結合互信息最大化的文本到圖像生成方法
2019-11-08 08:21:10莫建文徐凱亮林樂平歐陽寧
西安電子科技大學學報 2019年5期
莫建文,徐凱亮,林樂平,歐陽寧
(桂林電子科技大學 信息與通信學院, 廣西壯族自治區 桂林 541004)
通過自然語言描述自動地生成圖像在圖像生成領域一直都是一項很具有挑戰的任務,在一些應用方面都有著廣泛的需求,比如藝術生成,計算機輔助設計等。近年來,這個研究領域也越來越活躍,并且已經取得了很大的進展。
現階段,生成對抗網絡(Generative Adversarial Networks,GAN)在圖像處理中得到廣泛應用[1]。文本到圖像生成方法主要在生成對抗網絡的基礎上進行研究,研究目的是為了學習從文本語義空間到彩色圖像空間的映射。最初,REED等[2]通過基于條件生成對抗網絡[3]的框架來處理這項任務,方法是將整個文本描述編碼為一個全局的句向量并作為條件進行圖像生成,并且提出了一種新的圖像文本匹配對抗訓練策略,這種方法成功地生成了分辨率64×64的可信賴圖像,但無法生成生動的對象細節。而后,ZHANG等[4]提出了分階段的堆疊式生成對抗網絡(Stacked Generative Adversarial Networks,StackGAN),訓練策略是先繪制對象的大致輪廓,再修補細節和缺陷,生成過程分為多階段生成網絡,最后階段生成分辨率為256×256的圖像,這項策略極大地提高了圖像的生成質量。之后又提出了StackGAN的端對端改進方法StackGAN-v2[5],并進一步對模型的穩定性進行了優化。文獻[6]在這個基礎上提出了與注意力機制聯合的生成對抗網絡,提供了更為細致的圖像-文本匹配損失計算方法。該網絡生成的圖像更加生動,并且與文本描述的匹配度更高。值得注意的是,以上所述方法雖然能生成分辨率越來越高的圖像,更加逼真,并且細節更為豐富,但以上方法的目標優化函數只是在減小生成樣本分布和源樣本分布間的JS散度。該方法可以拉近兩個分布的距離,使生成樣本分布逐漸趨近于源樣本分布,但不能保證整體分布間的相似度。當只有一部分輸入信號在語義層面上起作用時,對訓練是極其不利的。由于生成對抗網絡訓練不穩定且收斂困難,因此很容易出現“模式坍塌”現象,訓練出單一模式的樣本,在文本到圖像任務當中,甚至還會訓練出不匹配和無意義的樣本。
