CNN與LSTM結合的語句級情感極性分析模型研究
2019-12-05 08:40:44韓碩蒿紅可
無線互聯科技 2019年17期
關鍵詞:深度學習
韓碩 蒿紅可

摘 ? 要:CNN與LSTM在情感分析任務中已有廣泛應用,但單獨應用CNN與LSTM模型時,模型自身的局限性限制了任務最重的分類準確率。文章結合CNN與LSTM,設計了兩種情感極性分析模型,并對兩種模型進行了論證。最后分別在兩種數據集上測試了模型,并將結果與常規模型進行了比較。測試結果表明,這兩種模型相比常規模型均達到了更高的分類準確率。
關鍵詞:情感分析;自然語言處理;深度學習
近些年,因分布式數據存儲技術的發展,大量數據被存儲下來,特別是各個論壇、博客、微博、Twitter和電商平臺用戶產生的在線評論等文本數據。自21世紀以來,情感分析成為自然語言處理(Natural Language Processing,NLP)中最活躍的研究領域之一。由于情感分析的研究對象多為人類語言,又因其對商業和管理、社會的重要性,其研究已經從計算機科學擴展到管理科學與社會科學,如政治學、市場營銷學、金融、通信、健康科學甚至歷史。這種擴散是自然發生且重要的,正確認識這些人類活動,對本文對事物的看法和未來的決策有著重要影響。
本文將使用深度學習模型在Twitter數據集(英文)與電商評論數據集(中文)上實現情感極性分類。任務目的是將數據集中的每一條文本準確分類為“積極情感”或“消極情感”。
本文將引入多個深度學習模型,并且在本文收集到的數據集基礎上實現情感分類任務,觀察其不同表現。本文還探究了兩種比較流行的深度學習模型的組合在情感分類任務上的使用效果,設計了兩種組合模型,與其基礎模型和基于統計的方法作了比較。
1 ? ?CNN與LSTM簡介
2006年Geoffrey Hinton[1-2]等提出了多隱層的人工神經網絡,它相比淺層的神經網絡具有優異的特征學習能力。多層次的網絡模型成為之后許多模型的主要架構。隨著深度學習技術的發展,之后又相繼出現了堆棧自編碼[3]、更深層的卷積神經網絡(Convolution Neural Networks,CNN)、循環神經網絡(Recurrent Neural Networks,RNN)等深度學習模型。CNN最初在圖像領域內取得了卓越的成績。Kim等[4]使用CNN對文本進行分類,也取得了很好的效果,證明CNN同樣可以抽取文本的特征信息。Lee等[5]使用RNN與CNN訓練文本的向量,通過前饋神經網絡實現文本分類,取得了相對較好的準確率,證明了在文本任務中,文本序列特征同樣重要。普通RNN雖然可以有效利用較短的上下文特征[6-7],但缺點較為明顯,在訓練時存在梯度消失的問題,所以不能處理句子中的長依賴特性。為解決這一問題,RNN出現多個變種循環神經網絡模型,如長短時記憶網絡(Long-Short Term Memory,LSTM),可在文本上提取比普通RNN更長距離的語義特征。本文的研究著重基于CNN與LSTM兩種基礎模型。
