科創(chuàng)板擬上市企業(yè)估值模型與估值水平預(yù)測
2019-11-01 03:32:04孫裕策秦猛猛韓翔宇中國礦業(yè)大學(xué)北京
新商務(wù)周刊 2019年20期
文/孫裕策 秦猛猛 韓翔宇,中國礦業(yè)大學(xué)(北京)
1 引言
本文根據(jù) 2009-2018 中國 1500 家上市企業(yè)和世界 2700 家企業(yè)的估值數(shù)據(jù)、基本面數(shù)據(jù)、流動數(shù)據(jù),首先測算出 2018年中國 A 股市場與美國 NASDAQ 市場的估值溢價水平。第二,對中美市場的估值指標(biāo)與基本面指標(biāo)、流動性指標(biāo)之間的關(guān)系進行定量分析,采用熵權(quán)法客觀求出各股對應(yīng)基本面指標(biāo)的評分值和流動性指標(biāo)的評分值,并以此為自變量,以各股市場估值水平為因變量,進行多元回歸分析,若擬合度較差,再改用 BP 神經(jīng)網(wǎng)絡(luò),求出權(quán)值與閾值進行定量分析并進行對比分析。 第三,采用時間序列分析模型,先對六個二級指標(biāo)進行時間序列分析,預(yù)測出 2019年的相關(guān)數(shù)據(jù),然后利用前面熵權(quán)法已經(jīng)得到的權(quán)重表達式,由六個二級指標(biāo)的預(yù)測值得出兩個一級指標(biāo)的數(shù)值,完成預(yù)測。