融合掩碼約束算法的Spindle Net行人重識別網絡
2019-11-23 08:46:50吳丹方明付飛蚺
長春理工大學學報(自然科學版) 2019年5期
吳丹,方明,付飛蚺
(長春理工大學 計算機科學技術學院,長春 130022)
行人重識別是指在不同攝像機下進行同一行人的查找和匹配,其主要應用在公共安全領域。雖然行人重識別技術已經發展了20多年,而且目前對其的研究工作也越來越多,但是依然有很多沒有很好解決的問題,由于行人重識別是在多個攝像機下進行匹配,這會造成很多問題,例如被遮擋、不同攝像頭下的位姿變化和相似的不同行人間的區分等。
本文在Spindle Net[1]網絡的基礎上導入了行人的掩碼策略。Spindle Net能較好解決遮擋和位姿問題,所以本文以Spindle Net為基礎加入掩碼信息,與一般的行人重識別方法相比,由于添加的行人圖片的掩碼圖中含有很多隱含的信息,掩碼邊緣特征作為圖片中行人最基本的特征之一,將其應用到神經網絡中進行特征提取,有助于提取到更多特征,抑制冗余或干擾的特征,在提取更多隱含特征的同時去除背景的干擾并且減少圖片的噪聲干擾,并在后續減少不必要的數據量處理,最終使得重識別準確率有所提升。本文使用Mask R-CNN來提取行人掩碼圖,該方法對目標的分割十分精確,為目前效果最好的幾種方法之一[2]。本文方法與目前集中行人重識別方法相比,準確率有明顯提升。
1 相關工作
對于行人重識別問題的研究可以追溯到1996年,主要針對的是無重疊的監控視頻,即多相機追蹤[3]。2006年澳大利亞國家信息與通信技術研究所首次提出行人重識別這一概念,此后行人重識別就成為機器視覺領域的熱門研究問題。Gheissari等人[4]通過對行人圖片的研究和分析,提取到了行人外貌中的穩定區域,主要為行人的顏色和邊緣特征,然后使用三角模型對行人的特征進行匹配。Weinberger等[5]提出了LMNN方法,該方法類似于支持向量機方法[6],同類間距離盡可能小,不同類間隔盡可能大。Dikmen等人[7]在LMNN的基礎上提出了改進的LMNN-R算法。Li等[8]定義了多種行人服飾的屬性,并將LFDA方法應用其中。Zheng等[9]將尺度學習與行人重識別技術融合,提出了PRDC這種改進的距離度量學習算法。Matsukawa等[10]提出了GOG方法,主要是通過像素點分布來表征行人。
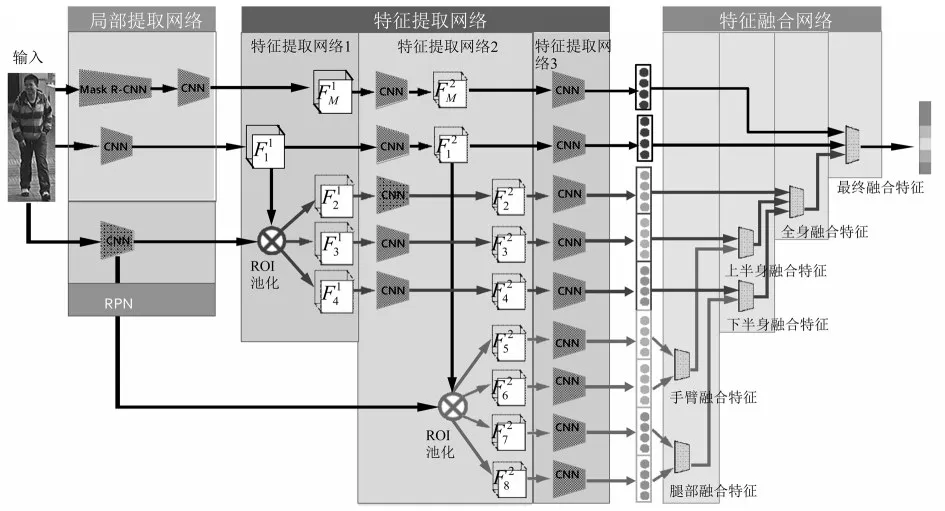
圖1 網絡結構
