數據挖掘:C5.0決策樹算法在警察院校學生體質分析中的應用
2020-03-02 02:09:08宋兆銘董如軍
四川體育科學 2020年1期
宋兆銘,葉 菁,董如軍
數據挖掘:C5.0決策樹算法在警察院校學生體質分析中的應用
宋兆銘1,葉 菁2,董如軍3
1.四川警察學院,四川 瀘州,646000;2.四川化工職業技術學院,四川 瀘州,646000; 3.廣東警官學院,廣東 廣州,510230。
C5.0決策樹算法適用于大數據集處理,特別是它的Boosting集成機器學習算法可以有效地將精度較低的“弱學習算法”提升為精度較高的“強學習算法”,從而達到模型修剪與優化的目的。研究結果表明:C5.0決策樹算法生成的模型可以精確地評價學生的體質健康狀況(97.8%)且模型預測的泛化能力較強(98.1%)。因此,C5.0決策樹算法可以用來判斷影響警察院校學生體質測試成績的關鍵因素,為深層挖掘相關警務數據內涵與監測提供了實證依據。
C5.0決策樹;警察院校;學生體質
我國警察院校的學生體質監測工作自1985年始已經進行了30多年,建立了體量巨大的體質信息數據庫。面對海量的數據,如何探尋簡便有效的分析方法對體質狀況精確、快速、直觀地給出反饋,一直是對警務培訓研究者的重大考驗。當前對警察院校學生體質數據的分析,主要還是使用一般性的現狀描述和傳統的相關性檢驗的統計分析方法,缺乏深層次的數據挖掘研究和決策分析,更無法發現測試數據中隱含著的重要結論[1]。因此,利用好耗費大量人力、財力采集的學生體質測試數據,深層挖掘數據的內涵,得出更多更精確的結論來為監測工作服務,是每一位警務培訓研究者的重要任務。同時,如何根據簡單測量指標判斷體質狀況也是目前警務培訓數據分析中的一個重要課題。值得慶幸得是,決策分析技術的出現使得這一課題有了重大的突破,基于決策分析的方法,可以根據身高、體重等一些簡單的體質指標快速判斷學生體質的關鍵影響因素。
丁亞芝等[1]以新疆師范大學學生體質測試數據為例,引入趨勢選擇的概念,將TESTSPRINT算法應用于體質測試數據分析中,該研究結合了先進的數據挖掘算法,提高了精確性,在一定程度上達到了監測學生體質的目的。但同時,TESTSPRINT算法也存在以下一些缺點,導致該方法在大量數據分析和數值型數據分析中的效果還有待提高:(1)使用屬性列表,使存儲代價是原來的三倍;(2)節點分割要創建哈希表,加大系統負擔;(3)節點分割處理相對復雜。于岱峰等[2]以人體握力肌肉力量測試數據研究為例,將ID3算法應用于人體肌肉力量數據分析中,為選擇人體握力Gain(K3)指標作為評價人體握力肌肉力量指標,提供了科學依據。但同時,雖然ID3算法具有理論清晰,方法簡單,學習能力較強等優點,但它只對比較小的數據集有效,且對噪聲比較敏感,當訓練數據集加大時,決策樹可能會隨之改變。李偉平[3]等采用K-Means快速聚類法、序列關聯規則、貝葉斯網絡、QUEST決策樹、C&R決策樹、CHAD決策樹、支持向量機(SVM)和神經網絡等數據挖掘技術,對西安市城鎮居民體育消費入戶調查數據進行了實證分析。同時,通過對這幾個模型評估效果的比對,李偉平等認為C5.0模型的解釋性、正確率為最高。