1.1 ?卷積神經網絡
卷積神經網絡最初因解決圖像問題而出現,近幾年,在自然語言處理領域中也有廣泛應用。CNN可以從原始數據中抽取局部信息。例如,CNN可以在不受圖片布局的影響下,以很高的準確率判斷一張圖片里是否有一只貓[8]。
基礎的CNN模型由卷積層、池化層、全連接層構成。原始數據被輸送到卷積層,這些數據可以是多重維度的,如彩色圖像的紅、綠、藍3個通道。卷積層中的多個卷積核可以橫向、縱向滑動,從而實現對數據進行局部采樣,采樣后的信息在池化層中池化。池化后的數據維度一般會大幅縮小,這些信息最終被送到全連接層,全連接層負責最后的數據處理。
在對文本進行卷積操作前,原始文本被詞向量層表示為本文矩陣K,維度為l×d。其中,l為文本的最大長度,d為詞向量的維度。CNN通過卷積核Wn×h×d對Kl×d編碼,此處n是卷積核的個數,h是卷積核的高度,在文本處理任務中,卷積核寬度d通常等于詞向量維度。在卷積層中,卷積核Wi在K中滑動取樣,i=1,2,…n。在文本的處理中,由于字、詞轉化成的詞向量維度一般是固定的,所以卷積核通常不會在詞向量維度上滑動采樣,而只是在詞的維度上滑動。卷積層的輸出為O={o1,o2,…,on},o的維度與每個卷積核的尺寸、步長有關。在池化層中,建立像卷積核一樣可以滑動的矩陣窗口,此窗口在oi上滑動,此處i屬于1,2,…,n,對在窗口內oi的部分使用最大池化方法,保留窗口的最大值,池化層輸出為P=[p1,p2,…,pn]。將P中的向量平鋪,再使用全連接層及softmax運算得到最后的分類。
1.2 ?長短時記憶模型
長短時記憶模型是一種循環神經網絡模型,該模型擁有記憶前序狀態的能力,所以特別適合處理序列問題。由于訓練算法通常是基于梯度的,在序列較長的數據上,原始的循環神經網絡模型在訓練時往往會產生梯度消失。為了解決這個問題,LSTM在神經元之間添加了“記憶細胞”,“記憶細胞”直接貫穿于整個神經元之間,只參與少量的線性運算,每個神經元通常通過“輸入門”“輸出門”“遺忘門”獲取或控制“記憶細胞”中的內容。
首先,句子中的詞被表示成維度為d的詞向量,文本被編碼成l×d的文本矩陣。這些向量被逐步輸送至神經網絡中。第步數為t時,遺忘門根據當前步的輸入計算出記憶細胞中哪些信息可以被遺忘,σ為sigmoid函數,最終輸出一個0~1之間的數值,公式如下:
輸入門由兩部分組成:第一部分,計算當前輸入的哪部分需要更新,第二部分,創建一個初始的待更新向量。
經上述操作后,更新細胞狀態為:
輸出層會基于細胞狀態計算輸出。首先,輸出層計算細胞中被輸出的部分:
其次,將細胞狀態通過tanh函數運算得到﹣1~1之間的值,并與上部分的結果相乘,得到最終輸出的部分:
因這些門可以控制信息的流入與流出,記憶細胞可以儲存比一般的RNN更長的序列信息,LSTM在處理文本任務中有著獨特的優勢,它可以綜合上下文重新對文本進行編碼。在情感分析任務中,它可以準確處理情感比較復雜的語句。
1.3 ?數據集
