一種基于SVM及文本密度特征的網頁信息提取方法
2019-10-21 01:09:26周艷平李金鵬宋群豹
計算機應用與軟件 2019年10期
周艷平 李金鵬 宋群豹
(青島科技大學信息科學技術學院 山東 青島 266061)
0 引 言
如今,在網絡信息飛速增長的時代,網絡信息變得越來越重要,它影響著人類學習、工作、生活等各個方面。然而,網頁通常包含非主題信息,如導航、廣告鏈接、版權信息等, 我們稱之為噪音信息。 在網頁上的正文信息通常與不相關的內容混雜在一起,這導致網頁信息的可利用性大大降低[1]。當對Web頁面信息再次分析或開發利用時,往往會有頁面上的噪音信息。如何準確有效地提取文本信息已成為當前研究領域的一個重要課題。
現有的網頁正文抽取的方法可以分為四類:基于包裝器和啟發式規則的信息提取方法,基于文本特征的信息提取方法,基于視覺分塊的信息提取方法,基于統計和機器學習的信息提取方法。
(1) 基于包裝器和啟發式規則的信息提取方法。該方法是一種早期且流行的方法,后續的Web模板提取技術也屬于這一類。 其原則是通過構造包裝器或Web模板規則從Web信息源中提取符合規則的信息[2-3]。該方法在特定格式信息源中的提取有很好的準確率,但在當前互聯網頁面越來越多樣化、越來越復雜的趨勢下,該方法并不是通用的。
(2) 基于文本特征的信息提取方法。 該方法通過網頁結構和文本特征將網頁劃分為文本塊和鏈接塊。通過使用連續出現的噪聲塊的結果來完成文本部分的位置,得到網頁正文信息[4-5]。該方法比傳統的基于包裝的提取方法更簡單實用。但對于某些多主題網頁的抽取,該方法無法正確地對正文進行定位,從而影響了準確率。
(3) 基于視覺分塊的信息提取方法。該算法受人眼視覺啟發,對人視覺處理信息進行模擬,并結合DOM樹對網頁進行文本分塊,最后從文本塊中定位到正文塊,達到提取正文的目的。該方法考慮了包含文本的DOM節點的結構。與傳統算法相比,該算法的精度有了一定的提高,但計算量大,實現難度較大。
