基于Pareto分布的眾包工人欺騙行為處理方法
2019-12-23 07:19:04潘慶先江珊董紅斌王瑩潔潘廷偉殷增軒
計算機應用 2019年11期
關鍵詞:質量控制
潘慶先 江珊 董紅斌 王瑩潔 潘廷偉 殷增軒

摘 要:由于眾包的組織模式自由松散,致使眾包工人在完成任務的過程中存在欺騙行為。如何識別工人的欺騙行為并降低其影響,從而保障眾包任務的完成質量,已經成為眾包領域的研究熱點之一。通過對任務結果的評估與分析,針對眾包工人統一型欺騙行為,提出了一種基于廣義Pareto分布(GPD)的權重設置算法(WSABG)。該算法對GPD進行極大似然估計,并用二分法逼近似然函數的零點以計算出尺度參數σ和形狀參數ε。算法中定義了新的權重公式,并利用眾包工人完成當前任務的反饋數據賦予每位工人一個絕對影響權重,最終設計出了基于GPD的眾包工人權重設置框架。所提算法可以解決任務結果數據之間差異性小且容易集中在兩極的問題。以煙臺大學學生評教數據為實驗數據集,提出了區間轉移矩陣的概念,證明了WSABG算法的有效性和優勢。
關鍵詞:眾包;質量控制;廣義Pareto分布;統一型欺騙;權重
中圖分類號:TP393.0
文獻標志碼:A
Pareto distribution based processing approach of
deceptive behaviors of crowdsourcing workers
PAN Qingxian1,2, JIANG Shan2*,DONG Hongbin1, WANG Yingjie2, PAN Tingwei2,YIN Zengxuan2
1.College of Computer Science and Technology, Harbin Engineering University, Harbin Heilongjiang 150001, China;
2.College of Computer and Control Engineering, Yantai University, Yantai Shandong 264005, China
Abstract:
Due to the loose organization of crowdsourcing, crowdsourcing workers have deceptive behaviors in the process of completing tasks. How to identify the deceptive behaviors of workers and reduce their impact, thus ensuring the completion quality of crowdsourcing tasks, has become one of the research hotspots in the field of crowdsourcing. Based on the evaluation and analysis of the task results, a Weight Setting Algorithm Based on Generalized Pareto Distribution (GPD) (WSABG) was proposed for the unified type deceptive behaviors of crowdsourcing workers. In the algorithm, the maximum likelihood estimation of GPD was performed, and the dichotomy was used to approximate the zero point of the likehood function in order to calculate the scale parameterσand shape parameterε. A new weight formula was defined, and an absolute influence weight was given to each worker according to the feedback data of the crowdsourcing workers to complete the current task, and finally the GPDbased crowdsourcing worker weight setting framework was designed. The proposed algorithm can solve the problem that the difference between the task results data is small and the data are easy to be centered on the two poles. Taking the data of Yantai University students evaluation of teaching as the experimental dataset, with the concept of interval transfer matrix proposed, the effectiveness and superiority of WSABG algorithm are proved.
