基于增強問題重要性表示的答案選擇算法研究
2020-01-10 03:17:22謝正文柏鈞獻琚生根
四川大學學報(自然科學版) 2020年1期
謝正文, 柏鈞獻, 熊 熙, 琚生根
(1.四川大學計算機學院, 成都 610065; 2.廣東財經大學財政稅務學院, 廣州 510320; 3.成都信息工程大學網絡空間安全學院, 成都 610225)
1 引 言
答案選擇(answer selection,AS)是問答(question answer, QA)中的一個子任務,也是近年來信息檢索(information retrieval,IR)中的一個熱門話題.答案選擇是根據輸入問題從候選答案列表中選擇最合適的答案.一般情況下,好的答案主要有以下兩個特點.
(1) 問題影響答案,因此一個好的答案必須與問題相關;
(2) 好的答案并非要求嚴格的單詞匹配,而是要表現出更好的語義相關性.
本文給出了一個從WikiQA數據集[1]中提取的例子,如例1所示,正確的答案并沒有直接提到喪生,而是用死亡,受傷等相關語義來代替.
例1 WikiQA數據集問答對
(1) Question:
有多少人在俄克拉何馬城爆炸案中喪生?
(2) Postive Answer:
俄克拉荷馬州的爆炸造成168人死亡,其中包括19名6歲以下兒童,并造成680多人受傷.
(3) Negative Answer:
據估計,炸彈造成至少6.52億美元的損失.
傳統的方法[2-3]通常基于詞法和句法特征,例如解析樹之間的編輯距離[2].這種方法在特征的設計和選擇上非常耗時,而且由于語義的復雜性,特征選取更依賴于經驗.端到端的神經網絡模型可以自動選擇特征[4-6],避免了手動構造特征的麻煩,同時具有強大的擬合能力,被廣泛應用.
近幾年的研究表明[7],答案選擇任務的難點在于捕捉問題句子和答案句子之間復雜的語義關系.而問題和答案之間屬于單向邏輯關系,答案需要根據問題來回答,因此問題表示在答案選擇任務至關重要.鑒于此,本文提出一種基于增強問題重要性表示網絡(question based importance weighting network, BIWN)的答案選擇算法.該算法包括以下機制:(1) 本文在問題和答案進行交互前通過自注意力機制賦予問題句子各個詞不同的權重從而緩解問題句子中的“無用詞”噪聲;(2) 本文構建詞級矩陣,通過詞級矩陣將問題和答案進行細粒度的交互,從而根據問題句子找出答案中的關鍵詞;(3) 本文通過CNN捕獲進行交互后的問題和答案的特征,進行匹配.
答案選擇通常被表述為一個文本匹配問題.以往的工作大致可以分為兩個分支:基于特征選擇的方法和基于神經網絡的方法.傳統的方法傾向于使用特征工程、語言工具或外部資源,這種方法費時且數據稀疏.前人的研究[2,8]通常利用句法解析樹上的信息來匹配問題和答案,而端到端的神經網絡模型可以自動選擇特征,避免了手動構造特征的麻煩;同時具有強大的擬合能力,更重要的是,在答案選擇任務上神經網絡模型的效果媲美于傳統手動構建特征的方法,甚至更優于傳統方法,因此如今被廣泛應用.Feng等人[7]利用卷積神經網絡(CNN)搭建6種不同的模型分別學習問題和答案的語義表示;Wang和Nyberg等人[9]利用循環神經網絡(RNN)更容易捕捉全局序列信息的特點,將問題和答案句中的單詞進行編碼,然后輸出它們的相關性得分; 然而這些模型都缺乏問題和答案句子的交互信息.注意力機制旨在關注與問題最相關的候選答案的片段[10-11],Wang等人[11]在詞嵌入層利用門控注意力機制獲取句子細粒度的語義表示;Nam等人[12]提出迭代模型MAN,該模型利用動態記憶網絡[13]的思想,先用問題向量推導出第一個注意層中的答案向量,然后在下一步中對問題向量進行遞歸,學習第二個注意層中的答案向量.最后,與答案向量進行多步匹配得出分數總和.
