
基于產生式規則的喬灌木識別推理算法研究
2020-03-11 13:55:54杜雨菲吳保國
計算機工程與應用 2020年5期
杜雨菲,吳保國,陳 棟
北京林業大學 信息學院,北京100083
1 引言
在生態建設日益推進的今天,公眾對樹木的認知有了更為深層的需求,從僅僅知道某樹種的名稱,演變到學習該樹種的相關知識,即從“認樹識樹”,演變為了“認樹識樹知樹”。通常情況下,公眾進行樹種識別主要是通過閱讀掛在樹上的標牌、查閱植物學家編制的樹種檢索表、樹種圖冊等方式。然而,標牌上展示的知識有限,利用植物檢索表識別樹種需要林學專業知識,樹種圖冊攜帶不便,均不適用于普通人群對樹種知識的學習。隨著人工智能技術和圖像處理技術的快速發展,國內外很多研究人員采用機器學習方法構建了植物圖像分類模型[1-5],并以模型為基礎研建了植物識別App,利用拍攝的樹葉、花果等對樹種進行識別[5-7],達到了一定的識別精度。美國的Leafsnap 是世界上首款運用智能識別技術的植物識別App[8],國內比較成熟的有形色App[8]和花伴侶[9],可以根據植物的形態照片對開花的植物進行識別。除此之外,還有研究人員提出了基于交互式檢索采用專家問答的方式進行植物識別的設想[10-11]。然而,由于開花植物的花形特征較為顯著,喬灌木較少開花且枝葉特征較為細微,基于圖像處理和機器學習技術構建的植物識別App多用于開花植物的識別,較少用于喬灌木識別;由于機器學習算法的準確率與樣品選取量的問題,對開花植物的識別率不高,對喬灌木植物的識別率更不容樂觀,容易對使用者造成誤導;植物識別App 沒有顯示植物識別的過程,使用戶喪失了進一步探究植物相關知識以及獲得辨識能力的機會;采用專家系統的方法可以彌補上述不足,但現有的植物識別專家系統還停留在設想和設計階段。鑒于喬灌木識別專家系統的匱乏,以北京喬灌木枝葉檢索表[12]中的專家知識為例,對專家知識進行提取整理,利用枝葉特征圖片對每條規則進行直觀解釋,建立了喬灌木識別知識庫,設計了喬灌木識別推理算法,研建了北京市喬灌木識別專家系統,實現了對北京市喬灌木樹種的有效識別,使公眾可以在生活中感受豐富的樹種知識,為森林生態建設服務。
2 專家知識構成及表示
2.1 樹木學專家識別樹種的知識構成