現階段的行人重識別技術,只提取行人的全局特征的模型已經達到瓶頸,目前大多都使用局部特征模型。Rahul等[11]將行人圖片進行水平分割,分別放入LSTM網絡中各自提取特征,最后再將其融合。Zhao等[12]提出了一種類似attention models的思想,旨在只對圖片中的行人進行處理,而非整張行人圖片。Wei等[13]提出了一種類似于Spindle Net的方法,不同點在于Spindle Net是對整體損失進行計算,而該方法是對不同部分分別計算其損失。
2 網絡模型
本文將掩碼圖與已有的行人重識別網絡Spindle Net相融合。網絡結構如圖1所示,主要分為三部分,局部提取網絡、特征提取網絡與特征融合網絡。
2.1 局部提取網絡
局部提取網絡主要分為兩部分,一個是掩碼提取部分Mask R-CNN網絡,另一個是骨架提取網絡RPN。Mask R-CNN是一種用于實例分割的速度較快且準確率較高的方法,能準確輸出目標區域的掩碼圖。RPN是一種基于串行化的全卷積網絡結構,通過使用卷積層學習紋理信息和空間信息進行人體姿態估計。CNN由3個卷積層、1個Inception模型構成。
Mask R-CNN是在Faster R-CNN的基礎上加入了輸出目標掩碼的功能,其網絡框架主要分為三個部分,首先是目標檢測,就是直接在圖片上繪制邊界框(bounding box)。其次是對每個邊界框中的目標進行分類,本文中使用到的是人的分類。最后是對目標進行像素層面上的分割,輸出行人的掩碼圖。掩碼圖經過CNN網絡后得到原始圖片經過CNN后得到
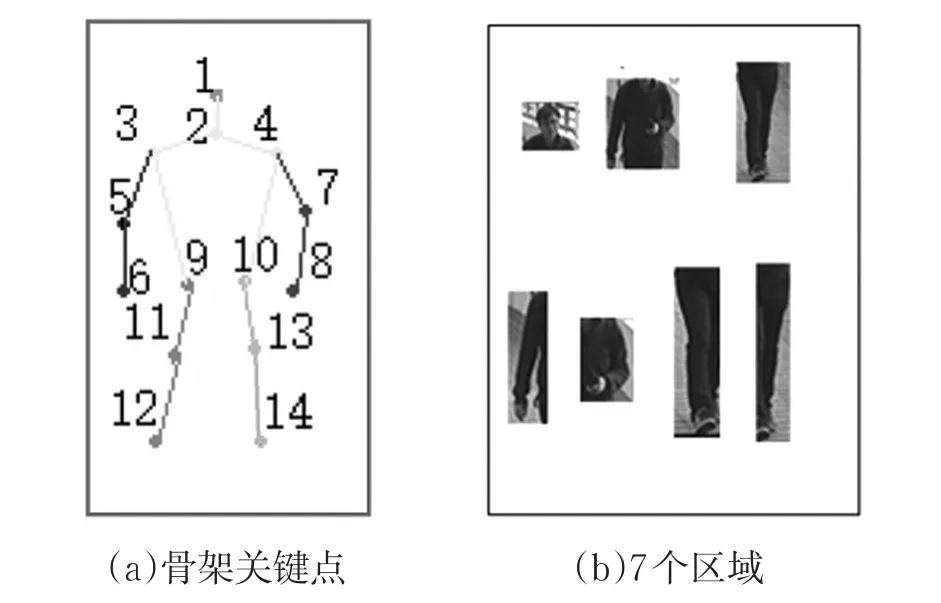
圖2 局部提取網絡中的提取區域
RPN是用來定位人體的14個關節點,關鍵點如圖2(a)所示,通過這14個關節點將人體分為7個區域,其中宏觀區域為:頭部區域F2=[1 , 2,3,4]、軀干區域F3=[3 , 4,5,6,7,8,9,10]、腿部區域F4=[9 , 10,11,12,13,14]。微觀區域為:左臂F6=[4 , 7,8] 、右 臂F5=[3 , 5,6]、左 腿F7=[9 , 11,12]、右腿F8=[1 0 ,13,14],7個區域如圖2(b)所示。
2.2 特征提取網絡
經過特征提取網絡(FEN)處理后得到包含整體行人、掩碼圖和七個局部區域在內的9個256維的特征,FEN包含3個網絡,特征提取網絡1(FEN1)、特征提取網絡2(FEN2)與特征提取網絡3(FEN3)。
FEN1是由1個ROI pooling構成,將F2、F3、F4依次與進行ROI池化得到,經過FEN1后,統一輸出大小為24×24的5個特征圖;FEN2由1個Inception模型和1個ROI池化所構成的,在FEN2中將上一層網絡中的輸出作為輸入,得到再將與區域提取網絡中的部分輸出F5、F6、F7、F8作為輸入,分別與進行ROI池化從而得到,經過FEN2后,統一輸出大小為12×12的9個特征圖。FEN3是由1個Inception模型、1個global pooling層和1個Inner product層構成,以上一層的所有輸出作為輸入,得到9個256維的特征。