以往的模型雖然取得了不錯的效果,仍然存在噪聲詞的影響.本文把噪聲詞總結為以下兩種情況.
(1) 如果問題句子中的詞(例如一些is,are,the等詞)與對應的答案句子中的詞高度相關,但該詞不是問題中的關鍵字,它應該被賦予更小的權重甚至是被忽略,因為它擾亂了加入問題信息后的答案句子的單詞權重分布,從而產生噪聲.
(2) 若一個單詞在答案句子中是局部重要的,但與對應問題語義不相關,則需要賦予它在答案句子中較少的重要性,因其在語義匹配中無用.
本文模型利用自注意力在問題和答案進行交互前緩解問題噪聲詞的影響,同時構建詞級交互矩陣,通過問題句子的信息來獲取答案句子中重要的部分,從而更精確地完成問題和答案之間的語義匹配.
本文的工作很大程度上受到MAN模型進行逐步學習的思想.首先,模型利用自注意力機制將編碼后的問題句子重新分配各個詞的權重,從而產生“干凈”的問題句子,然后將“干凈”的問題句子通過詞級矩陣與答案進行交互,最后通過CNN獲取問題和答案之間的多個特征進行匹配.實驗表明,在WikiQA數據集中,本文模型明顯優于以往忽略了問題噪聲詞的模型,并且在MAP,MRR這兩個評價指標上,本文模型超過MAN模型約0.7%.
本節將詳細描述本文提出的BIWN模型, 模型結構圖如圖1所示.3.1節介紹編碼層中BiLSTM的工作原理;3.2節介紹轉化層中的自注意力機制;3.3節介紹對齊層的相似度詞級矩陣交互;3.4節介紹特征融合層的多窗口CNN;模型最后將CNN提取的特征用一個多層感知機轉換成最后的預測向量.
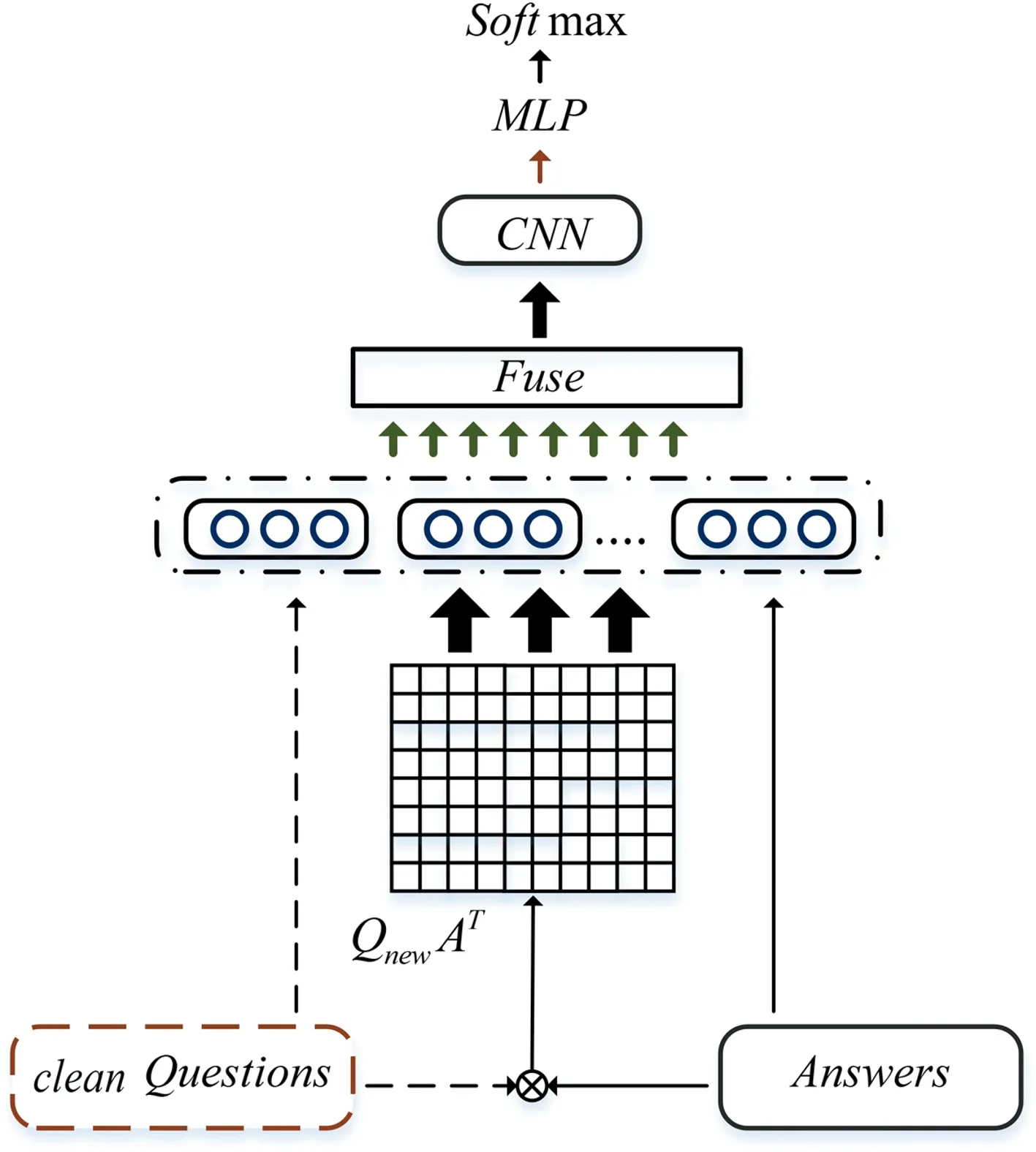
圖1 BIWN模型總體結構圖Fig.1 The network structure of BIWN
3.1 BiLSTM編碼層
