利用加權詞句向量的文本相似度計算方法
2019-11-09 06:51:26徐鑫鑫劉彥隆
小型微型計算機系統 2019年10期
徐鑫鑫,劉彥隆,宋 明
(太原理工大學 信息與計算機學院,山西 晉中 030600)E-mail:895045514@qq.com
1 引 言
隨著AI技術的迅速崛起,人工智能和隨之而來的海量文本數據對自然語言處理也提出了更高的要求.文本相似度作為自然語言處理領域的一大基礎任務,在搜索引擎、QA系統、機器翻譯、文本分類、拼寫糾錯等領域有廣泛的應用.
文本相似度,顧名思義就是衡量兩篇文本的相似程度.文本作為承載語義信息的一種重要方式,傳統的文本表示采用向量空間模型來表達語義信息,這種方式未考慮到特征詞的順序以及上下文語義理解,造成高維稀疏以及計算效率低的問題.韓如冰等人[1]提出了一種基于關鍵詞的權重改進傳統向量空間模型的權重算法,基于改進索引項權重的向量空間模型除了考慮原有索引項權重還考慮了文檔中關鍵詞的權重.通過特定領域FAQ的檢索測試結果表明,改進的算法很大程度上提高了檢索的查準率、查全率.隨著Harris[2]提出分布假說:“上下文相似的詞,詞義也相似”,引出分布式詞向量的術語.為了解決語義稀疏的問題,Mikolov等人[3]提出了word2vec詞向量工具,使用淺層神經網絡語言模型訓練語料庫得到富含詞語關聯信息的分布式低維實數向量表示.Arora等人[4]使用無標注語料庫訓練得到的詞向量進行加權平均得到句向量,并使用PCA/SVD進行優化,進一步改善了詞向量的表達效果.Kusner等人[5]將詞嵌入和EMD(Earth Mover′s Distance)距離用來度量文本距離,提出了WMD(Word Mover′s Distance)算法以及WCD(word centroid distance)、RWMD(relaxed word mover′s distance)兩種犧牲精度降低復雜度的算法.由于WMD距離算法無法充分提取文本中詞匯的語義信息,因此本文在WMD距離計算的基礎上,聯合使用詞向量和句向量,對WMD距離公式進行相應改進,提出了一種新的計算文本的相似度算法.在三大文本相似度對比試驗中,本文提出的方法的性能優于傳統的同類算法.
2 相關工作
2.1 word2vec
word2vec是Google于2013年開源的一款將詞表征為低維實數值向量的高效自然語言處理工具,便于度量和挖掘詞與詞之間的關系.該工具從大量文本語料中以無監督的方式學習語義知識得到詞向量,意義相近的詞將被映射到向量空間中相近的位置,可采用的模型有兩種,分別為連續詞袋模型(Continuous Bag-of-Words,CBOW)和跳元模型(Skip-Gram).CBOW模型如圖1所示,其輸入層是目標詞的上下文表示,經過投影層的求和累加,在輸出層使用層次化Softmax或隨機負采樣技術(Negative Sampling,NEG)降低訓練的計算開銷提升訓練速度.Skip-Gram模型如圖2所示,與CBOW模型利用文本序列周圍的詞來預測中心詞相反,Skip-Gram模型利用目標詞語預測其文本序列周圍的詞,通過把一個個的詞語當做特征,將特征映射到K維向量空間獲得文本數據更精確的特征表示.CBOW模型適用于小型數據量,而Skip-Gram模型在大型語料庫中性能更高.由于兩種模型簡單高效,word2vec工具可以達到每小時訓練千萬級別的詞向量,因此本文使用該工具訓練語料庫得到詞向量.
