條件約束下的自我注意生成對抗網絡
2019-12-24 06:29:18賈宇峰
西安電子科技大學學報 2019年6期
賈宇峰,馬 力
(西安郵電大學 計算機學院,陜西西安710061)
近年來,生成分辨率更高和更逼真的圖像是一個具有挑戰性的問題。早期的生成模型[1-3]由于訓練復雜性的限制,建模非常困難,使得大規模數據下目標函數變得極難求解。文獻[4]在2014年提出生成對抗網絡(Generative Adversarial Network, GAN),為解決圖像生成問題提供了一個特征學習模型框架,生成對抗網絡的顯著特點在于不直接以數據分布和模型分布的差異為目標函數,轉而采用對抗的方式進行學習,直到達到納什平衡[5]。目前,各種變異生成對抗網絡架構在許多特定任務中取得了令人矚目的成果,如圖像生成[6-7]、圖像到圖像的轉換[8-9]、視頻預測[10]、圖像風格轉換[11-12]、圖像超分辨率[13]和文本到圖像的生成[14-15]等。
已知生成對抗網絡的訓練不穩定,容易發生模式崩潰。為了解決這個問題,深度卷積生成對抗網絡(Deep Convolutional GAN, DCGAN)[16]引入卷積結構并提出了幾種啟發式技巧(如特征匹配、單側標簽平滑、虛擬批量歸一化、重建損失[17]等)以提高訓練穩定性。文獻 [18]使用Lipschitz約束的Earth-Mover(EM)[19]距離來解決消失的梯度飽和的Jensen-Shannon距離問題。最小二乘生成對抗網絡(Least Squares GAN, LSGAN)[20]在判別器上采用了最小平方損失函數。基于能量的生成式對抗網絡(Energy-Based GAN,EBGAN)[21]采用自動編碼器替換判別器進行訓練,旨在將判別器作為能量函數。邊界平衡生成對抗網絡(Boundary Equilibrium GAN, BEGAN)[22-23]提出了一種新的均衡方法,表現出逼真的面部生成。基于自我注意力生成對抗網絡(Self-Attention GAN,SAGAN)[24]首次在生成器和判別器中引入自我注意力模塊,解決了圖像遠距離空間局部細節不清晰問題和訓練穩定性,使得生成對抗網絡在圖像的生成上有了新的進步。
受條件生成對抗網絡(Conditional GAN, CGAN)[25]的監督思想的啟發,筆者提出了一種基于條件自我注意生成對抗網絡,所提方法的創新之處主要體現以下兩個方面:
(1)生成網絡與判別網絡中同時引入條件特征學習分布誤差的相似度作為監督信息,使得生成模型生成特定的樣本。
(2)引入用于衡量圖像像素級差別損失中的L1損失函數,使得網絡在注重圖像的特征信息的同時兼顧了圖像像素信息重建,L1損失函數的引入也使得網絡取得更好的性能和收斂速度。
1 生成對抗網絡
生成對抗網絡[4]是由生成網絡G和判別網絡D兩部分構成的。D的任務是將G生成的樣本與訓練數據區分開來。而G是通過生成分布接近訓練數據分布的樣本來混淆D。整個過程G和D同時訓練,構成了一個動態的“二人博弈游戲”(Two-Player Minmax Game)。生成對抗網絡的目標函數如式(1):
(1)

1.1 條件生成對抗網絡
CGAN[25]與GAN[4]的主要不同處是,CGAN把無監督生成對抗網絡改進為有監督的生成對抗網絡模型,對生成網絡G和判別網絡D都引入條件變量c,增加額外信息指導數據的生成過程,生成指定類別的樣本。CGAN的目標函數如式(2)所示:
(2)
其中,條件變量c就是加入的監督信息,CGAN接收條件變量c與隨機噪聲z作為輸入,通常c可以是其他任意的輔助信息,比如類型標簽和其他的數據類型,并且將c作為附加輸入層輸入到判別器和生成器來執行調節。
1.2 自我注意生成對抗網絡
傳統的生成對抗網絡[4]模型都依賴卷積操作,它只適合處理鄰域信息,在計算遠距離特征上效率很低,即是在低分辨率特征圖的空間局部點上來生成高分辨率的細節,而SAGAN[24]是可以從所有的特征處生成細節,并且SAGAN的判別器可以判別兩幅具有明顯差異的圖像是否具有一致的高度精細特征。SAGAN的創新就是在判別器和生成器上加入自我注意力模塊[28](Self-Attention Mechanism),幫助網絡從圖像較遠部分捕捉細節,有效地解決了生成對抗網絡目前存在的問題:當訓練多類別數據集時,生成對抗網絡容易捕捉紋理特征但很難捕捉幾何結構特征。SAGAN中的自我注意力模塊如圖1所示。

