城鎮居民餐飲消費偏好空間及菜系差異的PSM 分析
2020-01-02 06:21:10俞越馬佳欣周睿玲北京工商大學經濟學院
營銷界 2019年29期
■俞越 馬佳欣 周睿玲(北京工商大學經濟學院)
一、引言
自古以來,中國人民重視一日三餐,中國菜更是以獨具特色和種類之豐富而名揚海外。隨著經濟進步,人民的消費水平也日漸增高,在餐飲方面的消費投入更多,對于餐飲服務的要求也更為精細。中國餐飲服務市場穩步快速增長是有目共睹的,行業總規模從2013 到2018 年提升1.32 萬億,到2022 年將還將保持高速增長,且細分市場不斷地增加。同時餐飲業的O2O 市場也有較好前景。影響對于一家店鋪的評分的項目很多,例如不同的經營時長,不同的菜系分類,不同地理位置,這些都對顧客的評價都會產生影響。
通過對于相關論文的閱讀,陳燕(2016)[1]利用層次分析法,得到影響餐飲消費者購買行為的四大因素:個人、商家、網絡、其它。進而細分為14 個子因素,得出結論即企業選址應該確定餐飲企業城市定位,環境定位如周邊居民收入定位,注重維護企業聲譽,注重特色,注重和消費者間網絡溝通;關于餐飲消費行為特征分析,岳子靜[2]基于美團網數據,探究用戶的菜系偏好以及各菜系的傳播與發展情況;吳麗云[3]以大眾點評網為例,分析了餐飲消費者的網絡評論內容,發現不同消費水平的消費者消費偏好有明顯差異,餐飲消費者最關注的前五位要素是:食物、環境、服務、價格和便利性;任彬[4]從性別、地區、時間三個維度對微博用戶的飲食習慣特色進行了交叉分析,展示了飲食表達特色的分析結果。在消費行為的研究方面,莊巖[5]從農村居民旅游消費行為和旅游消費結構對農村居民的旅游消費進行了研究;蔡曉梅[6]從飲食消費頻率、時段分布和消費持續時長三方面分析了廣州居民在外飲食消費行為的時間特征;在飲食消費行為的空間分布上, 提出了不同類型飲食消費行為的圈層分布圖和高低檔次飲食消費行為的空間帶狀圖。
