基于機器學習方法的安全帽佩戴行為檢測*
2019-11-06 09:58:20楊莉瓊蔡利強
中國安全生產科學技術 2019年10期
楊莉瓊,蔡利強,古 松
(西南科技大學 土木工程與建筑學院,四川 綿陽 621010)
0 引言
安全帽作為安全防護用品,其主要作用是保護施工現場人員的頭部,防高空物體墜落,防物體打擊、碰撞。為了提高監管效率滿足現場實時連續監控的要求,學者們提出應用計算機視覺技術智能檢測施工人員是否佩戴安全帽[1-3]。目前,安全帽檢測方法主要分成2類:1類是基于傳統圖像特征提取的檢測方法。文獻[4]提出的人形檢測方法易受客觀環境如光照、背景等干擾;文獻[5]提出基于安全帽輪廓特征的檢測方法精度不高,存在較多的誤報、漏報問題。2類是基于人工智能的方法。文獻[6]提出的方法提高了安全帽檢測精度,但未考慮安全帽是否佩戴在頭部;文獻[7]提出的改進方法雖然能判斷工人是否佩戴安全帽,但由于工人工作姿勢及身體特征的復雜多樣性導致檢測精度不高;文獻[8]提出基于卷積神經網絡的行人安全帽識別方法適合于運動目標,如果人員處于相對靜止時則會產生較大誤差;文獻[9]提出基于深度學習的檢測方法雖然檢測精度較高,但檢測速度比較慢,無法滿足現場安全預警的實時性要求。
基于傳統圖像特征提取的安全帽佩戴檢測方法未考慮復雜的施工環境對其精度的影響;而基于人工智能的方法具有較好的環境適應性,但文獻[6-9]未考慮檢測效率。本文在綜合考慮現場安全監控的時效性、準確性以及復雜環境的適用性,提出1種基于機器學習的安全帽佩戴行為檢測方法,提高了檢測精度與效率。
1 安全帽佩戴行為檢測
安全帽作為保護頭部的重要裝置,施工及現場管理人員進入工地后必須正確佩戴安全帽,即“人”“帽”不分離。因此,為保證圖像檢測結果的準確可靠,首先要檢測出佩戴安全帽的頭部區域,再通過提取安全帽特征的方法分析判斷人員是否佩戴了安全帽。
1.1 工作平臺
基于機器學習的安全帽佩戴行為檢測平臺如圖1所示,包括部署在不同施工區域的監控相機、運行安全帽檢測算法的智能監控工作站、連接相機和工作站的施工現場通信網絡3部分。其中,監控相機的架設要符合《建筑工程施工現場視頻監控技術規范》和其視角范圍需覆蓋整個監控區域的要求;相機獲得的施工現場實時圖像通過施工現場通信網絡傳輸給智能監控工作站;安全帽檢測算法的智能識別模塊檢測人員是否佩戴安全帽,并將結果通過預警模塊顯示在監控軟件界面上,以顏色框標識在未佩戴安全帽的人員臉部。
1.2 檢測流程
安全帽佩戴行為檢測流程如圖2所示,主要步驟如下:
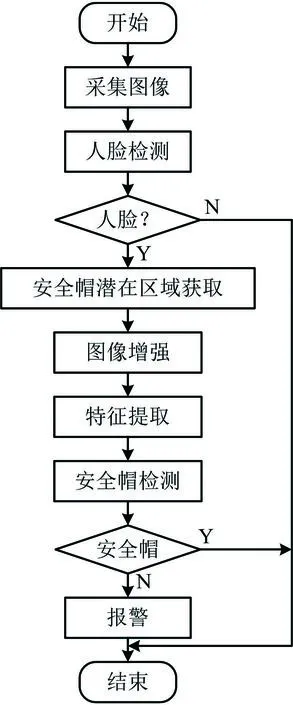
圖2 施工人員安全帽佩戴檢測流程Fig.2 Detection procedure on wearing of safety helmet for construction personnel