圖1 注意力機制模塊結構圖

LD=-E(x,y)~pdata[min(0,-1+D(x,y))]-Ez~pz,y~pdata[min(0,-1-D(G(z),y))] ,
(3)
LG=-Ez~pz,y~pdataD(G(z),y) 。
(4)
2 改進的條件自我注意生成對抗網絡
生成對抗網絡是一種無監督模型,它直接進行采樣,從而真正達到理論上可以完全逼近真實數據,這是生成對抗網絡最大的優勢。然而,這種不需要預先建模的方法缺點是太過自由,生成結果不太可控。基于條件生成對抗網絡的監督思想,在生成器和判別器上引入條件變量,使用額外信息指導數據生成過程,生成指定類別的圖像。并結合SAGAN網絡模型的優點,提出了C-SAGAN模型,其核心思想主要是通過添加條件特征信息,生成特定類型的高質量清晰的圖像。C-SAGAN的原理示意如圖2所示。
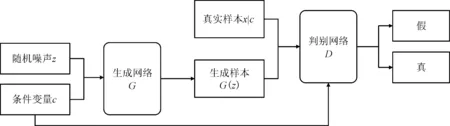
圖2 條件自我注意生成對抗網絡原理圖
模型的生成器接收隨機噪聲z與條件特征c作為輸入,生成一張圖片,再將生成的圖片與原條件特征輸入進判別器當中,同時判別器接收加入條件特征的真實圖片x|c作為輸入。C-SAGAN的優化函數將式(3)、(4)中的先驗概率x,y變為后驗概率x|c,y|c,如下所示。
LG=-E(x,y)~pdata[min(0,-1+D(x|c,y|c))]-
Ez~pz,y~pdata[min(0,-1-D(G(z|c)),y|c)]+L1,
(5)
LD=-Ez~pz,y~pdataD(G(z|c),y|c) ,
(6)
其中,L1=λ∑j=1|ωj|。為了提高生成圖像的質量,在生成器的后面添加L1正則化損失函數,使得生成器生成的圖像更加平滑,收斂速度更快。
2.1 生成網絡
C-SAGAN生成器的結構如圖3所示。生成網絡主要由卷積特征提取模塊、深度注意力殘差模塊、圖像上采樣模塊、圖像重建模塊4部分組成。生成網絡參數設置批次大小、圖像大小、卷積深度均為64,輸入數據大小為(64,64),同時輸入條件特征c(40維),經過卷積層,數據大小變為(64,128,1,1),進入深度注意力殘差模塊,經過前三層網絡后數據大小變為(64,512,4,4),(64,256,8,8),(64,128,16,16);第3層之后計算self-attention ,其中map1為(64,256,256),再經過一層卷積層變為(64,64,32,32);在第4層之后也有self-attention層,map2大小為(64,1 024,1 024)。之后再經過上采樣層與最后一層卷積核為4×4,步長為2的卷積層變為(64,3,64,64),生成器的輸出圖像的大小為64×64。

圖3 C-SAGAN生成器結構
2.2 判別網絡
C-SAGAN判別器的結構如圖4所示。判別網絡設定參數每批次大小、圖像大小、卷積深度均為64,輸入圖像的大小為64×64,同時輸入條件特征c(40維),前3層的網絡結構基本一致,通道的大小在不斷增加,但是尺寸的大小在減小,由輸入數據(64,3,64,64)變為(64,256,8,8),前3層結束后,進行一層self-attention層,此時尺寸大小不變,還是(64,256,8,8),map1為(64,64,64),在經過一次卷積層變為(64,512,4,4),第4個卷積層結束之后,再進行一次self-attention,輸出第二個注意力模塊map2為(64,16, 16),經過最后一層卷積層變為(64,1,1,1),使用squeeze()把shape中為1的維度去掉,判別器的輸出大小為(64)。

圖4 C-SAGAN判別器結構
3 實 驗
實驗在CelebA[26]數據集和MNIST[27]數據集上進行,實驗在Intel(R) Xeon(R) CPU E5-2 620 v4 @ 2.10GHz處理器,一塊NVIDIA Tesla P100 GPU顯卡,TensorFlow環境上進行。
3.1 CelebA數據集
3.1.1 數據集預處理
CelebA數據集是一個大規模人臉特征數據集,每個圖像具有40個屬性標簽(如“男”“眼睛”“胡子”“劉海”等)。包含10 177種身份,202 599個面部圖像和5個地標位置。首先在原始圖像臉部周圍裁剪生成128×128像素大小的圖像并縮小至64×64像素,最后將64×64像素的圖像作為模型輸入。
3.1.2 參數設置
實驗在CelebA數據集上迭代訓練50個epoch,每一個epoch的迭代次數為10 000次。訓練每一批圖片的數量均為64,使用的優化器是Adam,其中參數beta1設置為0.5,beta2設置為0.9,生成網絡和判別網絡的初始學習率分別為0.000 1和0.000 4,學習率衰減因子為0.95。
3.1.3 實驗結果與分析
圖5是模型C-SAGAN使用條件特征生成的樣本。在實驗過程中,每1、3行添加的條件特征是男性,2、4行添加的是女性特征,經過5次迭代后生成樣本圖像,模型就可以學習到準確的特征。但圖像存在噪聲且圖像的細節存在缺陷,人臉輪廓不清晰,當迭代到50次后,模型生成的樣本圖像細節效果清晰,具有多樣性且特征明顯。

