深度學(xué)習(xí)法在收入預(yù)測問題中的應(yīng)用
2020-01-05 07:00:06顧強(qiáng)
軟件導(dǎo)刊 2020年11期
關(guān)鍵詞:深度學(xué)習(xí)

摘 要:為了提升電信行業(yè)收入預(yù)測問題準(zhǔn)確率,建立基于循環(huán)神經(jīng)網(wǎng)絡(luò)和長短時記憶網(wǎng)絡(luò)相結(jié)合的收入預(yù)測模型。首先對數(shù)據(jù)作預(yù)處理,然后建立卷積層進(jìn)行核心預(yù)測算法優(yōu)化,再通過訓(xùn)練尋找最優(yōu)參數(shù),并將其應(yīng)用于電信運(yùn)營商收入預(yù)測。實驗結(jié)果表明,該模型可以預(yù)測出未來一個月或者幾個月的收入增減變化趨勢,預(yù)測準(zhǔn)確率比傳統(tǒng)方法提高20%,算法收斂性也提高約15%。該模型預(yù)測結(jié)果對于電信行業(yè)制定營銷方案具有較好指導(dǎo)作用。
關(guān)鍵詞:收入預(yù)測;深度學(xué)習(xí);神經(jīng)網(wǎng)絡(luò);長短時記憶網(wǎng)絡(luò)
DOI:10. 11907/rjdk. 201687
中圖分類號:TP301 ??? 文獻(xiàn)標(biāo)識碼:A?????? 文章編號:1672-7800(2020)011-0001-05
Application of Deep Learning Method in Revenue Forecast
GU Qiang
(China Mobile Group Jiangsu Co., Ltd.,Nanjing 210000,China)
Abstract:In order to improve the accuracy of revenue forecast in communication industry, the arevenue forecast model based on long short-term memory network of recurrent neural network is established in this paper. First, the data is preprocessed, then the convolutional layer is established to optimize the core prediction algorithm. The training is carried out to find the optimal parameters, and it is applied to the revenue prediction of telecom operators. The experimental results show that the model can predict the overall increase and decrease trend of income in the next month or several months. The prediction accuracy is improved by 20% compared with the traditional method, and the convergence of the algorithm is improved by about 15%. The prediction results of the model have a good guiding role for the communication industry to develop sales plans.
Key Words:revenue forecast; deep learning; neural network; long-short term memory network
0 引言
