
結合詞相關性特征的《紅樓夢》作者辨析
2020-03-14 23:26:06陳藹瑞?吳士軍?展浩宇
人物畫報 2020年29期
關鍵詞:特征
陳藹瑞?吳士軍?展浩宇






摘 要:自《紅樓夢》成書以來存有多種版本,對其作者的辨析也在不斷地進行,其本質是一個分類問題。本文以120回程高版本的《紅樓夢》的每個回合作為樣本,在人物頻數、虛詞頻數為樣本特征的基礎上,提出了一種用詞和詞之間的相關性差異作為不同作者寫作差異性度量,并用word2vec詞向量方法來計算詞與詞之間的相關性作為特征,對比了線性模型和非線性模型下,采用SVM分類器對樣本進行訓練和判別,實驗數據表明,結合詞相關性特征后,采用高斯核的非線性SVM,得出前80回和后40回存在顯著差異,從而可以合理地假設是兩位不同的作者。
關鍵詞:詞相關性;頻數;特征;詞向量;支持向量機
一、引言
《紅樓夢》是我國的明清四大名著之一,具有極高的藝術成就。自《紅樓夢》成書以來,一直有學者對其內容不斷進行研究探討。但因為歷史上流傳不便等原因,現存的《紅樓夢》具有多個版本,其作者也存在較大爭議。目前較為公認的120回版本是指前80回由曹雪芹所創,后四十回由高鶚續寫的版本。
在過去,大多數對《紅樓夢》作者討論的工作都是基于文學上感性的認識或者歷史上文獻文物的考證進行的。一些作者嘗試采用多元統計分析和機器學習的方法探討《紅樓夢》作者。瑞典漢學家高本漢最早使用統計方法研究《紅樓夢》,根據32中語法、詞匯現象的統計結果得出前80回和后40回為同一作者的結論。李賢平、成大康、施建軍等人的工作,都是以每回中文言虛詞的頻數作為訓練樣本的特征,結合方差分析、回歸分析、SVM分類器、K近鄰等方法進行分析,基本假設是每個作者使用虛詞的習慣是不同的。采用文言虛詞的頻數作為學習模型中樣本空間的特征值稱為辨析《紅樓夢》作者相關研究的主流。
這種特征選擇方法在一定程度上是有效地,但也存在一些問題:首先,虛詞頻數的差異程度多大能夠判決是不同的作者難以定義。其次這種特征選擇拋棄了語言成分如詞、語句的結構特性,事實上這種語言結構上的差異信息更能區分著者的不同寫作習慣和風格。
本文從統計的角度出發,選擇人物出場頻數、虛詞頻數等多個特征,并且引入詞向量分析提取詞和詞之間的關聯程度作為特征選擇,采用SVM分類器對120回程高版《紅樓夢》的作者進行了分析。
本文假設《紅樓夢》作者的分析問題可視為機器學習中經典的二類分類問題,整本《紅樓夢》可視為含有120個樣本點的樣本集。
我們在實驗中分別試驗了線性近似可分SVM和非線性SVM的分類性能;尤其通過使用非線性SVM模型,取得了高置信度的分類結果,證明了在不同的回目上曹雪芹、高鶚兩位作者存在“可分的”差異。
二、基于統計分析的文本分類方法
1.模型
令D={x1,x2,…,xm}表示具有m個樣本(sample)的數據集(data set),每個樣本xi=(xi1; xi2; …;xid)X是d維樣本空間中的一個向量,xi1是xi在第i個特征(feature)的取值,d為樣本xi的維數(dimensionality)。標有類標號(label)的樣本成為樣例(example),(xi,yi)表示第i個樣例。