1)啟動軟硬件系統。監控站通過施工現場通信網絡打開監控相機,同時在監控工作站啟動安全帽檢測軟件,從相機獲取的現場視頻流中以幀為單位采集圖像。
2)對施工現場人員進行人臉檢測。安全帽檢測軟件利用深度學習YOLOv3算法訓練出的模型定位人臉區域,當檢測出人臉時根據一定比例估算安全帽的可能區域及大小。
3)對安全帽進行檢測。對安全帽可能區域圖像使用MSRCR(帶顏色恢復的視網膜圖像增強)方法進行增強處理,使用方向梯度直方圖(Histogram of Oriented Gradient,HOG)提取樣本的特征向量,再使用機器學習的支持向量機(Support Vector Machine,SVM)對安全帽可能區域進行檢測。
4)根據檢測結果進行報警。當人臉的安全帽區域沒有發現安全帽時,發出警告信息并保存圖像,該幀檢測結束,進入下一幀圖像檢測。
2 基于深度學習的施工現場人臉檢測
基于深度學習的人臉檢測算法能夠實現從端到端的網絡結構,不需要人為手動提取人工特征,使用多個卷積層自動提取圖像特征,并通過深層網絡消除干擾因素的影響,能夠大大提高識別的準確率,且對環境具有較好地魯棒性。目前,基于深度學習的目標檢測算法原理主要有2類:第1類算法通過對目標應用候選框算法產生大量的候選框,進行分類回歸后得到邊界框預測,雖然識別精度較高,但由于過程中產生大量候選框,導致檢測速度比較慢,無法實現實時檢測,如開源算法Faster R-CNN;第2類算法通過對目標圖像中的邏輯劃分區域進行抽樣,利用卷積神經網絡進行分類回歸,檢測速度快但精度有所下降,如SSD和YOLO算法。綜合考慮現場安全監控的時效性、準確性以及復雜環境的適用性要求,選擇YOLO算法進行人臉檢測[10-11]。
2.1 卷積神經網絡獲取施工現場圖像的特征圖譜
卷積神經網絡可以通過降維操作訓練輸入的施工現場圖片,進而提高識別精度。該網絡由施工現場圖像輸入層、現場目標特征提取卷積層、激勵層、池化層、全連接層組成。其中,施工現場圖像輸入層主要是對圖像進行去均值、歸一化、降維等預處理;現場目標特征提取卷積層通過卷積核對目標進行局部感知,提取標志性特征,再將獲取的特征與之前學習到的施工人員人臉特征進行比對,當滿足一定閾值時判定目標是施工人員,最終完成施工人員的人臉識別;激勵層將卷積層的輸出進行非線性映射;池化層對特征進行降維處理。完成上述處理后,網絡的輸出層會得到關于施工人員的人臉識別特征圖譜。
2.2 YOLO的人臉識別框架