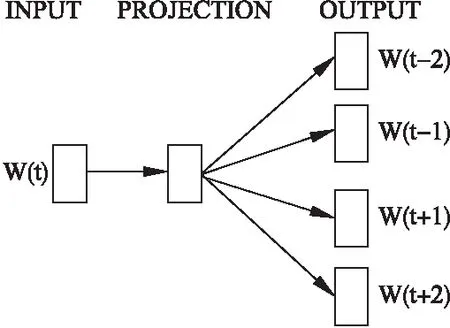
圖1 Skip-Gram模型Fig.1 Model of Skip-Gram
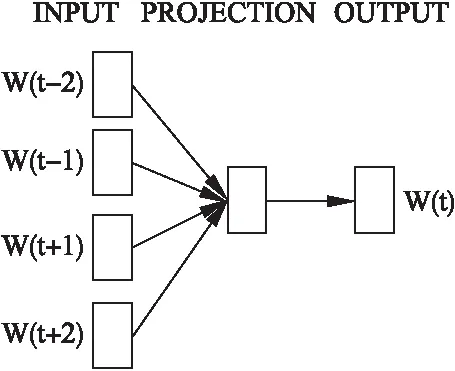
圖2 CBOW模型Fig.2 Model of CBOW
2.2 WR句嵌入
句嵌入將句子編碼為固定長度的密集向量,改善文本數據的處理.一大類為通用嵌入,在大型語料庫上預訓練的句嵌入可以插入到下游的任務模型中.Arora在2017年提出一種構建平均句子的詞向量基線的算法,即WR句嵌入,其中W(smooth inverse frequency weighting)代表權重計算,R(removing the common components)代表移除句中無關成分.該方法采用無監督建模方式,選擇word2vec詞嵌入技術在線性加權組合中對句子編碼,并移除第一主成分上的矢量.首先對語料庫中的每個詞語w計算詞語頻率p(w),采用權重公式賦予每個詞語相應的權重(smooth inverse frequency,SIF),如公式(1)所示:
(1)
式中a為不斷調整的參數.對句中的每個詞向量賦予權重之后,使用主成分分析方法(Principal Component Analysis,PCA)或者奇異值分解(Singular Value Decomposition,SVD)移除句向量中的無關部分,從句子的局部共現中提取語義上有意義的詞的表示.對重分配權重后的詞向量取平均值得到暫時句向量vs,使用公式(2)移除句中無關部分.
vs←vs-uuTvs
(2)
其中,u為句向量構成的矩陣的第一個主成分.該句向量的建模方式是基于文本生成隨意游走模型中的路徑向量,雖然構建方式簡單并且采用了無監督方式,但是在文本相似度上取得了良好的效果.在文本相似度任務中,SIF重分配權重方式要比簡單的拼接詞語效果要好,甚至比一些包括RNN和LSTM在內的有監督復雜模型的實驗效果更為突出.
2.3 WMD距離
由Kusner等人提出了一種新的計算文檔距離的方法:詞游走距離(Word Mover′s Distance,WMD).WMD距離是陸地移動距離(Earth Mover′s Distance,EMD)的一個特例,EMD用來測量兩個分布之間的距離,主要應用于圖像處理和語音信號處理領域.Kusner將EMD應用于自然語言領域,該算法基于訓練好的Word2vec詞向量,使用詞袋模型(Bag of Words,BOW)的歸一化表示文檔D,將詞語之間的歐式距離作為詞語的轉移代價c(i,j),構造詞語轉移權重矩陣Tij表示文檔D中詞語i轉移到文檔d′中的詞語j的比例.因此文檔之間的距離可以描述為運輸成本的最小問題,如公式(3)所示.
滿足:
(3)
WMD距離利用word2vec中的語義信息,實現高度語義共現精確度,并能挖掘出獨立詞之間的語義相關性.由于要計算兩兩詞語的歐式距離,WMD的算法復雜度比較高.
3 基于WMD距離的詞句聯合距離算法
針對WMD算法存在權重機制相對簡單無法充分表示語義信息以及計算復雜度過高的缺陷,本文提出了基于WMD距離的詞句聯合距離算法(WMD-JCS)度量文本間距離.該算法中詞句的聯合建模分別使用增強權重系數賦予詞句不同的權重代替原始算法中的詞頻權重,以充分挖掘單獨詞句的語義以及上下文語境.最后依據篩選出的關鍵詞和句嵌入計算WMD-JCS距離,以此得到文本的相似度度量.
3.1 增強權重系數
傳統的WMD距離在計算時使用詞語的詞頻作為流量轉移總代價,這種權重度量方式較為單一,未能充分整合詞語的語義信息,不同詞語對整篇文檔的貢獻度也不同.因此,本文對權重系數做出了以下改進:詞語的TF-IDF系數、詞性系數、位置系數以及句子的位置系數.