第四,根據(jù)上交所公布的 93 家企業(yè)申報科創(chuàng)板上市的相關(guān)數(shù)據(jù),運用時間序列分析模型預(yù)測出科技板市場 2019年的基本面數(shù)據(jù),代入美國市場的神經(jīng)網(wǎng)絡(luò)模型中,預(yù)測出科創(chuàng)板企業(yè)上市后的估值水平,此外,也將數(shù)據(jù)代入了訓(xùn)練過后的中國神經(jīng)系統(tǒng)模型,將兩種模型得到的預(yù)測值進行對比分析,使結(jié)果可靠性大大提升。得到了美國模型的結(jié)果略好于中國模型的結(jié)果,兩者存在一定的差距,說明中國還有較大發(fā)展空間的結(jié)論。
2 模型假設(shè)
1.篩選后的數(shù)據(jù)真實有效。
2.假設(shè)指標(biāo)之相互間影響不顯著。
3.假設(shè)提供的指標(biāo)能較全面地反映基本面指標(biāo)與流動性指標(biāo)。
3 符號說明
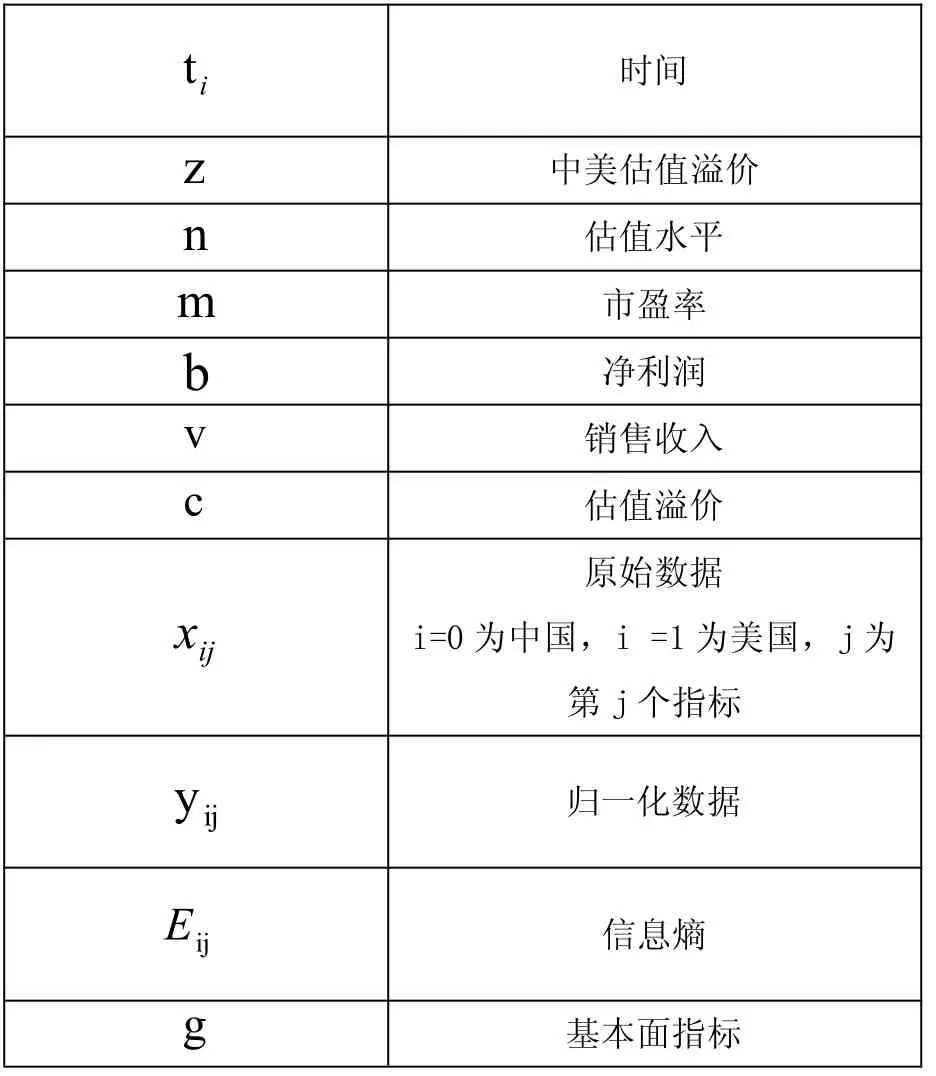
t i 時間z 中美估值溢價n 估值水平m 市盈率b 凈利潤v 銷售收入c 估值溢價x ij原始數(shù)據(jù)i=0 為中國,i =1 為美國,j 為第j 個指標(biāo)y ij 歸一化數(shù)據(jù)E ij 信息熵g 基本面指標(biāo)