YOLO采用端到端訓練和檢測,首先利用卷積神經網絡提取施工現場圖像中的目標特征,得到該圖像的特征圖譜;然后將輸入圖像分成相同大小的細胞網格,使用施工現場圖像中目標的中心坐標所在細胞網格進行預測;最后根據每個細胞網格固有數量的基礎框,計算出真值交并比(IOU)最高的基礎框,并用來判斷目標是否為施工人員的人臉。預測輸出的特征圖譜包含2個維度:①26×26網格數。②深度為X×(5+Y)的維度,其中X為每個細胞網格基礎框的數量;Y為基礎框的類別數;5表示矩形框的4個頂點坐標信息和該框的置信度,YOLO的整體結構如圖3所示。

圖3 YOLO整體結構Fig.3 YOLO overall structure
2.3 施工人員的人臉多尺度預測
當無法從施工現場圖片中提取人臉特征時,算法需要將其圖片的像素點映射到高一級尺度,進而在高一級尺度生成邊界框預測信息。尺度預測得到3個邊界框,通過錨點得到9個聚類中心,并分配給各級尺度:1級尺度添加卷積層輸出邊界框信息;2級尺度對1級尺度的倒數第2層卷積層進行上采樣,并與最后16×16的特征圖相加,再將結果進行卷積操作,得到邊界框信息;3級尺度操作過程與2級尺度一樣,只是特征圖尺寸變為32×32。上述邊界框有4個參數,即x,y,w,h,其中x,y表示施工現場圖像中目標圖像預測邊界框中心點坐標值;w表示該邊界框的長度;h表示邊界框的寬度。
邊界框預測如圖4所示,其中:cx,cy表示該邊界框中心所在細胞的左上角頂點坐標;pw,ph為預測邊界框的寬和高,可通過式(1)~(4)預測得到預測框的4個參數(bx,by,bw,bh);σ()為sigmoid函數,輸出0到1;tx和ty為預測坐標的偏移值;tw和th為尺度縮放。
bx=σtx+cx
(1)
by=σty+cy
(2)
bw=pwetw
(3)
bh=pheth
(4)
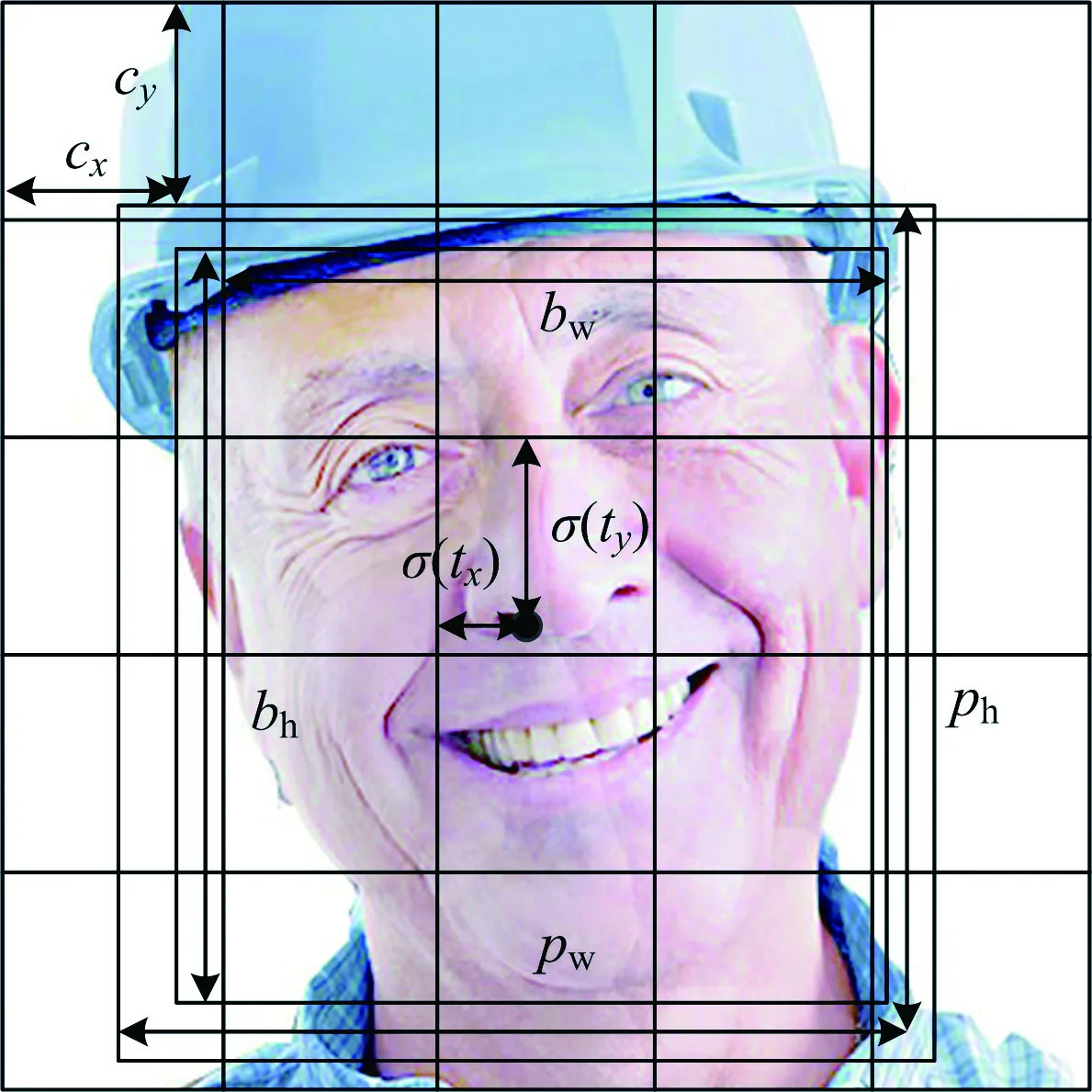
圖4 邊界框預測Fig.4 Prediction of boundary frame
YOLO框架對每個邊界框進行邏輯回歸分析后得到其分類得分,若預測邊界框接近真實邊界框,得分為1;若預測邊界框與真實邊界框相差較多,以至低于閾值0.5,得分為0,該預測框則被忽略。
2.4 施工現場的人臉訓練
YOLO訓練采用損失函數見式(5),考慮了預測框的位置、大小、種類、置信度等信息。

(5)

3 基于支持向量機的安全帽檢測
在識別出人臉并得到人臉位置后,檢測算法通過安全帽與人臉的關系推測出安全帽可能的區域。根據提前制作的大量安全帽正負樣本,使用HOG提取樣本的特征向量,再利用SVM分類器對安全帽區域進行檢測[12-13]。若未佩戴安全帽,則報警并保存當前幀。關鍵步驟如下。
1)對安全帽圖像進行增強處理
在實際施工環境中,光照會影響成像效果。如果不濾除光照影響,算法精度將受到很大的影響。本文應用基于Retinex算法的MSRCR圖像增強方法對施工場景中的安全帽進行圖像增強,使得整幅圖像亮度適中、色彩飽和,達到符合人眼觀察和細節完整描述的目的。Retinex是基于光照的均勻程度對物體的顏色沒有影響,不同光照下的同一物體應是相同顏色的理論。人眼獲取的圖像S是由于光照L照射到物體上,根據每個物體的反射特性反射到人眼得到的,并且反射特性R與物體的性質有關,與光照L無關。使用MSRCR方法對圖像處理后其亮度和對比度都有所增強,色彩飽和鮮明。