首先考慮詞語的增強權重系數.由于字詞的重要性隨著它在文檔中出現的次數成正比增加,同時隨著在語料庫中出現的頻率成反比下降.由此引入了TF-IDF系數度量每個詞語在文檔中的重要度.某篇文檔中的詞語i的詞頻表示為fi,計算公式為公式(4)所示:
(4)
詞語i的逆文檔頻率表示為idfi,計算公式為公式(5)所示:
(5)
詞語i的TF-IDF系數表示為TF-IDFi,計算公式為公式(6)所示:
TF-IDFi=fi×idfi
(6)
其中T為語料庫的文檔總數,D為某篇文檔,N(i|D)為詞語i出現在文檔D中的次數,N(i)為詞語i出現在語料庫中的總次數,N(D|i)為包含詞語i的文檔數.
詞性是確定一個詞屬于名詞、動詞還是其他類詞性,一個詞的詞性在某種程度上也代表了一個詞在整篇文本中表達語義的程度.根據陳宏[6]對現代漢語同義并列復合詞的詞性、詞序分析,在中文12種詞性中有名詞、動詞、形容詞、副詞、代詞、介詞、連詞七種詞性具有聯合結構.對此七類詞性進行統計,有如下詞性分布表,如表1所示.
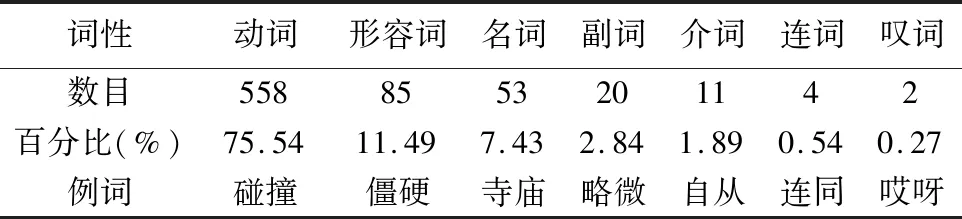
表1 復合詞詞性分布表Table 1 Part of speech distribution on compound word
從表1可知,現代漢語中能標識文本特性的往往是文本中的實詞,如名詞、動詞、形容詞等,在句法關系中占據重要地位,而文本中的一些虛詞對于標識文本會造成一定的噪音.由此本文根據漢語詞性在現代漢語中的分布以及語法規則,設置了相應的等級及詞性權重,詞性權重表如表2所示,除一級和二級特征詞外其余詞性的權重均設為0,某篇文檔中詞語i的詞性權重由Ki表示.

表2 詞性權重表Table 2 Distribution on part-of-speech weight
文章為了揭示主旨通常在首段和尾段提出觀點或進行總結,根據Baxendale[7]的統計結果,段落的主題句為段落首句的概率為85%,為段落末句的概率為7%.因此可根據句子的位置對詞語和句子進行加權,對文本中處于首段和尾段的詞語和句子賦予較高的權重,詞語和句子采用相同的位置權重公式,詞語i和句子S的位置權重分別由Pi和Ps表示,加權公式如公式(7)所示.
(7)
其中,p表示詞語或句子在文檔中所在位置的百分比,a1和a2為可調整的參數,經大量實驗驗證,本文中a1和a2取值0.5和0.7時性能最佳.
由以上對詞語的TF-IDF系數、詞性權重、位置權重以及句子的位置權重的相關定義,本文中詞語的增強權重系數由TF-IDF系數、詞性權重和位置權重三者相乘得到.詞語i在文檔D中的增強權重系數計算公式如公式(8)所示.
Wi|D=TF-IDFi×ki×Pi
(8)
本文中,對句子的權重僅考慮位置的影響,因此句子S在文檔D中的特征權重系數為位置權重Ps.