Key words:
crowdsourcing; quality control; generalized Pareto distribution; unified type deception; weight
0?引言
眾包(crowdsourcing)是指“一種把過去由專職員工執行的工作任務通過公開的Web平臺,以自愿的形式外包給非特定的解決方案提供者群體來完成的分布式問題求解模式”[1]。眾包有三個基本要素:眾包參與者、眾包平臺、眾包任務,其基本流程為:任務請求者通過眾包平臺發布眾包任務,眾包工人通過平臺選擇任務,完成任務之后向平臺提交結果,最后平臺檢驗結果質量并對眾包工人進行激勵或懲罰。由于眾包面向不確定大眾群體,而且眾包工人具有自私性,所以導致工人在完成任務過程中容易產生欺騙行為,從而導致完成質量不高。如何識別工人的欺騙行為,并對其科學化處理,已經成為眾包質量控制中亟須解決的問題。
本文工作主要包括以下幾個方面:1)對存在統一欺騙型任務結果進行研究;2)基于廣義Pareto分布(Generalized Pareto Distribution, GPD)為每一位眾包工人設置影響權重,提出了基于GPD的權重設置算法(Weight Setting Algorithm Based on GPD, WSABG),并對任務數據進行擬合;3)提出區間轉移矩陣,驗證不同算法之間輸出結果的差異;4)以煙臺大學學生評教數據為實驗數據集,驗證了WSABG算法的有效性。
1?相關工作
1.1?質量控制
目前關于眾包中質量控制的研究主要集中在3個方面:1)控制參與人群,主要指控制任務請求者和眾包工人的信譽程度。 2)優化任務設計,眾包任務的構造方式對獲取高質量的結果起到了極其重要的作用。例如Gaikwad等[2]通過預先使用樣本任務,利用工作者的反饋形成更佳的任務設計方案。3)評估反饋數據,主要評價數據的可靠性,Daniel等[3]提到高質量的輸出數據是眾包的關鍵驅動因素之一。
參與人群主要是指任務請求者和眾包工人,Allahbakhsh等[4]提到一個良好請求者需要具備慷慨、公平的品質,公平的態度和優秀的溝通能力。而對眾包工人有更嚴格的要求,比如:工人的基本信息,包括年齡、性別、所在位置、人格特征、責任心、行為動機等;工人的個人能力,包括專業技能、等級、憑據等;工人的工作經驗,包括歷史行為信息、聲譽分數、可信度等。例如Eickhoff等[5]深入研究了惡意眾包工人的行為模式;Khudabukhsha等[6]提出了一種聲譽評估方法,通過正確率對眾包工人進行等級劃分。Awwad等[7]提出一種離線算法,將歷史任務分組到同類集群中,并為每個集群學習工作人員特性,然后算法利用這些特性為每個傳入的任務選擇可靠的工人。另外,有些眾包任務需要眾包工人形成團隊合作完成,所以工作團隊的非共謀性也是研究的重點之一,例如Hossfeld等[8]提出一個良好的工作團隊應該由非共謀者所組成。
關于提高眾包任務的設計,一方面眾包工人希望請求者對于任務的描述清晰[9]、任務自身復雜度低,且能保證工人的隱私安全[10]等。Jain等[11]提出如何幫助請求者設計有效的眾包任務。施戰等[12]提出為了保證眾包系統的性能,必須設計出高效的任務分配機制,挑選出最合適的用戶完成任務,從而保證任務的完成質量。王瑩潔等[13]提出在眾包系統中,如何激勵用戶積極地參與任務感知,使得整個系統的收益最大化,是保證眾包系統性能的重要因素。所以好的任務設計還應該為眾包工人提供好的激勵方式。另一方面從任務本身來看,則希望加強法律約束,保障其信息安全以及合規性[14]。
在眾包中,數據是指在執行任務過程中或者由于執行任務而產生的信息,即輸入、輸出數據,其中輸入數據可以是需要翻譯的文本,那么輸出數據就是眾包工人翻譯好的文本。近年來研究工作主要包括:數據的準確性、一致性、及時性等。準確性是估量數據正確程度的屬性,Gaunt等[15]提出了一種基于深度神經網絡處理聚合數據的方法,以輸出準確性更高的反饋結果。一致性通常被解釋為不同眾包工人在響應相同輸入時產生的輸出之間的相似性,Huang等[16]提出使用一致性的評估結果要優于使用黃金標準數據的方式。及時性[17]多是在時空眾包中進行研究,例如外賣中的送餐服務、打車軟件中司機到達的時間等。