2)提取安全帽的HOG特征
HOG特征是對目標局部紋理的描述,通過檢測梯度方向和目標邊緣密度實現對目標的檢測。內容如下:對采集的安全帽圖像進行灰度化和歸一化后計算每個像素的梯度信息;以梯度幅值的方向權重為標準進行投影,并將圖像分為一些小的細胞;提取細胞元特征,并計算歸一化特征向量;對特征向量進行拼接得到原始圖像的完整特征向量,用于SVM分類操作[14]。對1張像素為472 px×350 px的安全帽圖片進行HOG特征提取,如圖5所示。設置塊像素為16 px×16 px,細胞像素為8 px×8 px,block在檢測窗口中上下移動的像素為8 px×8 px,一個細胞的梯度直方圖化為9個bin,滑動窗口在檢測圖片中上下移動像素為8 px×8 px,得到該安全帽如圖5所示的HOG特征。

圖5 安全帽HOG特征提取Fig.5 HOG features extraction of safety helmet
3)應用SVM對安全帽進行分類
得到上述安全帽特征后,利用SVM進行識別。對于安全帽這類目標,圖像特征明顯、類別較少,能充分發揮SVM分類器的效率。同時搭配顏色識別,SVM的分類準確度會更高。這里采用線性不可分的分類器,引入松弛變量ξi,得到較好的分類超平面:
yi(ωTxi+b)≥1-ξi
(6)
式中:i為樣本點;y為類標記;ωT為超平面轉置;x為向量;ξ為松弛變量。
目標函數變為:
(7)
式中:‖ω‖為ω的二階范數;C為懲罰因子,用于調節參數,構造拉格朗日函數并求解對偶后的最大值最小值問題:
(8)
式中:α為拉格朗日乘子;s.t.為約束條件。制作安全帽正樣本以及施工現場環境負樣本,進行HOG特征提取,并使用線性不可分SVM分類器進行訓練得到檢測集。對一張圖片上的安全帽進行檢測如圖6所示。

圖6 安全帽檢測Fig.6 Detection of safety helmet
4 實驗與測試結果
4.1 工程背景
某高鐵站房擴建工程臨近既有線路施工,環境復雜;現場人員構成復雜且數量較多,分別歸屬于不同的參與方,管理難度較大。為了便于監管,現場人員中的監理人員、施工管理人員、技術人員、作業工人分別佩戴藍色、白色、紅色、黃色的安全帽。由于實際工程施工受限,本文方法測試選在入口處對進出工地的人員開展安全帽佩戴智能識別測試。
4.2 人員安全帽數據集制作
1)施工現場人臉數據集制作
通過工地調查,共收集5 600張樣本。應用深度學習算法,對人員是否佩戴安全帽行為識別首先要檢測到人臉。將5 600張樣本分為一類,每張樣本包含1個人臉,對每1張樣本進行標注后開始訓練。