輸入兩個文本序列,表示為問題Q和答案A.通過預先訓練的d維詞嵌入,用Hq={hq1,...,hqm}和Ha={ha1,...,han}分別表示問題句向量和答案句向量.其中,hqi∈Rd是句子Hq的第i個詞嵌入.m和n分別表示問題和答案的長度.為了捕捉句子上下文的信息,本文采用BiLSTM來對問題和答案進行編碼.LSTM的隱層維度為u,在t時刻的詞嵌入為xt,前一時刻的隱層和記憶單元分別為ht-1和ct-1,下一時刻的隱層ht和記憶單元ct計算如下.
gt=φ(Wgxt+Vght-1+bg),
it=σ(Wixt+Wiht-1+bi),
ft=σ(Wfxt+Wfht-1+bf),
ot=σ(Woxt+Woht-1+bo),
ct=gt⊙it+ct-1⊙ft,
ht=ct⊙ot.
其中,W∈Ru×d;V∈Ru×u;b∈Rd;σ和φ分別是sigmoid函數和tanh函數;⊙表示兩個向量進行元素相乘,輸入門i,遺忘門f和輸出門o能夠自動控制信息的流動.同時記憶單元ct可以記住長距離的信息,ht是t時刻的向量表示.
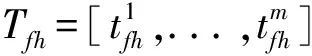
3.2 基于自注意力機制的問題向量重生成
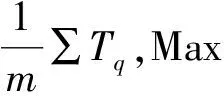

圖2 基于自注意力機制的問題向量生成圖Fig.2 The graph of re-generate the question vector based on Self-Attention Mechanism.
首先,計算問題向量Tq中每個單詞的權重,具體計算公式如下.
v=TqW1
(1)
αq=sigmoid(v)
(2)
其中,W1∈R2u×1表示參數矩陣;αq∈Rm×1表示問題句子中每個單詞不同的權重分布;sigmoid表示非線性激活函數,在得到權重分布之后,將權重αq與問題向量Tq相乘,生成新的問題向量表示Uq∈Rm×2u,具體計算公式如下.