生成對抗網絡模型不穩定的原因主要為訓練過于自由,難以達到納什均衡,導致模型訓練容易陷入局部最優,使得模型只需要生成符合部分模式的樣本就可以滿足目標函數的優化目標。加入有效的全局特征互信息約束和局部位置特征互信息約束,可以使模型對空間結構變得更加敏感,能使該問題得到一定程度的緩解。互信息最大化優化原理[7-8]主張在神經網絡的輸入和輸出之間進行最大化互信息,這可以獲取更為魯棒且均勻的映射關系。文獻[9]中提出的互信息神經估計可以利用神經網絡學習到連續變量的互信息估計,適用于深度神經網絡中的互信息估計。筆者利用互信息對模型進行優化的思想啟發于文獻[10]中提出的可解釋表示學習方法,通過最大化條件變量與生成數據的互信息,使得控制條件變量變化的同時能生成可解釋的圖像特征。另外,估計和最大化互信息的方法主要借鑒了文獻[11]中提出的通過互信息學習深度表示的方法。該方法遵循互信息神經估計,為學習一個可靠的特征表示,最大化輸入數據和高級表示之間的互信息來進行表示學習,并通過最大化輸入的表示和局部位置向量之間的平均互信息來改善分類任務的表示質量。該方法提出的互信息編碼器不需要解碼器,且訓練過程是無監督的。通常生成模型也常用作構建表示的方法[12-14],并且互信息在代表性質量中起著重要作用。
在StackGAN-v2的網絡模型基礎上,利用了互信息與圖像空間結構的聯系,并針對圖像生成任務,改進了最大化互信息方法,設計了一種結合互信息估計和最大化的堆疊式生成對抗網絡模型。模型主要有兩個改進部分,分別為全局互信息最大化模塊和局部平均互信息最大化模塊。在生成對抗網絡模型的輸入和輸出間構建互信息最大化模型,最大化模型中有兩個互信息估計器(即全局鑒別器和局部鑒別器),估計輸入隨機向量和生成特征圖之間的互信息,并分別考慮全局特征和局部特征兩者與全局向量之間的互信息。利用估計器來估計輸入和輸出間的互信息量,將互信息估計量作為互信息正則項加入到生成器損失當中,通過最大化互信息方法約束并優化模型參數間的互信息量。實驗表明這種方法可以有效約束輸入與輸出的全局和局部相關性,緩解“模式坍塌”問題,生成更具多樣性的樣本。
1 方 法
在生成對抗網絡模型的基礎上,結合了互信息估計和最大化優化方法。具體如圖1所示。
圖1中提出的方法有兩個組成部分:生成對抗網絡模型和互信息最大化模型。首先由生成對抗網絡生成不同尺度的特征圖,然后將生成過程最后階段的特征圖與輸入的全局向量進行互信息最大化優化。具體計算方法將在本節的其余部分詳細闡述。
1.1 網絡模型