互聯(lián)網(wǎng)時代,隨著電信行業(yè)的興起,各企業(yè)開始了搶占市場份額的戰(zhàn)爭。通過已有收入數(shù)據(jù)對未來收入進(jìn)行預(yù)測,掌握收入變化趨勢和內(nèi)在規(guī)律,根據(jù)結(jié)果合理調(diào)整營銷策略以得到更好發(fā)展成為各行各業(yè)的現(xiàn)實需要[1]。5G時代來臨,國內(nèi)電信市場發(fā)展態(tài)勢良好,國家進(jìn)一步加快信息化建設(shè),電信行業(yè)的業(yè)務(wù)種類變多,用戶數(shù)量大幅增長,給電信行業(yè)收入預(yù)測增加了難度,使用傳統(tǒng)的時間序列收入預(yù)測方法誤差變大[2]。因此,如何提高電信業(yè)務(wù)收入預(yù)測準(zhǔn)確性具有一定研究價值。本文主要根據(jù)電信行業(yè)經(jīng)營收入相關(guān)數(shù)據(jù),建立合適的收入預(yù)測模型。
1 收入預(yù)測研究現(xiàn)狀
解決收入預(yù)測問題的基本流程為:輸入歷史收入序列—提取序列特征—預(yù)測未來收入序列。
收入預(yù)測方法根據(jù)數(shù)據(jù)來源分為:宏觀預(yù)測和微觀預(yù)測、定性預(yù)測和定量預(yù)測[3,4]。幾種常用方法有回歸分析法、統(tǒng)計學(xué)預(yù)測法、機(jī)器學(xué)習(xí)方法等,主要通過一些指標(biāo),如GDP發(fā)展水平、市場占比、歷史收入數(shù)據(jù)等對行業(yè)的發(fā)展趨勢、盈利增減趨勢作出預(yù)測[5-6]。
傳統(tǒng)預(yù)測方法利用統(tǒng)計學(xué)方法[7]解決時間序列預(yù)測問題,對于具有線性關(guān)系的序列預(yù)測擬合程度較好,而對于實際情況中普遍存在的具有非線性關(guān)系的序列預(yù)測準(zhǔn)確度效果較差,尚有很大改進(jìn)空間[8]。時間序列方法的最大缺陷是適用于數(shù)據(jù)量較少且結(jié)構(gòu)簡單、噪聲較少的情況,并且只能對一維數(shù)據(jù)進(jìn)行分析,當(dāng)研究數(shù)據(jù)有多個維度時,需要對每個維度單獨分析,無法提取出數(shù)據(jù)不同維度之間的特征關(guān)系。如何選擇更有效的方法解決這類問題,引發(fā)了部分學(xué)者在該領(lǐng)域探索的興趣[9]。
20世紀(jì)初,隨著人工智能的快速發(fā)展,深度學(xué)習(xí)算法逐漸得以完善和發(fā)展,并廣泛應(yīng)用于圖像識別和分類、機(jī)器翻譯、語音識別等領(lǐng)域。機(jī)器學(xué)習(xí)預(yù)測方法在農(nóng)作物產(chǎn)量預(yù)測[10]、稅收收入預(yù)測[11]以及環(huán)境污染[12]變化等時間序列問題上取得了比傳統(tǒng)統(tǒng)計學(xué)方法更好的效果。比如,隨機(jī)森林、支持向量機(jī)、神經(jīng)網(wǎng)絡(luò)[13-15]等方法都可以擬合此類非線性時間序列問題。文獻(xiàn)[16]曾利用人工神經(jīng)網(wǎng)絡(luò)實現(xiàn)金融領(lǐng)域的預(yù)測。通信行業(yè)的收入數(shù)據(jù)復(fù)雜多樣,不適合人工提取特征,因此在解決電信行業(yè)收入預(yù)測問題中,運(yùn)用深度學(xué)習(xí)方法勢在必行。學(xué)者們發(fā)現(xiàn),深度學(xué)習(xí)算法在解決此類序列數(shù)據(jù)問題上十分有效,尤其是循環(huán)神經(jīng)網(wǎng)絡(luò),其預(yù)測準(zhǔn)確性得到顯著提升。