Uq=αq⊙Tq
(3)
3.3 詞級相似度矩陣對齊
詞級相似度矩陣的主要思想是將兩個句子拆分,進行句子間的詞級匹配,詞級矩陣中的元素是句子的局部相似度集合.Wang等人[14]直接用原始的詞向量計算詞級矩陣,但詞向量并未給句子帶來上下文信息.本文采用經過BiLSTM層后的句子向量獲取上下文信息,然后進行詞級矩陣計算.詞級矩陣有兩種計算方式,一種是將兩個句子直接相乘,不帶訓練參數;另一種是利用訓練參數與兩個句子共同作用本文采用兩種詞級矩陣進行建模,同時在后續的實驗(詳見4.2.3節)比較兩種詞級矩陣的優劣.詞級矩陣的兩種計算方式如下.
M(i,j)=Uq(i)Ta(j)T
(4)
(5)
其中,矩陣Wp∈R2u×2u是模型訓練的參數;M(i,j)∈Rm×n,詞級矩陣的每一行是問題中的詞對答案中的每個詞的影響.類似地,詞級矩陣的每一列看成答案中的詞對問題中的每個詞的影響.分別對詞級矩陣的行和列用softmax函數進行歸一化,得到互信息影響因子λq(i,j)和λa(i,j),其中,λq(i,j)和λa(i,j)的取值范圍均在[0,1],最后將問題向量和答案向量與對應的影響因子相乘得到兩個新的向量Eq和Ea.具體計算公式如下.
(6)
(7)
(8)
(9)
其中,Eq∈Rm×2u;Ea∈Rn×2u.
3.4 層級信息融合
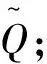
(10)
(11)
其中,Kq∈Rm×8u;Ka∈Rn×8u.
CNN和LSTM經常被用于特征融合層,LSTM通過計算每個隱藏向量的上下文感知權重來捕捉句子的全局序列信息,但是LSTM的串行工作機制使得模型運行的時間較長.而CNN可以并行快速計算,并且CNN捕捉特征能力比LSTM要強,同時多窗口的CNN也在一定程度上彌補了其處理長序列信息能力較弱的缺點.綜合上述原因,本文采用多層的CNN來提取融合特征.具體計算公式如下.
u=CNN(Fuse)
(12)
其中,Fuse表示融合向量Kq或者融合向量Ka.
本文將CNN的輸出u通過最大池化和平均池化得到Sq,max,Sa,max,Sq,mean和Sa,mean,然后將其拼接成一個向量S,送入多層感知器中(MLP)得到最后的預測向量Score∈RN.本文選用Listwise方法來建模答案排序任務,具體計算公式如下.
G=softmax(Score)
(13)
(14)
其中,G表示得分向量;Y表示目標標簽歸一化后的標簽向量;N表示Listwise的大小.本文使用KL散度作為模型的損失函數,該函數可以使得預測值的概率分布接近于標簽值的概率分布.損失函數公式具體如下.
(15)
4 實驗說明
4.1 實驗設置
4.1.1 數據集 本文采用兩個答案選擇領域的基準數據集進行實驗,數據集具體信息見表1.
WikiQA數據集[1]:WikiQA數據集是由微軟雷德蒙研究院在2015年發布,主要針對英文領域的答案句子選擇任務.該數據集包括3 047個問題,每個問題從微軟必應搜索引擎的查詢日志中采樣獲得,并保證該問題以疑問詞開頭、以問號結尾、并且點擊過至少一個維基百科頁面.數據集中將能夠回答該問題的句子標注為1,將其他句子標注為0.
TREC-QA數據集[15]:TREC-QA數據集是從TREC問答網站收集的基準數據集.數據集包含一組事實型問題,其中候選答案僅限于一句話.