1.3.1 ?推特數據集(英文)
推特數據集是Neik Sanders創建的“Twitter情感語料庫”,共有229 484條已標記數據,使用樸素貝葉斯方法得到的最高正確率為65%。
1.3.2 ?商品評論數據集(中文)
商品評論數據包含約25 000條電商買家評價,所有數據已標記,其中,積極情感、消極情感文本分別占所有數據集的50%。
2 ? ?模型設計
由于CNN具有抽取局部信息的能力,可以無視位置而對情感詞和詞組進行抽取,LSTM可以依據順序處理情感特征。基于以上考慮,本文結合了CNN與LSTM模型進行探究。
2.1 ?CNN+LSTM
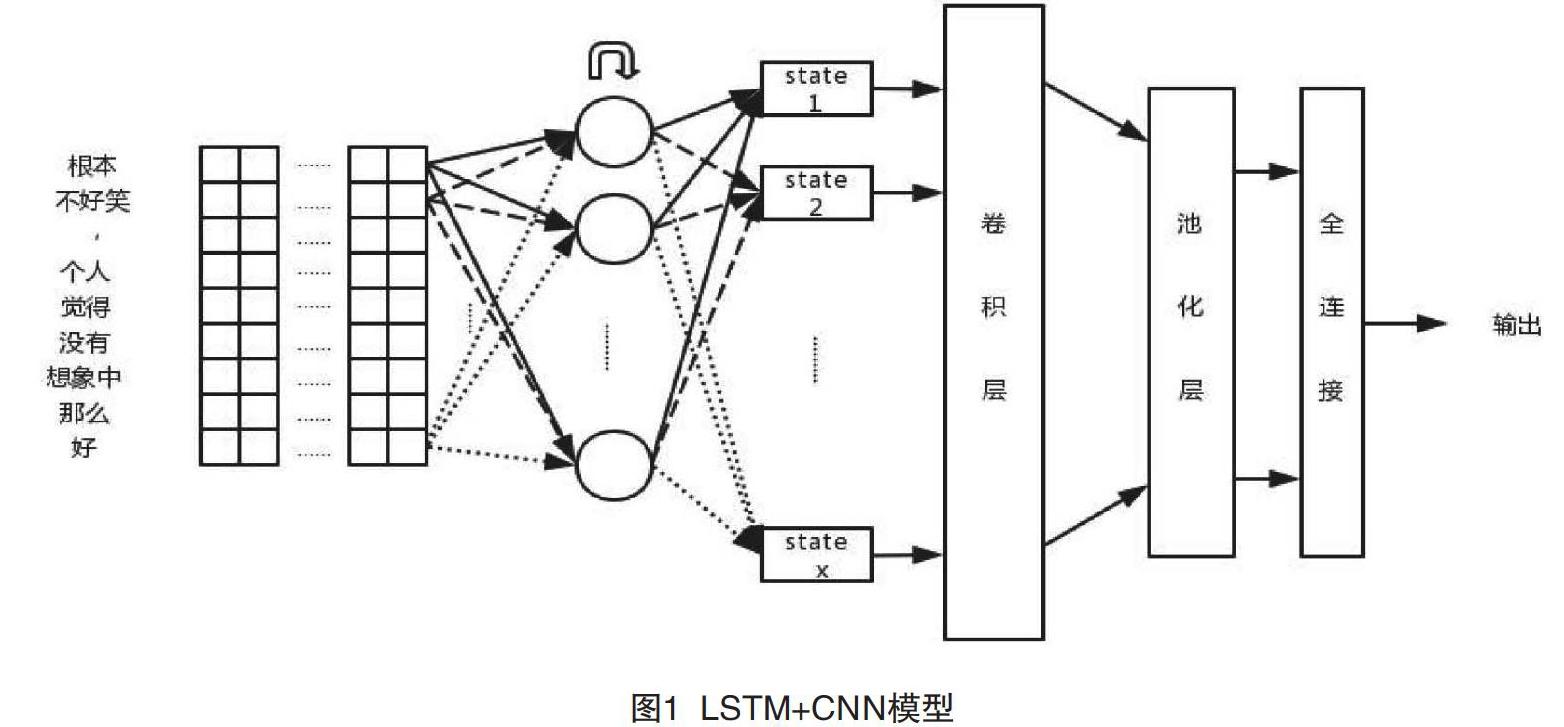
因為決定文本情感類別的情感詞只在文本局部出現,所以實際中有一部分文本對情感分類任務是無用的,首先,CNN可以從原始文本中提取局部的情感信息;其次,利用LSTM序列分析能力對整體文本作出情感判斷。最后,用CNN抽取局部信息可以縮短LSTM的輸入序列長度,避開LSTM無法處理長依賴的缺陷。本文基于情感分類語料庫長度的考慮與兩種基本模型的特點,設計了CNN-LSTM模型(見圖1)。
此模型包含CNN與LSTM兩部分。文本為CNN設計了多個尺寸的卷積核,在尺寸相同的卷積核上使用不同步長的采樣策略,可以讓CNN以不同的尺度感知文本中的情感因素。矩陣K被輸送到CNN中,經過卷積操作后得到O={o1,o2,…,on},其中,n等于卷積核的個數,即有n×d個參數。視卷積步長而定,使用不同尺寸的卷積核可能會導致O中的向量維度不統一。文本根據o1,o2,…,on的維度,使用不同尺寸的池化窗口,使池化后的向量維度相等,得到P=[p1,p2,…,pn]。在Kim等的研究中,CNN模型在池化層在對卷積結果進行池化時,將每個卷積核的結果進行整體池化,Kim等稱之為Max-over-time。為了保存文本的序列信息,本文在池化操作時沒有采用Max-over-time方案,而采用了小窗口的池化采樣,這種池化方式可以使每個卷積核保留若干值組成的序列,以供LSTM提取序列特征。由于P中的每個向量還保存著原始文本的序列信息,故在重排列層將P做一次轉置操作得到PT,緊接著PT被送到LSTM的輸入層,LSTM會試圖學習情感特征之間的序列關系。取LSTM的最后一步狀態F1×λ,其中λ為神經元個數。在softmax層中,先讓F與Wλ×cF做點擊運算到L1×c,其中,c是情感類別個數,WF是待評估參數,在本文的實驗中取c=2。再對F做softmax計算,得S=[s1,s2,…,sc],其中,,i,j∈L;η=1,2,…,c。S中各個元素的數值即為原文本屬于各個情感類別的概率。
2.2 ?LSTM+CNN
LSTM可以依據其強大的序列處理能力對詞向量進行重新編碼,編碼后的詞向量擁有更為豐富的上下文表達。CNN可以進一步提取這些信息的局部信息,從而給出更準確的情感分類結果。