循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks,RNN)的主要優(yōu)勢是可以學(xué)習(xí)到數(shù)據(jù)長期的依賴關(guān)系,并捕捉數(shù)據(jù)時間上的依賴關(guān)系。但是訓(xùn)練RNN網(wǎng)絡(luò)的困難之處在于RNN結(jié)構(gòu)隨時間變化具有向后依賴性,因此在學(xué)習(xí)階段,網(wǎng)絡(luò)會變得非常復(fù)雜,難以收斂。而長短時記憶網(wǎng)絡(luò)(Long Short-Term Memory Network,LSTM)作為RNN的一種變形,更加適合于序列型數(shù)據(jù)預(yù)測,并且解決了長期依賴問題。文獻(xiàn)[17]建立基于LSTM的日銷售額預(yù)測模型,驗證了LSTM網(wǎng)絡(luò)在該類問題上的良好性能;文獻(xiàn)[18]指出LSTM對于序列變化具有時序性變化的序列,有利于提高預(yù)測精度;文獻(xiàn)[19]提出一種試圖模擬人腦皮層的機(jī)器學(xué)習(xí)技術(shù),對于周期性變化的數(shù)據(jù)效果較好。
由此可見,相比于傳統(tǒng)統(tǒng)計學(xué)預(yù)測方法,基于RNN的深度學(xué)習(xí)網(wǎng)絡(luò)具有不需要人工提取序列特征的優(yōu)勢,而且擅長處理大量數(shù)據(jù)。因此,本文在循環(huán)神經(jīng)網(wǎng)絡(luò)RNN的結(jié)構(gòu)中加入長短時記憶網(wǎng)絡(luò)LSTM,不僅可以利用RNN擅長提取具有長時間依賴關(guān)系數(shù)據(jù)的特性,而且LSTM的加入使得預(yù)測算法收斂性和準(zhǔn)確性得到顯著改善。因此,本文建立基于LSTM-RNN的收入預(yù)測模型。
2 基于LSTM-RNN的收入預(yù)測模型設(shè)計
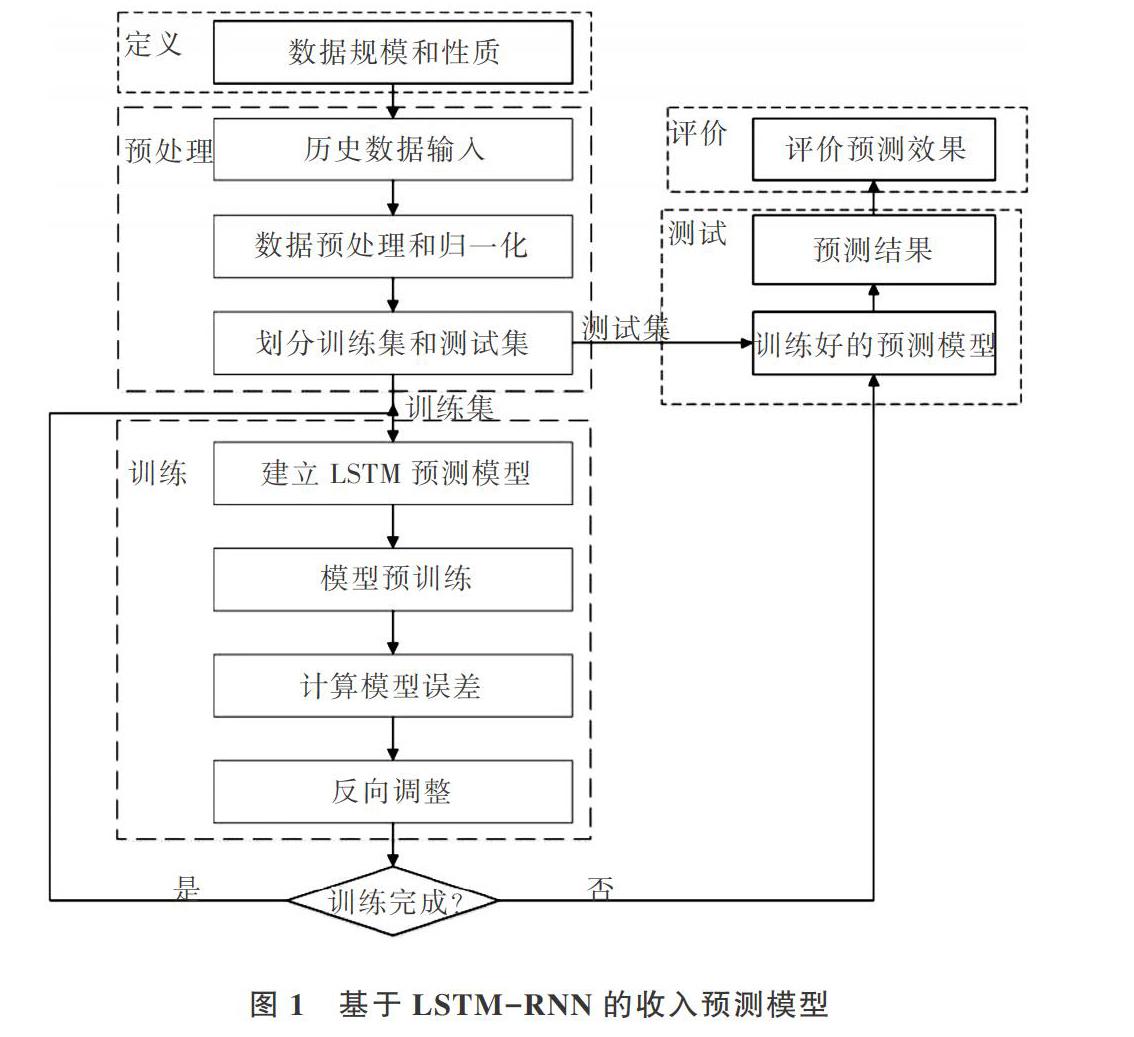
長短時記憶網(wǎng)絡(luò)LSTM由循環(huán)神經(jīng)網(wǎng)絡(luò)RNN發(fā)展而來,屬于RNN的一種變體[20]。相比于傳統(tǒng)RNN、LSTM網(wǎng)絡(luò)結(jié)構(gòu)而言,它增加了3個“門”的設(shè)計,使得它既擅長于捕捉數(shù)據(jù)的長期信息,又解決了RNN網(wǎng)絡(luò)結(jié)構(gòu)所導(dǎo)致的長期依賴而帶來的梯度消失或者梯度爆炸問題,被廣泛應(yīng)用于序列問題處理[21]。本文主要針對某電信基礎(chǔ)運(yùn)營商2019年以來至今的歷史每日收入數(shù)據(jù),在循環(huán)神經(jīng)網(wǎng)絡(luò)基礎(chǔ)上建立長短時記憶層LSTM,更好地建立一個完整的基于LSTM-RNN的電信運(yùn)營商收入預(yù)測模型,如圖1所示。
由圖1可以看出,整個收入預(yù)測模型設(shè)計分為5個模塊:數(shù)據(jù)定義模塊和預(yù)處理模塊,用以處理深度學(xué)習(xí)網(wǎng)絡(luò)輸入;LSTM-RNN收入預(yù)測模型訓(xùn)練模塊,使用分割好的大量數(shù)據(jù)對模型進(jìn)行訓(xùn)練,尋找到最佳參數(shù);測試模塊和結(jié)果評價模塊,使用訓(xùn)練好的模型,輸入測試集數(shù)據(jù),將結(jié)果與真實值對比,分析模型可行性。
2.1 基于LSTM-RNN的數(shù)據(jù)處理模塊
收入預(yù)測問題可看作時間序列預(yù)測問題加以解決,需依次對數(shù)據(jù)進(jìn)行如下操作:①先清洗數(shù)據(jù)也即數(shù)據(jù)異常處理;②對不平穩(wěn)數(shù)據(jù)進(jìn)行差分處理;③數(shù)據(jù)歸一化操作,消除數(shù)據(jù)量綱;④將收入數(shù)據(jù)集按照一定比例分割成訓(xùn)練集和測試集兩部分。
