基于GeoHash與聚類的共享單車動態回收點設置方法研究
2020-01-16 09:55:44張志清李亞偉ZHANGZhiqingLIYaweiDONGJing
物流科技 2019年12期
關鍵詞:區域
張志清,李亞偉,董 靜 ZHANG Zhiqing,LI Yawei,DONG Jing
(1.武漢科技大學 恒大管理學院,湖北 武漢 430065;2.武漢科技大學 服務科學與工程研究中心,湖北 武漢 430065)
近年來,隨著共享單車投入數量的逐年增多,也產生了大量損壞車輛,如果不能及時處理,在造成資源浪費的同時也會導致一定的經濟損失,因此,如何獲取損壞車輛的相關信息并進行及時處理,是相關企業良好運營的關鍵所在。對共享單車而言,由于其創新型無樁停放特性導致車輛停放位置是無序和分散的,因此,共享單車的故障車輛更難回收處理。有學者從多個視角對共享單車的運營進行了研究,主要集中在單車投放站點的選址[1]、單車系統的調度與優化策略[2-4]、停車點最佳投放量決策模型[5]等,但對如何高效處理故障單車方面的研究相對較少,因此本文提出動態回收點概念,在對騎行數據進行分析處理的基礎上,采用GeoHash與聚類方法對共享單車動態回收點設置方法,為共享單車的管理提供了新的思路,具有一定的理論和實際意義。
1 共享單車騎行數據處理分析
1.1 原始數據處理
本研究中的樣本數據取自2017摩拜杯算法挑戰賽,共包含3 214 096條出行記錄。由于原始數據經過GeoHash算法編碼,所以需要對數據進行解碼處理。根據GeoHash算法的編碼規則,設計解碼算法流程如圖1所示。
用Java語言編寫程序實現GeoHash解碼算法,經檢驗,算法運行效果良好,可以實現上述GeoHash解碼算法,解碼后的部分數據如表1所示。

表1 解碼后部分數據表

圖1 GeoHash編碼的解碼算法流程圖
1.2 空間分布特征分析
根據GeoHash解碼算法得到的經緯度數據,生成各個共享單車的空間分布數據,利用ArcGIS軟件形成.shp格式的點文件;然后通過ArcGIS漁網生成工具箱,生成北京市200*200米的網格數據形成.shp格式的面文件,將共享單車的O(Origin) 點、D(Destination)點空間位置數據聚合到網格中,將網格上的O點、D點數據通過核密度熱力圖的形式進行展示,圖2為北京市摩拜單車2017年5月10日至2017年5月24日騎行數據的O、D點熱力圖。
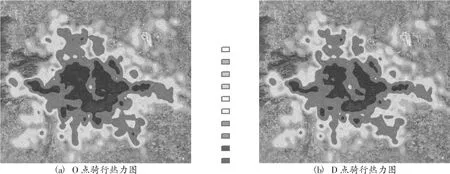
圖2 摩拜單車騎行熱力圖
圖中熱力強度等級由無色、綠色系、黃色系、橙色、深紅、黑色表示并依次增強。為了更加直觀、細致的了解各地區、站點共享單車的使用強度,在熱力圖分析的基礎上,通過對騎行區域進行網格劃分來量化顯示單車使用強度,其中每個網格設定為800*800米。以D點騎行數據為例,在ArcGIS軟件中計算每個網格區域的日平均騎行量,如圖3所示。

