慧
1(戰略支援部隊信息工程大學洛陽校區 河南 洛陽 471003)2(青島大學外語學院 山東 青島 266000)
0 引 言
命名實體識別(Named Entity Recognition,NER)是自然語言處理任務中一項基礎性的工作,可以為自動文摘、自動問答和機器翻譯等更復雜的自然語言處理任務提供支持。對于軍事領域信息處理而言,軍事類命名實體的識別同樣起著基礎性作用,武器裝備名是軍事類命名實體的重要組成部分。
命名實體識別的難點在于對未登錄命名實體的識別,要求識別模型具有較好的泛化能力,而提升泛化能力不能僅靠擴大語料規模,尤其是對于很難獲取大規模語料的領域而言,擴大語料規模的代價大,收益不一定高。本文從挖掘利用專門領域知識入手,將領域知識與深度學習相融合,提出基于領域特征向量的武器裝備名識別方法,實驗結果顯示該方法可有效提升模型對于未登錄命名實體的識別效果。
1 相關工作
命名實體的識別研究主要受到了如CoNLL等評測會議的影響,這使得大量命名實體識別研究主要集中在人名、地名、組織機構名、時間和數字表達上[1],而對類似于武器裝備名這樣特定領域實體的識別研究明顯不足。
對于命名實體的識別,早期的識別方法大都基于規則。自20世紀90年代后,基于大規模語料庫的統計方法逐漸成為自然語言處理任務的主流。近年來,隨著人工神經網絡在圖像識別、語音識別等領域取得突破性進展,該方法也逐步應用到自然語言處理任務當中。目前,運用人工神經網絡進行命名實體識別的研究還較為有限,主要有:文獻[2]使用了CNN、雙向長短記憶網絡(bidirectional long-short-term memory,Bi-LSTM)和CRF的聯合模型對命名實體進行了識別,在采用預訓練向量作為模型輸入的情況下,在對英文命名實體的識別中取得了最好的效果;文獻[3]采用BiLSTM+CRF模型對社交媒體上的命名實體進行了識別,該模型采用預訓練的詞向量、基于字符的詞向量和句法特征向量作為模型輸入,有效克服了社交媒體信息噪音多、句子過短的不利因素;文獻[4]采用融合了依存句法信息的圖卷積神經網絡(Graph Convolutional Network,GCN)對命名實體進行了識別,在OntoNotes 5.0數據集上取得了較好的效果;文獻[5]在中文上訓練了基于字的詞向量,并與基于上下文的詞向量一起作為模型的輸入,得到了優于SVM模型和CRF模型的識別效果;文獻[6]將詞向量與詞性向量作為DNN的輸入來對命名實體進行識別,取得了較好的效果。
