一種對稱殘差CNN的圖像超分辨率重建方法
2019-11-08 08:21:00劉樹東王曉敏
西安電子科技大學學報 2019年5期
劉樹東,王曉敏,張 艷
(天津城建大學 計算機與信息工程學院,天津 300384)
圖像超分辨率(Super-Resolution,SR)重建是圖像復原中的一個重要分支[1],是一種由低分辨率圖像恢復對應高分辨率圖像的方法。隨著圖像超分辨率在衛星成像[2]、醫學成像[3]、安全和監視[4]、圖像生成[5]等計算機視覺任務和圖像處理領域取得的突出成就,利用超分辨率技術重建出更高分辨率、更清晰的圖像成為目前圖像復原領域的研究熱點。
圖像超分辨率重建最早是由文獻[6]在20世紀60年代提出的。隨著超分辨率技術的廣泛應用,越來越多的學者開始對其進行探究。圖像超分辨率重建方法主要有3種:基于插值的方法[7]、基于重建的方法[8]和基于學習的方法[9-10]。基于差值的超分辨率重建方法計算簡單,容易實現,但對自然圖像的先驗知識具有較大的依賴性,對圖像細節恢復效果較差,容易出現邊緣效應。基于重建的方法根據已知的退化模型得到低分辨率圖像,通過提取低分辨率圖像中關鍵的像素點信息對高分辨率圖像的生成進行約束,結合高分辨率圖像中的先驗知識得到相應的重建結果。但由于獲得的先驗知識有限,因此對于復雜的圖像無法恢復出更多細節信息,重建性能有限。基于學習的方法通過建立高、低分辨率圖像兩者之間的映射關系,然后利用學習獲得的先驗知識來完成高分辨率圖像的重建。與其他重建方法相比,基于學習的圖像超分辨率方法可以從訓練樣本中學習到所需的細節信息,并對測試樣本進行估計,可獲得相對較好的重建效果。目前基于學習的方法主要有基于稀疏表示、近鄰嵌入和深度學習的方法。文獻[11-12]提出一種基于稀疏表示和字典學習的方法,通過學習低分辨率圖像塊和對應高分辨率圖像塊的超完備字典進行圖像重建。但由于對超完備字典的學習要求較高,實用性較差,文獻[13-14]將稀疏字典和領域嵌入進行結合,提出了錨定領域回歸算法和改進后的錨定領域回歸(A+)算法,計算效率得到了提高,但圖像細節恢復效果較差。
隨著深度學習的飛速發展,基于深度學習的方法與傳統方法[15-16]相比有顯著的優勢。卷積神經網絡(Convolutional Neural Network,CNN)作為深度學習的代表性算法之一,由于其高效的學習能力,在超分辨率領域得到了廣泛的應用[17-18]。文獻[9]采用3層卷積神經網絡(Super-Resolution Convolutional Neural Network,SRCNN)進行圖像超分辨率重建。該網絡結構簡單,容易實現,但由于卷積層數少、感受野小以及泛化能力差等缺陷,無法提取到圖像深層次的特征,導致重建性能有限。