3.2 WMD-JCS距離算法
3.2.1 算法描述
文本中的詞語并不是同等重要的,根據詞語對文本的貢獻度排序,篩選出一定比例的關鍵詞代表一篇文本.原始的WMD距離計算兩篇文本中兩兩詞語的轉移代價,在本改進算法中精簡為只計算關鍵詞之間的轉移代價.記文檔D和D′的某關鍵詞為Mi,Mj,文檔D和D′中的關鍵詞兩兩計算轉移代價,轉移代價使用歐式距離如公式(9)所示:
(9)
構造關鍵詞轉移矩陣TMiMj表示文檔D中的關鍵詞Mi轉移到文檔D′的關鍵詞Mj中的比例.為了將文檔D完全轉移到D′中,要確保從關鍵詞Mi轉移出的總和等于其增強權重系數,轉移入關鍵詞Mj的總和等于Mj的增強權重系數,如公式(10)和公式(11)所示:
(10)
(11)
最后計算將文檔D中所有關鍵詞完全轉移到文檔D′的關鍵詞所需要的詞轉移成本Ic,如公式(12)所示:
(12)
以同樣的方式構造句嵌入轉移矩陣Tsisj表示文檔D中的句子Si轉移到文檔D′的句子Sj中的量.D中的句子轉移到D′所需的句轉移成本Is要滿足以下條件,如公式(13)所示:
(13)
WMD-JCS距離算法的目標就是最小化詞和句轉移成本Ic和Is,兩篇文檔的距離即采用公式(14)計算.最終根據WMD-JCS距離得到文檔間的相似度度量,如公式(15)所示:
(14)
(15)
3.2.2 文本相似度計算流程
由以上對計算文本距離的計算方法得到文本相似度計算流程如圖3所示.首先對文檔進行去停用詞、分詞、詞性標注等預處理操作;其次使用word2vec工具訓練語料庫得到每個詞的詞向量,根據WR句嵌入由詞向量得到文檔的句向量;對詞向量和句向量進行WMD-JCS距離計算,最后得到文本相似度.
4 實驗與分析
4.1 實驗設置
為了驗證上述文本相似度算法的有效性,本文選取三個英文數據集和一個中文數據集進行實驗.英文數據集testI選取自20Newsgroups共20個類別,訓練集有11293篇文檔,測試集有7528篇文檔;數據集testII選取自Amazon reviews下的藝術、珠寶、辦公用品以及音樂設備等四大類共310090條評論,每類抽取1000條評論作為測試集;數據集testIII選取自Reuters-21578的R8版本,該版本由Cachopo[8]整理,訓練集5485篇文檔,測試集2189篇文檔;中文數據集testIV選取自復旦大學李榮陸提供的文本分類語料庫,9大類共7196篇文檔,每類抽取200篇文檔作為測試集,剩下的文檔為訓練集.實驗中首先對中英文語料庫進行一系列預處理操作,然后使用genism中的word2vec訓練詞向量,其中選用Skip-Gram模型和負采樣技術,上下文窗口和詞向量維數分別設置為5和300;得到詞向量文件后,使用訓練好的詞向量對文本進行句向量訓練,WR句嵌入的系數a設置為1e-4.對每篇文檔提取每個詞語以及句子的位置計算詞語以及句子相應的權重系數,采用WMD-JCS距離算法計算兩篇文檔之間的距離,基于此計算兩篇文本的相似度.
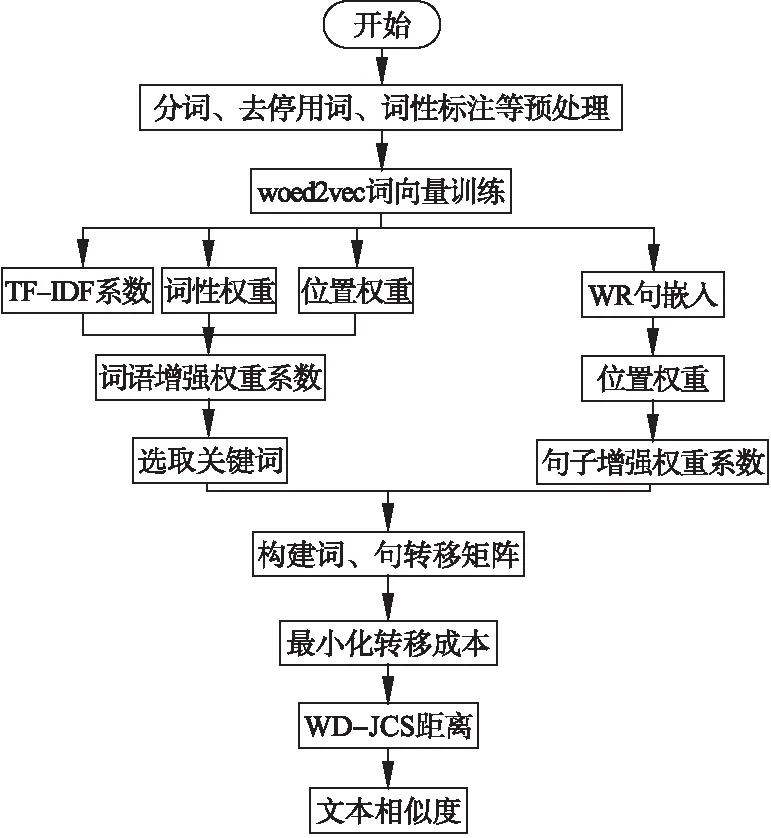
圖3 文本相似度計算流程Fig.3 Process of text similarity calculation
4.2 實驗結果及分析
實驗1.首先要確定WMD-JCS算法中選取不同數量的關鍵詞對文本相似度計算的影響.本實驗選取聚類算法中的K-means、DBSCAN、AHC算法進行實驗對比.實驗結果如圖4所示,給出了在使用K-means等三類聚類算法的實驗條件下,觀察選擇不同數目的關鍵詞對聚類效果的影響.