樹木學專家通過樹木的樹皮、枝、葉、花、果等部位來識別樹木的科、屬、種、名。經過長期的知識積累,樹木學專家編制了樹種檢索表[13]。為了方便識別北京市的喬灌木樹種,劉一樵[12]編制了《北京市喬灌木枝葉檢索表》,根據枝葉形狀分為針形(條形、鉆形或鱗形)、復葉、單葉對生、單葉互生(葉全緣)、單葉互生(葉有鋸齒或裂片)5類,分別編制檢索表。該檢索表中的知識包含了詳細的枝葉特征文字描述,根據不同的葉形特點,枝葉檢索知識又細分為5 種:針形、條形、鉆形或鱗形;復葉;單葉對生;單葉互生、全緣;單葉互生、有鋸齒或裂片。樹種知識包含了樹種的名稱、拉丁名、造林技術、圖片等信息。
本研究的樹種識別方式以北京市喬灌木枝葉檢索表作為參照,表1 為該枝葉檢索表進行檢索的示例:首先在首編號為1的枝葉特征中,確定該樹種的枝葉特征符合“葉針形,條形”,尾編號為2;繼續查詢首編號與尾編號相同的枝葉特征,即在首編號為2 的枝葉特征中,確定該樹種的枝葉特征符合“葉針形,單生或2~5 枚束生”,尾編號為3;繼續查詢首編號為3的枝葉特征,確定該樹種的枝葉特征符合“葉單生,在長枝上螺旋狀著生,在短枝上簇生”,該條件對應的尾編號為“雪松”,至此,完成了樹種的檢索與識別。

表1 枝葉檢索表示例
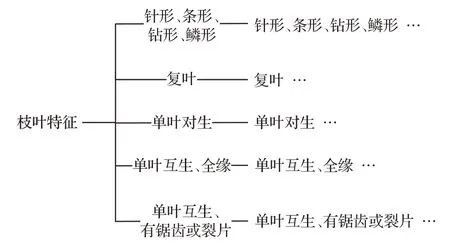
圖1 規則推理樹
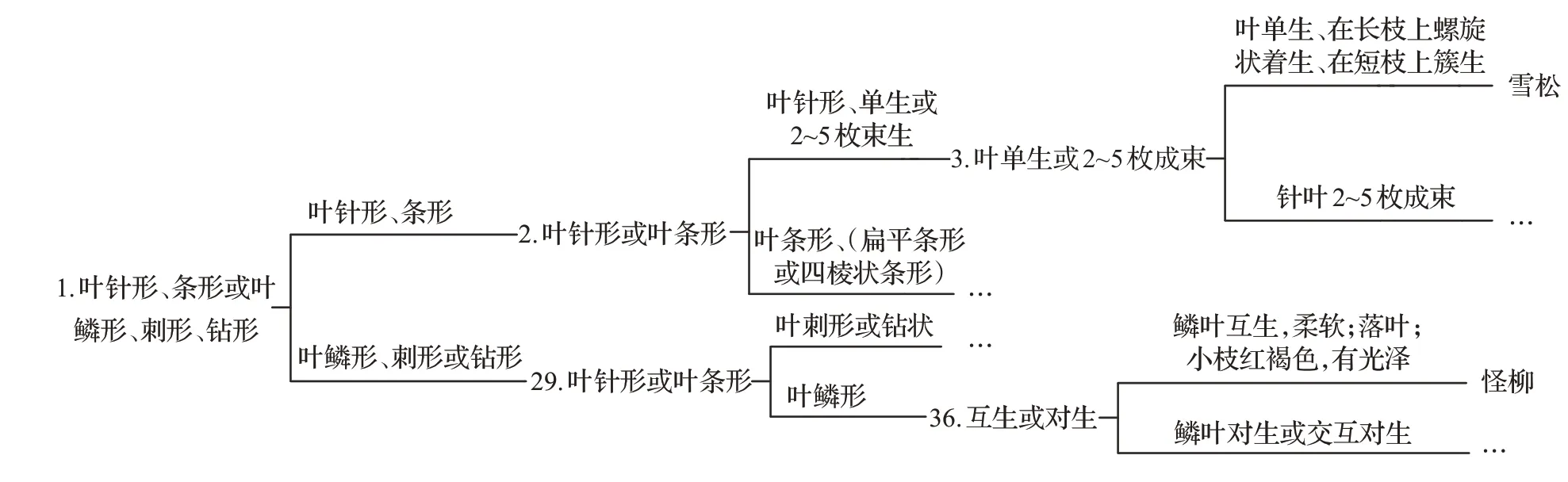
圖2 二級規則推理樹
本文研究了上述檢索方式的知識結構,構建了枝葉檢索知識的規則推理樹(圖1),每類枝葉特征均對應一個二級規則推理樹。圖2是以“針葉、條形、鉆形、鱗形”為例的二級規則推理樹示例,在樹的每一個節點都要判斷下一步應該走哪一條路徑,每一個分支路徑都擁有一個枝葉特征值,通過選擇枝葉特征的值來決定下一個節點,在下一個節點再重復上述過程,就可以最終找到所需要的節點。存在不同規則推理路徑最終節點為同一樹種的情況,這種冗余路徑增強了樹種檢索與識別的效果。
2.2 專家知識表示
專家知識表示方法通常有6種:一階謂詞表示法[14]、產生式規則表示法[15]、框架表示法[16]、語義網絡表示法[17]、劇本[18]以及本體論[19]。產生式規則表示法適合表示因果關系的知識,能夠清晰明確地表示知識之間的規則,表示形式與人類求解問題時的邏輯思維相似,易于理解,已經多次被應用在專家系統的構建中[20-22]。因此,本研究采取產生式規則表示法對枝葉檢索知識進行表示,例如雪松的檢索規則可以表達為:IF 葉針形,條形and 葉針形,單生或2~5枚束生and 葉單生,在長枝上螺旋狀著生,在短枝上簇生THEN 雪松。