沿用了StackGAN-v2中的多尺度圖像分布近似和條件與非條件聯合分布近似理論,網絡框架為樹形結構,具有多個生成器來生成不同尺寸的圖像。具體架構如圖2所示。
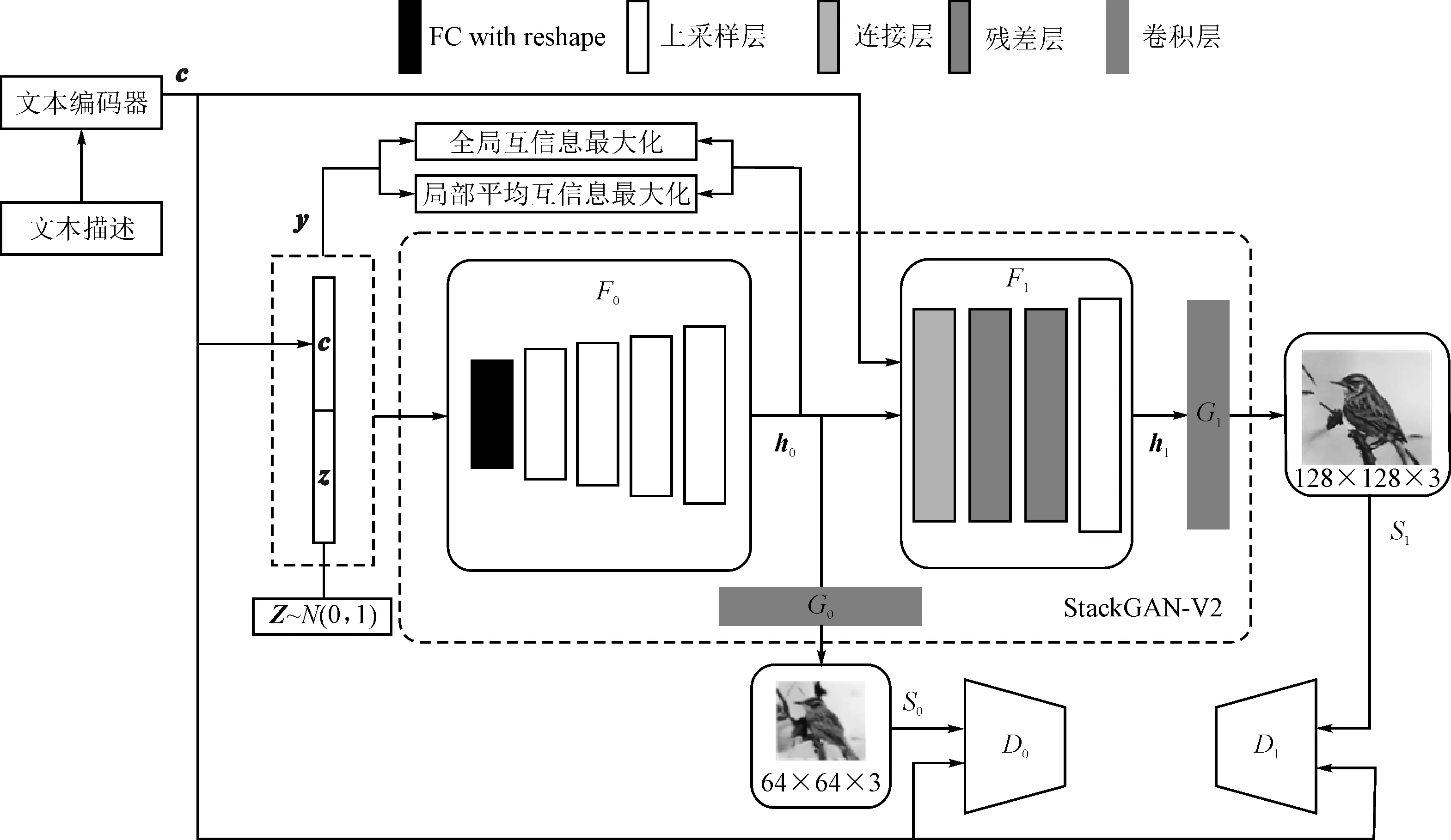
圖2 網絡模型架構
圖2中的大虛線框為輸出128×128分辨率的StackGAN-v2模型。c是條件向量,通過訓練好的文本編碼器[2]將文本描述映射為文本嵌入向量,再進行條件增強[5]處理得到低維條件向量c。首先由條件向量c與高斯隨機噪聲向量z組合得到全局向量y,然后通過StackGAN-v2生成不同尺寸的圖像。F0,G0,D0和F1,G1,D1分別為不同尺寸的生成器和鑒別器。另外,在輸入層y與特征層h0之間進行互信息估計。
過程具體可表示為
(1)
其中,z~N(0,1),為高斯先驗;{h0,h1}表示不同尺度的特征層;{s0,s1}是分辨率逐漸增加的圖像。每個生成器都有不同的鑒別器進行競爭,并學習不同尺度的判別特征。Fi、Gi和Di都被建模為神經網絡。
1.2 互信息估計與最大化
1.2.1 全局互信息估計
文本到圖像任務學習的目標是向量分布Y到源圖像近似分布S的映射。向量y由條件向量c和隨機向量z組成,向量y具有全局信息,而條件向量c在生成過程中起主導作用。圖2中的全局互信息最大化模塊具體如圖3所示。
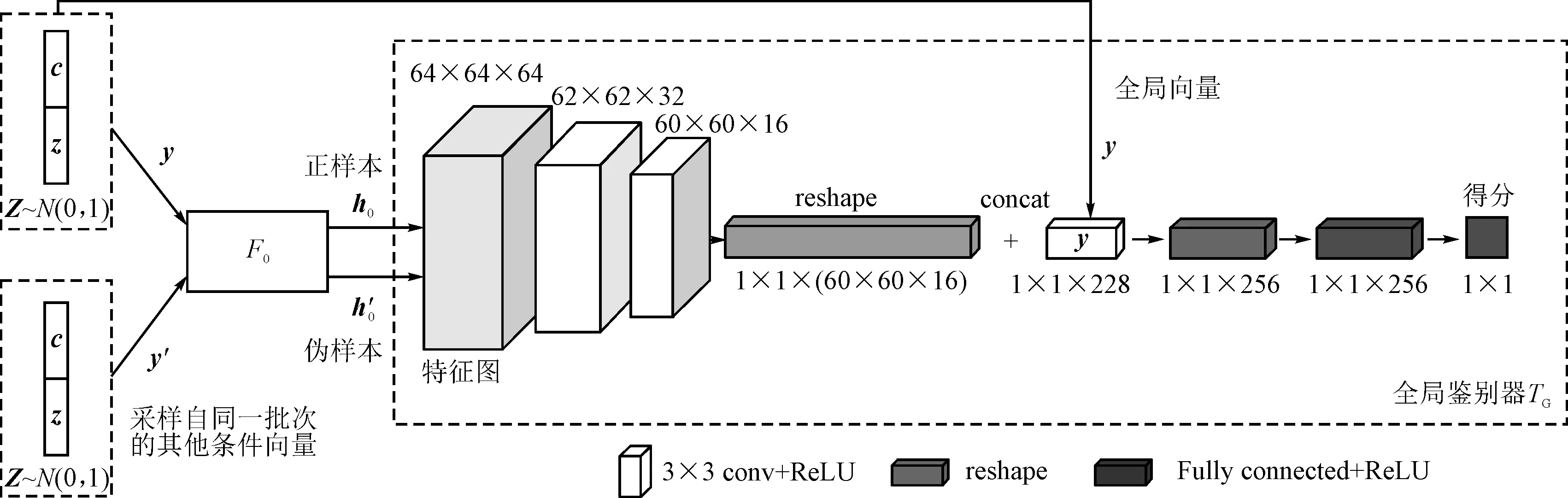
圖3 全局互信息估計示意圖
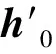
通過圖3中表示的全局鑒別器TG估計并最大化互信息的方法來優化生成器F0,該方法訓練鑒別器來估計互信息并打分,可以定義一個Jensen-Shannon互信息估計量[11,15]:
(2)
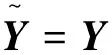
1.2.2 局部平均互信息估計
只進行全局互信息最大化優化通常不足以學習有用的表示。為了保證表示模型能夠適應圖像生成任務,并生成模式更為均勻的樣本,所提方法最大化全局向量與局部位置特征向量之間的平均互信息,提高相同的全局表征與所有局部塊的互信息,構建了局部-全局對,這有利于學習到共享的數據。圖2中的局部平均互信息最大化模塊如圖4所示。
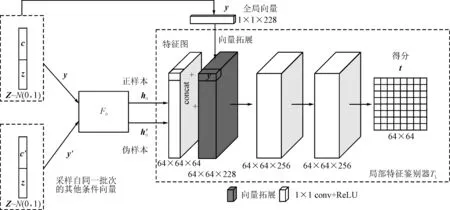
圖4 局部平均互信息估計示意圖