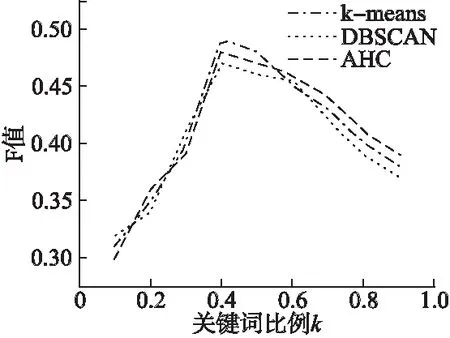
圖4 關鍵詞比例對比圖Fig.4 Keywords ratio
實驗表明,如果選取文本40%的關鍵詞能夠取得更好的聚類效果,低于這個比例則由于選取的關鍵詞數目較少,使得提取的文本信息無法表征文本,造成聚類效果欠佳;超過這個比例則會因為引入過多的冗余信息使得文本之間的獨立性降低,使得聚類效果因為關鍵詞數目增加而不理想.
實驗2.為了驗證WMD-JCS算法的有效性,該實驗選擇另外兩種具有代表性的文本相似度算法作為對比,分別為Kenter[9]提出的分類器計算法(實驗中用Classifier表示)和Yuan Sun[10]等提出的WVM模型.實驗結果如圖5(a)、圖5(b)和圖5(c)所示,分別給出了3種算法在各數據集上的準確率、召回率和F值的分布.
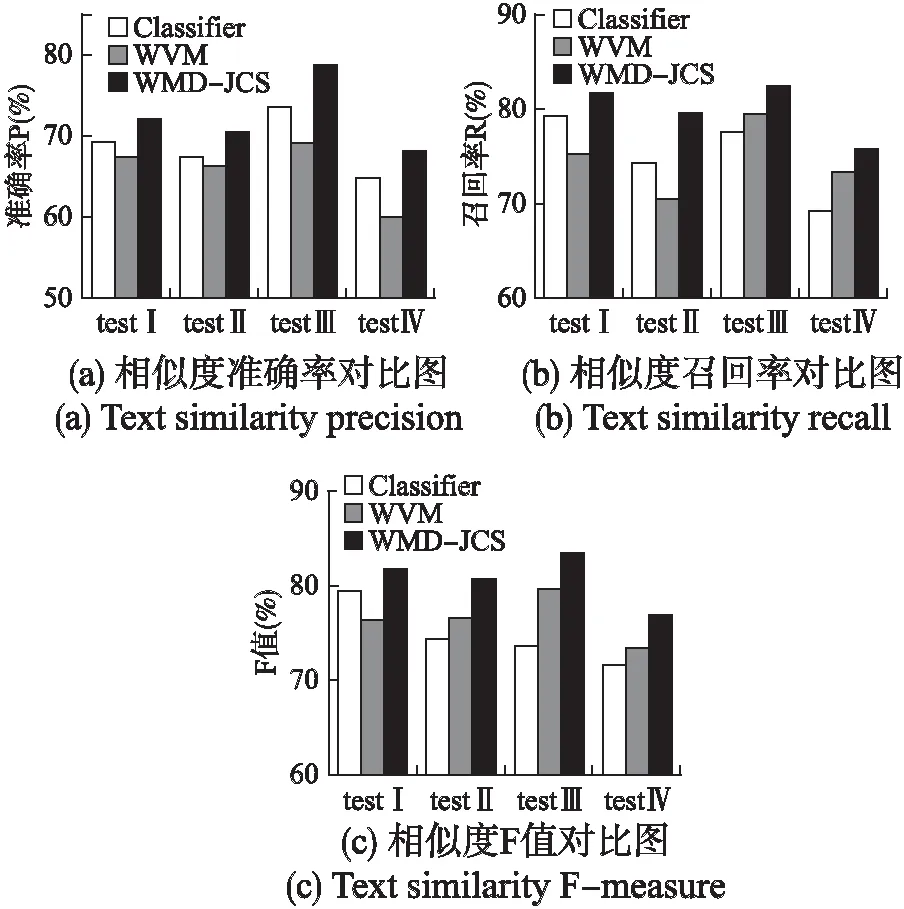
圖5 相似度對比圖Fig.5 Text similarity
從該實驗的三組結果圖來看,通過與另兩種相似度計算方法進行對比分析,采用不同的文本相似度計算方法得到的結果不同.較總體而言,WMD-JCS算法的計算結果都要比Classifier分類器和WVM方法好.與Classifier分類器和WVM相比,由于WMD-JCS距離使用語義挖掘度較高的詞向量和句向量來準確計算詞語間的游走距離,并考慮了不同詞語的語義貢獻度,以達到充分利用文本間的語義信息的效果,因此在三大評判標準上的表現效果要優于另外兩種文本相似度計算方法.同時可以看到在中文數據集testIV上的實驗結果沒有英文數據集的效果好,這是因為中文的句子結構復雜多變,句法、詞序以及處理語料的過程都會影響最終的相似度計算結果,但在3種算法中仍然是最優的.