為了方便在計算機中進行規則的存儲和調用,在推理規則樹的基礎上,構建了枝葉檢索知識規則推理樹的鏈式雙親表示模型,如圖3所示。每個節點都有頭指針和尾指針,父節點的尾指針指向子節點的頭指針,檢索過程由指針進行鏈接完成。在一級模型中,枝葉特征導航節點是頭節點,其頭指針為空,尾指針為T0,據此鏈接到頭指針為T0的節點,再根據“T1、T2、T3、T4、T5”這5 種尾指針,鏈接到對應的枝葉特征種類二級模型中。圖4 是枝葉檢索知識規則推理樹的鏈式雙親表示二級模型的示例,尾指針為0 的節點沒有子節點。例如,父節點“針形、條形、鉆形、鱗形”的頭指針為空,尾指針為1,子節點“葉針形、條形”的頭指針與其父節點相同,尾指針為2。諸如此類,直到檢索到尾指針為“0”的節點結束樹種識別過程。
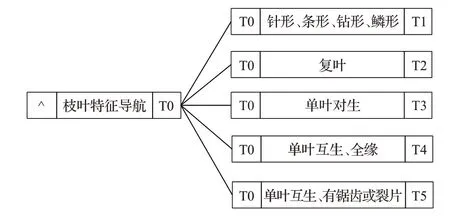
圖3 枝葉檢索知識規則推理樹的鏈式雙親表示

圖4 二級鏈式雙親表示
3 知識庫與推理算法設計
3.1 知識庫設計
根據樹種識別專家知識的表示,本研究設計了6個關系,分別是:存儲枝葉特征分類規則的導航表,存儲針形、復葉、單葉對生、單葉對生、單葉互生喬灌木樹種識別推理規則表。各個表之間的關系如圖5所示。
通過導航表,根據枝葉特征分類推理規則來從5種不同類型的喬灌木樹種識別推理規則表(表名分別為T1、T2、T3、T4、T5)中選擇推理規則表進行知識搜索,定位到所要識別的樹種;然后通過造林樹種表(表名為Trees)獲取該樹種對應的樹種知識,幫助用戶深入了解所識別樹種的知識。
導航表包含規則表序號、枝葉描述、表名和枝葉描述圖片名稱屬性,通過枝葉描述和枝葉描述圖片定位到喬灌木樹種識別推理規則表T1~T5種中的1種推理規則表。5種喬灌木樹種識別推理規則表結構相同,包含了首節點,尾節點,枝葉描述,枝葉描述圖片名稱,樹種編號屬性,通過識別推理規則對樹種進行識別,得到滿足規則的樹種編號,通過造林樹種表得到該樹種的知識。
導航表T0的關系模式如下:
T0(規則表序號,枝葉描述,表名,枝葉描述圖片名稱)
每類推理規則表的序號和表名均存儲在推理規則導航表的“規則表序號”“表名”字段中;推理規則導航表的“枝葉描述”字段存儲對推理規則表進行分類的枝葉特征,這是導航的基本依據。