局部平均互信息估計框架如圖4所示。特征圖中的每個位置向量都可認為是一個局部位置特征向量,通過尺寸為64×64的特征映射h0提取得到64×64個具有位置信息的局部位置特征向量,并將全局向量y分別與每個局部位置特征向量連接起來,構建64×64個局部-全局對。正偽樣本生成方式與圖3一致,通過一個局部特征鑒別器TL為每個局部-全局對生成一個得分。
正樣本得分矩陣t可表示為
(3)
其中,M×M為特征映射h0的尺寸,在實驗中設置M=64;TL是由神經網絡建模的局部鑒別器函數;ti,j為特征映射h0第i行第j列的局部位置特征向量經過局部鑒別器TL的得分。式(3)反映了數據中有用的結構(例如空間結構性)。
偽樣本得分矩陣可表示為
(4)
為計算得分矩陣t的平均得分,令
(5)
在局部-全局對上,參照式(2)并結合式(3)、式(4)和式(5),可定義平均互信息估計為
(6)
其中,第1項為正樣本的平均互信息估計量,第2項為偽樣本的平均互信息估計量,總體表現為局部位置特征向量與全局向量的平均互信息估計量。
1.2.3 最大化互信息正則項
在標準的堆疊式條件生成對抗網絡模型中,生成模型的輸入是由一個條件向量(例如文本嵌入向量)和一個連續的噪聲隨機向量(例如標準高斯分布)組合而成的,令其為向量y。由于文本條件類別不明確,存在同一個文本與多張圖片相關和同一張圖片與多個文本相關的情況,生成模型會將不同的輸入y映射到相同的生成樣本F0(y),導致F0(y)僅僅依賴于y的少數維度,從而生成的分布只是真實數據分布的“子分布”。簡單來說,就是因為生成樣本分布過于集中,不夠均勻,為此將全局互信息估計量和局部平均互信息估計量進行最大化優化,利用最大化互信息方法來約束生成器輸入和輸出的特征層,使得y的每個維度都盡可能地與特征映射h0產生特定的關系,迫使生成的分布更趨向于真實分布。
互信息總估計量由全局互信息和局部平均互信息兩部分組成,因此總估計量由式(2)和式(6)可知
(7)
其中,α和β為超參數,設置為0.5和1。
在StackGAN-v2中的多尺度圖像分布近似和條件與非條件聯合分布近似理論下,為最大化互信息,將互信息正則項I(F0(Y),Y)加入生成器優化目標當中,因此可知判別器的最大化優化目標為
(8)
其中,xi來自第i個尺度的真實圖像分布pdatai,si來自相同尺度的模型分布pGi。多個鑒別器并行訓練,前兩項為無條件損失,后兩項為條件損失。
生成器最小化優化目標為
(9)
其中,第1項為無條件損失,第2項為條件損失。