綜合而言,人工神經網絡使得命名實體識別效果有了一定程度的提升,但對未登錄命名實體的識別效果仍然不佳。目前仍存在兩點主要不足:首先,該方法對語料規模有一定的要求,如語料規模太小,會嚴重影響模型的識別效果,而對于特定領域實體識別任務而言,大規模且帶有實體標注信息的語料獲取往往面臨巨大障礙;其次,目前研究所采用的識別特征主要集中在詞形、詞性和句法特征上,對特定領域實體的領域特征知識挖掘和運用明顯不足,而特定領域實體往往具有較為明顯的領域特征,可以用來支持對特定實體的識別,也可以一定程度上彌補語料的不足。
基于以上問題,本文重點從特征層面對已有模型進行改進。首先專門對武器裝備名的構造特征進行研究,提取出武器裝備名構造特征要素庫,并基于大規模語料預訓練得到詞向量與特征向量,并將二者組合在一起作為Bi-LSTM+CRF模型的輸入。實驗結果顯示,本文的方法對特定領域命名實體的識別效果有著較大的提升作用,一定程度上克服了現有識別模型的不足。
2 英文武器裝備名構造模式與特征
2.1 概 述
武器裝備是武裝力量用于實施和保障戰斗行動的武器、武器系統和軍事技術器材的統稱,通常分為戰斗裝備和保障裝備。戰斗裝備是指在軍事行動中直接殺傷敵人有生力量和破壞敵方各種設施的技術手段,如槍械、火炮、坦克以及其他裝甲戰斗車輛、作戰飛機、戰斗艦艇、彈藥、導彈、水雷等。保障裝備是為了有效使用戰斗裝備所必需的軍事技術器材,如雷達、聲吶、通信指揮器材、軍用測繪器材、野戰工程機械、軍用車輛、保障艦船、輔助飛機、情報處理裝備、電子對抗裝備等。武器裝備名可分為類名與具體名兩類:類名是指某一類武器裝備名的統稱,例如槍(gun)、戰斗機(fighter)、戰艦(warship)等;具體名則專指某一款具體的武器裝備名稱,如“F-35A”、“M1”、“J-20”都屬于具體名。從軍事領域自然語言處理任務需求分析,無論是武器裝備的類名還是具體名都是重要的軍事領域專有信息,都應作為武器裝備名稱予以分析研究。
2.2 構成要素與類型
本文通過維基百科等渠道收集整理6 402條武器裝備名稱,并基于名稱實例及命名特點,對英文武器裝備名的構造特征進行了研究。
針對英文武器裝備名的總體命名特點,本文對武器裝備名的描述分為兩層:第一層是對武器裝備名的總體性描述;第二層是對各總體性描述要素的具體劃分。每一個英文武器裝備名都可以用該分類體系進行描述。
第一層分類將武器裝備名分為型號(A)、別稱(N)、描述(P)和縮寫(R)四類。第二層分類將第一層分類中的型號(A)做進一步區分,區分為系列E和具體型號V;第二層分類對第一層分類中的描述(P)也做了具體區分,如表1所示。

表1 描述類要素及舉例
2.3 構造特征