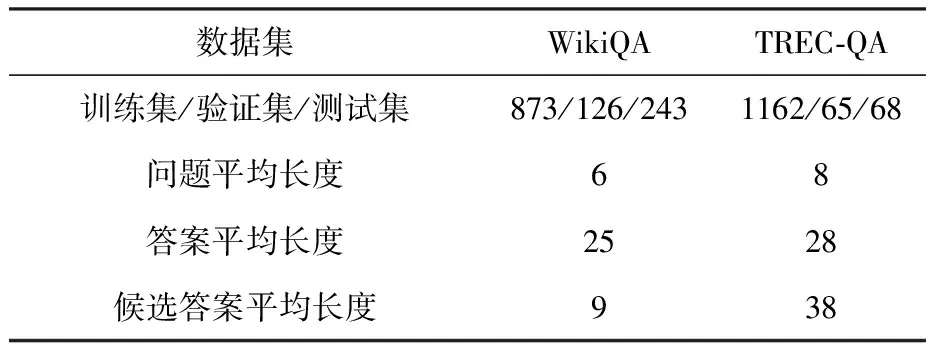
表1 問答數據集描述
4.1.2 實驗參數設置集 本文實驗算法基于Tensorflow 框架實現,BIWN模型采用300 d的Glove詞向量[16]作為詞嵌入;采用mini-batch的訓練方式訓練模型,采用用Padding的方式處理數據集,問題句子的padding長度設置為25,答案句子的padding長度設置為140;訓練采用Listwise的數據格式,列表尺寸設置為15,CNN的窗口尺寸設置為[1,2,3,5].采用學習率衰減的方式訓練模型,初始學習率設置為0.001,采用Adam優化器來進行梯度下降,為了避免模型過擬合,采用L2正則化來優化模型.
4.1.3 本文對比算法 (1) APLSTM[17]:該模型利用交互注意力獲取問題和答案的交互信息;(2)MP-CNN[18]:該模型在CNN的基礎上利用全連接層融合問題和答案的表示;(3) PWIM[19]:該模型將問題和答案的進行顯式交互以計算問題和答案之間的重要部分;(4) BiMPM[20]:Wang于2017年提出的多尺度匹配模型,該模型將問題和答案進行詞級,句子級的多尺度匹配,取得不錯的效果;(5) MAN[12]:Nam于2018年提出的迭代匹配模型,該模型用順序注意力機制將問題與答案進行多步匹配,最后將各個部分的分數相加進行預測.
4.2 實驗結果與實驗分析
4.2.1 基線模型對比 答案選擇任務文檔檢索(IR)任務相似,因此本文采用IR領域的評價指標MAP(平均準確率),MRR(平均倒排準確率)來評估模型性能.實驗結果如表2所示.
如表2所示,在WikiQA數據集上,BIWN模型的MAP值和MRR相比于其他模型分別提高了0.7%~5.9%和0.7%~6.1%.BIWN模型與APLSTM模型均使用了詞級矩陣結構,但是BIWN模型的效果卻遠遠好于APLSTM,原因在于BIWN模型在問題和答案進行交互前利用自注意力機制消除了噪聲詞.BIWN模型與MAN模型都采用了逐步學習的方式進行句對匹配,然而BIWN模型的指標優于MAN模型,表明BIWN模型中的詞級矩陣可以捕獲更細粒度的語義信息.在TREC-QA數據集上,BIWN模型的指標優于大部分基線模型,并且與MAN模型比較接近,原因在于TREC-QA數據集相比于WikiQA數據集更加規整,因此噪聲詞對模型的影響相對而言沒有那么大,而本文針對噪聲詞提出的BIWN模型則不能發揮其最大的作用.