文獻[19]提出的卷積網絡將網絡深度提升到了20層,并引入了殘差學習,提高了特征提取能力。同時,文獻[20]還提出了深度遞歸卷積網絡,采用遞歸學習實現了深度網絡的參數共享,降低網絡的訓練難度。雖然文獻[19-20]提出的兩種方法取得了較好的重建性能,但是隨著網絡的加深,梯度消失和網絡退化也會越明顯。文獻[21]提出了深度拉普拉斯金字塔網絡,采用級聯結構逐步學習,逐步優化,取得了很好的重建效果。文獻[22]提出了一種深度殘差遞歸網絡,通過循環殘差的方式減少訓練參數,降低網絡訓練難度,有效緩解了梯度消失現象。文獻[23]提出的深度殘差編碼解碼網絡,采用對稱方式跳躍連接卷積與反卷積層,使訓練收斂速度更快,達到更高質量的局部最優,但隨著網絡深度的增加,梯度消失或網絡退化現象仍然存在。
筆者針對上述方法的不足,將對稱跳躍連接引入到卷積神經網絡,提出了一種基于對稱殘差的卷積神經網絡模型,以進一步提高圖像重建的質量。通過在殘差塊內建立對稱短跳連接,實現塊內信息充分利用,提取更豐富的局部特征,同時,在殘差塊外建立長跳連接,實現全局特征融合,以彌補深度網絡圖像細節信息退化嚴重的損失。針對損失函數的選擇,采用處理異常點更穩定的平均絕對值誤差(Mean Absolute Error,MAE)函數進行訓練。
1 相關工作
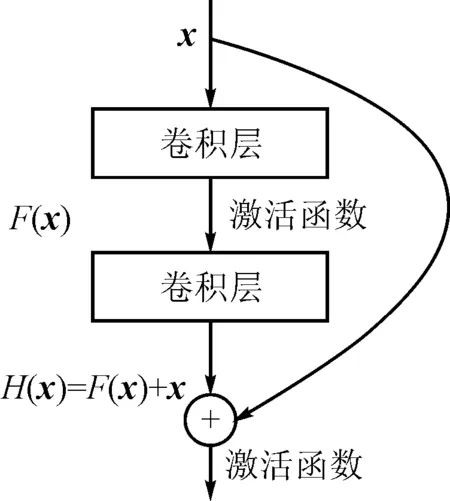
圖1 殘差結構圖
文獻[23]提出的深度殘差編碼解碼網絡是一種對稱網絡結構,將卷積神經網絡中的卷積和反卷積操作運用于圖像復原。首先,對稱跳躍連接有助于圖像信息直接反向傳播,從而緩解了梯度消失的現象,使深度網絡訓練更加容易,提高了網絡的恢復性能。隨著卷積神經網絡深度的增加,殘差網絡中的殘差結構可以有效緩解深度網絡引起的梯度消失和網絡退化現象,網絡架構越深,其豐富抽象特征的提取和網絡性能越好。
文獻[24]提出的152層深度殘差網絡(Residual Network,ResNet)利用非線性網絡可以擬合任意函數的特性,使用包含少數隱層的淺層網絡擬合自定義的殘差函數F(x):=H(x)-x,殘差函數再與恒等映射x相加,x表示網語的輸入,構成基本的殘差單元,實現期望的特征映射關系H(x)[25]。研究表明,這種方式更易于優化[6,26-30]。如圖1所示,殘差結構在解決梯度消失問題的同時,避免了因網絡加深而導致的額外參數引入,在深層網絡中使用跳躍連接的方式將卷積層連接,實現了不同卷積層中特征的重復利用,大大降低了訓練時的計算量[31]。文獻[18]在輸入數據和最后重建層之間采用跳躍連接進行信息傳遞。研究表明,在各層之間建立多個跳躍連接可以有效地訓練深度網絡[21]。