在上述分類體系下,英文武器裝備名的每一個內部構成成分都能找到其對應的分類。基于此分類體系,本文對收集整理的6 402條英文武器裝備名進行人工標注,分析了每一條名稱的構造模式與特征,并對標注后的結果進行了統計分析。表2是本文對武器裝備名的部分標注結果。表3是對武器裝備名構造模式的統計結果。
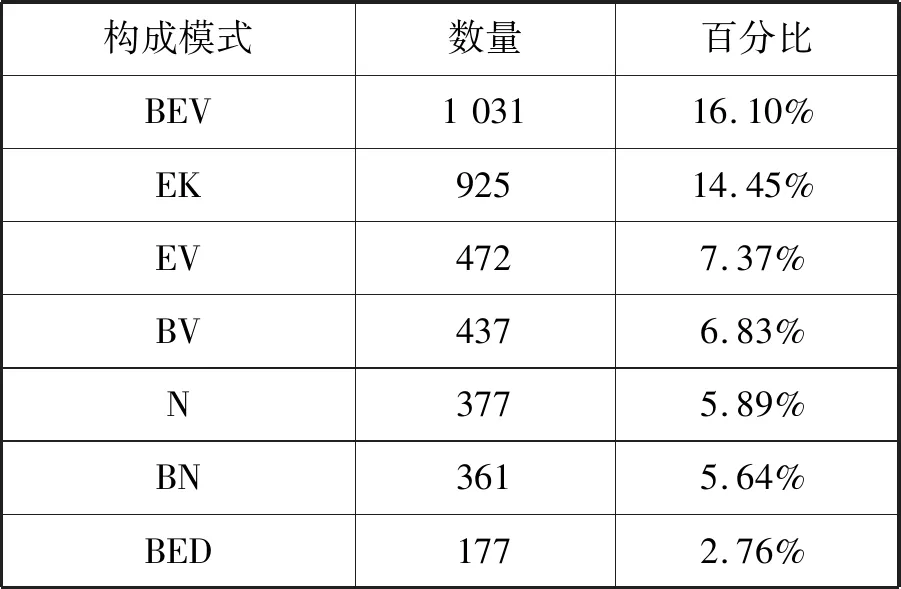
表3 武器裝備名構成模式統計結果
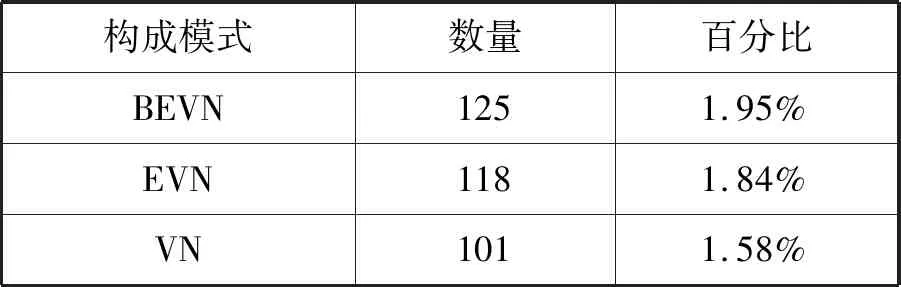
續表3
統計結果顯示,英文武器裝備名構造規律明顯:其構成成分類型相對有限,其構造模式相對集中穩定。具體來講,英文武器裝備名的構成成分類型在本文的分類體系下只有19種,而64.41%的武器裝備名的構造模式集中在10個主要構造模式上。這表明本文針對英文武器裝備名構建的兩層分類體系具有很強的描述能力,也反映出英文武器裝備名具有明顯的領域特征,且該領域特征是自動識別的重要依據,可以用來提高模型的類型泛化能力和約束能力。
2.4 識別框架
在前期調查基礎上,本文得到了英文武器裝備名的構造特征要素庫,訓練了特征向量,并以該特征向量與詞向量一起作為BILSTM+CRF模型的輸入進行訓練和識別。本文整體訓練和識別框架如圖1所示。
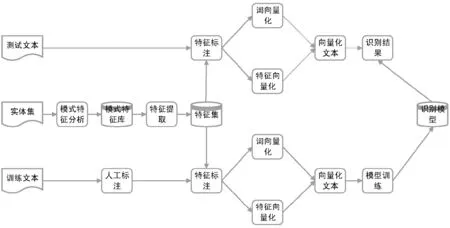
圖1 武器裝備名識別框架
3 Bi-LSTM+CRF模型
近年來,神經網絡在人工智能領域進展迅速,并逐步應用到自然語言處理任務當中。根據模型的不同架構和處理流程,人工神經網絡可以分為RNN、CNN等。這些神經網絡模型因架構的不同,使得其適用的任務類型也不同。其中,RNN因為能處理長序依賴的問題(如自然語言中的上下文)而被廣泛應用到自然語言處理任務當中。但RNN容易出現梯度彌散和梯度爆炸問題[7],而LSTM模型[8]可以很好地解決這個問題。Bi-LSTM則是對LSTM的改進,通過從正向和反向兩個方向利用上下文信息來進一步提升模型對長序依賴問題的處理能力。
本文采用Bi-LSTM+CRF模型作為命名實體訓練和識別模型,并將預先由維基語料與表1所示的武器裝備名構造要素特征庫訓練而來的領域特征向量融入到模型當中,以解決現有模型對特定領域的領域特征挖掘不足與傳統的神經網絡需要大規模訓練文本的缺陷。
3.1 模型整體框架
本文模型整體上由輸入層、Bi-LSTM層、輸出層和CRF層組成,各層之間的數據處理流程如圖2所示。
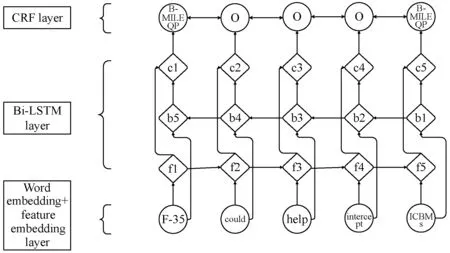
圖2 模型整體框架
3.2 Word Embedding+Feature Embedding模塊