表2基于WikiQA和TREC-QA數據集的實驗結果對比
Tab.2ComparisonofexperimentalresultsbasedontheWikiQAdatasetandTREC-QAdataset
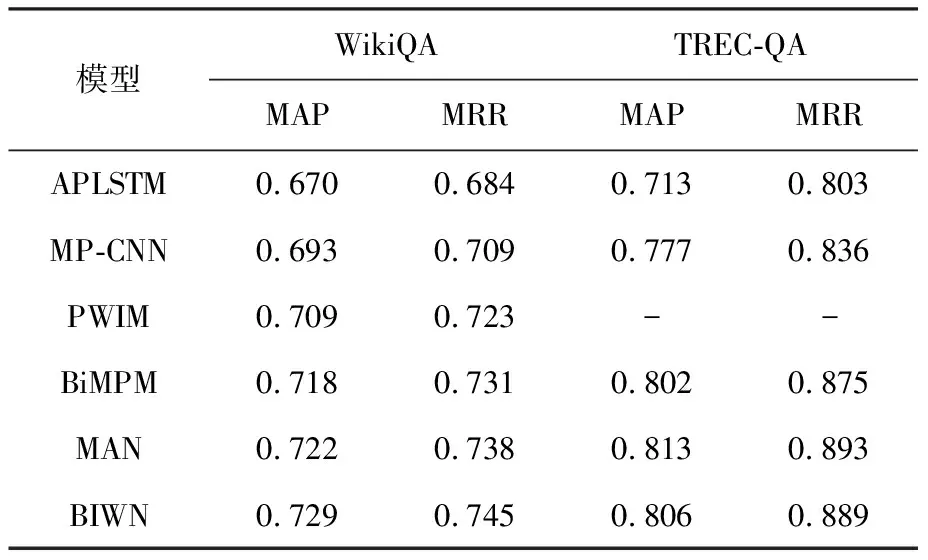
模型WikiQATREC-QAMAPMRRMAPMRRAPLSTM0.6700.6840.7130.803MP-CNN0.6930.7090.7770.836PWIM0.7090.723--BiMPM0.7180.7310.8020.875MAN0.7220.7380.8130.893BIWN0.7290.7450.8060.889
4.2.2 詞級矩陣對比 為了探究不同詞級矩陣對BIWN模型的影響,本文在不改變模型其他結構和模型參數的情況下進行對比實驗,實驗結果如表3所示.
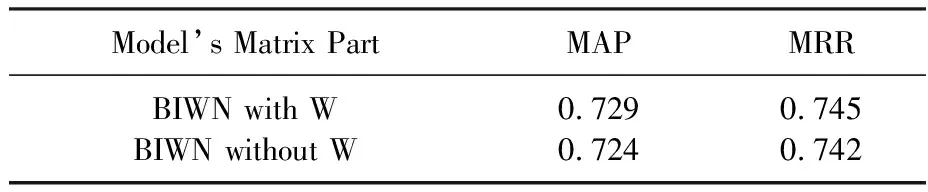
表3 詞級矩陣實驗對比
如表3所示,兩種詞級矩陣的效果沒有太大的差別,但是使用參數W的相似度詞級矩陣的效果要比兩個向量直接相乘要好.本文對此進行分析得出原因:答案選擇任務并不是完全意義上的句對匹配任務,相似的詞在語義表示上有可能是不同的,但是可訓練的參數W可以轉換信息,將其映射到另一個相似的空間,因此效果更好.
4.2.3 消融實驗對比 為了驗證模型中各個部件的有效性,分別移除特定模塊構建下列消融模型:(1) BIWN-Encoder表示去除Bi-LSTM編碼層;(2) BIWN-SelfAtten表示去除自注意力層;(3) BIWN-CNN表示去除詞級相似度矩陣;(4) BIWN-WordMatrix分表示去除CNN特征融合層的消融模型.圖3展示在WikiQA和TREC-QA的實驗結果,可以看出BIWN模型的每個模塊都具有有效性,其中自注意力機制和詞級矩陣相對其中結構影響最大.