針形、條形、鉆形或鱗形葉喬灌木樹種識別推理規則表T1、復葉喬灌木樹種識別推理規則表T2、單葉對生喬灌木樹種識別推理規則表T3、單葉互生全緣葉喬灌木樹種識別推理規則表T4、單葉互生有鋸齒或裂片葉喬灌木樹種識別推理規則表T5的關系模式相同,表Ti(i=1,2,…,5)的關系模式如下:
Ti(首節點,尾節點,枝葉描述,枝葉描述圖片名稱,樹種編號)
造林樹種表中存儲造林樹種知識,關系模式如下:
Trees(樹種編號,樹種學名,樹種別名,樹種拉丁名,樹種描述,樹種分布,樹種描述圖片名稱,造林技術,……)
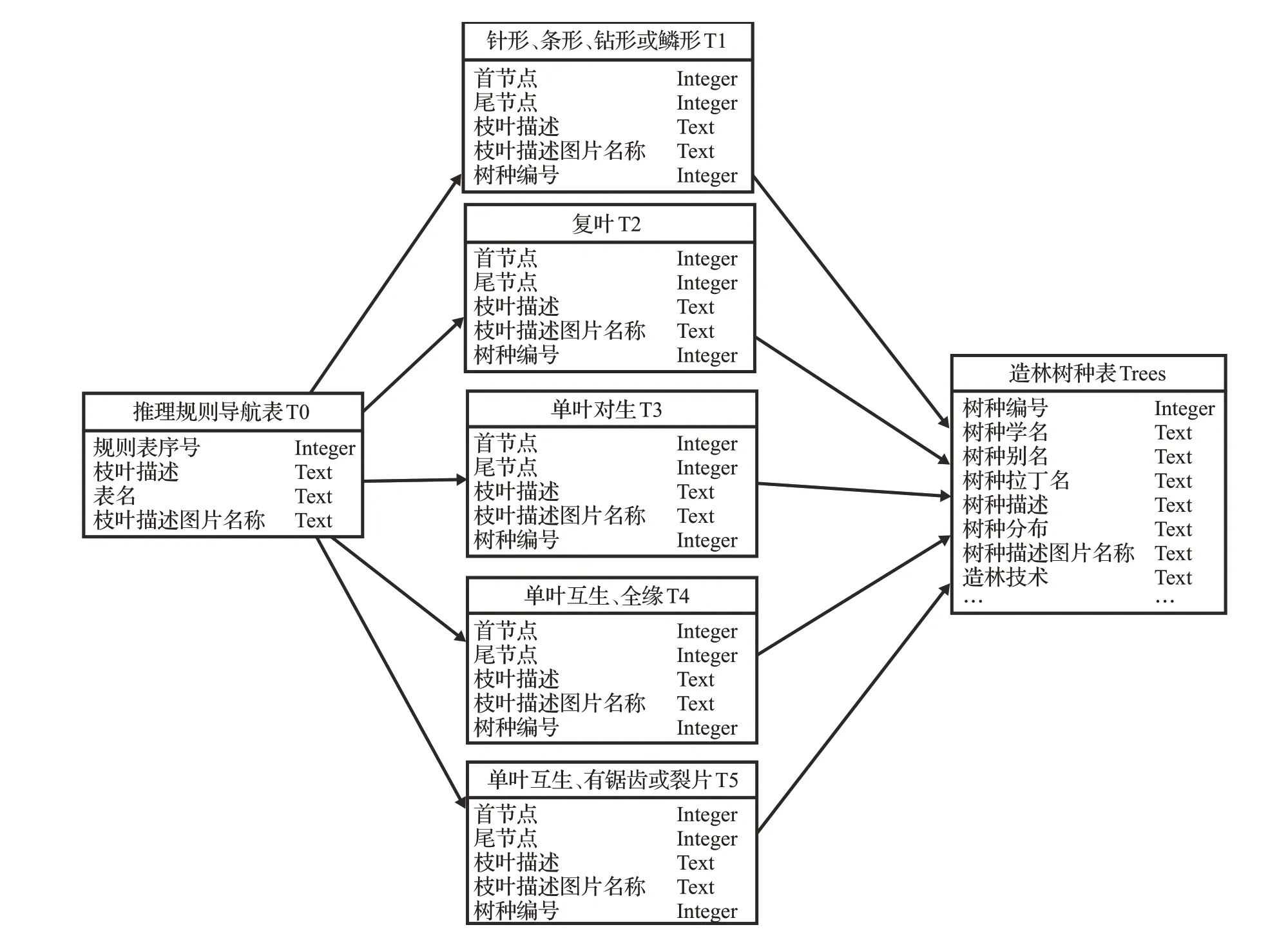
圖5 表之間的關系
本研究中每類喬灌木樹種識別推理規則的實現關鍵在于“首節點”和“尾節點”。“首節點”和“尾節點”共同標識一條推理規則,因此,采用“首節點”和“尾節點”作為每類推理規則表的聯合主鍵。在樹種的識別過程中,需要通過查找“首節點”與上一規則的“尾節點”相同的規則,每個“首節點”“尾節點”都是大于等于0 的整數。當“尾節點”的值為0 時,代表該條規則已經結束,樹種識別完成,立即讀取該記錄的樹種編號,到造林樹種表中查詢其樹種名稱、樹種、樹種拉丁名、樹種描述、樹種分布等信息。“枝葉描述”是用戶進行枝葉特征選擇的基礎,“樹種編號”字段存儲了規則結束對應的樹種編號,是與造林樹種表進行連接的外鍵。由于用戶缺乏相關專業知識,難以對文本描述的枝葉特征進行理解和判斷,因此,使用圖片對推理規則涉及的所有枝葉特征進行直觀展示,輔助用戶進行枝葉特征的理解和判斷。“枝葉描述圖片名稱”字段中以“img/表名/圖名”的形式存儲對應枝葉特征圖片的路徑和名稱,通過路徑和名稱獲取枝葉描述圖片。由于“首節點”和“尾節點”是每類推理規則表的聯合主鍵,因此,圖片均以“圖-首節點-尾節點”的形式進行命名,可以唯一標識每類推理規則下的圖片。
由于表T1~T5 的關系模式相同,這里只給出表T1的實例(表2),T2~T5的實例不再贅述。

表2 推理規則表T1實例
3.2 推理算法設計
推理機制的選擇需要與知識表示方式相匹配[20-21]。根據推理過程進行的方向,可以將推理機制分為3 種:正向推理、反向推理和雙向推理[22]。正向推理機制是數據驅動推理,推理基礎是邏輯演繹的推理鏈,與產生式規則表示法表示的知識結構吻合。因此,根據產生式規則表示法的特點,選擇正向推理機制。本研究的推理算法設計主要包括枝葉特征讀取、喬灌木識別兩部分,具體推理算法如下:
步驟1 根據推理規則導航表T0中所有推理規則表對應的枝葉描述、枝葉描述圖片,選定其中一類推理規則表。
步驟2 查詢選定的推理規則表Ti(i=1,2,…,5)中所有首節點為1的枝葉特征記錄,根據其對應的枝葉描述、枝葉描述圖片,選擇與事實一致的枝葉特征。
步驟3 獲取選擇的枝葉特征對應的尾節點,判斷該尾節點是否為0,不為0進行步驟4,若為0轉向步驟5。
步驟4 在推理規則表Ti 中查詢所有首節點與步驟3中尾節點相同的枝葉特征記錄,根據其對應的枝葉描述、枝葉描述圖片,選擇與事實一致的枝葉特征,轉向步驟3。
步驟5 獲取該枝葉特征對應的樹種編號,查詢造林樹種表Trees中對應的樹種信息并進行展示。
步驟6 推理結束。
根據喬灌木識別的推理算法,考慮數據庫存儲和編程特點和計算機的可操作性,設計了整個系統的推理數據流程,如圖6所示。
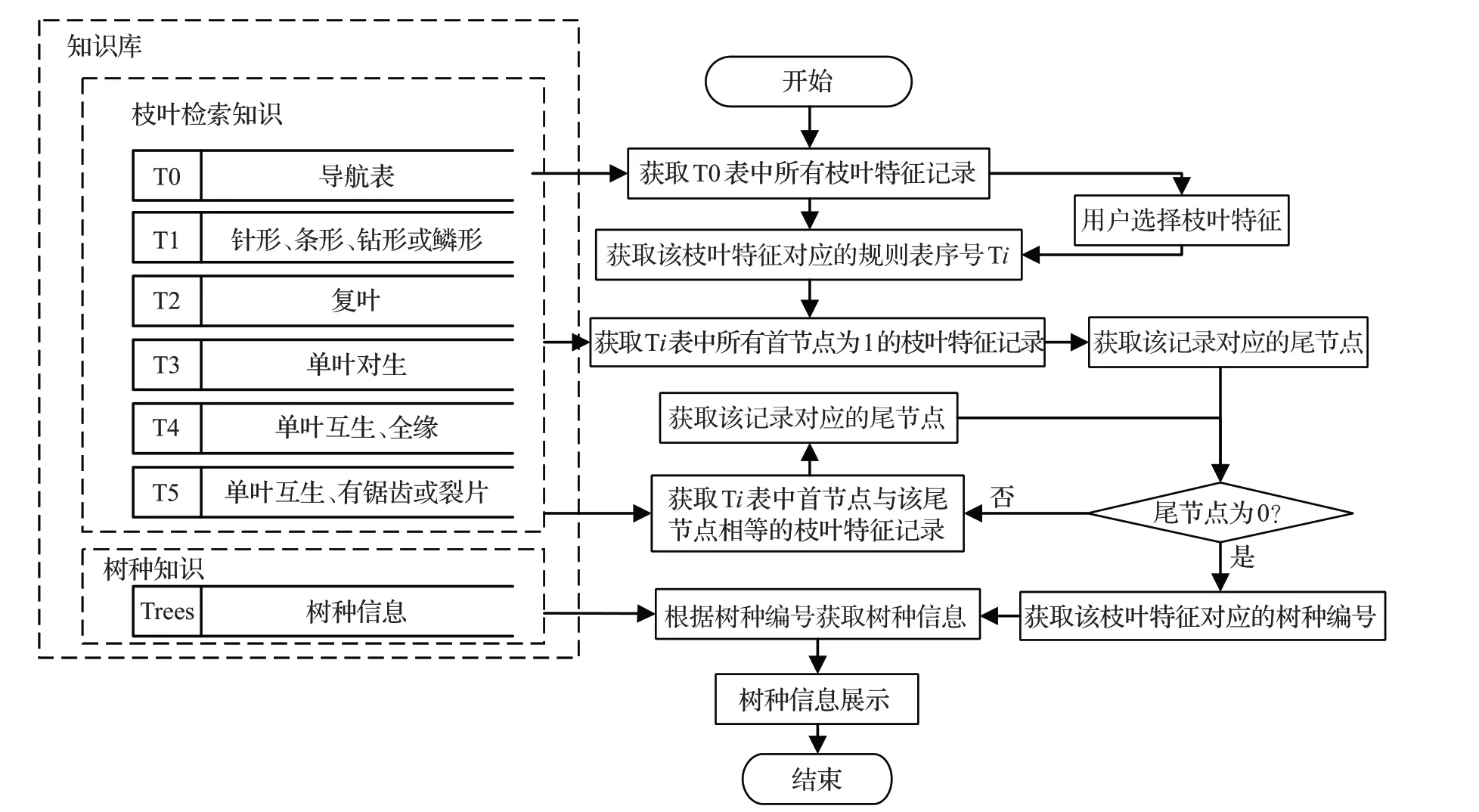
圖6 喬灌木識別推理流程圖

圖7 總體框架設計圖
4 系統設計與實現
4.1 系統體系結構與功能結構設計
北京市喬灌木識別專家系統的總體框架設計如圖7所示。用戶可以通過網絡訪問到系統界面,對系統進行操作,系統通過訪問枝葉檢索知識、樹種知識庫,調取相應的知識和規則,對用戶的行為做出響應,輸出結果。北京市喬灌木識別專家系統的功能結構如圖8所示,該系統主要包括以下3個功能模塊:
(1)樹種識別功能包括交互式枝葉特征提問,識別步驟退回、樹種信息展示。其中識別步驟退回功能在頁面中實時顯示用戶選擇枝葉特征的路徑,用戶不僅能根據路徑進行植物識別知識的學習,還能判斷已經選擇的枝葉特征是否有誤,如果有誤,可以返回上一步驟進行重新選擇。樹種信息展示功能是在樹種識別結束后,通過被識別出的樹種編號查詢樹種知識庫,將該樹種的信息、圖片展示在頁面中。
(2)樹種組合條件查詢可以根據喬灌木的樹種編號、樹種學名、樹種別名、樹種描述、樹種分布、造林技術等條件進行組合查詢,從樹種知識庫中查詢滿足條件所有樹種,用戶選擇后瀏覽該樹種的相關信息。
(3)知識庫維護功能包括知識查詢、知識增加、知識更新、知識刪除,分別實現對枝葉檢索知識庫、樹種知識庫中的知識進行查詢、增加、更新和刪除,達到維護知識庫的效果。