由于網絡深度的不斷增加,該方法將殘差網絡引入圖像超分辨率以解決深度網絡訓練難度大的問題;將一種對稱長短跳躍連接引入卷積神經網絡,通過在網絡中設置帶泄漏線性整流(Leaky Recitified Linear Unit,LReLU)函數作為激活函數,使網絡訓練更穩定,并以原始低分辨率圖像作為輸入,減少圖像經預處理后導致高頻信息丟失的現象,進一步提高了網絡的特征提取能力。
2 對稱殘差卷積神經網絡模型
2.1 對稱殘差卷積網絡結構
基于對稱殘差的卷積網絡(Symmetric Residual Convolution Neural,SymRCN)模型主要由特征提取、特征融合和重建3部分構成,共包含31層卷積層。該網絡模型包括4個殘差塊,采用對稱長短跳躍連接實現全局與局部特征融合,實現網絡訓練的穩定性和特征提取的高效性。在殘差塊內采用對稱殘差的方式提取更豐富的特征,殘差塊外通過長跳連接實現全局特征融合,有效緩解了由簡單堆疊多個殘差塊而導致特征提取不充分、梯度消失和網絡退化問題。網絡結構如圖2所示,其中,x和y分別表示網絡的輸入和輸出。

圖2 對稱殘差卷積網絡結構圖
對稱殘差卷積神經網絡模型建立時的具體實現步驟有3個:①特征提取。主要完成提取不同條件下的細節特征,將獲得的低分辨率圖像的穩定特征作為特征融合模塊的輸入數據;②特征融合。利用殘差塊內多個對稱殘差的卷積層和非線性映射函數的復合實現網絡中不同特征圖的提取;通過在殘差塊外建立長跳連接來完成各個殘差塊間特征的融合,并作為重建模塊的輸入數據;③重建。利用預測的殘差圖像重建出最終的高分辨率圖像。
特征提取部分由兩層卷積層構成,為了降低網絡參數數量和計算復雜度,每層卷積層均使用64個大小為3×3的卷積核對原始低分辨率圖像進行卷積,提取特征圖。特征B0提取過程可以表示為
B0=f(x) ,
(1)
其中,f表示特征提取函數,x并作為下面殘差塊的輸入。
特征融合部分由4個殘差塊組成,每個殘差塊由一個增強單元和一個壓縮單元構成,這個過程可以表示為
Bm=Fm(Bm-1),m=1,2,…,n,
(2)
其中,Fm表示第m個殘差塊對應的函數,Bm-1和Bm分別表示第m個殘差塊的輸入和輸出。
重建部分使用一層無激活函數的反卷積層實現最終圖像重建,該層的功能相當于上采樣操作。在反卷積過程中,當步長s大于1時,反卷積操作被視為上采樣,且網絡的整體復雜度會降低s2,但步長不宜過大,因為過大的步長會導致重建質量的下降。根據采樣因子的不同,相應調整步長大小,但步長始終大于1。重建過程中反卷積層對特征圖進行上采樣操作,將最終殘差塊的輸出特征組合起來生成殘差圖像,其中,反卷積層的偏置項能夠自動調整殘差圖像數據分布的中心值,使之接近原始圖像。由于輸入的原始低分辨率圖像與高分辨率圖像間存在極大的相似性,因而兩者間殘差圖像的像素信息多數情況趨近于零。使用輸入的低分辨率圖像、原始高分辨率圖像和生成的殘差圖像共同完成高分辨率圖像的重建,進一步提高了圖像的重建質量。網絡的輸出y可表示為