數據集建好后,將其中90%作為訓練集,10%作為測試集,劃分訓練數據和測試數據后,下載權重文件darknet53.conv.74,并在此權重上進行人臉數據的訓練,9 000次迭代后誤差降為0.02。
2)安全帽數據集制作
通過工地調查,共收集3 000張樣本。人員佩戴各種顏色的安全帽為正樣本,與安全帽形狀、顏色類似的施工現場其他物體為負樣本。考慮到施工人員未佩戴安全帽時,頭發形狀與安全帽形狀也有相似之處,負樣本中又添加了各種發型及顏色樣本,將正負樣本分類標記后進行訓練,得到訓練結果。
4.3 現場驗證
工地入口有3個,選擇人流較大的A出口,將網絡監控攝像頭架設在入口處進行圖像采集,通過圖像算法程序分析后對未佩戴安全帽的人員進行預警,并框選人臉顯示在軟件界面上。為驗證本文方法的準確性,設定了人員稀疏、人員擁擠等情況進行現場測試驗證,實驗效果如圖7所示。

圖7 施工人員安全帽佩戴檢測Fig.7 Detection of safety helmet wearing for construction personnel
通過1 000次的測試,本系統能夠準確識別在稀疏或擁擠狀態下未佩戴安全帽的人員,并且能夠對多種顏色的安全帽進行識別。算法進行優化后對多人同時進入時存在部分遮擋的情況也能較為準確的識別,實驗結果如圖8所示。其中:“正確”表示工人未佩戴安全帽被識別,比例約90%;“錯誤”表示工人佩戴安全帽被識別為沒有佩戴安全帽,比例約8%;“漏檢”表示工人未佩戴安全帽未被識別,比例約2%。同時,測試結果滿足實時性的要求,多次測試的統計數據顯示,采集一幀圖像的時間小于50 ms,檢測一幀圖像的時間小于50 ms。因此,系統識別的時間不到100 ms。

圖8 實驗結果Fig.8 Experimental results
為檢驗對復雜環境的適應性,選擇在施工現場的塔吊作業區域進行實驗。測試達到200次,正確率約91%、錯誤率約6%、漏檢率約3%。現場的實驗效果如圖9所示。

圖9 塔吊作業區域檢測效果Fig.9 Detection effect in tower crane operation
5 結論
1)提出1種基于機器學習的安全帽佩戴行為檢測方法,并在施工區域驗證其正確有效。
2)測試數據表明在施工通道和塔吊作業區域,該方法可實時有效的檢測出工人未戴安全帽的行為,識別率達到90%以上,識別時間低于0.1 s。
3)考慮圖像受環境光照和相機成像質量影響,下一步將圍繞算法穩定性開展深入研究,尤其是結合不同施工區域的成像特點對算法進行針對性優化,并考慮適當引入其他傳感器進一步提高該方法的實用性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