本文采用預訓練的詞向量和預訓練的特征向量作為模型的輸入,并使用Python的Gensim開源工具包對詞向量與特征向量進行預訓練。
Word2vec是神經概率語言模型的一種實現,其中包含了CBOW與Skip-gram兩種模型。Word2vec可以在構建神經概率語言模型的同時得到詞所對應的詞向量。其中,CBOW模型是通過上下文來預測當前詞,而Skip-gram則是通過當前詞來預測上下文。來斯惟[9]在2016年證明:當用于訓練詞向量的語料規模達到百兆級時,CBOW模型要好于Skip-gram模型。本文用于訓練詞向量的語料規模超過了600 MB,為此,采取CBOW模型來訓練得到詞向量。
詞向量方面,通過對來自維基百科的大規模無監督語料Cwiki進行訓練,本文得到了各個詞所對應的詞向量記為V={word1:vector1,word2:vector2,…,wordn:vectorn}。
特征向量方面,本文在前期調查得到的構造特征要素庫Kf(Kf的獲取過程見4.1)的支持下,采用動態規劃算法對來自維基百科的大規模無監督語料Cwiki進行標注,將每一個詞轉化為其對應的特征要素(沒有相應特征要素的詞則被轉化為“O”),形成了與Cwiki相對應的特征要素語料Cwiki-feature。以特征要素語料Cwiki-feature為訓練集,本文得到了每一個特征要素所對應的特征向量Vf={feature1:fvector1,feature2:fvector2,…,featuren:fvectorn}。由于特征向量Vf的訓練也是通過Word2vec(采用了CBOW模型,因為轉換后的特征要素語料Cwiki-feature超過了400 MB)處理,所以每一個特征向量能夠很好地表示該特征要素的上下文,也就是本文在前期武器裝備名構造特征調查中得到的構造模式。因此相較于直接給每個特征要素賦予一個特定向量值而言,這種特征向量獲取模式能更好地將本文前期調查得到的領域特征融合到模型中。
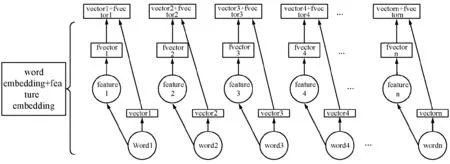
圖3 模型的輸入:詞向量+特征向量
3.3 Bi-LSTM模塊
本文采取了Bi-LSTM模型,并通過調用TensorFlow平臺的內置代碼庫對模型進行了實現。
相較于RNN而言,LSTM模型增加了記憶單元和遺忘機制。其中,輸入門決定什么值會被更新,遺忘門決定什么信息會被遺忘,而輸出門則決定什么信息會被輸出。這樣的記憶單元與遺忘機制使得LSTM模型在處理長序依賴問題上有著出色的表現。LSTM架構如圖4所示。
