一種采用冗余性動態權重的特征選擇算法
2019-11-08 08:30:00肖利軍郭繼昌顧翔元
西安電子科技大學學報 2019年5期
肖利軍,郭繼昌,顧翔元
(天津大學 電氣自動化與信息工程學院,天津 300072)
特征選擇的目的是在全部特征中挑選出最具代表性的特征子集,實現數據降維,從而減少后期數據處理所需時間[1]。根據選擇策略的不同,特征選擇算法可以分為3種[2]:嵌入式、封裝式和過濾式。在過濾式算法[3-5]中,信息理論中的互信息是衡量特征關系的常用指標,其中特征間的互信息用于描述特征間的冗余性,特征與類標簽間的互信息用于描述特征的相關性,三路交互信息常用于描述特征與類標簽間的交互性。
基于互信息的特征選擇算法大多通過消除冗余特征、保留相關特征實現特征選擇[6-7]。互信息最大化算法[8]將特征與類標簽間的互信息作為特征相關性的評價指標,考慮了特征與類標間的相關性,但由于忽略了特征間的冗余性,算法性能不理想。針對互信息最大化算法中存在的問題,互信息特征選擇算法[9]、最小冗余-最大相關算法[10]和條件互信息算法[11],通過引入候選特征與已選特征間的互信息,考慮了特征間的冗余性,性能得到一定提升,但忽略了特征與類標簽間的交互性,使目標函數丟失一部分有用信息。因此,一些基于三維互信息的特征選擇算法相繼被提出。DWFS[12]算法和IWFS[13]算法采用一種動態更新候選特征權重的方法,通過特征與類標簽間的三路交互信息度量特征的交互性,取得了不錯的結果。但其權重更新系數忽略了對特征間冗余性的考慮,因此算法性能仍有提升空間。
針對該問題,筆者在考慮特征的相關性和交互性的基礎上,進一步利用了特征間的冗余性,提出一種采用冗余性動態權重的特征選擇算法(Dynamic Weights Using Redundancy, DWUR)。該算法采用一種動態更新特征權重的方法,在每一輪特征選擇之后,計算候選特征與本輪已選特征間的對稱不確定性及與類標簽間的三路交互信息,生成權重更新系數。通過權重計算特征的目標函數值,并挑選目標函數值最大的候選特征。在此過程中,算法同時考慮了特征的冗余性、相關性和交互性信息,以盡量減少目標函數中有用信息的丟失。
1 相關基礎
假設X、Y和Z為離散隨機變量,候選特征集為F,候選特征fi∈F,已選特征集為S,已選特征fs∈S,類標簽為C。互信息表示隨機變量X與Y共同享有的信息量,定義如下:
(1)
其中,p(x)為概率密度函數,p(x,y)為聯合概率密度函數。互信息表示為熵運算的形式如下:
I(X;Y)=H(X)-H(X|Y) ,
(2)
其中,H(X)和H(X|Y)分別為信息熵和條件信息熵。
大多數特征選擇算法將互信息作為評價特征相關性的標準,但與類標簽互信息值大的特征并不能保證好的分類結果。互信息會使算法傾向于選擇多值特征,缺乏選擇的公平性,因此使用對稱不確定性描述候選特征fi與類標簽C間的相關性,用S(fi;C)表示。其值越大,代表相關性越強,如式(3)所示:
(3)
其中,fi與fs間的對稱不確定性代表特征間冗余性系數,用RR(fi;fs)表示。其值越大,特征間冗余性越強。

(4)
三維互信息包括條件互信息、三路交互信息以及聯合互信息。條件互信息是指在隨機變量Z給定的情況下,X和Y之間的互信息,定義如下:
(5)
其中,p(x,y,z)表示隨機變量X、Y和Z的聯合概率密度函數,p(x,y|z)表示當Z給定時X和Y的聯合概率密度函數,p(x|z)和p(y|z)表示當Z給定時X和Y的概率密度函數。條件互信息還可以表示為
I(X;Y|Z)=H(X|Z)-H(X|Y,Z) ,
(6)
其中,H(X|Z)和H(X|Y,Z)分別表示當Z和Y、Z給定情況下,X的條件熵。
三路交互信息表示隨機變量X、Y和Z共同享有的信息,其與條件互信息具有如下關系:
I(X;Y;Z)=I(X;Y|Z)-I(X;Y) 。
(7)
基于互信息的特征選擇算法一般將fi、fs和C間的三路交互信息作為評價三者之間交互性的指標:
I(fi;fs;C)=I(fi;C|fs)-I(fi;C) 。
(8)
為方便計算,對上式進行歸一化,得到特征與類標簽間的交互性系數,用IR(fi;fs;C)表示
(9)
當IR(fi;fs;C)取值為正時,fi和fs之間存在交互信息,指在fs給定的情況下,fi能為分類提供更多有效信息,值越大,交互性越強;為負時,fi和fs之間存在冗余;為零時,fi和fs間相互獨立,互不影響。
2 采用冗余性動態權重的特征選擇算法
假設有候選特征集F,fi∈F(i=1,2,...,N),為候選特征,N為候選特征總數,設有已選特征集S,fj∈S,表示已選特征集中最近被選入特征。所提算法在每一輪特征選擇中,根據fi與fj的交互性和冗余性信息,動態更新候選特征fi的權重系數,該權重系數限制了對應候選特征在下一輪選擇中的表現能力,權重越大,表明其與最近已選特征間交互性越強,冗余性越小。特征權重的更新方法為