(10)
其中,ρ為超參數,I(F0(Y),Y)為互信息正則項。由于生成器為最小化目標,所以在互信息正則項前加了負號。關于超參數ρ大小對結果的影響,利用實驗進行了詳細分析。
2 實 驗
實驗平臺的配置為 Intel Xeon E5-2687W八核3.1GHz處理器、32GB內存、GTX1080Ti 顯卡以及 Ubuntu 16.04 操作系統,并使用基于Python編程語言的 Pytroch深度學習框架。
2.1 數據集及評估指標
(1)數據集。實驗在數據集CUB[16]上評估了所提出的網絡模型。CUB數據集包含了200類別的11 788張鳥類圖像,其中8 855張樣本作為訓練集,2 933張樣本作為測試集,每張圖像都注釋了10個文本描述。預先訓練的文本編碼器將每個句子編碼為1 024維度的文本嵌入向量,再進行條件增強處理而得到128維的條件向量。
(2)評估指標。選擇多樣性指標值inception score[13]為定量評估指標,評估方法表示為
Is=exp(ExDKL(p(y|x)‖p(y))) ,
(11)
其中x表示一個生成的樣本,y是inception模型預測的標簽。這個指標表示為一個好的模型應該具備多樣性,因此邊緣分布p(y)和條件分布p(y|x)的KL散度應該足夠大。
2.2 實現細節
框架類似StackGAN-v2,類推也可以生成分辨率為256×256的圖像,甚至分辨率更高的圖像。由于分辨率128×128的圖像已經具備了完整的特征和結構信息,而所提出的方法主要針對樣本的空間結構信息進行優化,為了生成更可靠的全局和局部特征,并減輕計算負擔,設置128×128為生成目標的分辨率。從圖1中可知。將隨機向量z與條件向量c級聯組合得到輸入,經過全連接網絡并重組得到4×4×32Nt的特征張量。通過4個上采樣塊得到64×64×2Nt的特征張量,接著經過兩個殘差塊和一個上采樣塊得到128×128×Nt的特征張量,分別經過卷積核為3×3的卷積層得到相應比例的圖像。為增加輸入輸出的相關性,該部分框架額外增加了全局鑒別器TG和局部鑒別器TL來估計互信息的得分。
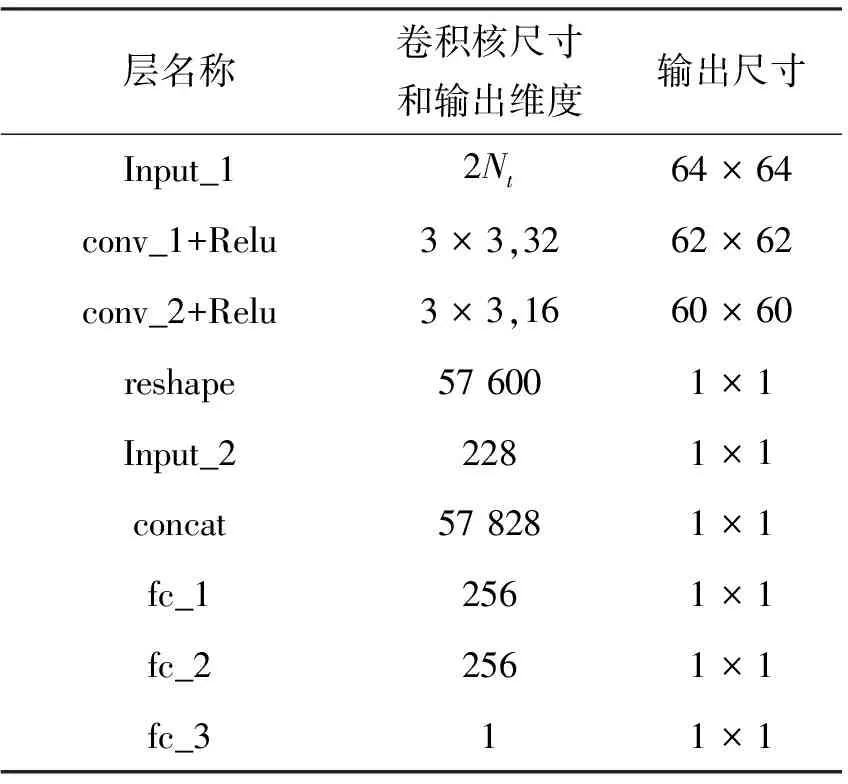
表1 全局鑒別器TG網絡細節
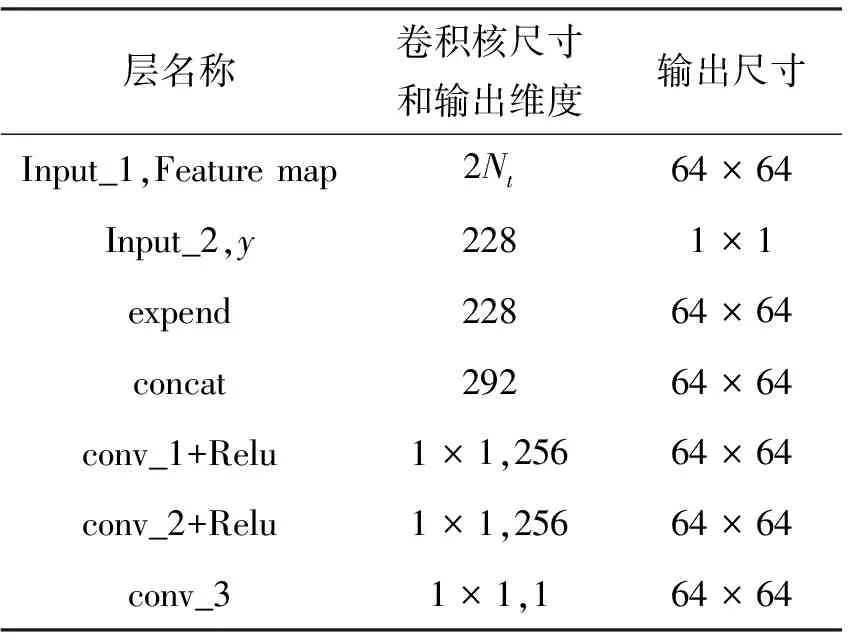
表2 局部鑒別器TL網絡細節