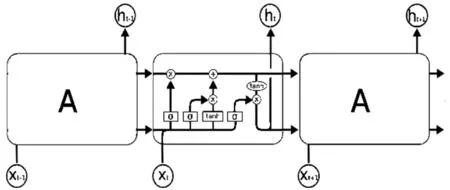
圖4 LSTM模塊
3.4 CRF模塊
為了彌補Bi-LSTM模型在序列標注任務上的缺陷,本文在Bi-LSTM之上增加了CRF層,通過TensorFlow平臺的內置代碼庫將輸出層的損失函數由softmax函數替換為CRF函數。
CRF模型由J.Lafferty等在2001年提出,其定義的條件概率表示為:
(1)
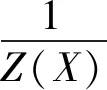
由于CRF模型去除了隱馬爾可夫模型(Hidden Markov Model,HMM)中不合理的輸出獨立性假設,使得CRF模型能夠很好地利用整個序列內部的信息和外部觀測信息,很好地解決了在HMM、最大熵馬爾可夫模型(Maximum-Entropy Markov Model,MEMM)中存在的標記偏置問題。CRF模型這樣的優點也使得其在序列標注任務中表現出色。
針對命名實體識別這樣一個序列標注任務,本文采用CRF模型來接受Bi-LSTM模型的輸出,將各輸出之間的轉移概率考慮進來,以此來提高模型在命名實體識別任務中的性能。
4 實 驗
4.1 實驗語料與標注集
本文收集了110篇美國國防部官方網站2017年度的新聞報道并對其中的英文武器裝備名進行了人工標注。實驗選取了其中80篇作為訓練語料Ctrain,另外30篇作為測試語料Ctest。
在對110篇新聞報道完成標注后,本文抽取出80篇訓練語料Ctrain所包含的英文武器裝備名,并利用上文所述的兩層分類體系對這些武器裝備名進行人工標注。標注完成后,本文統計總結了這些武器裝備名的構成成分和構造模式,做成包含(構成成分-構成成分類型)對的領域詞典作為構造特征集,并將該構造特征集充實到上文調查所得的構造特征集中,形成了構造特征要素庫Kf,如表4所示。Kf作為包含英文武器裝備名構造規律的知識庫參與到對武器裝備名的識別中。
本文采用三元素標注集:{B-MILEQP,I-MILIQP,O}。其中,“B-MILEQP”表示一個英文武器裝備名的起始部分,“I-MILIQP”表示英文武器裝備名的非起始部分,“O”表示非英文武器裝備名成分。
4.2 評測標準
只有對文本當中一個完整武器裝備名的各個部分全部標注正確并且對該武器裝備名的后一個其他成分沒有標注為“I-MILIQP”,本文才視為對該武器裝備名識別成功,部分標注正確或標注超出了該武器裝備名的界限則視為標注失敗。
為了更加全面地描述實驗效果,本文設置了六個評價指標,各個指標定義如表5所示。
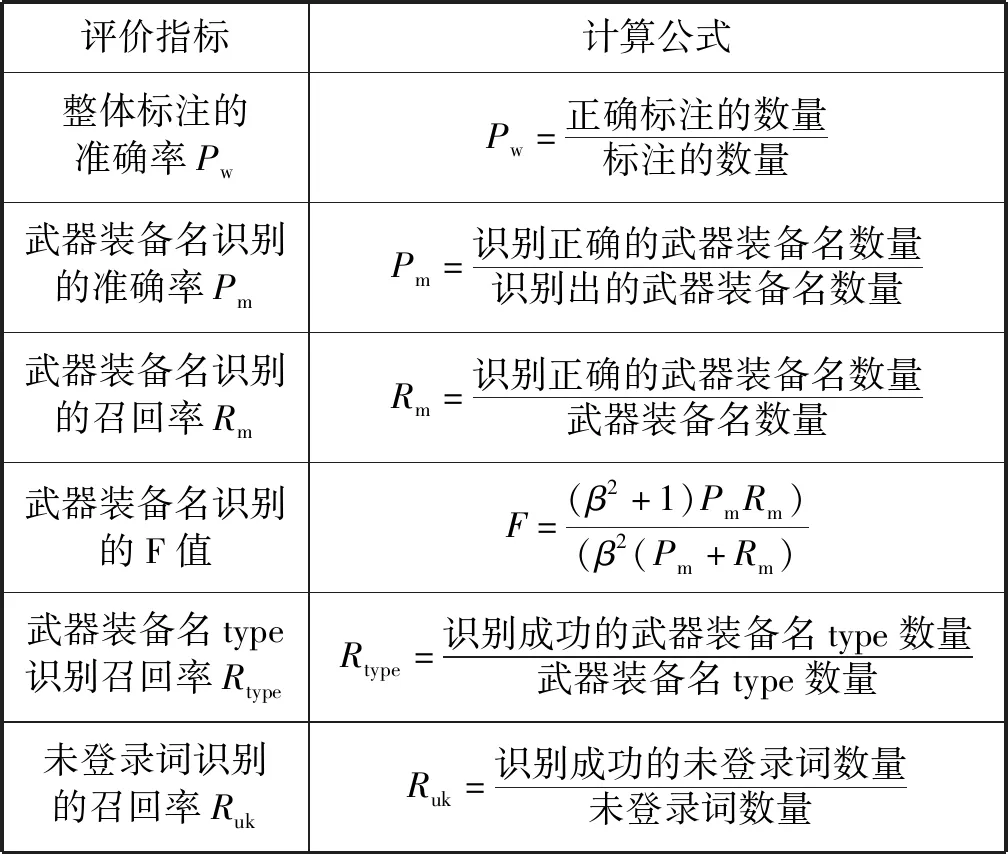