本系統以Java 為開發語言,采用了Spring MVC(Model,View,Control)框架,使將系統分為了3個層次:數據持久層、業務邏輯層和表現層。數據持久層:使用SQL Server 作為系統的數據庫,使用Hibernate 框架對數據庫操作進行封裝;業務邏輯層:基于Spring框架,實現了用戶知識查詢的接口;表現層:使用Ajax、JQuery技術與接口進行數據的交互,實現系統的異步刷新,減少頁面刷新次數,使基本功能由瀏覽器分流,用戶友好性較強。
4.2 核心功能實現
北京市喬灌木識別專家系統核心功能的實現主要依靠2個關鍵算法:喬灌木識別算法、退回算法。
(1)喬灌木識別算法的實現
本算法包括3 部分:枝葉特征知識的讀取、樹種知識的讀取、枝葉(樹種)描述與圖片的展示。依據圖6設計的喬灌木識別推理數據流程圖,具體的算法流程圖如圖9 所示。根據Spring MVC 架構的層次,代碼的編寫分為數據持久層、業務邏輯層和表現層,關鍵代碼如下所示:
數據持久層:
String hql="from T1 where node=?";
List
String hql="from Trees where treeNode=?";
List
業務邏輯層:
if("T1".equals(type)){
List
list=selectTreeService.findSelectT1(node);
returnWithJSONArray(response,list);
……
}else if("T5".equals(type)){
List
selectTreeService.findSelectT5(node);
returnWithJSONArray(response,list);}
表現層:
$.ajax({
type:'POST',
async:false,
url:"../../selectTree/selectTreeTextDetail",
dataType:"json",
data:{type:type,node:node},
cache:false,
success:function(data){ result=data;}});
If(node != 0){
var result=_this.stepData(type,node);