(4) 基于統計和機器學習的信息提取方法。該算法通過對樣本網頁的文本分布和節點特征進行統計分析,建立模型規則,并通過不斷學習對模型參數進行改進,從而在一定程度上實現自適應。文獻[7]根據網頁的顯示屬性對網頁文本進行分組,根據顯示屬性值對網頁文本進行分類,獲取相關文本,從而完成網頁的信息提取。目前,網頁的復雜性和非標準化程度越來越高。僅將屬性值作為訓練特征使用會導致某些網頁無法正確識別或特征遺漏。
本文提出了一種基于SVM和文本密度的網頁信息提取方法。 根據網頁的特點和文本信息塊周圍標簽的特點,提出了五種密度特征。使用分類效果比較高的監督學習分類器SVM進行正文信息塊篩選處理。實驗證明,該方法不僅有較高的精度,而且通用性好。
1 文本塊處理
網頁按內容可分為三類:主題型網頁,Hub網頁和多媒體網頁[11]。下面分別給出定義:
(1) 主題型網頁:以段落形式描述一個或多個主題的網頁,很少或甚至沒有圖片、視頻和鏈接。鳳凰新聞網是一個典型的主題網頁。
(2) Hub網頁:通常它不描述事物,但提供相關頁面的超鏈接,例如hao123的主頁。
(3) 多媒體網頁:這種網頁的內容通過圖片,視頻等體現,而文本只是對它們的描述,如電影天堂。
本文是以主題網頁為主開展研究工作。
1.1 網頁預處理
為了提高處理效率,在構建DOM樹之前,應先刪除網頁中如 HTML注釋及腳本等噪音信息。本文采用正則表達式來過濾噪音信息,噪音信息如表1所示。

表1 噪音信息
1.2 文本塊抽取
在網頁的DOM樹中,容器標簽如
、
- 、
- 、
- 、
- 、
- 等之間的文本內容(不包括標簽本身)稱為“文本塊”,它可以嵌套在其他文本塊中,也就是說,文本塊可以包含多個子文本塊。 包含正文內容的文本塊稱為正文塊,沒有正文內容的文本塊稱為噪聲塊[12]。
大量研究發現正文節點一般分布在DOM樹的葉節點中。 因此,采用DOM樹的深度優先遍歷來分析葉子節點中的信息。步驟如下:
(1) 深度優先遍歷DOM樹,從葉子節點開始,找到最底層的第一個容器標簽,讀取該節點信息加入文本塊隊列,并標記已訪問。
(2) 判斷葉子節點有未被訪問的兄弟節點,若有則讀取節點信息加入文本塊隊列,并標記已訪問。若無則讀取父節點信息,若父節點未被訪問,并且不是body節點,則重復(1)過程。直到將所有的節點都訪問,輸出文本塊隊列。
2 SVM文本塊分類