表1和表2中的Input_1和Input_2分別為特征圖和全局向量;表1中的reshape為向量重組的操作;表2中的expend為向量拓展成向量矩陣的操作,表1和表2中的concat為通道相加的操作,conv為卷積,fc為全連接,Relu為激活函數。設置Nt為32。互信息項作為正則項添加到生成器損失當中,全局鑒別器TG和局部鑒別器TL采用學習率為0.000 1的Adam求解器,其余模型均采用學習率為0.000 2的Adam求解器,其中Adam求解器動量皆設置為[0.5,0.999],批次大小為24,迭代600個epoch。
2.3 結果對比
為了證明互信息正則項的有效性,主要通過與各種主流的文本到圖像生成的網絡模型進行結果對比,利用多樣性指標值來衡量模型生成圖像的客觀性和多樣性。按照StackGAN的實驗設置,總共采樣了約30 000張模型生成的隨機圖像來評估模型的該指標。

表3 多樣性指標值對比結果
從表3可以看出,所提模型較之前不同的模型都有了顯著的提高,多樣性指標值較StackGAN-v2提高了0.41,這表明所提模型生成的樣本多樣性明顯強于其他模型。另外,特別詳細地與StackGAN-v2進行了結果比較,定性地比較了兩種模型在不同鳥類測試圖像的文本描述條件情況下生成的相同姿態圖像,結果如圖5所示。

圖5 相同姿態結果對比圖
圖5中結果都是在數據集CUB上得到,筆者所提模型最終輸出尺寸為128×128。比較了StackGAN-v2的兩種不同分辨率輸出,尺寸分別為128×128和256×256。由對比結果可以看出,所提模型在特征方面的處理強于StackGAN-v2。例如,圖5(a)中的樣本,文本中描述為短鳥喙,而StackGAN-v2中128×128分辨率的樣本已經丟失了該特征。在特征幾乎完全固定的情況下,提高分辨率只能增強紋理的細節,而筆者所提模型結果明顯保留了更多語義細節信息。空間結構的邊緣信息可以反映在圖5(b)和圖5(c)中。圖5(b)中文本描述的白色胸部在所提模型中更為明顯且整體性強;在圖5(c)中,筆者所提模型對于灰色翅膀和尾巴的紋理描述和結構的表現都略強于StackGAN-v2;圖5(d)主要表現在整體的色彩和內容上,筆者所提模型生成的樣本更接近原圖;而圖5(e)中,兩個模型都表現出了模式崩潰的傾向,兩者較原圖都有比較大的差距,但筆者所提模型明顯魯棒性更強一些。StackGAN-v2只保留了整體的形狀而完全丟失了局部特征,筆者所提模型還保留了文本描述中提到的鳥嘴。