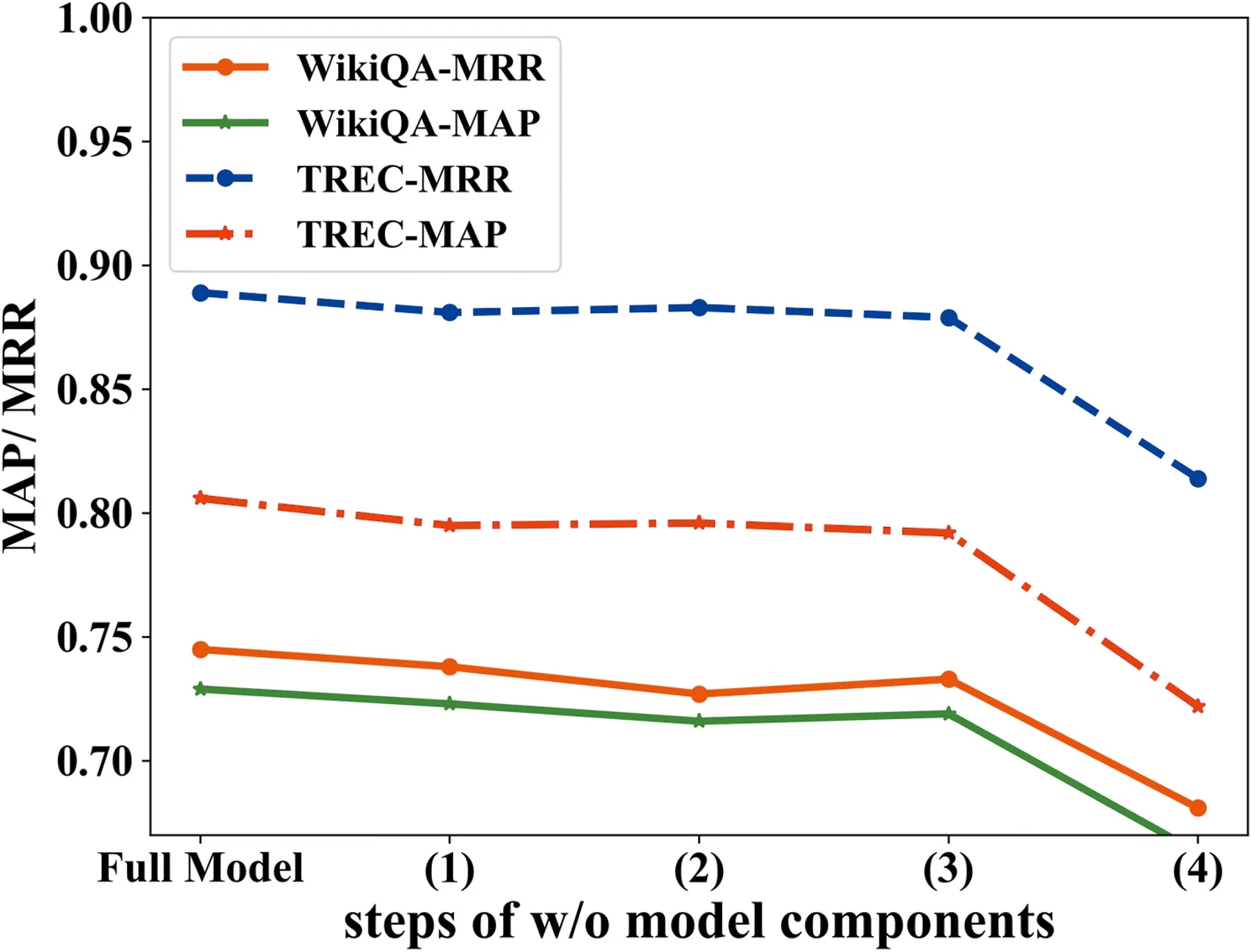
圖3 基于WikiQA和TREC-QA測試集的模型消融分析折線圖Fig.3 Ablation analysis about different components of model on WikiQA and TREC-QA test set
5 結 論
本文針對句子中的噪聲詞,提出了基于問題重要性表示網絡的答案選擇算法.該模型利用自注意力機制重新賦予各個詞不同的權重從而生成“干凈”的問題句子向量;利用詞級交互矩陣捕捉問題句子和答案句子之間的細粒度語義信息,緩解了答案句子中噪聲詞的影響.基準數據集上的對比實驗表明,BIWN模型在答案選擇任務的性能優于目前主流的答案選擇算法.在未來的工作中,會將外部的知識加入BIWN模型中;同時,沒有標簽的數據相對與有標簽的數據更容易獲得,將會把無監督學習應用到答案選擇任務中.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