在本文中,去噪被認為是二元分類問題,即正文塊和噪音塊。在實驗中,SVM用于解決二元分類問題。 假設在n維空間中定義了訓練集,正類表示正文塊,負類表示噪聲塊。選擇了可以區分正文塊和噪音塊的五個重要特征屬性,即可以訓練出五維的特征屬性矩陣。
2.1 文本特征標注
文本塊特征會直接影響SVM的分類效果,通過分析網頁結構發現,雖然各個網站的風格有差異,但主題網站的結構是很相似的。通過使用數學模型分析其組成并計算其比例,形成具有不同含義的特征文本的密度值。本文使用五種密度值進行特征標注,分別如下:
(1) 超鏈接密度:“超鏈接”形式的文本長度與文本塊總長度的比例稱為文本塊的超鏈接密度,其公式為:
(1)
式中:HLL為超鏈接文字長度,AL為文本塊包含的文字總長度。諸如廣告、友情鏈接、目錄和導航之類的大量“網絡噪聲”通常以“超鏈接”的形式存在,并且與正文內容在不同文本塊中。 也就是說,文本塊中超鏈接的密度越高,該文本塊屬于噪音塊的概率就越大。
(2) 噪音詞密度:通常用于標識網站自身的功能,與頁面正文內容無關的詞語數量,(如“首頁”、“搜索”、“聲明”、“版權”、“幫助”等)與整個文本塊詞語數量之比,稱為該文本塊的噪音詞密度,其公式為:
(2)
式中:NWC是文本塊中有噪音的詞語的數量,AWC是文本塊中的詞語總數。 噪音詞的出現并非偶然。 通過對大量網頁的研究,發現文本塊中的噪音詞的比例越高,該文本塊是噪音塊的概率越大。本文通過哈爾濱工業大學信息檢索研究中心開發分詞工具來對文本塊內容進行分詞處理,并提取出詞語信息來進行計算。
(3) 中文標點密度:在某一文本塊中,中文標點與文本塊內字符總長度之比,稱為該文本塊的中文標點密度,其公式為:
(3)
式中:SCL是文本塊中中文標點的數量,ACL是文本塊中字符的總數量。通過對網頁的研究和分析,發現網頁文本通常分段顯示。 段落通常包含標準標點符號,而網頁中的噪音信息通常不包含或僅包含一個標點符號。
(4) 文本修飾標簽密度:“strong”、“b”、“I”、“h1”、“h2”、“u”等修飾文字的標簽稱為文本修飾標簽。某一文本塊中,文本修飾標簽數量與文本塊中所有標簽數量之比,稱為該文本塊的文本修飾標簽密度,其公式為:
(4)