(1)數(shù)據(jù)異常處理及因子分析。首先對數(shù)據(jù)做時序圖,發(fā)現(xiàn)存在一些數(shù)值過大的數(shù)據(jù)導(dǎo)致整體數(shù)據(jù)的均值和方差顯著增大,不利于預(yù)測,需要對這些數(shù)據(jù)加以處理。
在電信收入數(shù)據(jù)中,數(shù)據(jù)間的邏輯關(guān)系為:當(dāng)日收入=語音業(yè)務(wù)收入+數(shù)據(jù)業(yè)務(wù)收入+其它收入,其中,“其它語音收入”和“其中話音增值收入”,歸屬“語音業(yè)務(wù)收入”;“短信收入”和“流量收入”,歸屬“數(shù)據(jù)業(yè)務(wù)收入”。
考慮到其中存在一些偏差過大的數(shù)據(jù),本文采用相鄰平均法對這些異常數(shù)據(jù)取其前后兩天的數(shù)據(jù)均值代替。其中,[Xt]表示第t天的收入向量,[X=(x1,x2,…,x8)],使用各種收入數(shù)據(jù)表示這一天的收入特征。
根據(jù)特征之間存在相關(guān)性,將原來8個維度的特征進(jìn)行刪減,縮小數(shù)據(jù)規(guī)模,更有利于提高預(yù)測準(zhǔn)確性。最后剩下“當(dāng)日收入”“語音增值收入”“其它收入”“數(shù)據(jù)業(yè)務(wù)收入”4列數(shù)據(jù)。同時,定義本文目標(biāo)為輸入[X=(X1,X2,X3,…,XT)],即前T天的收入序列,對于第t天的收入向量[Xt=(x1t,x2t,x3t,x4t)],其中,[x1t]表示第t天的當(dāng)日收入,以此類推。同時,模型可以對這4列數(shù)據(jù)同時進(jìn)行預(yù)測,并規(guī)定研究對象為當(dāng)日總收入,也即預(yù)測模型的輸出為T+a天的當(dāng)日收入這一項。其中,a值表示參數(shù)變化。
(2)數(shù)據(jù)差分處理。針對收入數(shù)據(jù)存在明顯的周期性,一般1個月為1個周期。因此,可以對數(shù)據(jù)進(jìn)行差分處理,也即使用后一天數(shù)據(jù)減去前一天數(shù)據(jù),預(yù)測結(jié)束后再進(jìn)行逆差分處理,還原數(shù)據(jù)真實值。
(3)數(shù)據(jù)歸一化處理。當(dāng)數(shù)據(jù)經(jīng)過歸一化處理后,數(shù)據(jù)分布就會被限制在一定范圍內(nèi),一般是[0,1]。在對深度學(xué)習(xí)網(wǎng)絡(luò)進(jìn)行訓(xùn)練時,可以加速梯度下降的尋優(yōu)過程。本文采用最大最小標(biāo)準(zhǔn)化,如式(2)所示,其中,[X]表示收入向量。
(4)數(shù)據(jù)集分割。在與神經(jīng)網(wǎng)絡(luò)有關(guān)的算法中,需要對數(shù)據(jù)集進(jìn)行分割,方便后續(xù)訓(xùn)練及結(jié)果分析。對于一組收入序列值,將數(shù)據(jù)集分成兩部分:訓(xùn)練集和測試集。為了保證預(yù)測準(zhǔn)確性,測試集不參與模型訓(xùn)練過程。一般訓(xùn)練集和測試集數(shù)據(jù)量之比為7:3,如果數(shù)據(jù)集很大,比如幾萬數(shù)量級,則這一比例可以擴(kuò)大。
2.2 基于LSTM-RNN的收入預(yù)測模型訓(xùn)練模塊
LSTM作為一種深度學(xué)習(xí)算法,有它自己的網(wǎng)絡(luò)結(jié)構(gòu),并且根據(jù)數(shù)據(jù)集的不同而變化。神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)算法由兩部分內(nèi)容構(gòu)成,它們是前向傳播和反向傳播。其中,前向傳播用于計算損失函數(shù),反向傳播用于計算導(dǎo)數(shù),兩部分相互監(jiān)督,不斷迭代、優(yōu)化,最后得到使損失函數(shù)最小的參數(shù)值,這時網(wǎng)絡(luò)訓(xùn)練完成。