圖3 摩拜單車D點日均騎行量圖示

圖4 北京局部地區摩拜單車日均騎行量顯示圖
在有單車使用數據的區域,最低日平均騎行量為0.66667次,最高日平均騎行量為1 376.333374次,據此劃分了5種顏色所代表的日平均騎行量等級,圓圈內數字表示該區域的日均騎行量。其中綠色圓點表示該區域單車日均使用200次以內;藍色表示該區域單車日均使用200~400次;黃色表示該區域單車日均使用400~600次;粉色表示該區域單車日均使用600~800次;紅色表示該區域單車日均使用800~1 376.333374次。取局部區域進行共享單車空間分布點更加細致的分析。局部日均騎行量如圖4所示。
圖4中三個紅色圓點所在區域為北京大紅門服裝商貿城到百榮世貿商城的一片商貿區域和東鐵營村這一集中住宅區,并且這三處均離地鐵站點較近;并且由圖4可知,圖中紅、粉、黃三色所代表的最高強度單車使用區域有其共同特征,這些區域多在地鐵站點周邊,且所在區域多為辦公樓、商場、娛樂場所、住宅區,這些區域均有較多且穩定的騎行需求。
綜上所述,通過對騎行終點數據的空間分布分析,可以基本了解到北京摩拜單車的使用情況,包括單車使用的熱點區域分布特征以及各地區日均使用量數據,可為后續的逆向物流網絡規劃提供參考依據。
1.3 單車回收點聚類分析
本文利用北京摩拜的騎行終點數據,通過K-means聚類分析形成一定范圍的騎行終點區域作為回收需求區域,并將回收需求區域中的聚類中心點作為回收點,便于后續逆向物流網絡構建。K-means算法是基于無監督學習提出的聚類算法,算法描述如下:
輸入:訓練樣本V={v1,v2,v3,…,vn};k:聚類個數;
輸出:C={c1,c2,c3,…,ck}。
步驟1:在數據集中隨機挑選k個對象作為初始聚類中心c1,c2,c3,…,ck。
步驟2:計算數據集中每個對象到聚類中心的位置,選取最小距離分配到聚類中,其中V={v1,v2,v3,…,vn};j=1,2,3,…,k。
步驟3:將每個聚類中的所有對象的均值作為新的聚類中心,如式(1)所示:

nj為第j類中對象的個數,j=1,2,3,…,k。
步驟4:當各個簇的聚類中心不在發生變化,聚類準則函數如式(2)所示:

收斂,則算法結束,到步驟5;否則返回步驟2繼續迭代。
步驟5:輸出聚類結果。
K-means算法優點是可以處理大數據集,并且聚類速度較快,有較好的拓展性,K-means算法是相對可伸縮的和高效率的,因為它的計算復雜度為O(nkt),其中n為對象個數,k為聚類個數,t為迭代次數,通常有t≤n,k≤n,因此它的復雜度通常也用O(n)表示。
本文取經緯度坐標點(116.345771,39.981975)和(116.400532,39.955543)作為該矩形區域對角線上兩點,在樣本騎行數據中截取出D點在此范圍內的數據,共獲得70 480條騎行數據,該區域面積約為4.5km*2km。在此區域根據騎行數據建立D點熱力圖,如圖5所示。
利用Matlab進行編程實現K-means聚類算法,并在Intel Core i5-5600U CPU@2.50GHz處理器PC上運行,設置算法參數,利用基本的K-means算法進行求解,運行4min得到聚類結果。經檢驗,該聚類算法具有很強的可操作性,結果可用于后續規劃模型。計算過程中,基本的K-means算法的誤差平方和的收斂圖如圖6所示。

圖5 聚類區域D點熱力圖

圖6 K-means算法誤差平方和的收斂圖
可以看到:聚類的誤差平方和在12個聚類點之后趨于穩定,說明算法收斂。并且在選擇算法k值時也可參考聚類區域熱力圖輔助分析,結合聚類區域熱力強度高的區域個數作為現實參考因素合理配置k值。本文結合熱力圖分析和上述收斂圖結果,選取12個聚類點。算法得到的聚類中心的經緯度坐標如表2所示。
在ArcGIS軟件中將上述聚類點顯示于聚類區域熱力圖上,如圖7所示。

表2 K-means算法聚類點坐標

圖7 聚類點結合熱力圖綜合顯示圖
圖中黑色棋子即為聚類中心點所在位置,可以看出,聚類中心整體分布情況與共享單車騎行熱力圖中的熱點區域吻合度較高,比較符合共享單車運營的實際情況,證明該方法的有效性。
2 結論
在考慮騎行分布特征和現實回收狀況的前提下,對共享單車回收處理的逆向物流網絡規劃方法進行了研究, 基于GeoHash算法對原始數據進行解碼處理, 在此基礎上,對騎行大數據進行空間分布特征分析, 然后通過聚類分析方法,對所取研究范圍內的騎行數據進行聚類分析,得到回收服務區的回收點分布及每個回收點的位置信息。在分析共享單車騎行空間分布特征的基礎上,提出了利用K-means聚類對共享單車回收點進行聚類分析的方法。該方法可以有效地計算騎行需求區域,即為單車回收需求區域,并將聚類點作為單車回收點。這一關鍵步驟為后續的共享單車回收逆向物流路徑規劃研究奠定了堅實的基礎。
猜你喜歡
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經大學學報(2015年3期)2015-12-10 03:49:15