式中:LC為文本塊包含的文本修飾標簽的數量,ALC為文本塊中所有標簽的數量。文本修飾標簽對文本的內容進行裝飾,增加文本的可讀性,通常修飾標簽會在正文中體現。
(5) 網頁區域密度:在整個HTML中,正文文本塊通常集中在網頁的某個區域位置,稱為該正文文本塊的網頁區域密度,其公式為:
(5)
式中:NS為該文本塊容器標簽所在的節點序數,ANS為整個DOM樹的節點總數。經過大量的研究發現,正文容器標簽的區域密度通常在18%~55%范圍內,這對我們進一步判斷正文文本塊有很大的參考價值。
2.2 數據模型訓練
本文從網易、新浪、人民網等主題網站隨機提取10個頁面作為訓練網頁,通過特征提取器針對2.1節提出的五種密度特征來提取,并且人工標注文本塊的類別(-1:噪音塊、1:正文塊)。針對訓練期間所出現的問題,文本通過以下方法解決:
(1) 數值歸一化處理。為了讓結果更加準確,在處理不同取值范圍的特征值時,通常采用數值歸一化方法,本文將任意取值范圍的特征值轉化為(0,1)區間內的值,公式如下:
(6)
式中:newValue為特征值數值歸一化后新的值,oldValue為原始特征值,max和min分別是數據集中的最小特征值和最大特征值。
(2) 確定訓練矩陣。將上述五個特征屬性用作輸入參數,得到訓練矩陣。
(3) 選擇核函數。核函數的作用就是隱含著一個從低維空間到高維空間的映射,而這個映射可以把低維空間中線性不可分的兩類點變成線性可分的。SVM中常用的內核函數有四種:線性核函數,高斯核函數,多項式核函數,感知核函數[13]。多實證應用表明高斯核函數(RBF)SVM具有良好的學習能力,其公式如下:
(7)
式中:σ為核函數的參數,需要人工根據經驗調整。
(4) 調參方法。在模型中,有兩個超參數分別是懲罰系數C和RBF核函數的系數σ是需要人工調整的。當C越大,σ越小,核函數對x的衰減越快,這就放大了數據之間的差別,致使該模型只適用于支持向量附近,未知樣本分類效果差,訓練精度高,而測試精度不高的可能;如果C值越小,σ值越大,平滑效果越大,訓練精度不高,從而也會影響測試精度。本文使用交叉檢驗法來確定此數據模型的參數σ1、C1。