對本文電信運(yùn)營商的收入數(shù)據(jù)集進(jìn)行調(diào)優(yōu)后的網(wǎng)絡(luò)結(jié)構(gòu),使用偽代碼描述如下:
Algorithm 1 定義內(nèi)部網(wǎng)絡(luò)結(jié)構(gòu)
# train訓(xùn)練數(shù)據(jù)集 ,batch_size 批次大小, nb_epoch迭代次數(shù),neurons 神經(jīng)元個數(shù)
def fit_lstm(train,batch_size,nb_epoch,neurons):
model=Sequential ()
model.add(LSTM (input_shape, neurons))
# 其中input_shape 包含兩個元素,第1個表示每個輸入樣本的序列長度,第2個元素表示每個序列# 中1個元素的維度,在本文電信收入數(shù)據(jù)集中,該參數(shù)值設(shè)置為(3,4),表示使用前3天的收入進(jìn)行預(yù)測,4表示4個收入特征。
# neurons 決定在一層里L(fēng)STM單元的數(shù)量,也表示這一層輸出的維度。
model.add(Dropout)
model.add(Dense)
model.compile(定義loss=mean_squared_error,優(yōu)化方法為adam)
return model
由圖2可以看出,整個模型的網(wǎng)絡(luò)結(jié)構(gòu)類似于一個搭積木的過程,添加的網(wǎng)絡(luò)層有1個LSTM層、1個Dropout(正則化層),最后是1個(Dense)全連接層。這些層的個數(shù)在實際操作過程中可以任意添加,組合出最佳效果。
(1)LSTM網(wǎng)絡(luò)層。該層是算法核心結(jié)構(gòu),內(nèi)部實現(xiàn)原理如上文所示。已有研究表明,一般情況下LSTM層的個數(shù)為1~4即可取得良好效果。層數(shù)越多,對于高級別特征的學(xué)習(xí)能力就越強(qiáng),但也更加難以收斂。本文使用了一層,預(yù)測效果已經(jīng)達(dá)到預(yù)期。
(2)Dropout(正則化層)。在深度學(xué)習(xí)網(wǎng)絡(luò)中添加dropout層可以減少模型過擬合。簡單而言,在神經(jīng)網(wǎng)絡(luò)前向傳播時,某個神經(jīng)元的激活值以一定概率p停止工作,這樣可以增強(qiáng)模型泛化能力,因為它不會太依賴于某些局部特征,基本原理如圖3所示。
(3)Dense層(全連接層)。很多網(wǎng)絡(luò)結(jié)構(gòu)中都會有全連接層,最常應(yīng)用于卷積網(wǎng)絡(luò)。而在本文模型結(jié)構(gòu)中,LSTM的輸入要求是三維,因此在輸入數(shù)據(jù)時需使用reshape函數(shù)將數(shù)據(jù)轉(zhuǎn)換成三維,在輸出時,需再添加一個全連接層將其還原成模型想要的一維輸出。
2.3 基于LSTM-RNN的收入預(yù)測算法
基于長短時記憶網(wǎng)絡(luò)LSTM的收入預(yù)測偽代碼如下:
Algorithm 2:lstm收入預(yù)測算法
Input:
1訓(xùn)練過程:按照時間順序排列的前1 283個收入數(shù)據(jù)向量。
2測試過程:按時間順序排列的最后74個收入數(shù)據(jù)向量。
每個向量表示為X=(x1,x2,x3,x4)。
Output:
對74天收入數(shù)據(jù)的預(yù)測值。
1?? 加載收入數(shù)據(jù) ‘data.csv
2?? 對數(shù)據(jù)進(jìn)行差分轉(zhuǎn)換