u 流動性指標(biāo)Y i=0 為中國,i=1 為美國,j=1基本面指標(biāo),j=2 流動性指標(biāo)ij j 0某指標(biāo)起始數(shù)據(jù)
4 模型建立與求解
4.1 問題一:對中美市場估值溢價求解
4.1.1 估值水平求解
選取平均市銷率作為估值水平,計算 2018年兩市場估值水平可由 2018年平均市銷率來估計,可求得中國 A 股市場估值水平為 4.88,美國市場估值水平為 90.35。
4.1.2 估值溢價(或折價水平)的計算
(1)
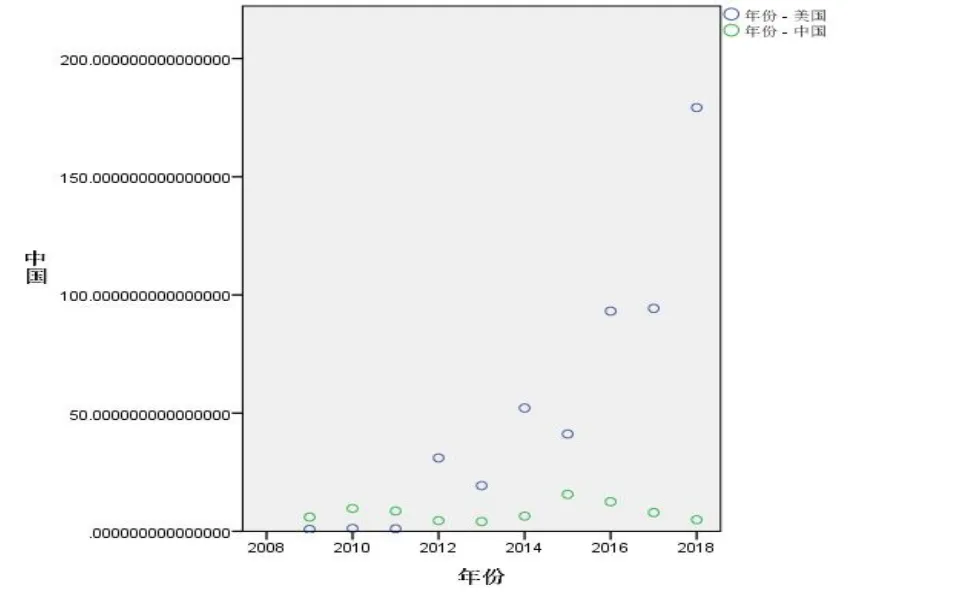
圖1 中美近年來估值水平對比圖
(2)中美之間估值溢價
兩者之間估值溢價可由二者估值水平之差求解:z=n1-n2
(3)中美各自估值溢價
Ⅰ模型的建立
估值溢價=預(yù)期收益率-投資必要報酬率
市盈率=股價/每股盈余額
故可用市盈率倒數(shù)表示估值溢價,市盈率=(市銷率/凈利潤)*銷售收入:
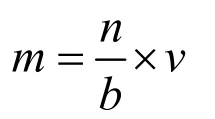
各自估值溢價最后表達式
估值溢價=凈利潤/(市銷率*銷售收入):
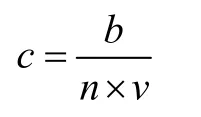
Ⅱ模型的求解
代入數(shù)據(jù)可得中美之間估值溢價為-85.47,即折價水平 85.47。得到各自估值溢價:
中國市場估值溢價 0.017
美國市場估值溢價 0.0011
4.2 問題二:對中美兩個市場各指標(biāo)之間的關(guān)系進行定量分析
4.2.1 模型的建立
(1)熵權(quán)法求中美基本面指標(biāo)、流動性指標(biāo)評價值
Step1::標(biāo)準(zhǔn)化后的數(shù)據(jù)比重的計算:
Step2:各指標(biāo)信息熵的計算
由此可分別得中美市場年度營業(yè)收入、年度歸母凈利潤、年度凈資產(chǎn)收益率的信息熵;可得年度單只股票交易量、年度單只股票交易金額、年度單只股票平均換手率的信息熵,得到基本面指標(biāo)與流動性指標(biāo)的評價值。
Step3:各指標(biāo)權(quán)重的計算
由此得到了各項指標(biāo)在結(jié)果中所占的權(quán)重,指標(biāo)越大,評價分越高。由 matlab 編程得到結(jié)果。
(2)基本面指標(biāo),流動性指標(biāo)與估值水平的 BP 神經(jīng)網(wǎng)絡(luò)模型
輸入層有 2 個神經(jīng)元,隱含層取七個神經(jīng)元,輸出層一個神經(jīng)元
輸入向量 x 與隱含層輸入向量 hi 為:
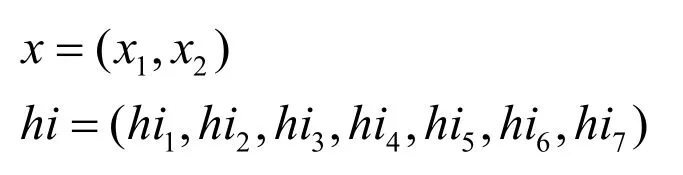
輸出層輸出向量 yo,期望輸出向量 do,誤差函數(shù)e為:

采用trainlm函數(shù)進行訓(xùn)練得到結(jié)果
得到神經(jīng)網(wǎng)絡(luò)函數(shù):

4.2.2 模型的求解
(1)基本面指標(biāo)、流動性指標(biāo)熵值法量化求解(程序略)
將給定的標(biāo)準(zhǔn)化數(shù)據(jù)代入熵值法公式進行計算,運用 matlab 編程得出各指標(biāo)權(quán)重部分。
(2)基本面指標(biāo)、流動性指標(biāo)與估值水平的神經(jīng)網(wǎng)絡(luò)模型求解
Matlab 編程求解,經(jīng)過不斷試驗,隱含層數(shù)為 7,且符合隱含層數(shù)經(jīng)驗公式
訓(xùn)練結(jié)果如下:

圖2 中國 A 股市場訓(xùn)練結(jié)果
可發(fā)現(xiàn)精度為 0.001,可以接受
輸入層到隱含層權(quán)值
Iw:

39.5744 4.7693 24.8793 8.8798 34.2773 12.0005 42.4514 4.8466 25.7665 9.2070-6.8681 10.6393-26.4594 -9.7348
隱含層到輸出層權(quán)值
Lw:

2.1845 5.0375 5.9266 -1.7025 -21.4683 0.0045 -10.0223

圖3 美國市場訓(xùn)練結(jié)果
可發(fā)現(xiàn)精度為 0.001,可以接受
輸入層到隱含層權(quán)值
Iw:
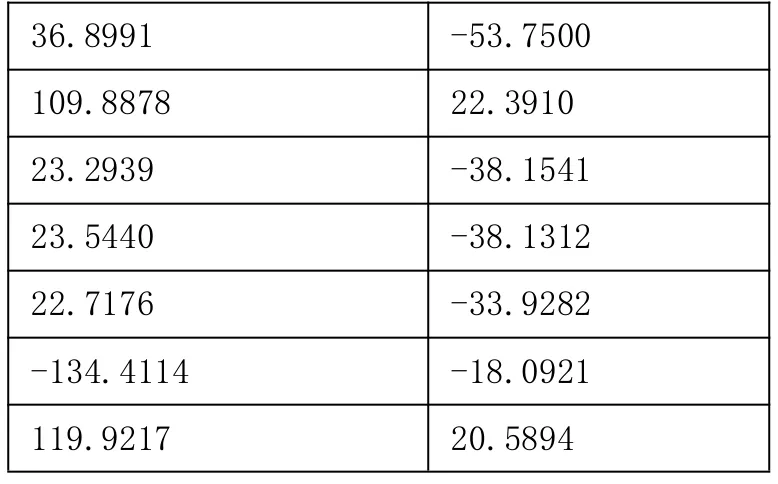
36.8991 -53.7500 109.8878 22.3910 23.2939 -38.1541 23.5440 -38.1312 22.7176 -33.9282-134.4114 -18.0921 119.9217 20.5894
隱含層到輸出層權(quán)值
Lw:

0.2470 -4.2470 5.5060 -6.2176 0.4696 3.1887 7.4301
兩市場對比可發(fā)現(xiàn),美國輸入層到隱含層平均權(quán)值絕對值較大,為 49 ,中國為 12,中國隱含層到輸出層平均權(quán)值絕對值較大,為 6.52 ,美國為 3。可見中美股票市場呈現(xiàn)不同的特點。
4.3 問題三:計算中美兩個市場 2019年的估值指標(biāo)
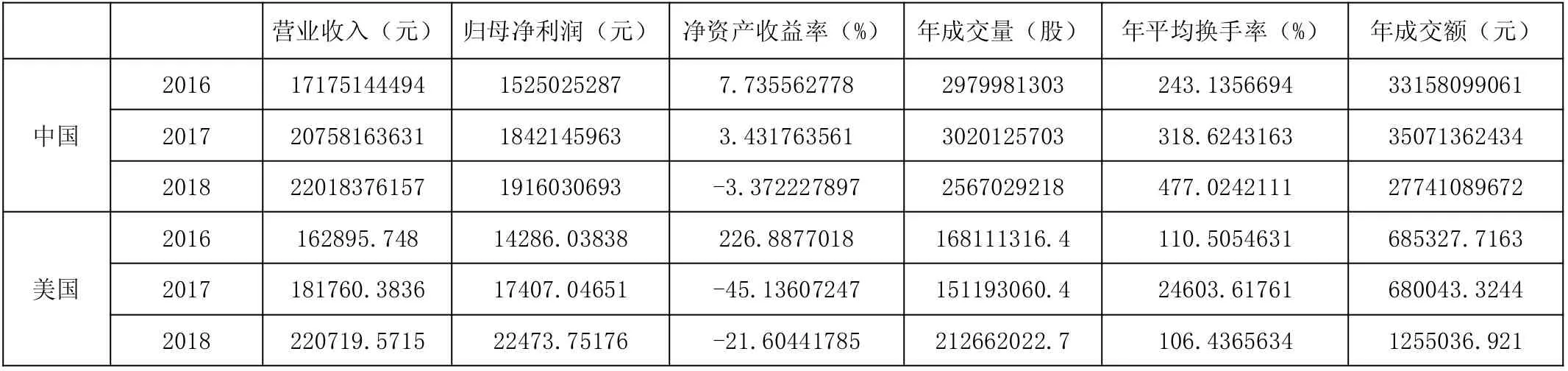
表1 十年內(nèi)中美市場的六個指標(biāo)