(5) 交叉檢驗法。首先把數據集分為兩部分:訓練數據集和驗證數據集;為了判斷一個模型的優秀程度,我們將模型的訓練數據集替換成驗證集進行檢驗,從而獲得驗證結果。但我們不能只對數據集進行一次分割,而是必須將其隨機分割幾次,從而每次都得到一個結果。再求所有結果的均值,就可以對訓練模型進行評估了。我們可以在其間不斷地調整模型參數,通過比較結果可以得出這個模型的最佳參數。
2.3 文本塊分類
通過SVM數據模型對文本塊進行分類,需要注意的是,這時已經完成了文本塊處理相關的工作,具體步驟如下:
(1) 先對網頁進行預處理并生成DOM樹。
(2) 遍歷DOM樹獲得文本塊并加入到隊列中。
(3) 利用特征提取器對每個文本塊進行密度特征提取。
(4) 將文本塊密度特征輸入到SVM數據模型中,返回相應結果R。
(5) 保存R>0的文本塊(R為結果值,R<0:噪音塊,R>0:正文塊)。
根據上述方法,得到正文塊的具體步驟如圖1所示。
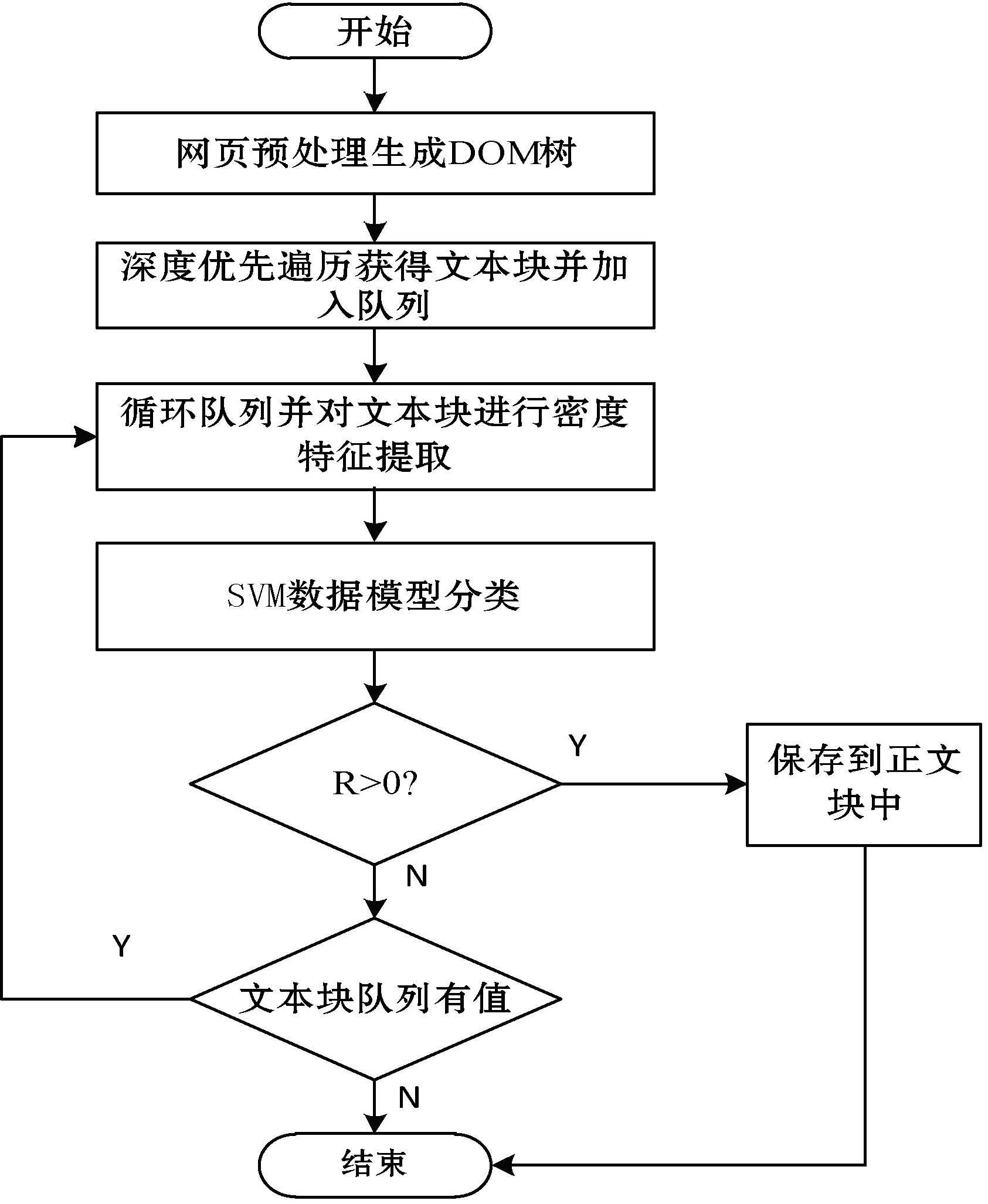
圖1 正文塊獲取步驟
3 SVM正文塊內降噪
經過上述步驟處理之后,就可以獲得正文塊。文本塊中仍有一些需要去除的噪聲信息。研究分析發現塊內噪音一般存在以下特點[12]:
(1) 噪音信息不會太長,通常只有幾個詞,而且不包含標點符號信息。
(2) 塊內噪音通常存在于正文塊的頭部或尾部,并且不會出現在混淆文本內容的段落。
根據上述特點,本文以段落為基本單位分析正文文本塊,提出“段落文字密度”,“段落標點密度”和“段落區域密度”的概念,以評估某個段落是否為塊內噪音段落。
常用的HTML分段指示標記有:
、
、、
、
、
、
、
、
、
、
、和主站蜘蛛池模板: 国产亚洲欧美日韩在线一区二区三区| 热久久国产| 亚洲最新地址| 人妻无码中文字幕一区二区三区| 永久免费无码日韩视频| 国产午夜福利亚洲第一| 99re在线视频观看| 福利国产在线| 国产日韩欧美中文| 尤物特级无码毛片免费| 成人日韩精品| 99视频在线免费看| 日韩精品无码一级毛片免费| 国产无遮挡裸体免费视频| 国产精品网曝门免费视频| 中文字幕丝袜一区二区| 欧美国产日韩另类| 国产高清在线观看91精品| 日韩在线视频网| 免费看美女毛片| 婷婷中文在线| h视频在线播放| 午夜国产理论| 