3?? 給數(shù)據(jù)打標(biāo)簽,轉(zhuǎn)換為監(jiān)督學(xué)習(xí)型數(shù)據(jù) supervised_values
4?? 按需求分割出訓(xùn)練集和測試集,同時做數(shù)據(jù)歸一化處理
5?? 定義模型lstm_model = fit_lstm(訓(xùn)練規(guī)模,迭代次數(shù),神經(jīng)元個數(shù))
6?? 開始訓(xùn)練過程
7??????? for i in range(迭代次數(shù))
8??????????? model.fit()
9??????????? 訓(xùn)練完一個epoch,重置一次網(wǎng)絡(luò)
10? 結(jié)束訓(xùn)練過程
11
12? 進(jìn)行預(yù)測訓(xùn)練 lstm_model.predict(輸入數(shù)據(jù)形狀,batc_size)
13
14? 開始預(yù)測
15?????? for i in range(測試集規(guī)模)
16?? ????????導(dǎo)入測試集數(shù)據(jù)
17?????????? yhat=forecast_lstm(model,batch_size,一維數(shù)據(jù))使用訓(xùn)練好的模型進(jìn)行預(yù)測
18?????????? 對yhat進(jìn)行逆縮放
19?????????? 對yhat進(jìn)行逆差分變換
20????????? 存儲預(yù)測值prediction
21? 結(jié)束預(yù)測
22
23? 求真實值和預(yù)測值之間的標(biāo)準(zhǔn)差
24? 畫圖分析結(jié)果
3 仿真實驗
3.1 實驗環(huán)境及超參數(shù)選擇
為了測試本文基于長短時記憶網(wǎng)絡(luò)LSTM的收入預(yù)測效果,在Windows10操作系統(tǒng)、Bios1.1.3、處理器i5-6200U CPU @ 2.30GHz~2.4GHz、內(nèi)存12GB的筆記本上,以及Anaconda3.0、Jupyter Notebook開發(fā)環(huán)境、Python3.6.3、keras2.3.1、tensorflow2.0.0下進(jìn)行電信收入的時間序列預(yù)測實驗。所有數(shù)據(jù)經(jīng)過預(yù)處理后成標(biāo)準(zhǔn)化形式,優(yōu)化方法為Adam方法,重要參數(shù)設(shè)置值如表1所示。
3.2 數(shù)據(jù)預(yù)處理
本文要解決的問題是通過對歷史收入數(shù)據(jù)進(jìn)行建模,預(yù)測未來收入。所采用的數(shù)據(jù)集為電信運(yùn)營商的收入在時間上的序列。該數(shù)據(jù)集共包含統(tǒng)計日期、當(dāng)日總收入、話音業(yè)務(wù)收入、數(shù)據(jù)業(yè)務(wù)收入、其它收入字段,總計1 315天的收入數(shù)據(jù)。其中,每個字段都可以進(jìn)行預(yù)測,但是為了簡化問題,最終目標(biāo)定義為對當(dāng)日總收入的預(yù)測,即最后只輸出當(dāng)日總收入這一字段的預(yù)測值。
(1)數(shù)據(jù)集預(yù)處理過程。對數(shù)據(jù)集中的當(dāng)日收入、話音業(yè)務(wù)收入、數(shù)據(jù)業(yè)務(wù)收入、其它收入、語音收入、話音增值收入、短信收入和流量收入這8個關(guān)鍵字段進(jìn)行預(yù)處理。統(tǒng)計連續(xù)60天的數(shù)據(jù)可以得出,該8個字段呈現(xiàn)明顯的時序性,選取當(dāng)日語音收入和流量收入時序圖為例展示,如圖4所示。
(2)數(shù)據(jù)差分處理。經(jīng)過分析對比發(fā)現(xiàn),收入數(shù)據(jù)存在明顯周期性,如圖4所示,本文使用后一天數(shù)據(jù)減去前一天數(shù)據(jù),預(yù)測結(jié)束后再進(jìn)行逆差分處理,還原數(shù)據(jù)真實值。