W(fi)k+1=W(fi)k(1+IR(fi;fj;C))(1-βRR(fi;fj)),k=1,2,...,K-1 ,
(10)
其中,W(fi)k代表候選特征fi在第k輪挑選中的權重,W(fi)k+1代表候選特征fi根據第k輪所選特征fj更新得到的下一輪權重,β為系數項,K代表預先設定的特征選擇數目。RR(fi;fj)與IR(fi;fj;C)分別為特征間的冗余性系數和特征與類標簽間的交互性系數。
fi與C間的相關性在特征的目標函數中體現,其定義為
JDWUR(fi)k=W(fi)kS(fi;C) ,k=1,2,...,K,
(11)
式中,JDWUR(fi)k代表在第k輪挑選中fi的目標函數值,W(fi)k代表fi在本輪的權重,S(fi;C)為fi與C間的對稱不確定性,代表候選特征與類標簽間的相關性。由式(10)和(11)可知,算法在考慮特征相關性和交互性的基礎上,同時考慮了特征間的冗余性,保證特征的目標函數能最大程度地保留有用信息,消除冗余信息。在每一輪選擇中,算法挑選目標函數值最大的候選特征加入到已選特征集S,并將其作為新的已選特征fj,繼續下一輪的權重更新和特征挑選,直到所有特征被挑選完畢或特征選擇數目達到K。具體執行過程的偽代碼如下:
輸入:原始特征集X,類標簽C,閾值K,候選特征集F
(1)初始化參數:k= 0 ,S=Φ,F=X
(2)初始化候選特征權重:W(fi)1=1 (?fi∈F,i=1,2,...,N)
(3)for eachfi∈F
(4) 根據式(3)計算各候選特征與類標簽間的對稱不確定性
(5)end for
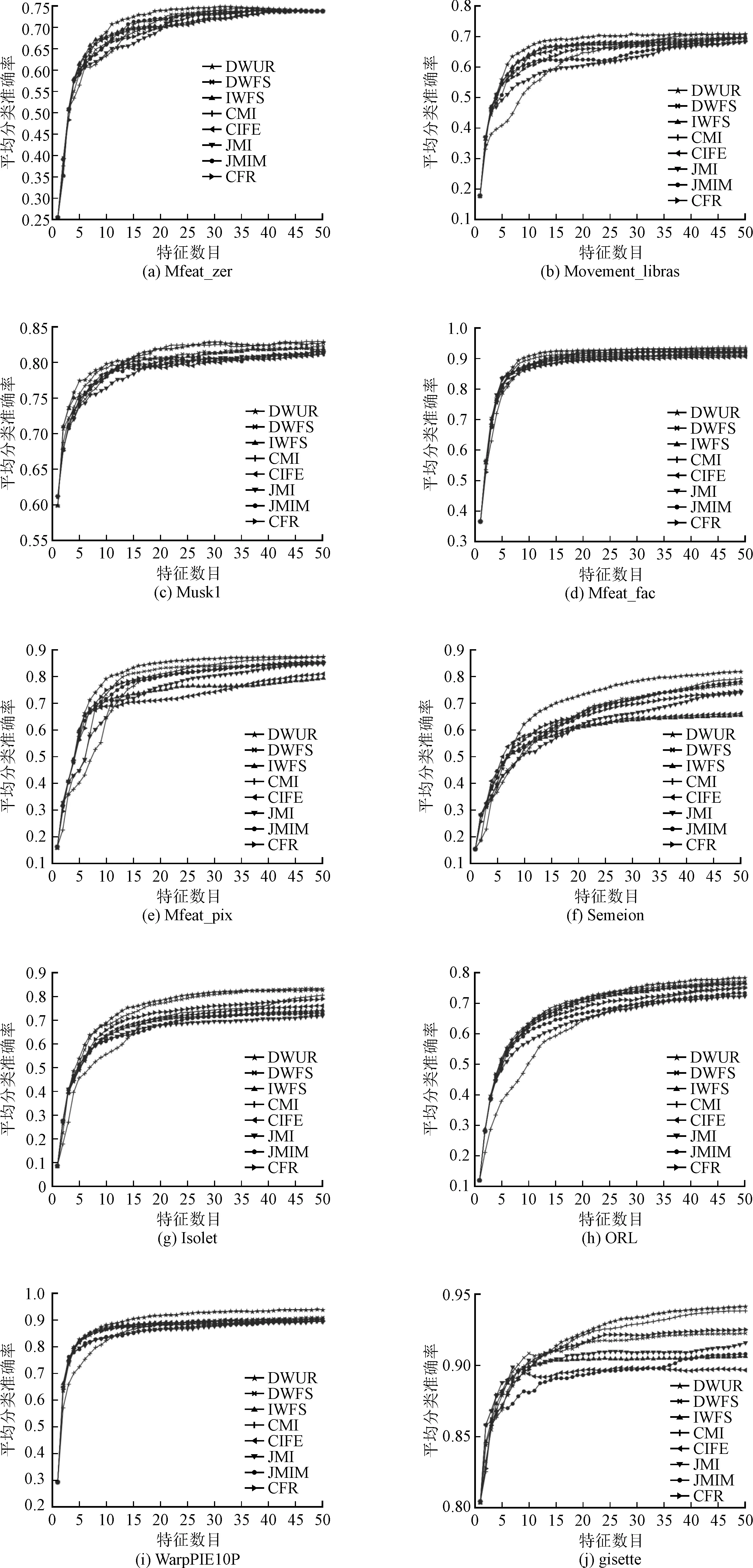
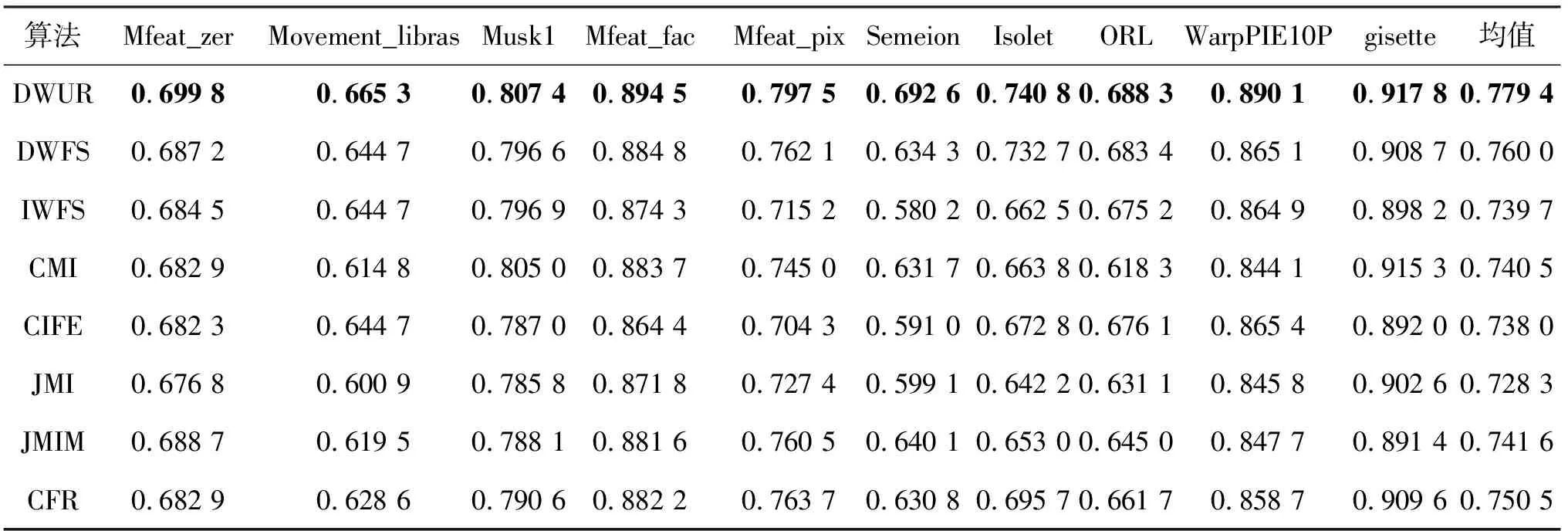
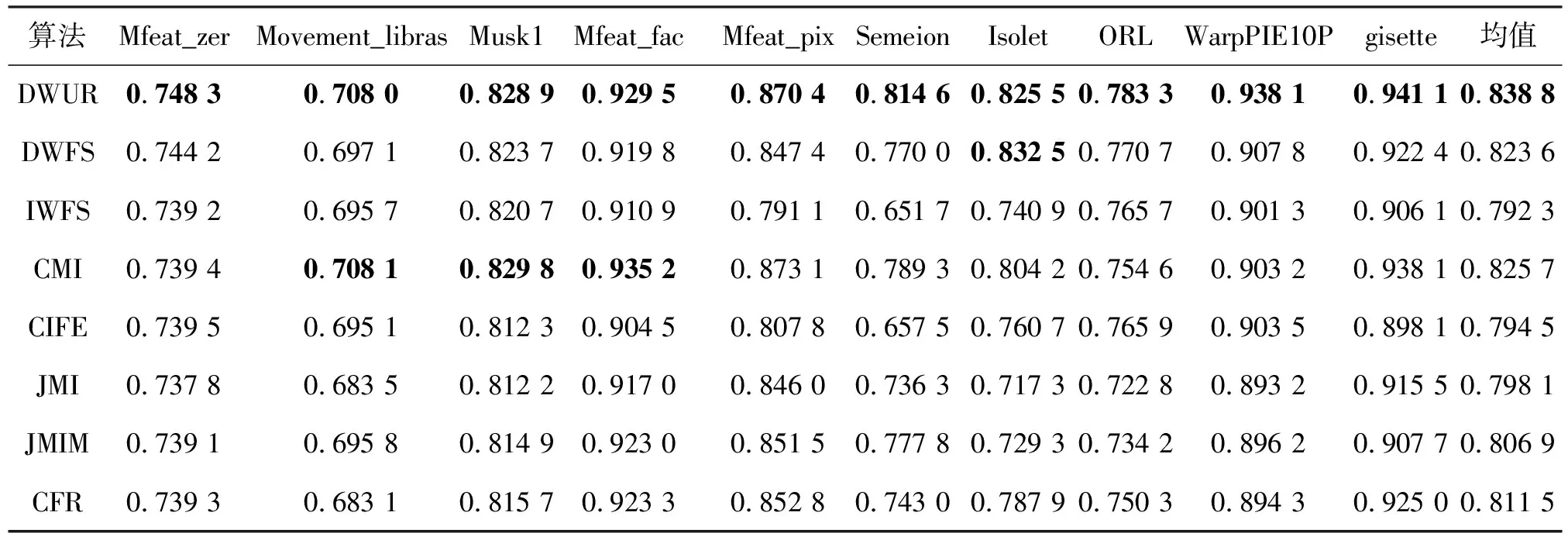
(6)whilek (7) for eachfi∈F (8) 根據式(11)計算各候選特征在當前輪的目標函數值JDWUR(fi)k (9) end for (11) 將fj添加到已選特征集S=S∪{fj} (12) 從候選特征集中將fj去除F=F-{fj} (13) for eachfi∈F (14) 根據式(4)計算冗余性系數 (15) 根據式(9)計算交互性系數 (16) 根據式(10)更新fi的權重 (17) end for (18)k=k+ 1 (19)end while 輸出:已選特征集S (1)~(2)行是初始化過程,設置特征選擇數目閾值K,已選特征數目k= 