以上工作多基于眾包系統中的歷史信息進行研究,由于信息的龐大雜亂,難以實現質量控制。本文方法基于眾包工人的當前任務數據進行研究,避免了使用歷史信息這一方式,從而更加具有針對性。
1.2?Pareto分布
Pareto分布是根據瑞士經濟學家Vilfredo Pareto的名字來命名的,關于Pareto分布的研究起源于1897年在羅馬出版的由Vilfredo Pareto著的經濟學書,該書中Pareto通過研究個人收入的統計分布,提出了經典的Pareto分布函數:
F(x)=1-cx-a(1)
其中:F(x)為收入不超過x的個體所占的比例;c為實數;a為正數,并且稱a為Pareto指數。基于Vilfredo Pareto的研究,又有數種不同的Pareto分布被提出,統稱Pareto分布族,其中以GPD在實際應用中最為常見。
本文中所研究的GPD是由Pickands[18]首次提出的,現已被廣泛應用于各個領域,例如:Dey等[19]通過使用由自助采樣產生的模擬颶風系列來量化颶風損失極端回報水平推斷的不確定性,發現颶風的破壞數據遵循廣義的Pareto分布。Murata等[20]提出了基于廣義Pareto分布的信息檢索模型。關于GPD二參數形式的研究,多是利用極大似然估計求得數據所擬合的函數參數。Castillo等[21]提出在Akaike和Bayesian信息標準下比較相同數據的幾個模型,從而得到可以在GPD中使用極大似然估計的一種新方法。
2?問題描述及處理方法
2.1?欺騙型眾包工人
本文選取評價類眾包任務為研究對象,該類任務應用廣泛,比如滴滴打車中乘客對司機的評分、淘寶評價、影評、學生評教等。為了獲取高質量的評價信息,需要眾包工人客觀、公正地進行評價,所以欺騙型眾包工人的存在將會影響評價信息的可靠性。
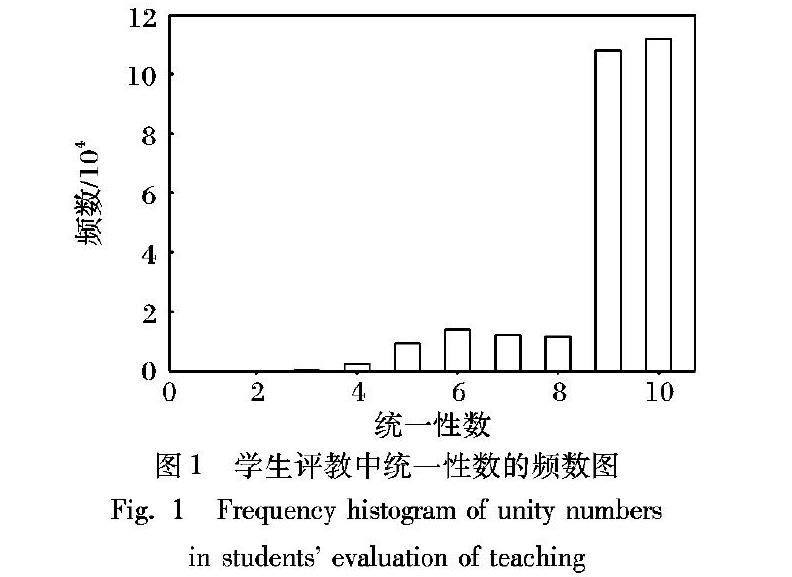
張志強等[22]提出欺騙類眾包工人的行為主要分為兩種:一種是故意隨機提交任務結果的眾包工人;另一種是統一型欺騙的眾包工人。本文主要研究統一型欺騙行為的眾包工人。以煙臺大學學生評教數據為研究對象,通過對任務結果的評估與分析,發現數據存在“二八分”的現象,即具有統一型欺騙行為的眾包工人所提交的數據約占總體的80%,剩余20%的數據體現出值得信賴性等特點。其中統一型任務結果的頻數圖如圖1所示。
圖1中的橫坐標是指學生10項指標重復分數的最大值。比如某名學生在評價中10項指標的打分為:{8,8,8,7,8,8,6,7,8,8},其中共有7個8分,2個7分,1個6分,則重復分數的最大值就從{7,2,1}中取最大數,本文定義此值為“統一性數”。縱坐標是指各統一性數取值的頻數。從圖中可以看出此數據中統一性數為9和10時,其頻數非常大。經計算,這兩項占了全部比重的81.2%,說明評分中的統一型欺騙行為非常嚴重。
定義1?總數m名眾包工人中,第i名工人的符號標記為wi,全部工人組成的工人集標記為W={w1,w2,…,wm}。這些工人所做的任務都包含在任務集T={t1,t2,…,tn}中,第j項任務的符號標記為tj。工人wi所做的任務集用Ti(TiT)表示,完成任務tj的工人集用Wj(WjW)表示。
定義2?Tkij(k=1,2,…,K)是評價型任務的一組指示變量。當工人wi對任務tj的反饋結果的統一性數取值為k時,Tkij=1; 若不為k,則Tkij=0。
任務tj的反饋結果中統一性數取k時的頻率UnityFrekj采用式(2)計算得到:
UnityFrekj=∑wi∈WjWTkij|Wj|(2)
2.2?GPD的極大似然估計
GPD是Pareto函數分布族中的二參數形式。評價類眾包任務需要對每一項任務匯總,所以單獨考慮每一項任務的分布情況,那么任務結果中的統一性數服從GPD,其分布函數如下:
G(x;σ,ε)=1-(1+εx/σ)1/ε,ε≠0
1-exp(-x/σ),ε=0 (3)
其中:σ>0為尺度參數,ε∈R為形狀參數。樣本值統一性數用x表示,x∈[0,1]。
為了求取參數ε和σ,設X={X1,X2,…,Xn}是一組隨機變量,(σ,ε)是二維參數向量。因為眾包工人之間完成任務是相互獨立的,所以隨機變量的聯合密度函數為:
L(X1,X2,…,Xn;σ,ε)=∏ni=1g(xi;σ,ε)(4)
其中
g(x)=
1σ(1+εx/σ)-1/(ε-1),ε≠0
1σexp(-x/σ),ε=0 (5)
是式(3)的密度函數,將其代入式(4)整理得似然函數為:
lnL=-nlnσ-(1ε+1)∑ni=1(1+εXi/σ),
ε≠0
-nlnσ-1σ∑ni=1Xi,ε=0 (6)
令θ=ε/σ
ε=ε(7)
當θ≠0時,對式(7)中的參數求得一階偏導為:
dLdθ=nθ-1+1ε∑ni=1xi1+θxi=0(8)
dLdε=-nε+1ε2∑ni=1ln(1+θxi)=0(9)
由式(9)可求得:
=1n∑ni=1ln(1+θ^xi) (10)
聯立式(8)、(9)、(10),求得關于θ的似然方程為:
nθ-(n/∑ni=1ln(1+θxi)+1)∑ni=1xi1+θxi=0(11)
為求此方程的數值解,考慮采用二分法逼近其零點,首先將方程視為關于θ的函數:
h(θ)=nθ-(n/∑ni=1ln(1+θxi)+1)∑ni=1xi1+θxi(12)
下面進行零點存在定理的證明:當θ→0時,h(θ)→+∞;當θ→1/(n),h(θ) → -∞,其中X(n)是樣本值中的最大值[23]。又因為函數f(θ)是連續函數,根據零點的存在性定理可知此函數存在零點。
2.3?基于GPD的眾包工人權重設計框架
眾包工人的統一類型欺騙行為將會導致數據之間差異小,甚至容易集中在兩極的狀況。研究發現任務結果數據的統一性現象符合GPD,于是可以利用此分布為每一位工人設置影響權重。圖2描述了基于GPD的眾包工人欺騙行為處理辦法的流程。
此流程主要包括以下幾個方面的工作:
1)利用極大似然估計求取各任務結果服從的GPD參數。
2)利用GPD為工人設置影響權重。本文選取的眾包任務要求每個眾包工人都需要完成多項眾包任務,每項眾包任務由多個眾包工人完成,所以每一項眾包任務都對應一個Pareto分布函數,得到多個影響權重后,取其平均值作為工人的絕對影響權重。
3)求得任務輸出結果的加權值。本文的最終目標是降低欺騙類工人的影響權重,計算每一項任務的可靠輸出值。
2.4?算法設計
Pareto法則提出,在眾多現象中,80%的結果,來自20%的原因, 因此輸出結果統一性高的眾包工人將會被設置較低的影響權重,輸出結果統一性低的眾包工人將會被設置較高的影響權重。由此便可以降低工人的欺騙行為對任務匯總結果產生的不良影響。
為了更客觀地設置眾包工人的影響權重,從每一位工人wi的任務集TiT作為出發點,求得任務tj∈Ti結果所服從的GPD的密度函數gj,則wi關于任務tj的影響權重可以設置為:
λij=1-gj(ki)-gj(kmin)gj(kmax)-gj(kmin) (13)
其中:k是定義2中提到的統一性數,表示工人提交任務結果的重復數的最大值; ki是工人wi的統一性數; kmax表示統一性數的最大取值; kmin表示統一性數的最小取值。為了得到工人的絕對影響權重,對其任務集TiT中全部任務得出的權重取平均數:
i=∑tj∈TiTλij|Ti| (14)
算法1給出WSABG的算法過程。此算法中,2)~10)行遍歷任務集求得相應的Pareto分布參數,并在4)~9)行中對每個任務中參與的工人標記了權重;11)~13)行對每個工人求取絕對影響權重。由于二分法求零點時算法運行在固定區間,可認為時間復雜度為O(1),算法第3)行的時間復雜度為O(m),其中m為工人人數;4)~9)行中求工人權重的時間復雜度為O(m),于是2)~10)行時間復雜度為O(n×m),其中n為任務數;11)~13)行時間復雜度為O(m)。因此,算法1總的時間復雜度為O(n×m)。
算法1?基于GPD的權重設置算法。
輸入?眾包任務集T={t1,t2,…,tn},眾包工人集W={w1,w2,…,wm},工人wi∈Wj對任務tj∈T的評價結果tj(wi)。
輸出?工人集W的權重向量。
程序前
1)
初始化Weights,Counters均為長度為m的空數組
2)
for tj∈T do
3)
求得極大似然估計的參數σ和ε
4)
for wi∈W do
5)
if wj參與并完成了此任務 then