因此,本研究在總結前人算法引進不足之處的基礎上,提出引入在執行效率和內存使用方面進行了改進的C5.0算法,并以S警察學院學生體質監測數據為分析對象,定量分析我國警察院校學生體質健康水平的關鍵影響因素。旨在引起上級主管部門對學生體質健康水平的重視,為以學校為基礎的干預措施提供科學依據,為我國警察院校體育課程的改革提供實證參考。
1 C5.0算法
1.1 算法簡介
C5.0是決策樹模型中的經典算法[5]。決策樹模型是一個預測模型,它表示對象屬性和對象值之間的一種映射,樹中的每一個節點表示對象屬性的判斷條件,其分支表示符合節點條件的對象,樹的葉子節點表示對象所屬的預測結果。決策樹模型的建立通常包括特征選擇、決策樹的生成和修剪3個步驟[4-8]。
J R Quinlan于1979年提出了ID3算法,主要針對離散型屬性數據,其后又不斷的改進形成C4.5,它在ID3基礎上增加了對連續屬性的離散化[7-8]。為了適應處理大規模數據集的需要,后來又提出了若干改進的算法,其中SLIQ(super-vised learning in quest)[3]和SPRINT (Scalable Parallelizable Induction of Decision Trees)[1,9]是比較有代表性的兩個算法。C5.0算法則是C4.5算法的修訂版,適用于處理大數據集,同時它增加了強大的Boosting算法提高了分類精度[10]。Boosting算法依次建立一系列決策樹,后建立的決策樹重點考慮以前被錯分、漏分的數據,最后生成更準確的決策樹且計算速度比較快,占用的內存資源較少。Boosting算法作為一種新的集成機器學習方法,以學習理論為依據,可以有效地將精度較低的“弱學習算法”提升為精度較高的“強學習算法”,從而達到模型修剪與優化的目的[11-12]。
1.2 基本概念
C5.0決策樹的生長過程采用的是最大信息增益率的原則進行節點選擇和分裂點的選擇,具體涉及的基本概念有:
信息熵:信息雜亂程度,信息越雜亂(越不純),則信息熵越大;反之,信息熵越小[4-5]。其公式為:
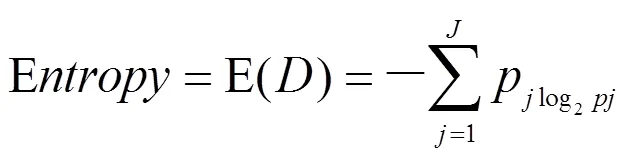
其中-log2(pj)反應的是信息量,即某隨機事件發生的概率越小,則信息量越大;反之概率越大,則信息量越小。所以信息熵就是指事件發生的概率(pj)乘以其對應的信息量(-log2(pj)),然后再加總。
信息增益(Info Gain):分裂前的節點熵減去分裂后子節點熵的加權和,即不純度的減少量,也就是純度的增加量。其中,參數選擇的規則是選擇使信息增益最大的參數分割該節點[4-5]。其公式為:

其中,Info為Y變量的信息熵,InfoA為自變量A對Y變量分割的信息熵。其公式為:
由于信息增益選擇偏向于取值多的屬性(參數的取值越多,其分割后的子節點純度可能越高)。C5.0采用了信息增益率的方法,對那些水平比較少的離散變量進行平衡處理[4-5]。其公式為:
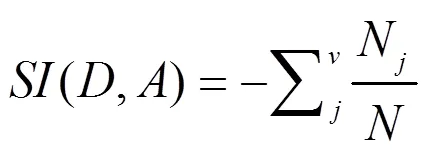
其中,為分割信息(自變量的信息熵);信息增益率就是在信息增值的基礎上除以自變量的信息熵。
1.3 模型建立