(3)數(shù)據(jù)歸一化處理。為保證數(shù)據(jù)分布在一定范圍內(nèi),一般是[0,1]。本文采用最大最小標(biāo)準(zhǔn)化,依據(jù)式(2)加以處理。
(4)數(shù)據(jù)集分割。在本文數(shù)據(jù)集中一共有1 315天的收入數(shù)據(jù),本文規(guī)定所有模型輸入一律以2020年4月份中30天的收入數(shù)據(jù)作為測試集,用于評價模型好壞,并且不參與模型訓(xùn)練過程。
對于時間序列類型數(shù)據(jù),本文采用“滑動窗口”方法劃分單個樣本。將問題轉(zhuǎn)化為監(jiān)督學(xué)習(xí)問題加以處理。本文取前n個時間步的收入數(shù)據(jù)作為輸入X,后一天的當(dāng)日收入數(shù)據(jù)作為標(biāo)準(zhǔn)輸出結(jié)果Y,然后向后滑動窗口分出每個輸入輸出對作為訓(xùn)練樣本。
3.3 仿真結(jié)果分析
在預(yù)測任務(wù)中,常用算法評價指標(biāo)是損失函數(shù)的數(shù)值大小。損失函數(shù)值越小,模型準(zhǔn)確度越高。對于這樣的預(yù)測模型,通常有3種評價方法,本文采用均方根誤差RMSE、平均絕對誤差MAE進(jìn)行評價,計算公式如式(3)所示。
其中,[yt]表示t時刻的收入預(yù)測值,[yt]表示t時刻的收入真實值,m表示測試集的樣本數(shù)量。
最后將2020年4月共30天總收入數(shù)據(jù)作為測試集,得到的擬合結(jié)果如圖5所示。
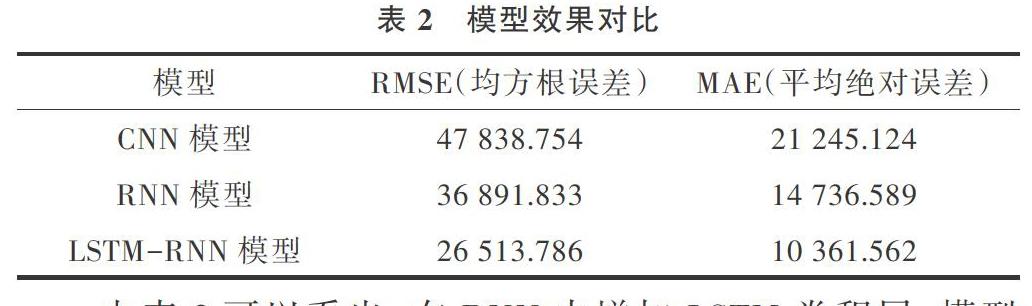
從圖5中可以看出,絕大部分日期的收入預(yù)測值和真實值相差不大,整體趨勢比較吻合,說明該模型測試集數(shù)據(jù)擬合得不錯。雖然算法中的部分日期有少許偏差,預(yù)測值與真實值存在一定差距,查看原始數(shù)據(jù)后發(fā)現(xiàn),數(shù)據(jù)本身來自于移動業(yè)務(wù)收入,業(yè)務(wù)收入類型的數(shù)據(jù)容易受到某些特殊情況的影響,偏離趨勢,就可能會出現(xiàn)上述情況。最后Loss值大概收斂到0.014左右,得到的RMSE值為26 513.786,MAE值為10 361.562。
在無法從直觀上獲知模型準(zhǔn)確性是否提升的情況下,本文將CNN模型、RNN模型、LSTM-RNN模型在同等情況下進(jìn)行仿真實驗,其均方根誤差RMSE值計算以及平均絕對誤差MAE值比較如表2所示。
由表2可以看出,在RNN中增加LSTM卷積層,模型均方根誤差RMSE值和MAE值已經(jīng)大幅縮小,說明預(yù)測準(zhǔn)確性有較大提升,同時算法收斂性也得以提高。
4 結(jié)語
本文對電信運(yùn)營商的各項收入數(shù)據(jù)進(jìn)行分析,得出該收入數(shù)據(jù)是一個周期變化的時間序列,從而建立基于LSTM-RNN的收入預(yù)測模型。設(shè)計核心預(yù)測算法,基于電信運(yùn)營商收入數(shù)據(jù)開展實驗,可以較好地預(yù)測未來一段時間的收入變化情況。本文提出的收入預(yù)測模型對于電信行業(yè)制定營銷方案有一定指導(dǎo)作用。
參考文獻(xiàn):
[1] 音春,柳之乏. 通信服務(wù)收入變動因素分析[J]. 世界電信,2017,18(1):57-63.
[2] 張忠海. 通信行業(yè)收入預(yù)測模型淺析[J]. 現(xiàn)代國企研究,2017,8(12):185-187.
[3] 李博偉,許飛云,楊會超. RBF-BL時間序列模型及其在建模和預(yù)測中的應(yīng)用[J]. 東南大學(xué)學(xué)報(自然科學(xué)版),2020,50(2):368-376.