6)
Countersi+=1
7)
Weightsi+=λij(tj(wi))
8)
end if
9)
end for
10)
end for
11)
for Weightsi∈Weights do
12)
Weightsi=Weightsi/Countersi
13)
end for
14)
return Weights
程序后
3?實驗結果與分析
3.1?實驗數據
實驗數據取自煙臺大學學生評教數據,共計269-307條,每一條內容包括一名學生對一門課程關于10項指標的評分。此數據中,將學生視為眾包工人,將老師教授的課程視為眾包任務, 則眾包任務集中的每一個集合元素都對應一門課程。眾包工人集中的每一個集合元素都對應一名學生。
3.2?擬合結果分析
圖3是隨機選取的4門課程的評教數據呈現出一致性的頻數圖。
圖4是廣義Pareto的密度函數在幾種不同參數下的圖像,由圖可見當σ的值不變時,ε的值越大,函數圖像的彎曲程度越高;當ε的值不變時,σ的值越大,函數圖像的值越大。
圖5(a)~(d)是圖3中4門課程的頻度折線圖及其擬合后密度函數所形成的對比,表1是函數對應的相關參數。從圖中以看出,此4門課程的擬合圖像在形狀上十分接近,所以表1中的參數值也十分接近。
為了驗證擬合效果,本文采用假設檢驗中的方差檢驗法對擬合前后的數據進行分析。原假設為擬合前后數據值差異不顯著,記為H0; 備擇假設為擬合前后數據值差異顯著,記為H1。在顯著性水平α=0.05的情況下,表2給出了對此四門課程進行方差檢驗相關的數據值。
其中,p>α接受原假設,p<α接受備擇假設。F值等于組間均方和組內均方的比值,表示隨機誤差作用的大小。在自由度為13的情況下,F查表值為4.667, 且當F實際值小于F查表值時,p>α;當F實際值大于F查表值時,p<α。h和p1是判斷正態性假定的輸出值,當h=0時,認為數據服從正態分布,h=1則認為不服從正態分布。p2是方差齊次性假定的輸出值,p2>0.05時,滿足方差齊次性。其中,滿足正態性假定和方差齊次性假定是采用方差檢驗法的前提條件。從表3數據可知四門課程的檢驗結果皆符合原假設,說明擬合前后的數據之間并沒有顯著差異,擬合效果良好。
3.3?算法結果分析
處理統一型欺騙行為中常用的算法為加權平均法,后文稱之為傳統算法。此法是對10項指標進行加權,再從全部學生打的分數中求取平均數作為課程的最后輸出結果。本文對兩種算法作了對比,結果如圖6所示,圖中將兩種算法的輸出結果區間按升序平均分為50份,視為50個區間并作為橫坐標。之后取各區間內取值的頻數作為縱坐標。其中,左側部分的山峰是WSABG輸出結果頻數取值,右側部分的山峰是傳統算法輸出結果頻數取值。
從圖6中可以看出,傳統算法的輸出結果集中在第40~50區間,且圖像截止在高分數區間,分布圖右側沒有尾巴,說明此算法對大部分課程的評教結果都取了高分,在高分區對課程的區分程度較低。然而傳統算法在第0~10區間也存在小部分課程,此類區間的課程分數很低。由此可知,由于學生敷衍或欺騙性地進行評教,對部分老師的評教結果是不公平的,因此難以達到學生評教真正的目的和意義。
WSABG所輸出的結果更接近正態分布,其中大部分的課程都取了普通的分數,左側是分數較低的課程,右側是優秀的課程。此算法可以將課程更好地區分開,從而達到學生評教的目的, 所以本文基于Pareto分布為學生設置權重的算法取得了較好的效果,可以解決傳統算法高分區間數據之間差異小,以及課程在高分區嚴重集中的問題。
下面考察算法評級結果的準確率。將課程等級標記為“1級”“2級”和“3級”,級別越高表示課程越優秀。等級的劃分需要在分數區間內設置兩個分割點,驗證在不同的分隔點下,算法的準確率。圖7(a)給出了WSABG的準確率在不同分割點下的具體數值,圖7(b)給出了傳統算法的準確率在不同分割點下的具體數值。圖中的第X行第Y列的元素值表示將等級區間分成{0~(X*10)%,(X*10)%~(Y*10)%, (Y*10)%~100%},如第4行第7列表示將等級分成{0%~40%, 40%~70%, 70%~100%}三個區間。0%~40%區間代表“1級”,40%~70%區間代表“2級”, 70%~100%區間代表“3級”。從圖7中可以看出,本文的算法在多數等級區間劃分下的準確率均要高于傳統算法。