C5.0決策樹模型第一次拆分確定的樣本子集隨后再次拆分,通常是根據另一個字段進行拆分,這一過程重復進行直到樣本子集不能在被拆分為止。最后,關注最低層次的拆分,那些對模型值沒有顯著貢獻的樣本子集被提出或者修剪。主要分為以下四個步驟[4-5]:
第1步,對數據進行預處理,將連續型的屬性變量進行離散化處理形成決策樹的訓練集(分類屬性忽略)。
第2步,計算每個屬性的信息增益和信息增益率。
第3步,根節點屬性每一個可能的取值對應一個子集,對樣本子集遞歸地執行第二步過程,直到劃分的每個子集中的觀測數據在分類屬性上取值都相同,生成決策樹。
第4步,根據構造的決策樹提取分類規則,對新的數據集進行分類。
具體計算過程如下:
(4)類別的信息熵:
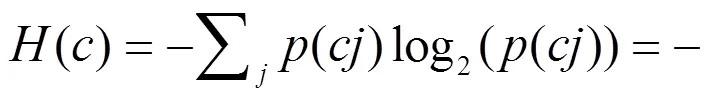
(5)類別的條件熵:
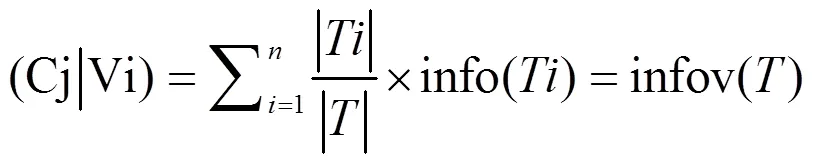
(6)信息增益(Gain):
(7)屬性V的信息熵:
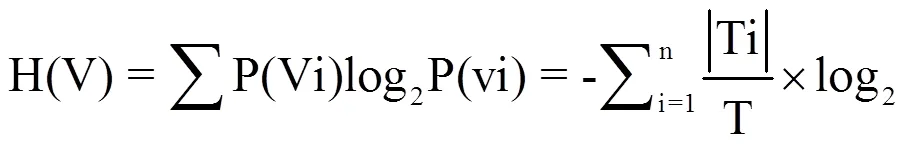
(8)信息增益率:
gain_ratio=I(c,v)/H(V)=gain(V)/split_info(V)
最后,通過比較各個屬性的信息增益率即可確定決策樹的節點,重復以上過程,最終得出屬性分類的決策樹。
2 實例分析
2.1 數據來源
按照《國家學生體質健康標準》[13]的規定,對四川警察學院所有在校大學生進行了體質監測測試,測試過程嚴格按照測試的操作方法要求完成。測試以年級為單位分別安排在2018年12月每周日(4、11、18、25)上午8:30-11:30、下午14: 30-17:30 兩個時間段。測試人員均為經培訓后的四川警察學院警體教師,現場測試技術規范并有巡視組監督檢查,測試質量符合規定要求。數據匯總后按性別分為兩類樣本,有效樣本量見表1。

表1 研究對象基本信息一覽表
2.2 分析變量
按照《國家學生體質健康標準》[11]的規定測試的指標,本研究分析變量主要分為身體形態、機能、素質指標,BMI指數,具體賦值與說明見表2。

表2 變量選擇與賦值
注:由于男女生測試項目不同,所以分別建模分析。
2.3 統計分析
采用Excel2010進行數據的錄入與整理。數據分析采用R3.4.2完成,決策樹建立應用“C50”軟件包及相關函數完成。
(1)導入數據集,連續變量離散化代碼命令和運行結果如圖1:
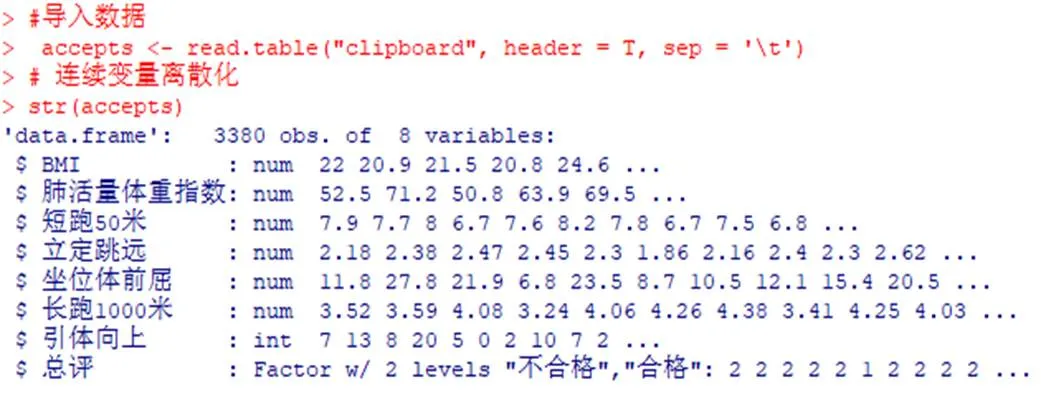
圖1 數據導入、變量離散化代碼運行結果圖
(2)隨機抽樣,將數據分為訓練集和測試集。運行結果如圖2:

圖2 數據拆分代碼運行結果圖
(3)運行C50算法建模代碼,查看預測的結果,構建混淆矩陣,計算模型的在訓練集預測準確率。運行結果如圖3:

圖3 C50算法建模代碼運行結果圖
圖3表明通過訓練數據測試,模型的預測準確性為97.8%,模型在測試集上有較好的預測效果。
(4)計算模型在測試集預測準確率。運行結果如圖4:

圖4 測試集預測準確率代碼運行結果圖
圖4表明通過測試集數據測試,模型的預測準確性為98.1%,模型有較好的泛化效果。
(5)圖形展示:plot(model)。
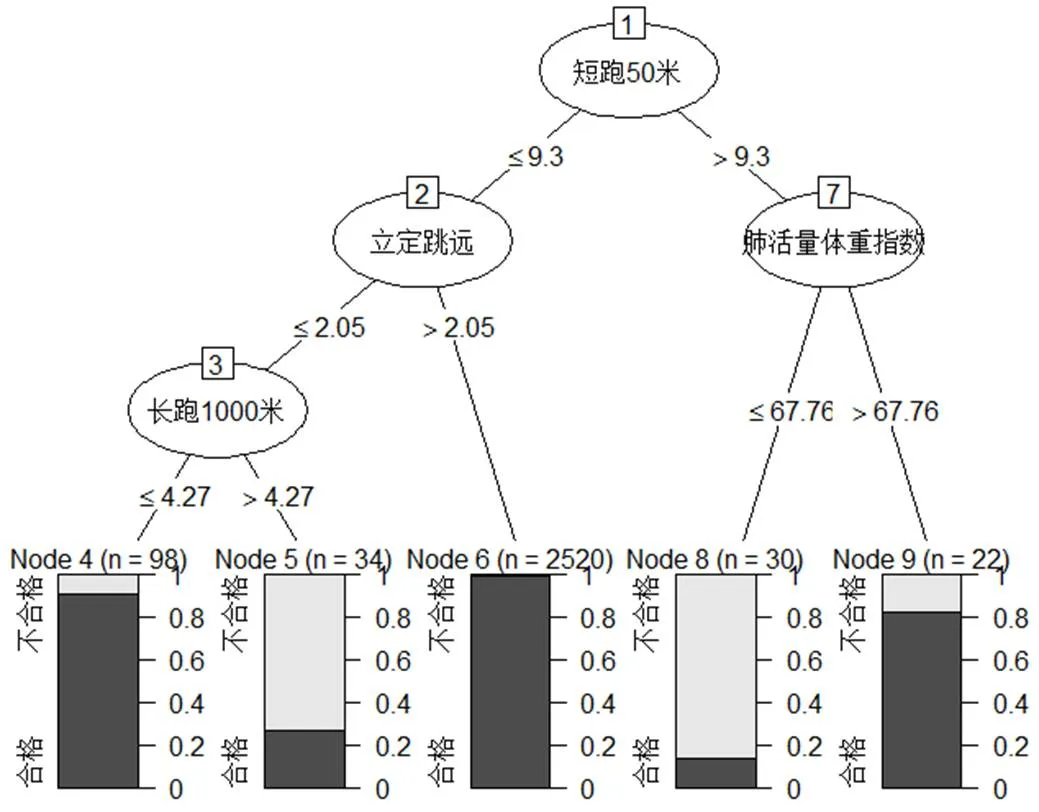
圖5 男生決策樹圖形代碼運行結果圖