0,已選特征集S為空集,候選特征集為原始特征集,候選特征初始權重均為1;(3)~(5)行計算每個候選特征與類標簽間的對稱不確定性作為候選特征相關性的指標;(6)~(12)行計算每個候選特征在本輪挑選中的目標函數值,并選擇最大值對應的特征作為被選特征,加入到已選特征集S中;(13)~(19)行根據本輪挑選結果,動態更新候選特征集剩余特征對應的權重,用于下輪選擇中目標函數的計算。 假設原始特征集中特征總數為N,要計算各特征與類別標簽的對稱不確定性(3~5行),時間復雜度為O(N);設已選特征數目為k,則候選特征數目為N-k。在每一輪挑選中,要對每一候選特征計算目標函數值(7~9行),時間復雜度為O(N-k);挑選完成后,計算剩余N-k-1個候選特征對應的相關性系數、交互性系數、更新候選特征權重(13~17行),時間復雜度為O(N-k-1);當預設的特征選擇數目閾值為K時,算法總的時間復雜度為O(NK)。在最壞情況下,當N=K,即依次選取全部特征時,算法時間復雜度為O(N2)。 在10個數據集上對所提算法進行對比實驗,具體數據集信息描述如表1所示。 表1 數據集描述 表1中,前6種數據集來自于UCI機器學習數據集,后4種數據集來自于ASU數據集[14]。實驗選用數據集特征數目分布均勻,Mfeat_zer數據集特征數目最少為47,特征集gisette特征數目最多為5 000。樣本數目分布為210~7 000,類別數目分布為2~40;除Musk1與gisette為2分類數據集外,其它均為多分類數據集。10個數據集中8個為連續數據集,實驗采用MDL離散方法對連續數據集進行離散化。在式(10)中,為保證權重計算結果非負,為交互性系數添加常數項1。為著重考慮特征間冗余性對特征選擇性能的影響,對冗余性系數項中的β參數進行多種取值。實驗證明,在β=0.5時,算法性能較好,因此實驗中β取值為0.5。 利用所提算法和7種基于互信息的算法在上述10個數據集上進行對比實驗,對比算法包括CMI[11]、DWFS[12]、IWFS[13]、JMI[15]、CIFE[16]、JMIM[17]和CFR[18]。其中CMI利用特征的相關性和冗余性構建目標函數,其余算法目標函數中引入了三維互信息來考慮特征的交互性。DWFS、IWFS與文中所提算法同屬于動態更新權重類方法,其特征選擇性能的對比具有代表性意義。 對特征選擇結果通過10次10折交叉驗證方法,分別利用3種分類器C4.5、IB1和樸素貝葉斯進行分類,并計算3種分類器的平均分類準確率。