亚洲不卡无码av中文字幕| 国产成人福利在线| 久久狠狠色噜噜狠狠狠狠97视色| 久久精品一品道久久精品| v天堂中文在线| 欲色天天综合网| 亚洲无线视频| 亚洲一区无码在线| 国产精品偷伦视频免费观看国产| 亚洲人成影视在线观看| 亚洲成a人片在线观看88| 亚洲第一黄色网址| 亚洲福利视频一区二区| 亚洲日韩精品综合在线一区二区 | 男女男免费视频网站国产| 又黄又湿又爽的视频| 香蕉蕉亚亚洲aav综合| 免费观看国产小粉嫩喷水| 国产成人高清精品免费软件| 亚洲色图综合在线| a网站在线观看| 国产成人一区| 在线观看精品国产入口| 国产无码网站在线观看| 国产美女视频黄a视频全免费网站| 国产毛片不卡| 国产色偷丝袜婷婷无码麻豆制服| 99久久精品免费视频| 午夜精品久久久久久久99热下载| 一本大道香蕉久中文在线播放 | 中文字幕在线一区二区在线| 欧美色综合久久| 欧美精品亚洲精品日韩专| 国产精品亚欧美一区二区| 伊人久久大香线蕉影院| 亚洲精品国产精品乱码不卞| 沈阳少妇高潮在线| 国产精品19p| 免费欧美一级| 久久99久久无码毛片一区二区| 9cao视频精品| 高清无码不卡视频| 亚洲精品日产AⅤ| 日韩毛片免费观看| 免费不卡在线观看av| 国产精品无码AV中文| 五月激情婷婷综合| 国产精品色婷婷在线观看| 欧美日韩中文字幕二区三区| 欧美日本在线播放| 亚洲 欧美 日韩综合一区| 暴力调教一区二区三区| 国产你懂得| 伊在人亞洲香蕉精品區| 欧美日本在线观看| 中文字幕日韩久久综合影院| 成人小视频网| 免费日韩在线视频| 亚洲va在线∨a天堂va欧美va|,源HTML腳本中的回車符可以忽略不計[14],這些標記對之間的文本(不再被其他標記分隔)稱為段落。 定義1(段落文字密度) 劃分某正文文本塊為若干段落,每個段落中的文字數量與整個文本塊文字數量之比,稱為該段落的段落文字密度。
定義2(段落標點密度) 劃分某正文文本塊為若干段落,每個段落中的中文標點數量與該段落的內容字符數之比,稱為該段落的段落標點密度。
定義3(段落區域密度) 劃分某正文文本塊為若干段落,每一段落所占文本塊的起始位置到終止位置的行數,稱為該段落的區域。整個區域相對于段落的位置,稱為段落區域密度。