_this.detailStepShow(result,stepCount);
}else{
var result=_this.findData(type,node);
var endResult =
_this.endData(result.treeNode);
this.endStepShow(endResult,stepCount);}
(2)退回算法的實現
若只進行了一次枝葉特征問答,退回上一步需要從T0 表中查詢所有記錄;在已經進行了至少兩次枝葉特征問答的情況下,通過節點的查找與鏈接,退回上一步。具體算法為:從存儲已經選擇的枝葉特征記錄的數組中獲取最后一條記錄的首節點,利用該首節點在該子表中查詢出首節點相同的所有枝葉特征記錄,具體的算法流程如圖10所示。由于本算法是在讀取枝葉特征記錄算法的基礎上,增加了部分算法邏輯,因此代碼的編寫主要在表現層,關鍵代碼如下所示:
表現層:
if(node=="1"){ //從T0表查詢所有記錄
type = T0;
node= T0;
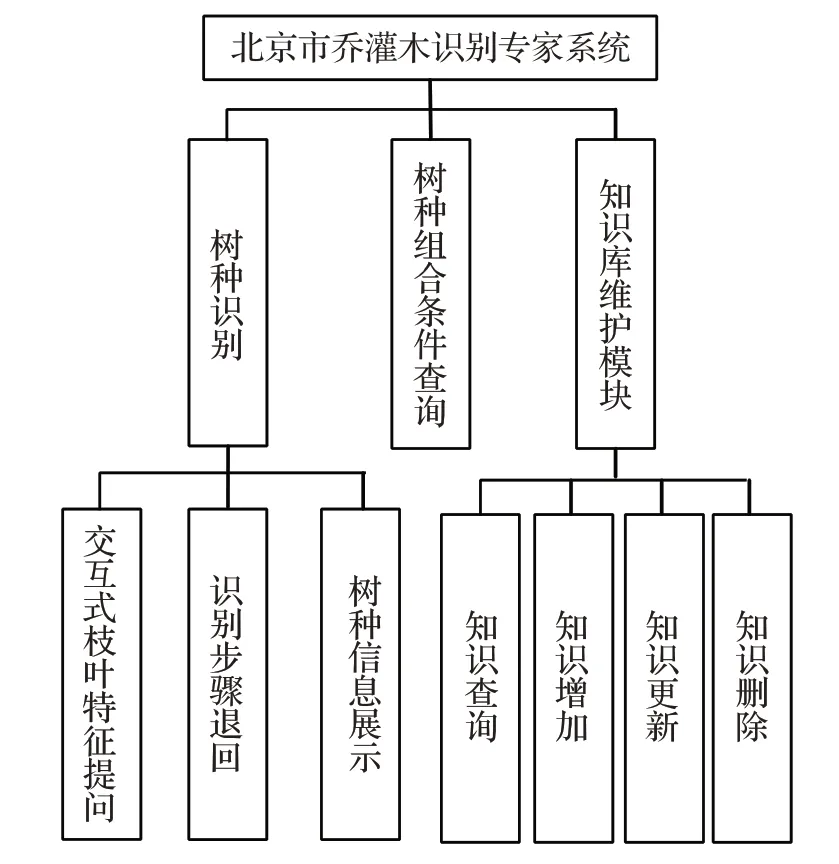
圖8 功能結構圖
var result=_this.stepData(type,node);
_this.detailStepShow(result,stepCount);
}else{
var endResult=_this.stepData1
(type,stepRecordArray[stepCount?1]);
var node=endResult.node;
stepRecordArray.length=stepRecordArray.length?1;
var result=_this.stepData(type,node);
_this.detailStepShow(result,stepCount);}
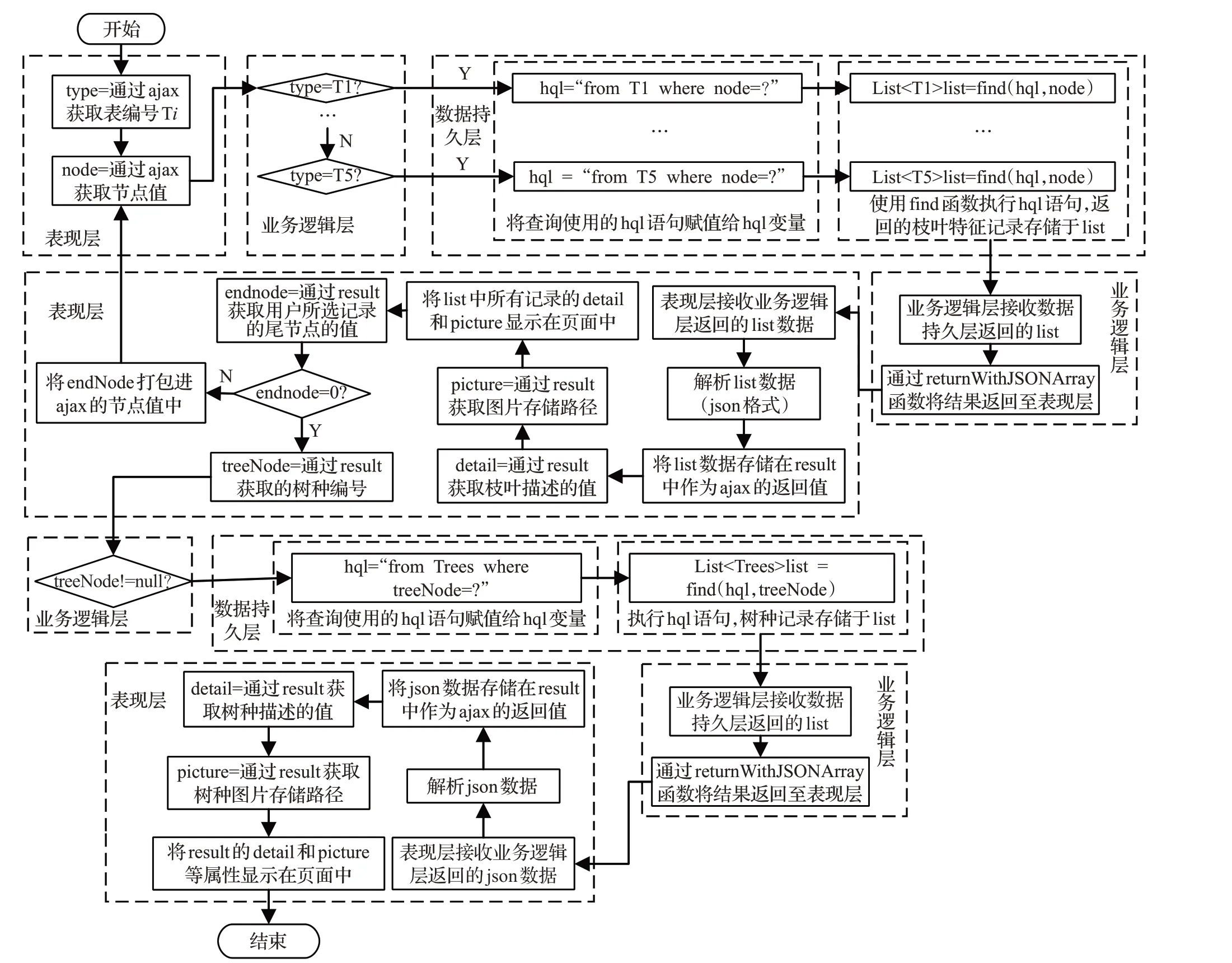
圖9 樹種識別算法實現流程圖
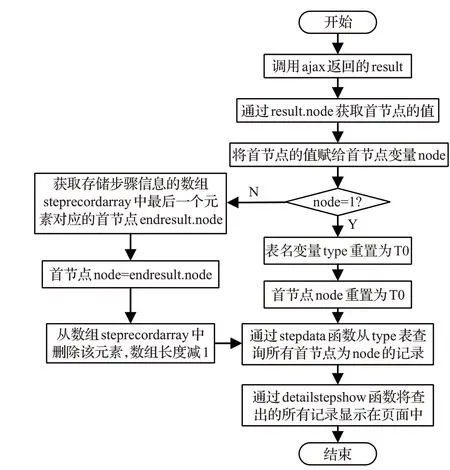
圖10 退回算法實現流程圖
4.3 運行實例