首先,文本矩陣K被輸送到LSTM中,得到LSTM每一步的輸出Hλ×1=[h1, h2, …, hl],其中,λ為LSTM神經元的個數;其次,將H作為CNN的輸入。在卷積層的設計中,文本使用的卷積核寬度與LSTM單元的個數相同,卷積核在LSTM輸出的步維度上滑動取樣得到O=[o1,o2,…,on],經過池化層得到P=[p1,p2,…,pn],再將P中的每個向量平鋪得到F。在全連接層中,F與WF做點積運算再經過softmax運算,最終得到文本的情感分類概率。
2.3 ?損失函數
在上述兩種模型的學習過程中,均采用交叉熵誤差作為模型的損失函數。具體公式如下:
其中,N為訓練的樣本數,y為模型輸出的每個類別的預測概率,t為第i個樣本的真實類別,訓練目的是讓J最小化。
3 ? ?實驗
3.1 ?實驗準備
為了驗證模型的分類效果,本文使用tensorflow對前兩部分所述模型進行了構建,并在兩種語言的公共語料上進行實驗,列舉了實驗過程及結果,最后對這兩種實驗結果進行了分析。
英文的推特數據集樣本容量較大,本文僅使用了1%的數據作為測試集,其余數據均參與訓練。每個模型均測試3次,測試結果取其平均值。本文對中文電商數據進行了分詞預處理,使用了2 000條積極情感文本、2 000條消極情感文本作為測試集,其余數據均參與訓練。每個模型均測試3次,測試結果取平均值。
本文使用的詞向量維度為512,LSTM單元64個,卷積核32個。實驗所使用的設備配置如下:系統16.04-Ubuntu,CPU為Intel酷睿i7-7700,主頻2.8 GHz,16 G內存,GPU為NVIDIAGeForce-1060,6 G顯存。
3.2 ?實驗結果分析
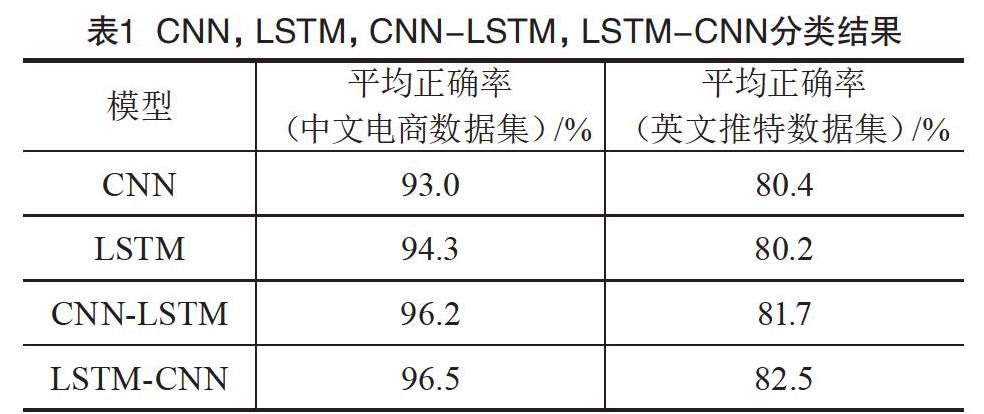
在不同語言的數據集上進行實驗后,本文發現LSTM-CNN與CNN-LSTM模型均優于CNN及LSTM模型1.5%~3.5%,LSTM-CNN模型以0.3%~0.8%優于CNN-LSTM模型。在不同數據集方面,CNN,LSTM,LSTM+CNN,CNN+LSTM模型的表現差異較大,這4種模型在中文數據集上表現更好,當然,這可能和推特文本中存在大量簡寫及錯誤拼寫現象有關。
實驗結果印證了本文的論證。CNN+LSTM模型可以使LSTM更高效地利用原始文本的序列信息,本文進一步猜測,這種優勢在處理長度更長的句子時更加顯著。但是在句子長度普遍小于70的情感分類語料中,LSTM+CNN模型的效果是這幾種組合中最好的。該模型中的LSTM單元充當解碼器,將原始句子中的每個詞都解碼為一個中間信息,這個中間信息除了這個單詞本身的含義,還包含它之前單詞的信息。之后,CNN可以利用其強大的信息識別能力處理更為豐富的中間信息,從而獲得更好的分類效果。CNN,LSTM,CNN-LSTM,LSTM-CNN的分類結果如表1所示。
4 ? ?結語