y=R(Fn(Bn-1))+U(x) ,
(3)
其中,R和U分別表示重建和雙三次插值函數。
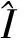
(4)
2.2 特征融合
特征融合是本網絡的核心部分,由增強單元和壓縮單元組成,Conv+LReLU(k,n)中k代表卷積核大小,n代表卷積核個數,并使用帶泄漏線性整流函數作為激活函數。其中增強單元包含6層結構相同的卷積層,通過對稱殘差實現淺層與深層信息的恒等映射,融合網絡上下文信息,提取更豐富的特征。壓縮單元由1層1×1的卷積層構成,為后續網絡提取關鍵信息。殘差塊內增強與壓縮單元框架如圖3所示。當前殘差塊的輸出Bm-1可表示為
(5)
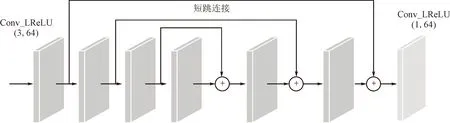
圖3 殘差塊內增強與壓縮單元框架圖
3 實驗結果分析
3.1 數據集預處理
使用文獻[12]的91張圖像和文獻[32]中的200張圖像作為訓練樣本。為了充分利用訓練數據,通過對291張圖像進行90°、180°、270°旋轉,水平翻轉,并以因子0.9、0.8、0.7、0.6的順序縮小,對訓練圖像進行數據增強處理后獲得訓練圖像11 640張。為了進一步證明提出方法的有效性,選擇應用廣泛的標準數據集Set5、Set14、BSD100進行測試,數據集中包含了豐富的自然場景,可以有效地測試網絡的性能。
利用雙三次插值法以因子k(k=2,3,4)對原始圖像進行下采樣,生成相應的低分辨率圖像,將低分辨率訓練圖像裁剪為一組lsub×lsub的子圖,相應的高分辨率訓練圖像被裁剪為klsub×klsub的子圖。由于網絡使用Caffe深度學習框架進行訓練[33],所以將反卷積核產生的輸出大小設置為(klsub-k+1)2,而非(klsub)2,因此,高分辨率子圖的像素邊界應裁剪(k-1)。同時,使用Caffe框架訓練時,若擁有較大學習率的訓練樣本尺寸越大,則訓練過程越不穩定。由于裁剪圖像塊時無重疊部分,為了充分利用291張圖像,當采樣因子增大時,子圖像采樣步長相應縮小,裁剪后的訓練子圖尺寸相應變小,以便得到更多邊緣的圖像塊。以采樣因子k=3為例,根據數據集中最小圖像的尺寸,將低分辨率子圖像采樣步長設置為15,低分辨率圖像裁剪為15×15(152)的訓練子圖,對應的高分辨率圖像裁剪為43×43(432,其中高分辨率子圖尺寸通過15×3-3+1獲得)的訓練子圖,故訓練階段使用大小為152/432的訓練對進行訓練。初始學習率設為10-4,訓練過程中,每250 000次學習率下降10-1,總的訓練次數為600 000次。訓練樣本尺寸如表1所示。