表5 評價指標
其中:整體標注的正確率Pw用來評價模型對整體文本的標注情況;武器裝備名識別的準確率Pm與召回率Rm用來評價模型對武器裝備名的識別情況;F值則用來綜合評價模型對武器裝備名的識別情況;為了排除模型對某一特定武器裝備名多次識別成功或失敗所造成的對總體評價指標的影響,本文設置了武器裝備名type識別的召回率Rtype這一指標,在這一指標下,對同一武器裝備名的多次識別成功只計算一次;而未登錄詞識別的召回率Ruk則用來評價模型對未登錄詞的泛化能力。
4.3 模型參數與特征
4.3.1預訓練詞向量與特征向量模型的參數設置
本文采用Google在2013年開發的Word2vec對來自維基百科的大規模無監督語料Cwiki進行訓練。本文采用了CBOW模型,模型窗口大小設置為5,即用當前詞的上下文各五個詞共同表示當前詞;模型的詞頻閾值設置為1,即對語料中每一個出現的詞都賦給一個詞向量,由此得到了一個40萬詞級的詞向量集。對于特征向量的訓練,本文采取了與詞向量訓練相同的參數設置,得到了規模為140的特征向量集。
對于向量維度的選擇,本文對詞向量分別設置了{50, 100, 200}三個維度,對特征向量分別設置了{10, 25, 50}三個維度。本文將詞向量與特征向量的三個不同維度進行組合,通過多次實驗,得到了詞向量與特征向量的最佳維度組合:50維詞向量+10維特征向量。
4.3.2Bi-LSTM+CRF模型的參數設置
本文的輸入層維度為相應的輸入向量的維度(單獨使用詞向量為50維,使用聯合向量為60維),隱藏層的維度為128維。
受文獻[3,10]的啟發,考慮到Adam優化算法能夠在得到較好訓練效果的前提下更快地收斂,因此本文采用Adam函數作為模型的優化算法。其中,learning rate設置為0.01,gradient clip設置為5.0。
為了避免過擬合現象,在訓練過程中進行了正則化處理,設置dropout參數為0.5,即對每次輸入的訓練數據隨機去除50%,實驗結果也證明了進行正則化處理的有效性。
此外,將訓練的batch size設置為32,Bi-LSTM模型的輸入步長(即一次訓練輸入的詞數)設置為訓練數據集中的最長句子長度Lmax。對于長度不足Lmax的句子,在訓練時將其通過零向量補全,使得其長度達到Lmax。因此,本文的訓練是對每一句話進行的,這樣做的目的是為了更好地利用每一個句子的語義,為識別提供支持。
4.3.3CRF模型的特征選取