表2 歸一化結(jié)果
4.3.1 模型的準(zhǔn)備
(1)數(shù)據(jù)預(yù)處理
由于后續(xù)的分析中需要用到的兩個市場十年之間的六個二級指標(biāo)的數(shù)值,現(xiàn)采用企業(yè)的平均值來表示,這樣,可以得到美國和中國十年內(nèi)六個指標(biāo)的數(shù)據(jù)。部分見表1。
(2)中美 2019年基本面指標(biāo)和流動性指標(biāo)的時間序列分析模型
時間序列分析有多種算法,本文綜合使用一次指數(shù)平滑法、霍爾特預(yù)測法、ARIMA 模型三種算法進行時間序列預(yù)測。
4.3.2 模型的建立與求解
Step.1:
采用 spss 中的時間序列分析模塊進行預(yù)測,spss 可以為每一項指標(biāo)的預(yù)測匹配相應(yīng)的的最優(yōu)算法。
結(jié)果分析:
對于中國 2019年六項指標(biāo)的擬合,擬合度都在 0.5 以上,擬合效果良好。
對于美國 2019年六項指標(biāo)的擬合,有極個別指標(biāo)的預(yù)測值偏大,這是由于本次預(yù)測中所采用的的原始數(shù)據(jù)均為每年指標(biāo)的平均值,而美國貧富差距比較大,所以導(dǎo)致數(shù)據(jù)波動較厲害,但為了讓模型更加真實有效,保留這部分?jǐn)?shù)據(jù)。其余指標(biāo)都擬合良好。
Step.2:
將上述數(shù)據(jù)進行歸一化處理,見表2。
帶入問題二中運用熵權(quán)法的得到的表達式,可得出 2019年美國和中國的基本面指標(biāo)和流動性指標(biāo)的數(shù)值:

表3 2019年美國和中國的基本面指標(biāo)和流動性指標(biāo)
Step.3:
得到 2019年的基本面指標(biāo)和流動性指標(biāo)后,然后可帶入經(jīng)過訓(xùn)練的神經(jīng)網(wǎng)絡(luò)模型中,從而預(yù)測出 2019年中國市場和美國市場的估值水平。
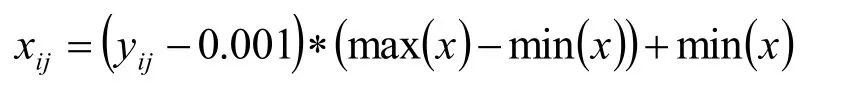
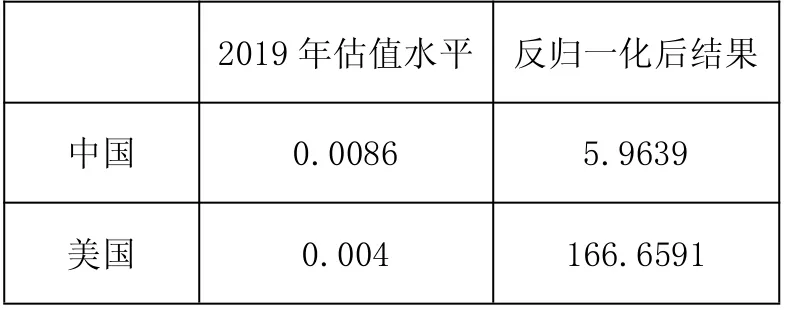
表4 2019年中國市場和美國市場的估值水平
需要對結(jié)果進行反歸一化處理,公式如下:4.4 問題四 預(yù)測我國首批 93 家科創(chuàng)板企業(yè)上市后的估值水平4.4.1 預(yù)測 2019年科技板基本面指標(biāo)
根據(jù)上交所給出的 93 家科創(chuàng)板企業(yè)在 2016-2018年間的年度營業(yè)收入、年度歸母凈利潤、年度凈資產(chǎn)收益率,可以計算出每一年三項指標(biāo)的均值,以此來表示每一年各個指標(biāo)的總體水平。帶去問題三的時間序列預(yù)測模型中,運用 spss 可以得到如下結(jié)果:
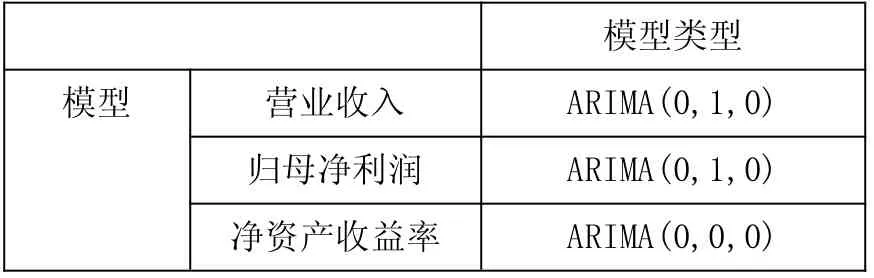
表5 科創(chuàng)板 2019年指標(biāo)預(yù)測算法
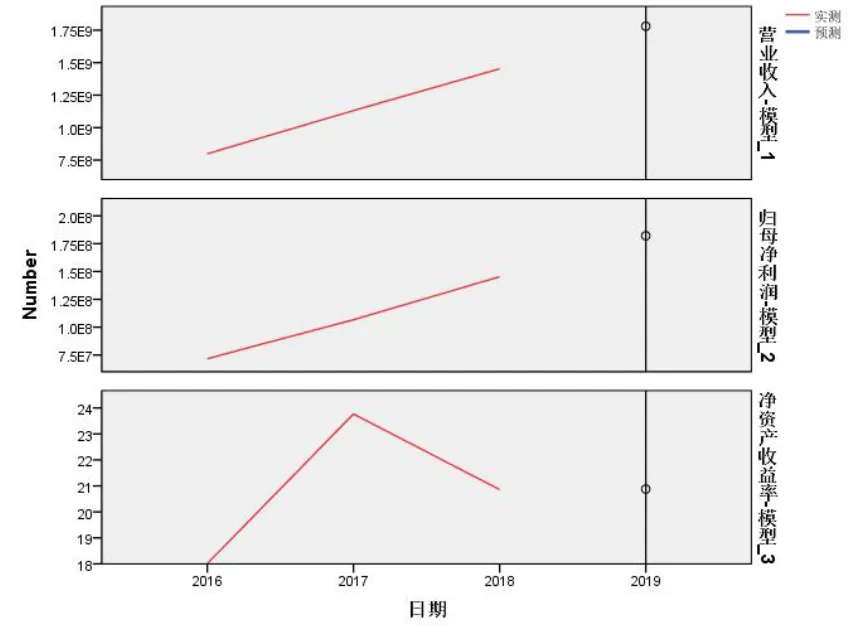
圖6 各項指標(biāo)的 2019 預(yù)測值