表1 不同采樣因子的訓練子圖尺寸
對于原始彩色圖像,將每張彩色圖像從RGB顏色空間轉換為YCbCr彩色空間。由于人眼視覺相比于顏色對圖像亮度更加敏感[34],在SRCNN中已經證明僅在Y通道進行映射關系不會影響圖像的重建質量[9],所以僅對Y通道即亮度通道做訓練從而得到對應的映射關系,對Cb、Cr顏色分量進行簡單的插值放大,這樣可以減輕計算的開銷,同時保證了圖像的重建質量[35]。
網絡中,所有采樣因子的上采樣核均為17×17,帶泄漏線性整流函數的負斜率設置為0.05,使用文獻[36]提出的方法初始化權重,偏置設為零,網絡使用Adam進行優化。
3.2 實驗分析
實驗硬件配置為Intel(R)Xeon(R)CPU E5-1650 v4 @3.60GHz×12處理器,Tesla K20c顯卡,64GB內存,平臺為Matlab R2016a軟件和caffe深度學習框架以及用于調用GPU的開發包CUDA8.0。首先針對在殘差塊內使用和不使用對稱短跳連接兩種情況,采用兩種不同的網絡模型進行峰值信噪比(PSNR)的測試實驗,然后使用標準測試集Set5、Set14、BSD100進行測試,將SymRCN方法與Bicubic、A+[13]、SRCNN[9]、VDSR[14]、DRCN[15]和LapSRN[16]6種典型方法的重建結果進行比較,使用峰值信噪比和結構相似度(SSIM)作為衡量圖像重建質量的指標。
圖4統計了殘差塊內是否使用對稱,并經過600 000次迭代后,在Set5測試集上重建結果的平均峰值信噪比曲線圖。從圖4中可以看出,使用對稱的網絡模型,峰值信噪比值有明顯提高,充分證明了使用對稱可以有效改善網絡加深帶來的梯度消失現象。
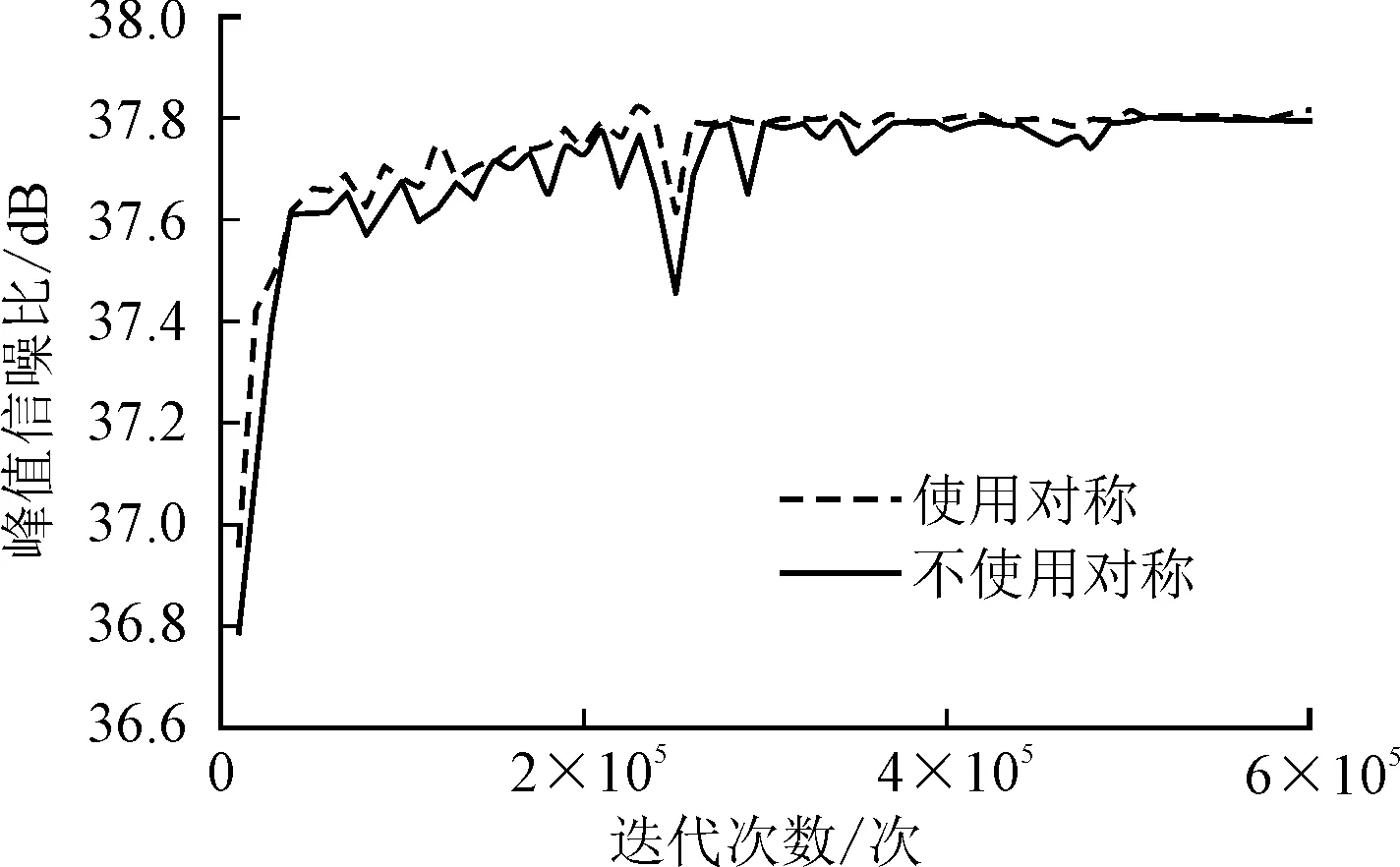
圖4 在Set5測試集上兩種方法的峰值信噪經收斂曲線
圖5~圖7展示了當采樣因子為2倍、3倍和4倍時,在Set5和Set14測試集上使用對稱殘差卷積網絡方法和其他6種方法進行重建后的圖像對比,從主觀角度對圖像的重建效果進行了展示。可以看出,Bicubic和A+兩種方法所重建的圖像比較模糊,鋸齒狀較為明顯,重建效果較差。SRCNN、VDSR、DRCN和LapSRN相較于前兩種方法的重建效果較好,但重建圖像仍然存在細節不完整,清晰度不夠高的問題。在不同采樣因子下,使用對稱殘差卷積網絡方法重建Set5中butterfly_GT圖像后的蝴蝶翅膀紋理更加清晰,細節更豐富,結構相似度更高;重建Set5數據集中的bird_GT圖像后的小鳥身體各部位細節信息提取更充分,邊緣更清晰,辨識度更高;重建Set14中zebra圖像的峰值信噪比和結構相似度雖略低于LapSRN,但重建的圖像與LapSRN算法重建的圖像視覺感官上十分接近。同時,相較于其他5種方法,該方法重建圖像更清晰,整體視覺效果更好。