從圖5可以出,學生的體質測試成績是否合格的關鍵因素有:“短跑50m”“肺活量體重指數”“立定跳遠”和“長跑1000m”。(1)首先,“短跑50m”這一指標處于樹的根部,即:學生體測成績合格還是不合格,最關鍵的影響因素是學生短跑能力的強弱(節點1);(2)依據學生短跑能力的強弱(9.3s),第二層節點分別是“肺活量體重指數(節點2)”和“立定跳遠(節點7)”。其中,反映學生呼吸系統機能狀況的肺活量體重指數如果大于67.76 ml/kg,則學生的體測成績合格率較高,反之則合格率較低;反映學生下肢力量與爆發力的發展水平的立定跳遠成績如果大于2.05m,那么學生的體測成績合格率較高,反之則應進一步考查長跑1000m的測試成績來判定總評成績是否合格;(3)長跑1000m是反映學生堅持長時間運動的能力,如果長跑1000m成績小于4.27min,則學生的體測成績合格率較高,反之則合格率較低。
綜上所述,如果學生的短距離快速運動的能力強,下肢力量與爆發力的發展水平高,則其體測合格的可能性最高。如果學生的短距離快速運動和堅持長時間快速運動的能力強,則其體測合格的可能性最高為其次。如果學生短距離快速運動的能力較弱,但其呼吸系統機能能力較好,則其體測合格的可能性也相對較高。但如果學生的短距離快速運動的能力較弱、下肢力量與爆發力的發展水平較低、堅持長時間快速運動的能力也較差,則其體測合格的可能性較低;特別是呼吸系統機能能力差的學生其體測合格的可能性為最低。因此,我們應積極進行警察體能課程教學改革,在課程開始前應對學生體質健康水平進行評估,并依據評估結果,在尊重學生個體差異的原則下開展分層教學,使不同層次學生得到有針對性的教法指導,從而有效提升學生的體質健康水平。
3 結論與展望
3.1 主要結論
本文利用C5.0算法對S警察學院學生體質測試成績的影響因素開展了有數據支撐的定量研究,判斷了影響學生體質測試成績的關鍵因素,為深層挖掘學生體質測試數據內涵、監測學生體質提供了實證依據。主要結論有:(1)C5.0算法生成的決策樹模型可以運用簡單的體質監測的指標精確地評價學生的體質健康狀況(98.4%)且模型預測的泛化能較強(98.2%)。(2)學生的體質測試成績是否合格的關鍵影響因素有:“短跑50m”“肺活量體重指數”“立定跳遠”和“長跑1000m”。(3)在警察體能課程教學中,我們要注重發展學生的下肢力量與爆發力、短距離快速運動的能力和長時間快速運動的能力;同時,要特別注重學生呼吸系統機能能力的提高,從而精確有效地提高學生體測的合格率。
3.2 研究展望
我國國民體質監測數據已呈現出不同地理位置上的數據共享,數據庫系統的數據量的增加將導致未來國民體質數據分析必須采用分布式海量數據計算方法。因此,如何借助數據挖掘技術從龐大的數據中識別數據內部的聯系,去偽存真,從中提取有用的信息,為體質監測和相關警務培訓決策提供支持是極具意義的研究課題。同時,由于各種數據挖掘方法各有利弊,其理論和算法本身也正在不斷的擴展和提升之中。所以,要得出更多更精確的結論還需要更多地致力于數據挖掘算法及其在體質數據分析中的應用研究。
[1] 丁亞芝,鄭志高,馬 嶸.改進的SPRINT算法及其在體質數據分析中的應用[J].體育科學,2014,34(06):90~96.