表6 六個指標(biāo)的數(shù)值
4.4.2 預(yù)測估值水平
Step.1:
整理上述結(jié)果可得如下結(jié)果:見表6。
Step.2:通過美國 NASDAQ 市場的估值量化模型預(yù)測科創(chuàng)板
將上述預(yù)測到的 2019年科創(chuàng)板的基本面指標(biāo)和中國 A 股的流動性指標(biāo)進行數(shù)據(jù)的歸一化處理,考慮到使用美國的估值量化模型,所以在美國環(huán)境下進行歸一化處理,即將數(shù)據(jù)加入 2018年美國企業(yè)各項指標(biāo)的表格中,統(tǒng)一進行歸一化。此外,由于中美統(tǒng)計過程中計算單位不一致,需將中國的這三項指標(biāo)同除以進率 70000,換算成美元。再進行歸一化,見表7。

表11 2019年兩項一級指標(biāo)的數(shù)值
可直接進之前訓(xùn)練好的中國神經(jīng)網(wǎng)絡(luò)模型,預(yù)測出相應(yīng)的估值水平。最后結(jié)果需要進行反歸一化處理。

表7 歸一化后六個指標(biāo)的數(shù)值
數(shù)據(jù)歸一化后,按熵權(quán)法可得出 2019年兩項一級指標(biāo)的數(shù)值
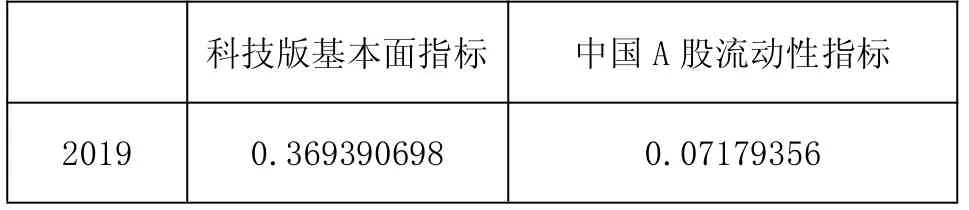
表8 2019年兩項一級指標(biāo)的數(shù)值
直接將上述數(shù)據(jù)輸入之前訓(xùn)練好的美國神經(jīng)網(wǎng)絡(luò)模型,預(yù)測出相應(yīng)的估值水平。最后結(jié)果需要進行反歸一化處理。

表9 科技板估值水平
Step.3:通過中國 NASDAQ 市場的估值量化模型預(yù)測科創(chuàng)板
與上一步驟類似,使用中國的估值量化模型,在中國環(huán)境下進行歸一化處理,見表10。

表10 歸一化后六個指標(biāo)的數(shù)值
數(shù)據(jù)歸一化后,按熵權(quán)法可得出 2019年兩項一級指標(biāo)的數(shù)值
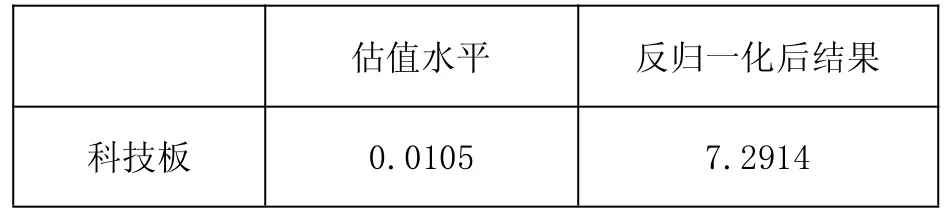
表12 科技板估值水平
4.4.3 結(jié)果分析
通過分析可以得出無論運用哪種模型進行預(yù)測,科技板 2019年上市后的估值水平都將在中等水平附近波動,運用美國模型得出的結(jié)果略好于中國模型得到的結(jié)果,兩者存在一定的差距,說明中國的發(fā)展空間還很大,而中國近幾年的經(jīng)濟形勢呈穩(wěn)定發(fā)展的態(tài)勢,相信在不久的將來,中國市場的估值水平將與美國市場比肩。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
美與時代·美術(shù)學(xué)刊(2022年3期)2022-04-27 01:18:15
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
火花(2019年12期)2019-12-26 01:00:28
人大建設(shè)(2019年12期)2019-05-21 02:55:32
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
學(xué)苑創(chuàng)造·A版(2015年11期)2016-01-14 09:03:27
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中國火炬(2010年8期)2010-07-25 11:34:30