段落區域是一個范圍值,因此我們使用均值法得到一個中間密度值作為該段落區域密度,其公式為:
(8)
式中:MIN(PC)為段落區域中最小行對應的正文塊中段落序數,APC為正文塊中段落總數,MAX(PC)為段落區域中最大行對應的正文塊中段落序數。
針對這2個特征建立SVM數據模型,參數σ2、C2是由交叉檢驗法得出,分類步驟如下:
(1) 循環遍歷圖1已經得到的正文塊隊列。
(2) 隨機選取100個段落進行特征提取,建立數據模型,將特征輸入到數據模型中訓練。
(3) 利用訓練好的數據模型來對文本塊的段落進行分類。
(4) 保存R>0的段落(R為結果值,R<0:噪音段落,R>0:正文段落)。
根據上述方法,得到正文段落的具體步驟如圖2所示。
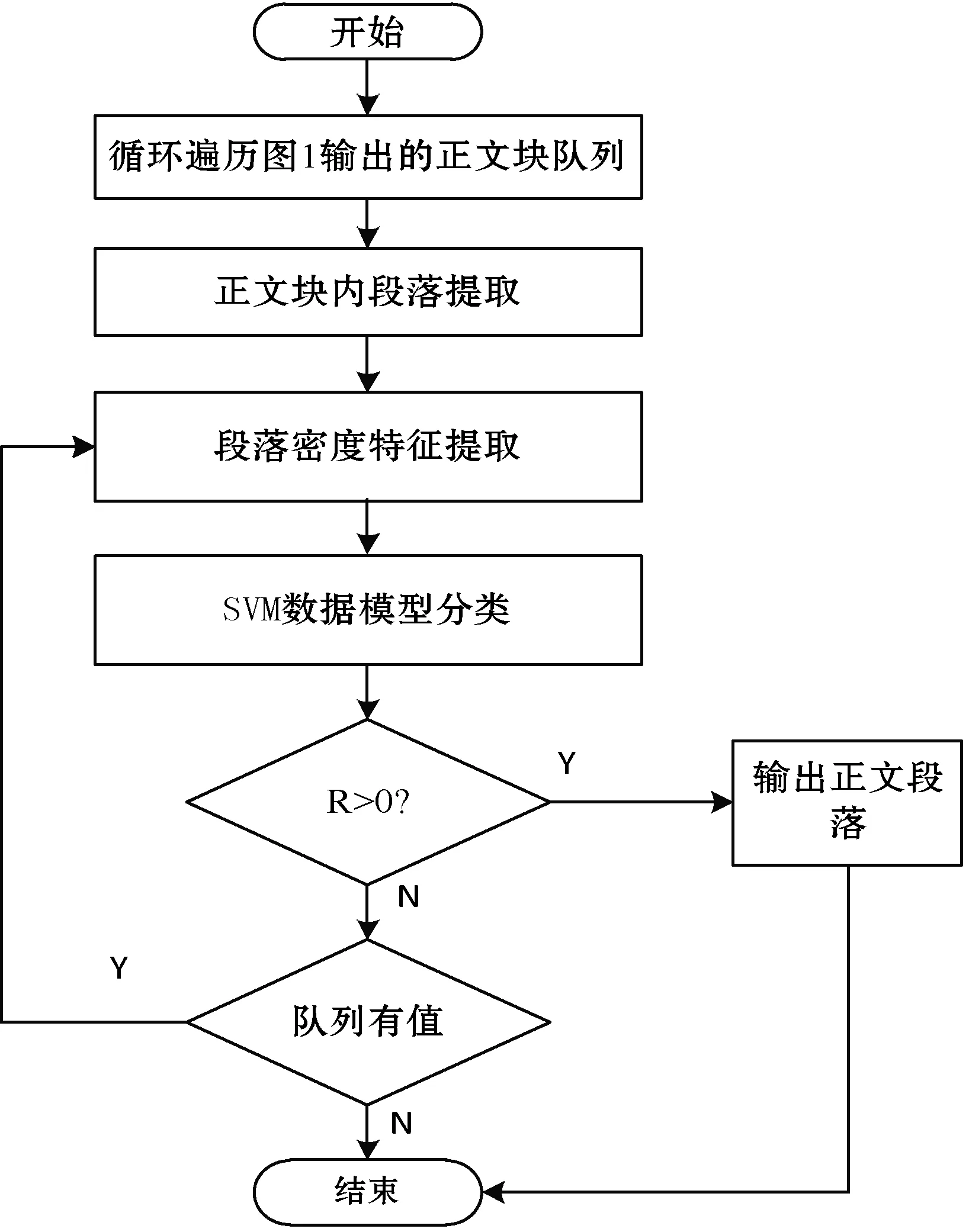
圖2 正文段落獲取步驟
4 實驗及結果分析
實驗選取互聯網中3個的主題網站:網易、新浪、人民網,和2個多主題網站:新浪博客、博客網。每個網站隨機爬取110個網頁,其中100個作為測試集,10個作為訓練集。訓練集需要進行人工標注和整理,并將每個網站的訓練集隨機分成2個驗證數據集和8個訓練數據集。
實驗環境是Windows7 X64,開發工具為PyCharm4.5.4,anaconda4.4.0,選用機器學習開發包sklearn進行開發。本文使用sklearn中的網格搜索,即GridSearchCV類實現調參工作。實驗證明,將SVM文本塊分類和SVM文本塊內降噪的高斯核函數參數σ1、σ2分別設定為1.6、1.2。懲罰參數C1、C2分別設定為3.0、2.0。這種情況下,分類驗證結果是最好的。
采用信息檢索技術中的準確率(P)、召回率(R)和F值(F)三個指標來衡量該方法返回結果的實際效果。定義網頁中有效正文內容總行數WebValidRow,返回結果的總行數為ResultAllRow,返回結果中屬于有效正文內容的行數為ResultValidRow,則:
(9)
(10)
(11)
實驗對比了三種文本提取方法的準確率、召回率和F值,結果如表2-表4所示。
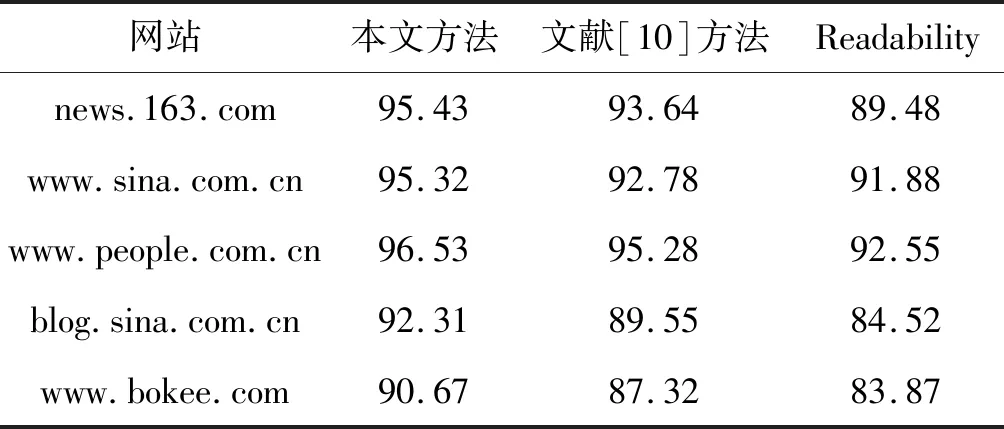