這些研究從城市差異、消費者飲食偏好差異、餐飲店鋪環境差異做了分析,還對飲食消費時段分布等做了分析,給予讀者分析問題的多種視角,對于一些干擾情況,比如確定是否是因為某一個變量造成了被解釋變量有一定差距,還未非常明白地確認,對這些因素進行排除相互干擾的工作也還未做,本文意在通過PSM 模型減少干擾度,進一步探索不同菜系之間、不同消費水平之間的打分差異,并利用半徑匹配法、最近鄰匹配法、核匹配法三種方法檢驗匹配效果,發現顧客的菜系偏好,為店鋪決策帶來更多結論。
二、傾向性得分匹配方法(PSM)
本文將繁華地區樣本作為處理組、非繁華地區樣本作為對照組,并運用PSM 方法展開分析,具體方法如下。
(一)匹配變量的篩選
匹配變量用logit 模型來回歸以確定,根據AUC 的值可以判斷出是否具有較好的擬合程度。一般而言,當我們利用Logit 模型求出選擇的匹配變量,AUC 大于等于0.8 代表有較好的匹配效果。
(二)平均處理效應的衡量
在考察是否為老店、是否繁華以及什么菜系這些不同的角度帶來店鋪評價打分差異時的一個關鍵性問題是,對一個店鋪而言只能分析其中一種變量,即為典型的反事實因果推斷分析框架。Rosenbaum & Rubin(1983)[8]提出了傾向性得分匹配(Propensity Score)方法,通過找到與處理組(Treated Group)主要特征盡可能相似的控制組(Comparison Group),比較兩者之間的差異效應,從而更加客觀的評價不同身份帶來的影響差異與效果。傾向性得分被定義為:
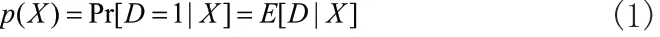