北京市喬灌木識別專家系統主要提供了根據枝葉特征來識別北京市喬灌木樹種的服務,識別過程中為避免用戶專業知識儲備不足會造成枝葉特征選擇疑惑的情況,采集了每個枝葉特征所對應的圖片進行輔助選擇。頁面上方顯示在該樹種識別的過程中枝葉特征的選擇路徑,方便用戶進行系統的知識學習;下方為枝葉特征單選框,選定某種枝葉特征后,頁面右方會有相應的枝葉特征圖片展示。以雪松為例,樹種識別的過程和最終結果分別如圖11和圖12所示。
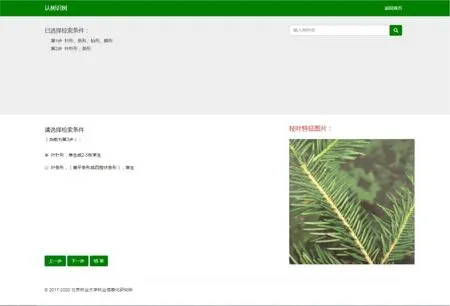
圖11 樹種識別過程
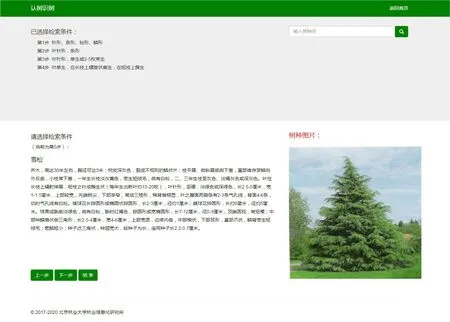
圖12 樹種識別結果
系統運行環境要求操作系統為64 位的Windows Server 2008 或更新的操作系統,WWW 服務器為Tomcat 7。硬件要求內存為16 GB,硬盤空間大于等于100 GB,處理器為Intel?Xeon?CPU E5-2620 v2 @2.10 GHz。使用JMeter開源測試工具,模擬多用戶并發訪問系統,對系統的性能進行評估。測試結果如圖13所示,虛擬并發用戶數為1 000時,系統平均響應時間約為20 ms,運行情況良好,能夠有效地為公眾提供樹種識別服務。
5 結束語
針對目前喬灌木識別方式存在的問題,以北京市喬灌木識別專家知識為例,分析了樹木學專家識別樹種的知識構成,根據枝葉檢索表整理提取了枝葉檢索知識的邏輯結構,設計了枝葉檢索知識的規則推理樹,基于產生式規則表示法對枝葉檢索知識進行了表達。
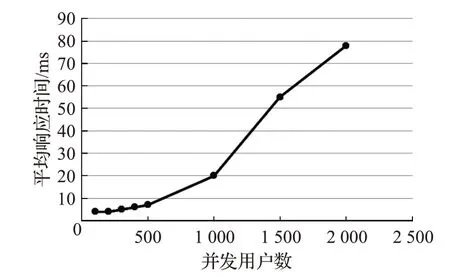
圖13 系統平均響應時間測試結果
為了方便將規則在計算機中進行存儲,采用樹的鏈式雙親表示法構建了推理規則的數據結構。基于該數據結構,完成了知識庫的設計,構建了一種可以使用關系型數據庫存儲規則性知識的關系表結構,采用首節點、尾節點實現規則的存儲和推理。
與傳統的推理規則不同的是,本研究采用圖片對每條規則進行直觀解釋,避免用戶在進行樹種識別的過程中出現困惑,指引用戶進行正確的選擇。
采用正向推理方式,詳細分析與設計了喬灌木識別推理算法。在此基礎上,構建了北京市喬灌木枝葉識別專家系統,設計并實現了2 個核心功能的算法,使該系統能實現樹種的準確識別。目前,北京市喬灌木枝葉識別專家系統已經應用在“森林培育與經營全過程專家輔助決策支持系統”項目中,運行效果良好。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