實驗中依次選取前50個特征進行分類,數據集特征數目不足50時選取全部特征進行分類。實驗結果如圖1所示。其中,橫坐標表示依次遞增的所選特征數目,縱坐標表示3種分類器的平均分類準確率。 由圖1可知,所提算法在10個數據集上均取得了不錯的分類結果,說明所提算法對高維和低維、2分類和多分類數據集均具有不錯的特征選擇性能。值得注意的是,相比于DWFS和IWFS算法,由于所提算法在候選特征權重更新系數中增加了特征間冗余性的考慮,所以在WarpPIE10P、gisette、Movement_libras、Musk1、Mfeat_pix、Semeion這6個數據集上取得了明顯優于DWFS和IWFS算法的結果,說明特征間的冗余性是影響特征選擇算法性能的一個重要因素。 圖1 各算法在10個數據集上3個分類器的平均分類準確率 表2進一步列出了各算法在10個數據集上所有分類準確率的平均值,加粗數字表示在該數據集上達到的最好結果。 表2 各算法在10個數據集上所有平均分類準確率的平均值 表2顯示,相比于其他算法,所提算法在所有數據集上分類準確率的平均值均最高。對比于DWFS算法,文中所提算法性能提升明顯,進一步說明了在特征權重更新階段,加入特征間冗余性考慮是有必要的。 表3列出了各算法在10個數據集上所有平均分類準確率的最大值。 由表3可知,文中所提算法在5種數據集上效果達到了最好,而且在另外5種數據集上表現都是最接近最好結果的算法,如在Movement_libras數據集上雖沒有達到最好結果,但是其最高平均分類精度為70.80%,基本等于該數據集上達到最好結果的CMI算法的70.81%。 表3 各算法在10個數據集上所有平均分類準確率的最大值 針對基于互信息特征選擇算法的不足,提出一種采用冗余性動態權重的特征選擇算法。算法除考慮特征相關性和交互性外,還同時利用了特征間的冗余性,以盡可能保證目標函數不丟失有用信息。首先,依據信息理論給出相關性、冗余性和交互性的理論說明和客觀評價指標,給出了算法的實現過程;然后,在10種數據集上采用3種分類器同7種相關算法做了對比實驗。實驗結果表明,相比于其他算法,該算法具有明顯的優勢。由于數據維度高速增長,探究多維特征間的關系,構建更有效的評價指標將是今后工作的重點。3 實驗研究
4 結束語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