其中,X為自變量的多維向量,是一系列可能影響店鋪評價打分的變量;D是指標變量,取值1 表示為處理組店鋪,取值0 表示對照組店鋪。理論上,如果我們可以獲得傾向性得分的估計量(average treatment effect on the treated)則為處理組受到的平均處理效應 (Becker & Ichino, 2002),如下:
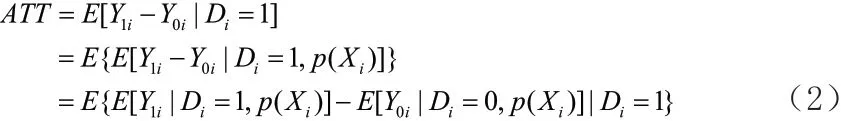
其中,Y1i和Y0i分別為處理組與對照組店鋪潛在的被顧客評價打分所具有的潛在偏好因素。
三、變量與描述統計
本文的數據主要來源于北京大學開放研究數據平臺的“大眾點評網餐廳口碑數據”[17],其中包含3124 條大眾點評網廣州站美食分類下多種類型餐飲店店家評價和評論信息。
(一)變量選擇
餐廳的口碑得分是本研究的目標變量,主要包括等4 種口碑得分。分類變量主要包括是否老店(營業時長大于1000 天的被定義為老店,小于1000 天的為非老店)及各種菜系(包括川菜、粵菜、粥粉面、西餐、日本料理)。相關的匹配變量包括區域類別(分為白云區、海珠區、天河區、越秀區等4 個區域)、星級店鋪評價人數,高質量店鋪評價人數、推薦率、照片數、是否可團購等變量。
(二)描述性統計
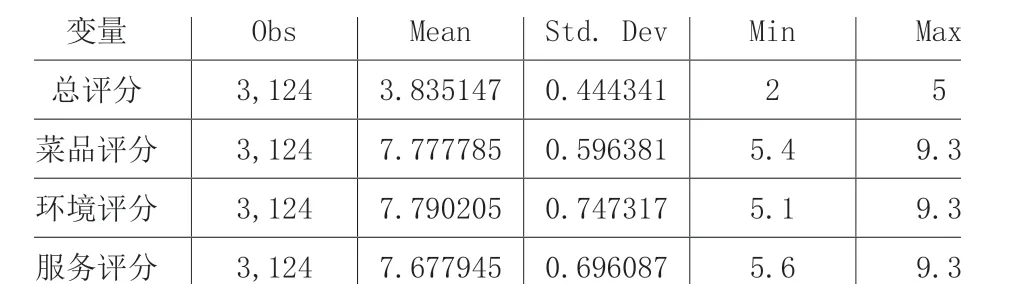
表1 對評分類指標進行統計分析
表1 對餐廳的觀測值、均值、標準偏差、最大、最小值進行了分析。在3124 個觀測值中,餐廳的平均評分等級為3.83,其標準偏差小于其余各變量(口味、環境、服務),說明評分等級相對較為集中。其中餐廳評級的最高等級為5 級,最小值為2 級。餐廳口味的評分均值為7.78,標準差大于餐廳評級這一變量。值得一提的是,口味打分、環境打分、服務打分的最大值都是9.3。餐廳服務的平均水平在7.79 分左右,其標準偏差在0.75 左右,數據的離散程度在4 個變量中是最大的,其最小值為5.1 分。餐廳服務質量評分的均值是7.68 左右,標準差僅次于“服務”這一變量的標準差,其最小值為5.6,是四個變量中最大的。