另外,定性地比較了兩種模型在同一測試圖像的10個不同文本描述條件下生成的圖像。結果如圖6所示。
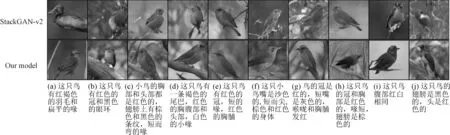
圖6 不同文本描述生成圖像對比圖
圖6表示為同一測試圖像的10個不同文本描述條件下生成的圖像,大致描述了一只小鳥,擁有短鳥喙、紅色的冠和胸部,還有棕色的翅膀。可以觀察出兩種模型都能生成不同姿態的樣本,而筆者所提模型擁有更健全的特征和細節并且魯棒性更強。例如圖6(c)、(e)和(g)的文本描述都提到了鳥喙,StackGAN-v2的生成樣本已經丟失了該特征,筆者所提模型結果保留了較為完整的特征。出現同樣情況的還有圖6(b)中的眼睛和(d)中的尾巴;另外在圖6(b)、(d)、(f)、(g)和(j)中,StackGAN-v2已經出現了明顯的畸形等現象,而筆者所提模型出現該情況的結果相對較少。實驗表明,針對全局-局部特征加入的互信息正則項,有效地加強了局部信息與全局信息的相關性,使生成圖像的局部特征不易丟失,保持了更完整的姿態,模式也更為均勻,也因此提高了生成樣本的多樣性。
另外,對不同的輸入和不同的超參數ρ做了多樣性指標值評估,如表4所示。

表4 不同互信息正則項超參數的多樣性指標值對比結果
表4中Our1方法為直接最大化條件向量c和特征圖h0的互信息,Our2方法將高斯隨機噪聲z與條件向量c組合后與特征圖h0的互信息作為最大化優化目標,其中ρ為式(10)中的互信息正則項的超參數。實驗表明,當ρ=3時,多樣性指標值最大,多樣性最好;當超參數設置過高時,觀察生成樣本發現,部分樣本會出現模式塌陷,導致多樣性變差。結果表明,Our2方法分數高于Our1方法,這說明了不僅僅文本語義對結果有影響,選取的隨機噪聲分布Z同樣對結果也有一定的影響。綜上所述,筆者所提模型最后選擇了Our2方法。
3 總 結
由于文本到圖像任務當中生成對抗網絡訓練困難,常常會出現模式丟失或模式崩潰等現象,導致生成的樣本缺乏多樣性。筆者提出了一種結合局部-全局互信息最大化的堆疊式文本到圖像的生成對抗網絡模型。該模型通過估計全局特征和局部特征兩者與全局向量間的互信息并將其最大化的方法,增強文本描述與生成樣本的相關性,建立更為全面且可靠的映射關系。實驗結果表明,該方法在保證了生成樣本質量不降低的情況下,提升樣本多樣性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