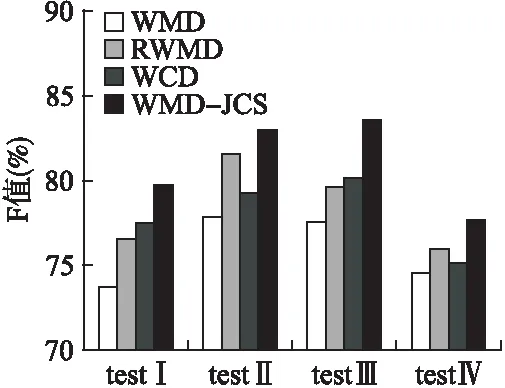
圖6 聚類F值對比圖Fig.6 Cluster F-measure
實驗3.該實驗選取在K-means聚類算法下驗證WMD-JCS算法的有效性.實驗結果如圖6所示.
該實驗與原始的WMD距離算法以及另兩種提升WMD算法效率的方法進行對比,WMD-JCS算法的F值較其他三種方法有顯著提高,尤其是在testIII數據集下,該算法性能提升最明顯,取得了相對較好的結果.這是因為WMD-JCS算法在WMD算法的基礎上,將權重因子由單一的詞頻提升為語義信息提取度更高的增強權重,并充分融合詞語的上下文語義,降低詞語間的冗余度,使得計算出的轉移距離能夠精確代表兩篇文本的關鍵信息,同時改進后的算法由于降低了語義冗余度,在時間復雜度上要比原始算法低.
5 結束語
本文提出了一種基于WMD距離的詞、句聯合距離算法.與原始WMD算法不同,該算法使用word2vec訓練得到的詞向量與WR句嵌入訓練得到的句向量聯合構建特征權重系數,并基于此改進WMD距離計算公式計算文本間距離.該方法引入了句向量,充分考慮文檔的語義完整性,并賦予詞句不同的權重表示不同詞句對文本的語義貢獻程度,選取一定比例的關鍵詞降低語義冗余度,使得結果更加準確.實驗結果表明,本文方法可以提升原始WMD距離計算結果的準確率,同時優于其他文本相似度計算方法.該方法仍然有不足之處,下一步將考慮詞序以及詞的內部結構等特征,以及繼續優化權重系數的各項參數進一步提高計算的準確性.
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
當代修辭學(2011年6期)2011-01-29 02:49:50