在本文的研究中,結合了CNN與LSTM模型,并在兩種不同語言的數據集中測試,最終獲得了更高的情感分類準確率。實驗結果發現,LSTM-CNN與CNN-LSTM模型以1.5%~3.5%的準確率優于CNN及LSTM。實驗結果驗證了本文的設想,在語句級的情感分析任務中,聯合CNN與LSTM可以發揮兩個模型的優勢,達到更佳的準確率。
此次實驗中,CNN+LSTM的表現雖然優于CNN與LSTM模型,但在這兩種語料中的效果都不是最好的,本文進一步地猜測此模型更適用于較長的句子。另外,LSTM+CNN模型雖然表現最佳,但是該模型組合并沒有克服LSTM不能處理長序列的缺陷,其在更長的句子中的效果可能欠佳。在未來,筆者將進一步測試此模型在長句的情感分析任務中的表現,進一步對模型進行研究以克服長序列難題。
[參考文獻]
[1]HINTON G E,SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006(5786):504-507.
[2]HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006(7):1527-1554.
[3]LAROCHELLE H,BENGIO Y,LOURADOUR J,et al.Exploring strategies for training deep neural networks[J].Journal of Machine Learning Research,2009(10):1-40.
[4]KIM Y.Convolutional neural networks for sentence classification[J].Eprint Arxiv,2014(14):1181.
[5]LEE J Y,DERNONCOURT F.Sequential short-text classification with recurrent and convolutional neural networks[J].arXiv Preprint:2016(4):515-520.
[6]CHO K,VAN M B,GULCEHRE C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[J].arXiv Preprin,2014(14):1078.
[7]EBRAHIMI J,DOU D.Chain based RNN for relation classification[C].Colorado:Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2015.
[8]SANDERS N.Twitter sentiment corpus[EB/OL].(2019-03-15)[2019-09-10].http://www.sananalytics.com/lab/twitter-sentiment/.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