[2] 于岱峰,鐘亞平,于亞光.基于數據挖掘技術在人體肌肉力量數據分析中的應用——以人體握力肌肉力量測試數據研究為例[J].體育科學,2010,30(02):70~74+82.
[3] 李偉平,權德慶,蔡 軍,魏 華,雷 文. 西安市城鎮居民體育消費結構及其特征研究——基于數據挖掘的視角[J]. 體育科學,2013,33(09):22~28.
[4] JiaweiHan, MichelineKamber, JianPei,等. 數據挖掘:概念與技術[M]. 機械工業出版社,2012.:162~171.
[5] PANG-NINGTAN, MICHAELSTEINBACH, VIPINKUMAR. 數據挖掘導論:完整版[M].人民郵電出版社,2011:89~122.
[6] http://127.0.0.1:23641/library/C50/doc/C5.0.html.
[7] Quinlan J R. C4.5: programs for machine learning[M]. Morgan Kaufmann Publishers Inc. 1993.
[8] Max Kuhn, Steve Weston. C50: C5.0 Decision Trees and Rule-Based Models[J]. 2012.
[9] 王云飛. SPRINT分類算法的改進[J]. 科學技術與工程,2008,8(23):6248~6252.
[10] 劉迷迷,劉永佳,溫 麗,蔡 巧,李麗婷,蔡永銘.C 5.0決策樹對早期胃癌風險篩查研究[J].中華腫瘤防治雜志,2018,25(16):1131~1135.
[11] 張 宇,張之明. 一種基于C5.0決策樹的客戶流失預測模型研究[J]. 統計與信息論壇,2015,30(01):89~94.
[12] 楊劍鋒,喬佩蕊,李永梅,王 寧.機器學習分類問題及算法研究綜述[J].統計與決策,2019,35(06):36~40.
[13] http://www.csh.edu.cn/wtzx/bz/20141226/2c909e854a84301a014a8433fc500003.html
Research of Data-mining in Police Training: The Application of C5.0 Decision Tree to Students ' Constitution in Police Colleges
SONG Zhaoming1, YE Jing2, DONG Rujun3
1.Sichuan Police College, Luzhou Sichuan, 646000, China; 2.Sichuan Vocational College of Chemical Technology, Luzhou Sichuan, 646000, China; 3.Guangdong Police College, Guangzhou Guangdong, 510230, China.
The C5.0 Decision Tree can be used for large data sets. Due to the addition of Boosting, The C5.0 Decision Tree can get better models. Booting optimizes the model by effectively improving the less accurate “weak learning algorithm” to a more accurate “strong learning algorithm.”Result: The decision tree model generated by C5.0 algorithm can accurately evaluate students' physical health status (98.4%) with simple physical monitoring indicators and the generalization of model prediction can be strong (98.2%). Conclusion: The C5 .0 algorithm can be used to determine the key factors physical test results, to deeply dig Students ' Constitution data and monitor its changes in Police Colleges.
C5.0 Decision Tree; Students ' Constitution; Police Colleges
G804.49
A
1007―6891(2020)01―0052―04
10.13932/j.cnki.sctykx.2020.01.11
2019-06-17
2019-07-29
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
電力與能源(2017年6期)2017-05-14 06:19:37
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
信息通信技術(2015年6期)2015-12-26 01:16:46