為了更加直觀地觀察兩種算法的準確率對比。圖8給出了描述準確率如何相對兩個分割點變化而變化的三維圖像。由三維圖可以看出,WSABG在1~2級分割點約為0.5,2級分割點約為0.8時取最大值,而傳統方法中,三維圖的最大值點出現在2~3分割點約為1時,且對于大多數的分割點,WSABG分類精度高于傳統方法。為了方便觀察,對三維圖較有代表性意義的位置進行了兩次切片,切片展示成了折線圖9。圖9(a)表示2~3級分割點固定為0.7時,兩種算法的準確率對比。圖9(b)表示2~3級分割點固定為0.8時的準確率對比。可以明顯地看出,WSABG的準確率普遍更高。
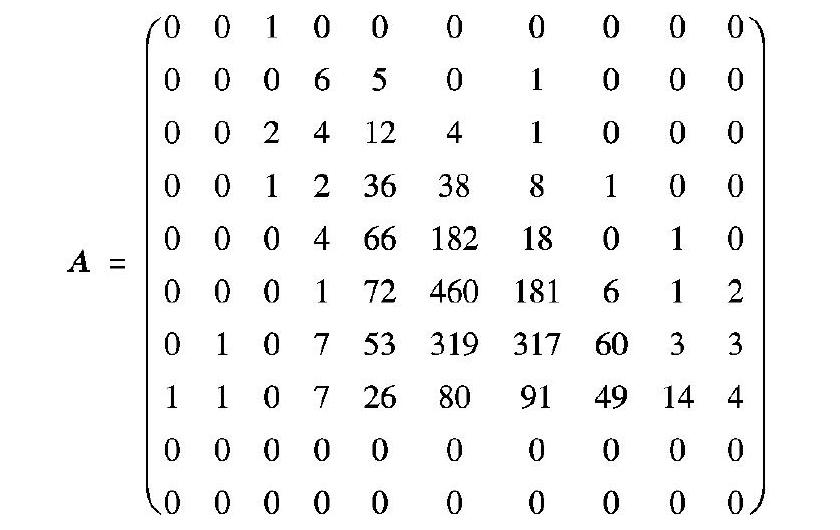
為了衡量兩種算法之間的差異,本文提出了區間轉移矩陣如A所示, 矩陣中的元素Aij代表在傳統算法中屬于第i區間的課程在WSABG中屬于第j區間的個數。將兩種算法進行歸一化并對齊平均值后,按照相同的間隔將評分劃分成了10個區間。從區間轉移矩陣中可以看出,數值較大的元素均分布于主對角線及其附近,說明原本在傳統算法中屬于平均水平的課程在WSABG中也分布于這個區間或其附近。例如區間轉移矩陣中的第6行,也就是傳統算法中的第六區間,共有723門課程,其中A67=181表示在傳統算法的第六區間中的課程,有181門在WSABG的第七區間內。由區間轉移矩陣可以看出,大部分的課程在兩種算法中的等級區間跳躍不會太大,但是也存在個別異常值。
A=001000000000065010000024124100000123638810000046618218010000172460181612010753319317603311072680914914400000000000000000000
異常值主要分布在矩陣的邊緣部分。例如右上邊緣的課程表示在傳統算法中區間等級較低,但在WSABG中區間等級較高的課程。例如元素A81=1,表示在傳統算法第八區間內的一門課程,在WSABG中被分到了第一區間。也就說傳統算法對于此門課程的判定是極高的等級,但是在WSABG中給出的等級卻很低。本文對此類異常值的評教數據進行了調查,發現此類課程的數據均給了一致性的高評分(幾乎全為滿分),但是主觀評價(學生自愿填寫)幾乎全部空白。對于此類課程,本文提出存在師生共謀的猜想,并建議學校對此類課程進一步調查。
4?結語
本文針對存在統一類型欺騙行為的數據展開研究,發現此類數據符合GPD。利用極大似然估計對此類任務結果數據進行參數估計,并使用二分法逼近參數估計值。得到數據擬合的廣義Pareto密度函數之后,為每一位眾包工人設置影響權值,并取各任務影響權值的平均值作為工人的絕對影響權重。利用工人的絕對影響權重為原始結果進行加權,求得眾包任務反饋結果的可靠值。經過實際數據測試,驗證了該算法對于解決存在統一類型欺騙行為眾包工人的任務具有較好的效果。在后續工作中,將會繼續考察該方法在不同任務類型下的實際效果,設計更加具有通用性的框架。
參考文獻 (References)
[1]SCHEE B A V. Crowdsourcing: why the power of the crowd is driving the future of business[J]. American Journal of HealthSystem Pharmacy, 2010, 67(4): 1565-1566.
[2]GAIKWAD S, CHHIBBER N, SEHGAL V, et al. Prototype tasks: improving crowdsourcing results through rapid, iterative task design[EB/OL].[2017-07-18]. http://web.media.mit.edu/~gaikwad/assets/publications/daemomhcomp.pdf.
[3]DANIEL F, KUCHERBAEV P, CAPPIELLO C, et al. Quality control in crowdsourcing[J]. ACM Computing Surveys, 2018, 51(1):1-40.