[4] MAGGIORI E, TARABALKA Y, CHARPIAT G, et al. Convolutional neural networks for large-scale remote-sensing image classification[J]. IEEE Transactions on Geoscience & Remote Sensing, 2017, 55(2):645-657.
[5] 許學(xué)國,桂美增. 基于深度學(xué)習(xí)的技術(shù)預(yù)測方法——以機(jī)器人技術(shù)為例[J/OL]. 情報雜志,2020-07-03.https://kns.cnki.net/kns/brief/default_result.aspx.
[6] 梁霞. 模糊時間序列預(yù)測法的改進(jìn)及應(yīng)用[J]. 內(nèi)蒙古農(nóng)業(yè)大學(xué)學(xué)報(自然科學(xué)版)2018,39(3):94-100.
[7] 江元,楊波,趙東來,等. 基于時間序列分析及機(jī)器學(xué)習(xí)的移動網(wǎng)絡(luò)業(yè)務(wù)量預(yù)測技術(shù)[J].? 物聯(lián)網(wǎng)技術(shù),2020,10(6):42-45.
[8] LIU T,TIAN B,AI Y F,et al. Parallel reinforcement learning-based energy efficiency improvement for a cyber-physical system[C]. IEEE/CAA Journal of Automatica Sinica,2020,7(2):617-626.
[9] 羅雨欣. 基于機(jī)器學(xué)習(xí)的收入預(yù)測研究[J]. 機(jī)電信息,2019,62(24):114-115,117.
[10] 任晶晶. 基于BP神經(jīng)網(wǎng)絡(luò)的山西省農(nóng)民收入預(yù)測模型[J]. 太原學(xué)院學(xué)報(自然科學(xué)版),2017,16(1):57-60.
[11] 劉蘭苓,孫德山,張文政. 基于支持向量機(jī)與BP神經(jīng)網(wǎng)絡(luò)的稅收收入預(yù)測模型[J]. 江蘇商論,2019,36(2):131-133.
[12] 曾豪. 基于LSTM的環(huán)境污染時間序列預(yù)測模型的研究[D]. 武漢:華中科技大學(xué),2019.
[13] 付磊. 基于深層LSTM的分布式負(fù)載預(yù)測模型[J]. 現(xiàn)代計算機(jī),2020,37(9):25-28.
[14] STRUYE J,LATRé S.Hierarchical temporal memory and recurrent neural networks for time series prediction: an empirical validation and reduction to multilayer perceptrons[J]. Neurocomputing,2020:291-301.
[15] KUMAR J P,DIVYENTH A. Modelling and prediction of strength of ultrasonically welded electrical contact joints using artificial neural network[J]. Materials Today: Proceedings,2020,22:4.
[16] 閆洪舉. 基于深度學(xué)習(xí)的金融時間序列數(shù)據(jù)集成預(yù)測[J]. 統(tǒng)計與信息論壇,2020,35(4):33-41.
[17] 吳娟娟,任帥,張衛(wèi)鋼,等. 一種基于LSTM模型的日銷售額預(yù)測方法[J]. 計算機(jī)技術(shù)與發(fā)展,2020,30(2):133-137.
[18] 李金澎,丁博,王雨,等. 基于GA和LSTM的智能交通燈調(diào)度方法[J]. 物聯(lián)網(wǎng)技術(shù),2019,9(12):50-54.
[19] MAJD M,SAFABAKHSH R. Correlational convolutional LSTM for human action recognition[J]. Neurocomputing,2020:224-229.
[20] 宋旭鳴,沈逸飛,石遠(yuǎn)明. 基于深度學(xué)習(xí)的智能移動邊緣網(wǎng)絡(luò)緩存[J]. 中國科學(xué)院大學(xué)學(xué)報,2020,37(1):128-135.
[21] 余本功,許慶堂,張培行. 基于MAC-LSTM的問題分類研究[J]. 計算機(jī)應(yīng)用研究,2020,37(1):40-43.
(責(zé)任編輯:孫 娟)
收稿日期:2020-07-14
基金項目:江蘇移動企業(yè)數(shù)據(jù)中心七期營銷數(shù)據(jù)平臺改造擴(kuò)容項目(B1823482S002);江蘇移動企業(yè)數(shù)據(jù)中心七期擴(kuò)容工程項目(B1823482S001)
作者簡介:顧強(qiáng)(1977-),男,碩士,中國移動通信集團(tuán)江蘇有限公司高級工程師,研究方向為大數(shù)據(jù)技術(shù)、數(shù)據(jù)治理、機(jī)器學(xué)習(xí)建模及人工智能圖像識別。
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