四、實證分析
(一)匹配變量選擇
我們選取是否為繁華區為被解釋變量(繁華地區為實驗組,非繁華地區為對照組),區域類別(分為白云區、海珠區、天河區、越秀區等4 個區域)、星級店鋪評價人數、高質量店鋪評價人數、推薦率、照片數、是否可團購等變量做為解釋變量,運用logit 模型展開匹配變量的選擇,具體結果見表2。
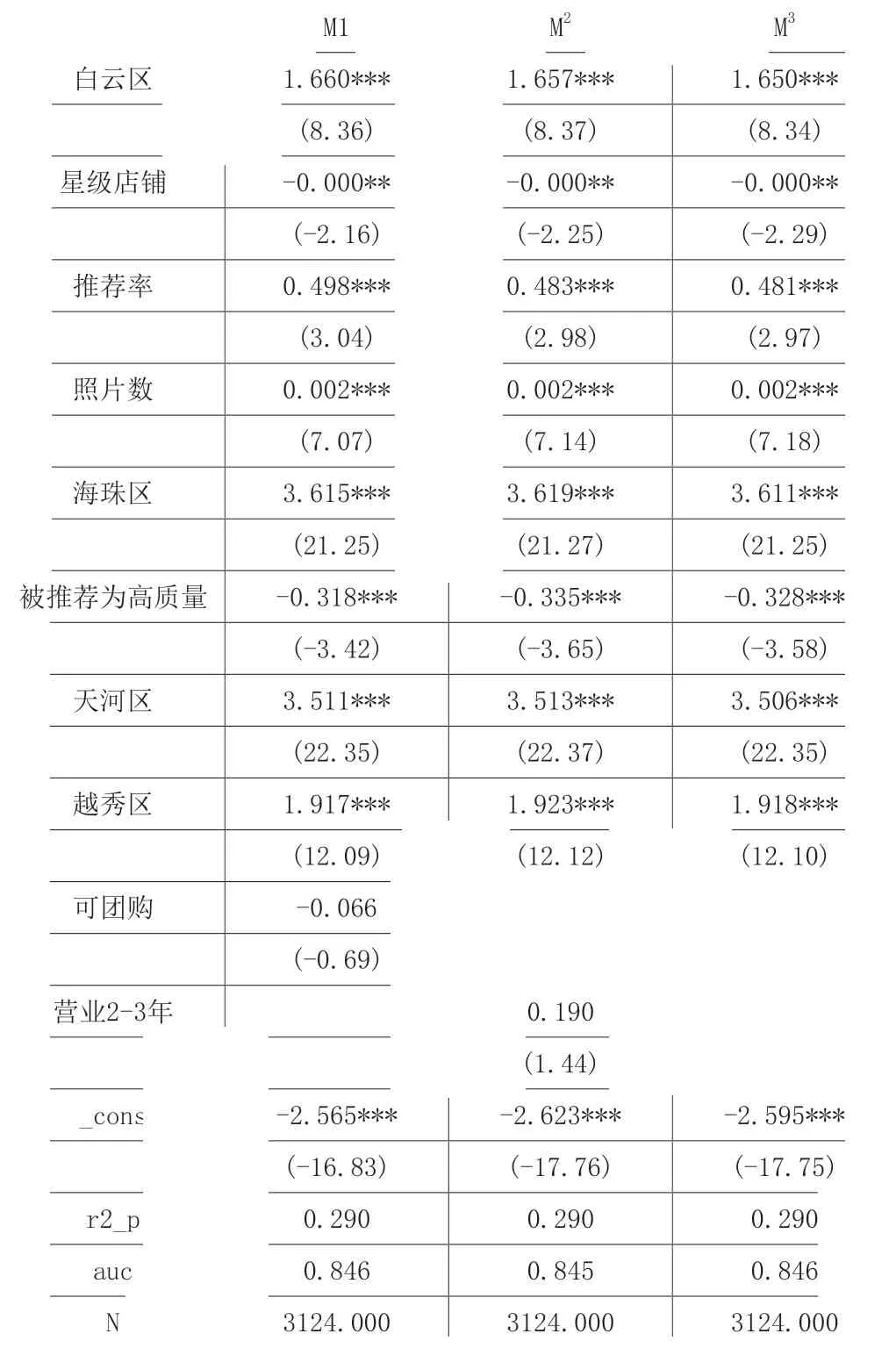
表2 匹配變量的篩選
根據Sturmer,Joshi,Glynn,Avorn,Rothman and Schneeweiss(2006)的研究[9],當AUC 達到0.8 時,匹配效果是比較良好的,從表中可見,模型1-3 的AUC 均達到了0.845 以上,匹配效果良好。另外,在模型1、模型2 中,可團購、營業時間為2-3 年均不顯著,為此,本文選擇模型3 作為最終的匹配結果。
為了檢驗模型3 的匹配效果,我們還進一步做了匹配前后的核密度圖,這里僅用半徑匹配法為例來展示匹配效果,具體見圖1。
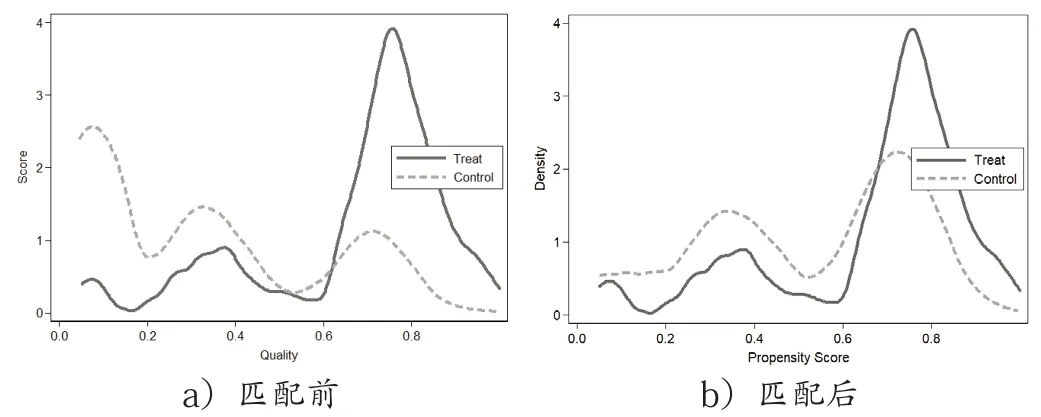
圖1 匹配前后核密度圖對比
從圖中可以看出,在匹配前對照組和實驗組的概率分布圖還存在明顯差異,而完成匹配后,對照組和實驗組的概率分布已經很接近了,匹配效果良好。
(二)利用ATT 模型檢驗匹配結果
為了獲取更穩健的結果,本文分別運用最近鄰匹、半徑匹配、核匹配等三種匹配方法估計不同繁華區域對餐飲企業口碑得分的平均處理效果(ATT),結果見表3。
首先,我們對全樣本進行分析,從表3 可以看到,三種匹配方法下,處理組(繁華地區)和控制組(非繁華地區)的服務評分均呈現出顯著的差異,繁華地區較非繁華地區高出0.101-0.126 分;而在菜品評分,環境打分方面,繁華地區與非繁華地區的ATT 不存在顯著差異。