[4]ALLAHBAKHSH M, IGNJATOVIC A, BENATALLAH B, et al. Reputation management in crowdsourcing systems[C]// Proceedings of the 8th International Conference on Collaborative Computing: Networking, Applications and Worksharing. Piscataway: IEEE, 2012: 664-671.
[5]EICKHOFF C, de VRIES A. How crowdsourcable is your task[C]// Proceedings of the Workshop on Crowdsourcing for Search and Data Mining at the 4th ACM International Conference on Web Search and Data Mining. New York: ACM, 2011: 11-14.
[6]KHUDABUKHSH A R, CARBONELL J G, JANSEN P J. Detecting nonadversarial collusion in crowdsourcing[C]// Proceedings of the 2nd AAAI Conference on Human Computation and Crowdsourcing. Menlo Park, CA: AAAI Press, 2014: 104-111.
[7]AWWAD T, BENNANI N, ZIEGLER K, et al. Efficient worker selection through historybased learning in crowdsourcing[C]// Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference. Piscataway: IEEE, 2017: 923-928.
[8]HOSSFELD T, KEIMEL C, TIMMERER C. Crowdsourcing qualityofexperience assessments[J]. Computer, 2014, 47(9): 98-102.
[9]GADIRAJU U, YANG J, BOZZON A. Clarity is a worthwhile quality: on the role of task clarity in microtask crowdsourcing[C]// Proceedings of the 28th ACM Conference on Hypertext and Social Media. New York: ACM, 2017: 5-14.
[10]ZHUO G. Privacypreserving and finegrained data aggregation framework for crowdsourcing[C]// Proceedings of the 2017 10th International Conference on Mobile Computing and Ubiquitous Network. Piscataway: IEEE, 2017: 1-6.
[11]JAIN A, SARMA A D, PARAMESWARAN A, et al. Understanding workers, developing effective tasks, and enhancing marketplace dynamics: a study of a large crowdsourcing marketplace[J]. Proceedings of the VLDB Endowment, 2017, 10(7): 829-840.