在自然語言處理領域,CRF模型被廣泛使用在命名實體識別領域,其主要思想是將命名實體識別任務轉化為線性序列標注任務。在實際使用中,模型使用的特征基本限定為詞形、詞性等淺層語言特征。但在特定領域中,詞性這樣的淺層語言學特征往往不能反映更深層的領域特征,從而造成了關鍵識別特征信息缺失,影響模型的識別效果。
本文通過對英文武器裝備名的內部構成特征進行調查,形成了如表1所示的武器裝備名構造特征要素庫,從而可以將武器裝備名更深層次的領域特征融入到模型當中。本文使用CRF++開源工具包進行實驗,并對CRF與Bi-LSTM+CRF模型的實驗結果進行了比較。
4.4 實驗設計及結果分析
4.4.1實驗設計
實驗分為兩個部分,第一部分分別使用輸入為詞向量V的Bi-LSTM+CRF模型和輸入為聯合向量Vunion的Bi-LSTM+CRF模型對武器裝備名進行了識別。通過將輸入為詞向量V的Bi-LSTM+CRF模型和輸入為聯合向量Vunion的Bi-LSTM+CRF模型的識別效果進行對比,證明特征向量對于模型識別效果的提升作用。
實驗第二部分是將構造特征要素庫Kf中每個詞對應的特征要素類型作為CRF模型的特征標簽來對武器裝備名進行識別。對于不在特征要素庫中的詞,則其特征標簽為“O”。通過比較融入了英文武器裝備名特征要素的CRF模型與融入了英文武器裝備名特征向量的Bi-LSTM+CRF模型的識別效果,發現Bi-LSTM+CRF模型并不是在任何情況下都優于CRF模型。
4.4.2實驗結果與分析
本文得到的實驗結果如表6所示。
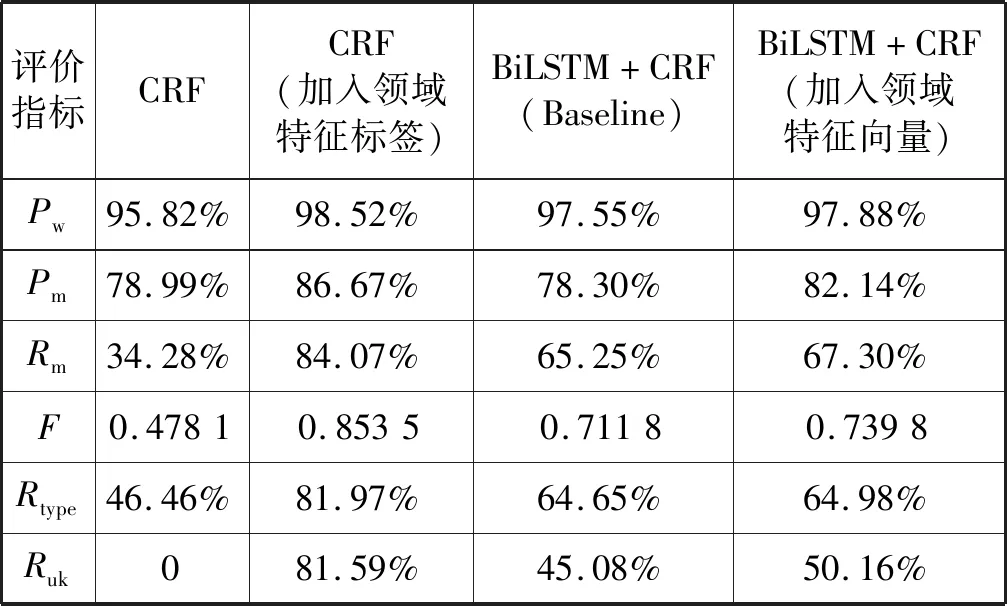
表6 實驗統計結果比較
對于第一部分實驗,通過實驗結果可以看出,Bi-LSTM+CRF模型在絕大多數指標上都相較于CRF模型都有著較大提升,這說明使用詞向量的Bi-LSTM+CRF模型對武器裝備名識別的有效性。其中:武器裝備名識別準確率Pm相較于CRF模型有0.69%的下降,但召回率卻提升了超過30.97%;在Rtype指標上,Bi-LSTM+CRF模型也相較于CRF模型有著18.19%的提升,這說明前者有著較強的類型泛化能力;此外,Bi-LSTM+CRF模型對未登錄武器裝備名識別的召回率Ruk的提升是根本性的,達到了45.08%,這進一步證明使用詞向量的Bi-LSTM+CRF模型較強的類型泛化能力。綜合來看,使用詞向量的Bi-LSTM+CRF模型相較于CRF模型有著相當的提升效果。這一方面是Bi-LSTM+CRF模型本身的優勢,另一方面也得益于包含了一定語義信息的詞向量。這兩個因素共同作用,使得Bi-LSTM+CRF模型相對CRF模型而言有了一個根本性的提升。