表2 正文文本提取準確率P對比 %
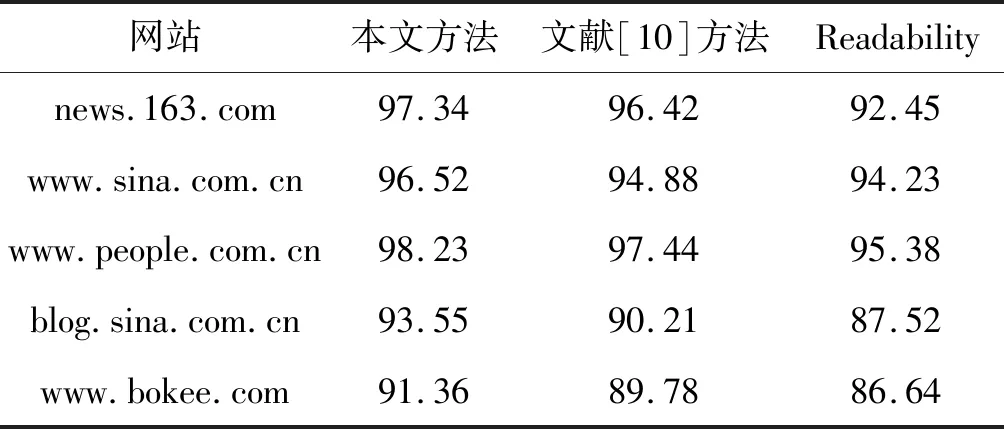
表3 正文文本提取召回率R對比 %
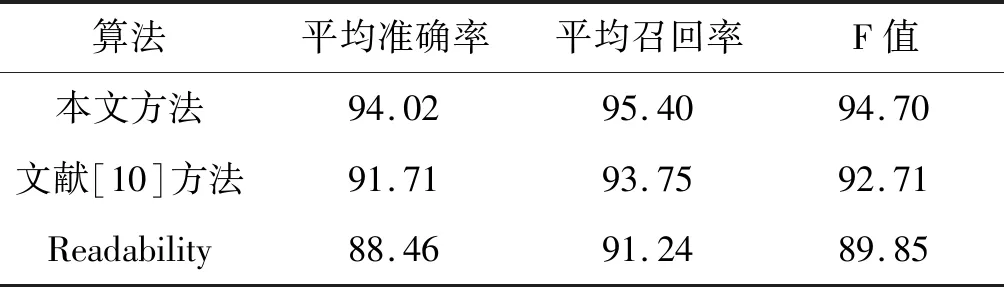
表4 正文文本提取綜合對比 %
由上述測試結果可見,對于單主題的網頁,這三種均擁有較高的召回率和不錯的準確率,且本文方法的準確率要略優于文獻[10]方法;而對于多主題網頁,本文方法在準確率和召回率方面要明顯優于其他兩種方法。可見,本文方法總體表現上要優于文獻[10]方法,特別在多主題網頁的處理方面,優勢較為明顯。
5 結 語
與傳統的文本提取方法相比,本文方法在準確率、召回率上都有所提高。 從實驗結果來看,本文中使用的方法可以應用于大多數網站,但在個別網頁中也存在一些不準確的文本塊提取。特別是一些比較簡短的正文文本,該類信息密度特征提取不準確,致使分類時將其作為噪音信息濾掉。這將是今后算法改進的方向。
猜你喜歡- 在808DA上文本顯示的改善
制造技術與機床(2019年10期)2019-10-26 02:48:08- 基于doc2vec和TF-IDF的相似文本識別
電子制作(2018年18期)2018-11-14 01:48:06- 訂閱信息
中華手工(2017年2期)2017-06-06 23:00:31- 用對方法才能瘦
Coco薇(2016年2期)2016-03-22 02:42:52- 文本之中·文本之外·文本之上——童話故事《坐井觀天》的教學隱喻
小學教學參考(2015年20期)2016-01-15 08:44:38- 四大方法 教你不再“坐以待病”!
Coco薇(2015年1期)2015-08-13 02:47:34- 捕魚
小雪花·成長指南(2015年4期)2015-05-19 14:47:56- 展會信息
中外會展(2014年4期)2014-11-27 07:46:46- 如何快速走進文本
語文知識(2014年1期)2014-02-28 21:59:13- 健康信息
祝您健康(1987年3期)1987-12-30 09:52:32 - 在808DA上文本顯示的改善
- 、
- 、