[12]施戰, 辛煜, 孫玉娥,等. 基于用戶可靠性的眾包系統任務分配機制[J]. 計算機應用, 2017, 37(9): 2449-2453.(SHI Z, XIN Y, SUN Y E, et al. An allocation mechanism based on the reliability of users for crowdsourcing systems [J]. Journal of Computer Applications, 2017, 37(9): 2449-2453.)
[13]王瑩潔, 蔡志鵬, 童向榮,等. 基于聲譽的移動眾包系統的在線激勵機制[J]. 計算機應用, 2016, 36(8): 2121-2127. (WANG Y J, CAI Z P, TONG X R, et al. Online incentive mechanism based on reputation for mobile crowdsourcing system[J]. Journal of Computer Applications, 2016, 36(8): 2121-2127.)
[14]HANSEN D L, SCHONE P J, COREY D, et al. Quality control mechanisms for crowdsourcing: peer review, arbitration, & expertise at family search indexing[C]// Proceedings of the 2013 Conference on Computer Supported Cooperative Work. New York: ACM, 2013: 649-660.
[15]GAUNT A, BORSA D, BACHRACH Y. Training deep neural nets to aggregate crowdsourced responses[C]// Proceedings of the 32nd Conference on Uncertainty in Artificial Intelligence. Barcelona, Spain: AUAI Press, 2016: 242251.
[16]HUANG S W, FU W T. Enhancing reliability using peer consistency evaluation in human computation[C]// Proceedings of the 2013 Conference on Computer Supported Cooperative Work. New York: ACM, 2013: 639-648.
[17]WU P, NGAI E W T, WU Y. Toward a realtime and budgetaware task package allocation in spatial crowdsourcing[J]. Decision Support Systems, 2018, 110: 107-117.
[18]PICKANDS III J. Statistical inference using extreme order statistics[J]. The Annals of Statistics, 1975, 3(1): 119-131.
[19]DEY A K, DAS K P. Modeling extreme hurricane damage using the generalized Pareto distribution[J]. American Journal of Mathematical and Management Sciences, 2016, 35(1): 55-66.
[20]MURATA M, HIRAMATSU K, SATOH S. Information retrieval model using generalized Pareto distribution and its application to instance search[C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 1117-1120.
[21]CASTILLO J D, SERRA I. Likelihood inference for generalized Pareto distribution[J]. Computational Statistics & Data Analysis, 2015, 83: 116-128.
[22]張志強, 逄居升, 謝曉芹, 等. 眾包質量控制策略及評估算法研究[J]. 計算機學報, 2013, 36(8): 1636-1649.(ZHANG Z Q, PANG J S, XIE X Q, et al. Research on crowdsourcing quality control strategy and evaluation algorithm[J]. Chinese Journal of Computers, 2013, 36(8): 1636-1649.)
[23]GRIMSHAW S D. Computing maximum likelihood estimates for the generalized Pareto distribution[J]. Technometrics, 1993, 35(2): 185-191.
This work is partially supported by the National Natural Science Foundation of China (60903098,61502140,61572418).
PAN Qingxian,born in 1979, Ph. D. candidate,associate professor. His research interests include artificial intelligence,group intelligence perception, crowdsourcing.
JIANG Shan,born in 1994, M. S. candidate. Her research interests include crowdsourcing.
DONG Hongbin, born in 1963, Ph. D., professor. His research interests include artificial intelligence,machine learning, multiAgent system.
WANG Yingjie,born in 1986, Ph. D.,associate professor. Her research interests include temporalspatial crowdsourcing.
PAN Tingwei,born in 1992, M. S. candidate. His research interests include crowdsourcing.
YIN Zengxuan, born in 1995, M. S. candidate. His research interests include crowdsourcing.
猜你喜歡
中國科技博覽(2016年19期)2016-10-19 13:36:59
中國科技博覽(2016年18期)2016-10-19 11:06:33
中國科技博覽(2016年18期)2016-10-19 09:03:36
中國科技博覽(2016年18期)2016-10-19 08:46:18
科技視界(2016年21期)2016-10-17 17:58:28
中國實用醫藥(2016年24期)2016-10-17 06:28:30
科學與財富(2016年28期)2016-10-14 19:44:52
科學與財富(2016年28期)2016-10-14 18:58:41
科學與財富(2016年28期)2016-10-14 18:44:58
科技視界(2016年20期)2016-09-29 13:11:33