在Bi-LSTM+CRF模型內部來看,使用聯合向量使得Pm提升了近3.84%,Rm提升了2.05%,這證明了特征向量的有效性,也證明單純的詞向量并不能容納一個詞全部的語義信息,詞向量對特定領域特征的描述還有欠缺。此外,使用聯合向量也使得Ruk有了超過5%的提升,這證明隨著特征向量的加入,模型對未登錄武器裝備名的泛化能力也隨之提升。如:由于“F-35A”未在訓練文本中出現,屬于未登錄武器裝備名,單純使用詞向量并沒有將該武器裝備名識別出來,但當加入該詞條對應的特征向量后,該詞條就被成功地識別了出來,這樣的例子還有“P-8A”、“Bradley fighting vehicles”等;而“stealthy(隱形的)”由于經常形容戰斗機,因此單純使用詞向量時,模型錯誤地將該詞條識別為武器裝備名,但當加入該詞對應的特征向量后,該詞就沒有被識別為武器裝備名,類似的例子還有“hardened”等。
對于第二部分實驗,通過實驗結果可以看到,加入領域特征標簽的CRF模型在各個指標上均好于加入了領域特征向量的Bi-LSTM+CRF模型,其中在召回率上CRF模型超出Bi-LSTM+CRF模型16.77%,在對未登錄武器裝備名識別的召回率上CRF模型更是超出Bi-LSTM+CRF模型31.43%。這樣的實驗結果顯示了CRF模型對稀疏特征的利用遠勝Bi-LSTM+CRF模型。武器裝備名在語料中分布稀疏,這導致武器裝備名的領域特征要素在文本中也比較稀疏,這樣的特點就要求模型能夠充分利用一些稀疏特征來進行識別,尤其是在語料較少的情況下,更要求模型能充分利用稀疏特征。實驗結果表明,雖然Bi-LSTM+CRF模型在很多方面超過了CRF模型,但在利用稀疏特征這一方面,Bi-LSTM+CRF模型還有待進一步提升。
5 結 語
本文首先對抽取自維基百科的6 402條英文武器裝備名進行了構造模式特征分析,得到了武器裝備名的構造特征要素庫,并在來自維基百科的大規模無監督語料上預訓練了詞向量與特征向量。在此基礎上,本文設計了兩部分實驗,分別證明了特征向量對Bi-LSTM+CRF模型的提升和CRF模型在對稀疏特征的利用上要優于Bi-LSTM+CRF模型。同時也證明了詞向量難以表示更深層次的領域知識,對特定領域進行專門的語言學研究具有很大的必要性。
本文更大的意義在于:研究證實了對于很難獲取大規模語料的特定領域而言,可以通過對該領域領域知識的研究,并將該領域知識加入到統計模型當中,以對領域知識研究的深度來彌補語料的不足,從而提高模型的類型泛化能力和約束能力,獲得更好的識別效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年19期)2016-08-11 08:17:03