接著,我們進一步按營業天數分類,探討繁華地區與非繁華地區在總評分、菜品打分、服務打分和環境打分等方面的ATT 差異,見表3。對于營業天數大于1000 天的店鋪,不存在顯著的差異。對于營業天數小于1000 天的店鋪有顯著的差異,尤其是對于服務的評分方面,繁華地區與非繁華地區相比高出0.068-0.167 分。
最后,我們還根據不同菜系分類,探討繁華地區與非繁華地區在總評分、 等方面的ATT 差異,見表4。
由表4,所用方法順序與表4 相同,菜品類型分別是川菜、日式料理、西餐、粵菜、粥粉面。對于不同菜品來說,是繁華地區與非繁華地區對四項評分類指標的打分沒有顯著影響。處理組(繁華地區)和控制組(非繁華地區)的總評分,以及服務評分均在日式料理呈現一定差異,這表明日式料理的服務評分可能與店鋪地理位置有關系。西餐方面,繁華地區和非繁華地區在服務評分有一定的差異。粵菜的環境和服務評分,粥粉面的環境評分,都和店鋪開設在繁華地區與否有很大關系。
五、結論與啟示
由本文得到如下結論:(1)日式料理的服務評分可能與店鋪地理位置有關系,開店地理位置需仔細考慮;(2)繁華地區和非繁華地區的服務評分均呈現出顯著的差異;營業天數小于1000 天的店鋪對于服務的評分方面有顯著的差異。參考文獻
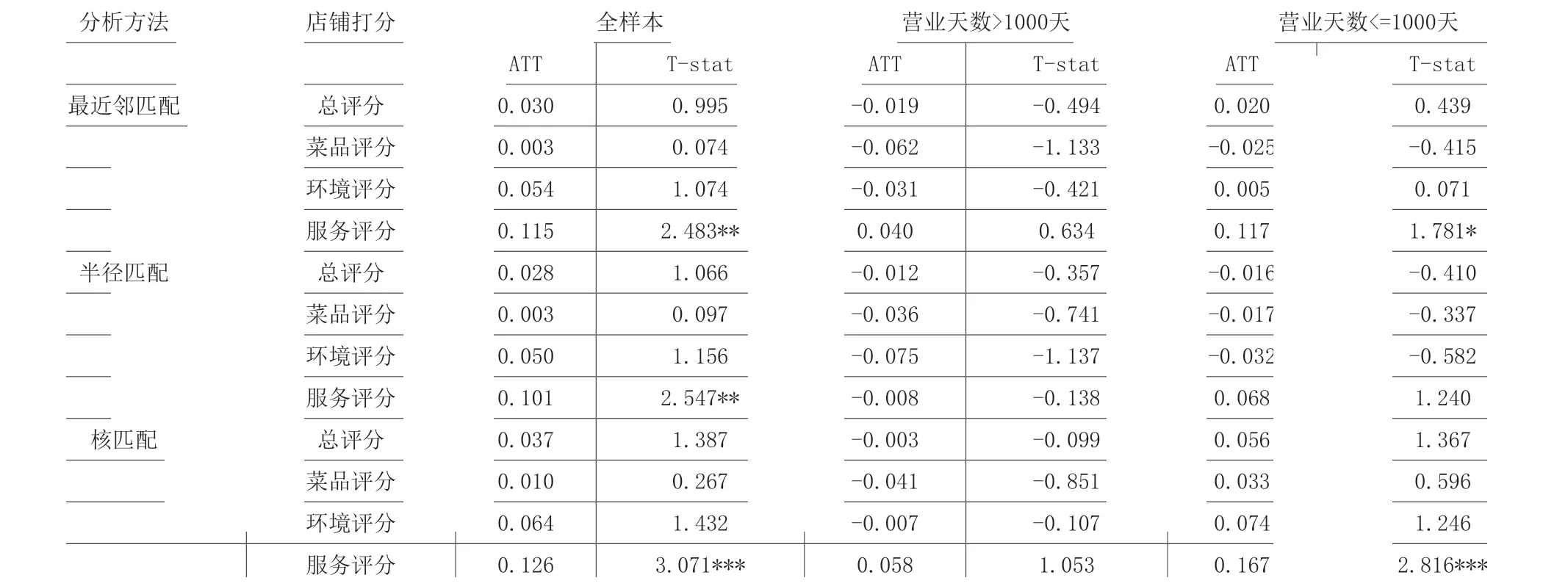
表3 全樣本、不同營業天數類別的ATT估計值
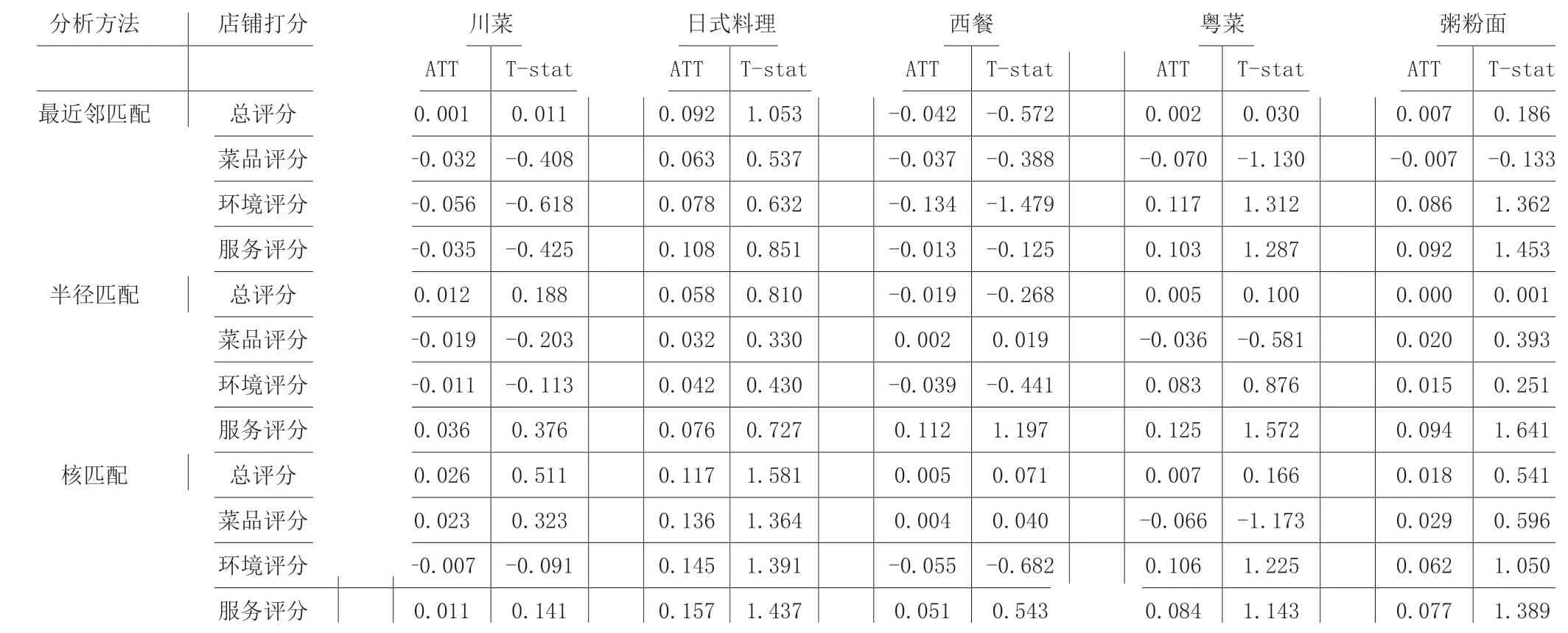
表4 菜系為分類的ATT檢驗
[1]陳燕.餐飲消費者購買行為影響因素探討[J].商業經濟研究,2016(1):36-38.
[2]岳子靜,章成志,周清清.利用在線評論挖掘用戶飲食偏好——以北京地區為例[J].圖書館論壇,2017,37(3):108-115.
[3]吳麗云,陳方英.基于網絡評論內容分析的餐飲消費者行為研究[J].人文地理.2015(5):147-152.
[4]任彬.基于微博的用戶飲食特色及表達習慣分析[D].哈爾濱:哈爾濱工業大學,2005.
[5]莊巖,毛曉東.中國農村居民旅游消費行為與消費結構分析.改革與戰略[J].2017(9):114-116.
[6]蔡曉梅,賴正均.廣州居民在外飲食消費行為的時空間特征研究[J].人文地理,2008,101(3):79-84.
[7]司倩楠,2018,"大眾點評網餐廳口碑數據",http://dx.doi.org/10.18170/DVN/EB6KJ1, 北京大學開放研究數據平臺,V1.
[8]Estimating the impact of antenatal care visits on institutional delivery in India: A propensity score matching analysis.
[9]Sturmer, Joshi, Glynn, Avorn, Rothman and Schneeweiss.2006.10.1016/j.jclinepi.2005.07.004.
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
今日農業(2019年14期)2019-09-18 01:21:54
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
今日農業(2019年12期)2019-08-15 00:56:32
中國特種設備安全(2018年11期)2019-01-08 02:08:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
商周刊(2017年9期)2017-08-22 02:57:56