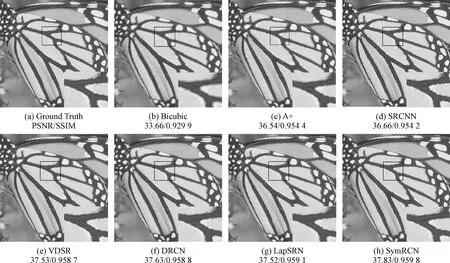
圖5 Set5中的butterfly_GT采樣2倍的重建對比圖

圖6 Set5中的bird_GT采樣3倍的重建對比圖
表2在Set5、Set14和BSD100數據集上不同超分辨率重建方法的平均PSNR/SSIM

數據集采樣因子Bicubic(PSNR/SSIM)A+(PSNR/SSIM)SRCNN(PSNR/SSIM)VDSR(PSNR/SSIM)DRCN(PSNR/SSIM)LapSRN(PSNR/SSIM)SymRCN(PSNR/SSIM)Set5×233.66/0.929 936.54/0.954 436.66/0.954 237.53/0.958 737.63/0.958 837.52/0.959 137.83/0.9598×330.39/0.868 232.58/0.908 832.75/0.909 033.66/0.921 333.82/0.922 633.81/0.922 034.00/0.924 6×428.42/0.810 430.28/0.860 330.48/0.862 831.35/0.883 831.53/0.885 431.54/0.885 231.53/0.885 5Set14×230.24/0.868 832.28/0.905 632.42/0.906 333.03/0.912 433.04/0.911 832.99/0.912 433.22/0.913 7×327.55/0.774 229.13/0.818 829.28/0.820 929.77/0.831 429.76/0.831 129.79/0.832 529.88/0.833 8×426.00/0.702 727.32/0.749 127.49/0.750 328.01/0.767 428.02/0.767 028.09/0.770 028.05/0.768 8BSD100×229.56/0.843 131.21/0.886 331.36/0.887 931.90/0.896 031.85/0.894 231.80/0.895 232.01/0.897 4×327.21/0.738 528.29/0.783 528.41/0.786 328.82/0.797 628.80/0.796 328.82/0.798 028.87/0.799 