圖5 CelebA生成樣本

圖6 CelebA添加條件特征生成樣本與SAGAN生成樣本
圖6(a)、(b)、(c)、(d)是在模型C-SAGAN上經過30次迭代后生成的樣本,圖6(e)是SAGAN迭代50次后的結果。圖6(a)是加入男性、黑發條件特征的圖像,圖6(b)是加入女性、金發條件特征的圖像,圖6(c)是加入黑皮膚條件特征的圖像,圖6(d)是加入白皮膚條件特征的圖像。從圖中可以看出,C-SAGAN模型在30次迭代后就可以達到SAGAN模型訓練50次后得到的樣本,并且C-SAGAN生成的樣本特征更明顯,輪廓更分明,細節更清晰。

圖7 CelebA監督模型生成樣本對比圖
圖7為C-SAGAN與目前主流的加入條件特征的生成模型,主要包括條件生成對抗網絡(CGAN),深度卷積生成對抗網絡(DCGAN),基于Wasserstein距離的WGAN和基于條件自我注意生成對抗網絡(C-SAGAN)。從圖中可以看出,經過15次迭代后生成的樣本圖像,CGAN與DCGAN生成模型生成的樣本性別特征區分不明顯,存在模式崩潰且圖像不平滑,WGAN模型生成的樣本性別特征相比較與CGAN與DCGAN較明顯,圖片質量較好,C-SAGAN相比其他監督模型,生成的樣本清晰,人臉五官輪廓特征明顯,因此,C-SAGAN模型生成的樣本圖片質量更好,收斂速度更快。
3.2 MNIST數據集
MNIST數據集是包含70 000張手寫數字的灰度圖片,其中有60 000個訓練樣本和10 000個測試樣本,每張圖片的大小為28×28像素點,總共有0~9的10個類別。
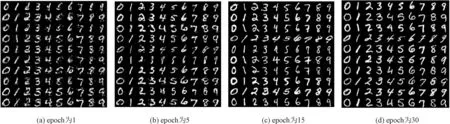
圖8 MNIST生成樣本
圖8是在模型C-SAGAN上生成的效果。在實驗過程中,每列分別表示輸入的條件特征為 0~9,使用條件特征生成的樣本總共迭代30次,僅僅經過了1次迭代,模型就學習到了非常準確的特征,但圖像不清晰,有大量的噪聲。當到達 30 次迭代后,生成器已經能夠生成清晰的圖像,并且圖像平滑且具有多樣性。

圖9 MNIST監督模型生成樣本對比圖
圖9為使用同CelebA實驗相同的加入條件特征的模型對比圖。從圖中可以看出,經過5次迭代后生成的樣本圖像,除C-SAGAN 外,其他的生成模型生成的樣本都存在噪聲且均不平滑。
3.3 評價指標
為了定量地評估生成圖片的質量,筆者采用弗雷歇距離(Fréchet Inception Distance, FID)評估標準衡量生成樣本的質量。弗雷歇距離是一個更具有原則性和綜合性的指標,它可以更好地捕捉生成圖像與真實圖像的相似性,符合人類的區分準則。弗雷歇距離值越低,意味著生成的圖像有更好的圖像質量和多樣性。表1展示了筆者提出的方法與其他生成模型相比較的最佳弗雷歇距離值。

表1 不同模型FID值對比圖
4 結束語
筆者提出一種基于條件自我注意力生成對抗網絡(C-SAGAN)的監督模型,結合SAGAN的優點,引入條件特征,從而對特定類型的圖像進行生成。相比于目前主流的加入監督類型的生成對抗網絡方法,如DCGAN,WGAN等,筆者提出的方法在CelebA、MNIST數據集上生成指定類型的樣本具有良好的表現,生成圖像的質量和多樣性都具有一定的優勢,弗雷歇距離值相比較于SAGAN分別提高了1.26和2.47。但同時發現,在圖像包含復雜的細節特征的情況下,條件特征信息仍有一定局限。不過,相對于簡單的條件屬性特征,C-SAGAN仍是一種較為理想的有監督生成模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