2.3 特征融合網絡
特征融合網絡采用對應元素取最大值的方法將FFN中輸出的9個256維特征,融合成1個256維特征,用該特征表示輸入行人的最終特征F。融合過程如圖1所示。
3 實驗結果及分析
本文的實驗是在裝載有兩個NVIDIA GEFORCE GTX 1080 GPU顯卡的電腦上,在Ubuntu 16.04系統下的Caffe環境中運行,本文采用與JSTL相同的設置來生成訓練、驗證和測試圖像集/候選圖像集樣本,訓練和驗證集中的行人與所有數據集的測試集行人沒有重疊。將PSDB與CUHK02數據集也作為訓練樣本,但是不用來做測試。在訓練過程中本文采取與Spindle Net相同的策略即分步訓練方法,該方法是在訓練時將所有數據集整合到一起,然后打亂順序對其進行訓練。
圖3為Mask R-CNN掩碼提取情況,由圖可知,該方法的行人掩碼提取十分準確,其對后續的特征提取有很大幫助。

圖3 Mask R-CNN掩碼示例
本文分別在 Shinpuhkan[14]與 Market-1501[15]數據集中進行了測試,采用CMC評估方法,對重識別的準確率進行對比。實驗結果如表1與表2所示所示。
從表中可知本文方法在Shinpuhkan數據集中Top-1的準確率有大約5%的提升,而在Market-1501數據集中Top-1的準確率有2%的提高。
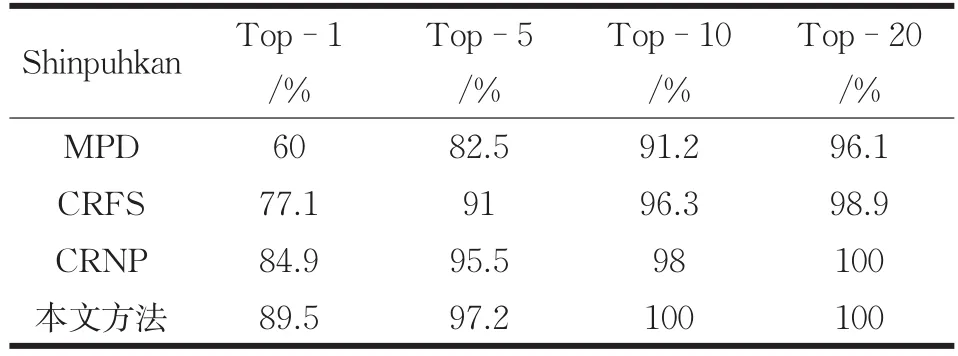
表1 Shinpuhkan方法準確率對比

表2 Market-1501方法準確率對比

圖4 CMC曲線準確率
為了更直觀的表述本文方法與其他方法的準確率,針對不同的數據集,繪制了不同方法在該數據集上的重識別準確率,如圖4所示,4(a)為包含本文方法在內的四種方法在Shinpuhkan數據集的準確率對比,可以很直觀的看出本文方法對比準確率較高的方法,Top-1的準確率有5%左右的提升,4(b)是在Market-1501數據集中的準確率對比結果。該方法在各個數據集中Top-1的準確率平均有3%的提升。
4 結論
本文在現有準確率較高的行人重識別方法Spindle Nec的基礎上引入掩碼圖,使得重識別的準確率平均提高3%左右,證明該方法對重識別的準確率有一定提高,但同時還有很大改進空間,下一步會對該方法進行更進一步的改進,例如對網絡結構進行進一步的精簡,或者對網絡參數進行微調以繼續提高重識別的準確率。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