6×425.96/0.667 526.82/0.708 726.90/0.710 127.29/0.725 127.23/0.723 327.32/0.727 527.24/0.724 7平均值28.78/0.800 430.50/0.841 730.64/0.843 131.26/0.854 931.30/0.854 531.30/0.855 831.40/0.867 5
注:粗體標記數字表示最佳效果。
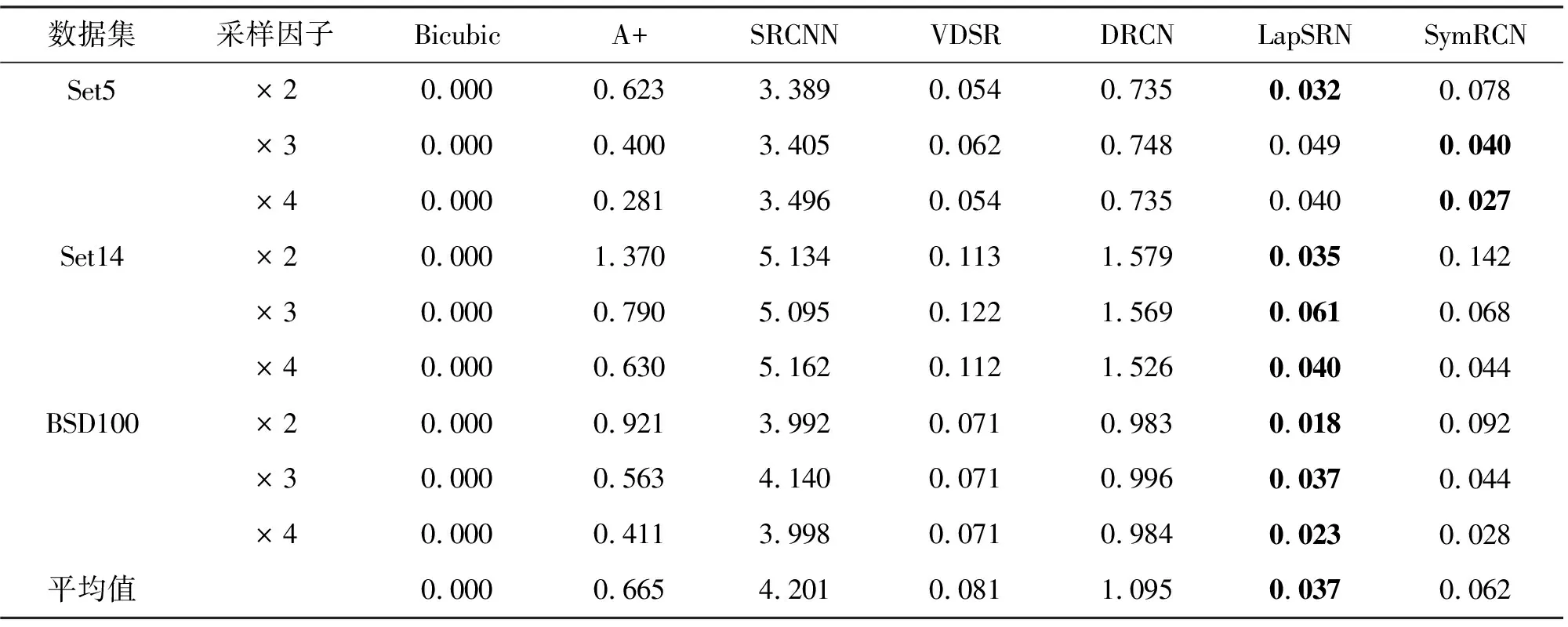
表3 在Set5、Set14和BSD100數據集上不同超分辨率重建方法的平均測試時間 s
注:粗體標記數字表示最佳效果。
不同圖像超分辨率重建方法在Set5、Set14和BSD100數據集上進行測試的PSNR和SSIM結果如表2所示,從客觀角度評價了圖像的重建效果。可以看出,VDSR、DRCN和LapSRN這3種方法比Bicubic、A+和SRCNN這3種方法的峰值信噪比和結構相似度值均有提高;由于SymRCN方法將對稱殘差引入到了卷積神經網絡中,實現了局部和全局特征融合,SymRCN方法較VDSR、DRCN和LapSRN這3種方法的平均峰值信噪比值分別提高了0.14 dB、0.1 dB和0.1 dB,平均結構相似度值分別提高了0.012 6、0.013 0和0.011 7,充分證明了該方法的有效性和重建圖像質量的可靠性。除了圖像質量評價外,測試時間也是評價超分辨率重建質量的一項重要指標,不同方法在Set5、Set14和BSD100數據集上測試的時間結果如表3所示。從表3中可以看出,SymRCN方法的測試時間雖略高于LapRCN方法的,但綜合峰值信噪比和結構相似度兩種評價指標,SymRCN方法的整體重建效果更好,效率更高,同時相較于其他5種比較方法所用平均測試時間較短,實際應用中實時性較好。
4 結束語
文中方法將跳躍連接引入圖像超分辨率重建,設計了一種長短跳躍連接網絡,提出了基于對稱殘差卷積神經網絡的圖像超分辨率重建方法。采用對稱殘差學習以提升收斂速度,采用長短跳躍連接融合全局與局部分級特征,從而保證網絡訓練的穩定性。實現了殘差塊內局部信息的充分利用,有效改善了由網絡深度帶來的梯度消失;同時實現了殘差塊外全局特征的融合以彌補網絡加深丟失的高頻細節。實驗結果表明,對稱殘差卷積神經網絡方法的重建效果較傳統方法有明顯的優勢,重建圖像的視覺效果更貼近人眼感官要求,充分證明了該方法的有效性和實用性。在后續的研究中,將嘗試繼續拓寬網絡寬度和深度以進一步改進網絡,尋求其他優化方法以進一步提高重建質量。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