文本分類的基本流程如圖1所示:
2.詞向量
在文本分類中,詞向量是用來表示詞的特征向量,One-hot表示方法將每個詞表示為只有一個維度取值為1、其余維度取值都為0的d維向量,d也是詞表的大小。在深度學習中,采用一種低維的實值向量表示詞向量。利用詞向量之間定義的各種度量,可以表示詞語之間的相似性程度。詞向量可以通過基于神經網絡語言模型經過訓練而產生,目標函數可以采用對數似然函數:
三、基于人物出場頻數、虛詞頻數和詞向量的作者辨析
我們按照題意分別采取了幾種不同的提取《紅樓夢》語料中詞語特征的方法。通過組合這些詞的特征,我們構建了《紅樓夢》每一回目的文本特征。我們將前40回文本樣本作為正例、81~100回文本樣本為反例,用以訓練SVM模型,41~80回文本樣本、101~120回文本樣本作為測試樣本,最終輸出分類結果,以判別《紅樓夢》前80回與后40回是否是同一作者。
下面我們按照題目順序介紹幾種特征提取的方法。
1.統計120回中每一回目主要人物名稱出現的頻數
首先我們將程高版《紅樓夢》的txt文檔按照120回目分開,儲存為一個csv格式的文件,然后我們用python的pandas框架讀取這個文件,并用python的jieba框架對文本進行了分詞。在去掉中文的停用詞之后,我們用python的nltk框架的FreqDist模塊統計了分詞后每個回目每個詞的頻數。
由于紅樓夢的出場人物眾多,造成了統計120回中每一回目主要人物名稱出現的頻數的以下3個困難:
a.人物眾多,有名有姓者就有732人;
b.許多人物往往只在120回中出現了一次,造成了樣本的稀疏性。
c.對于文本分詞產生的指代性人稱代詞、別名、小名無法處理。
針對問題b,我們采用主成分分析PCA(Principal Component Analysis)進行降維,計算出主要人物。最終選取了15個人物每一回目的出場次數,作為每一回的文本特征,如圖2所示:
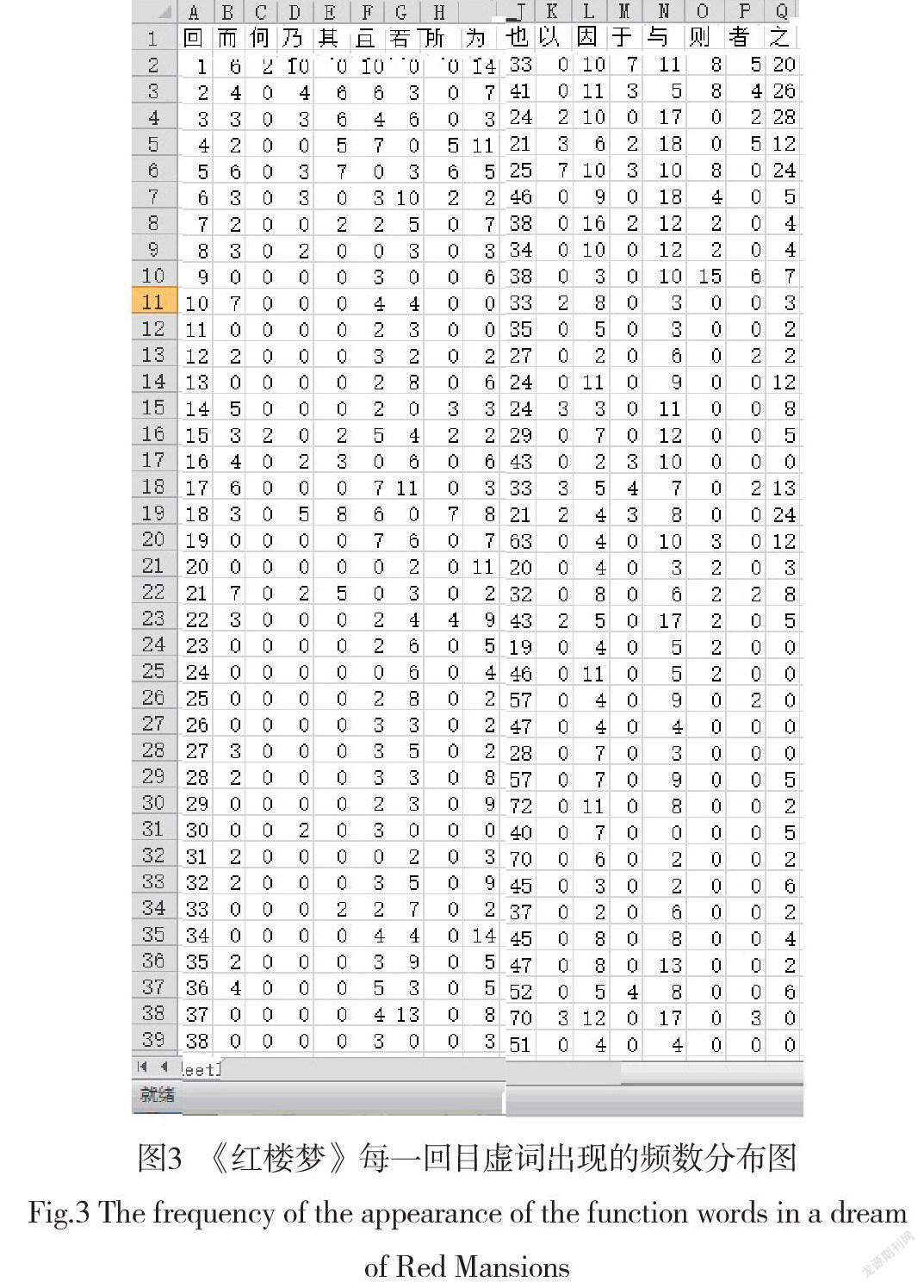
2. 統計120回中每一回目常見文言虛詞的頻數
處理思路和方法與統計人物出場次數相同,但統計虛詞作為文本特征相比于統計人物出場次數有兩個優勢。規定的文言虛詞數量只有18個。除去2個120回都沒有出現過的虛詞外,其余的16個虛詞出現頻數都相對正常。
我們完整地統計了每一回目16個虛詞出現的頻數,如圖3所示。
3.基于詞與詞之間相關性的特征提取
我們采用了一種word2vec的詞向量方法來計算詞與詞之間的相關性。為了節約篇幅,我忽略了對自然語言處理從詞的one-hot向量的特征形式到詞向量的特征形式發展的介紹,簡單來說可將one-hot視作對字典中的詞一種非常稀疏的編碼形式,且無法計算出詞與詞的相關性;詞向量則是將某個詞與上下文n個詞之間的相關性用馬爾科夫決策過程計算,用計算的數值來作為這個詞的特征。而word2vec算法主要功能就是通過簡單的單隱層神經網絡來訓練出表示詞和詞之間相關性的詞向量。
word2vec算法的輸入是one-hot向量,隱藏層沒有非線性激活函數,也就是線性的單元。輸出層維度跟輸入層的維度一樣,用的是softmax回歸。我們要獲取的詞向量其實就是隱藏層的輸出單元。
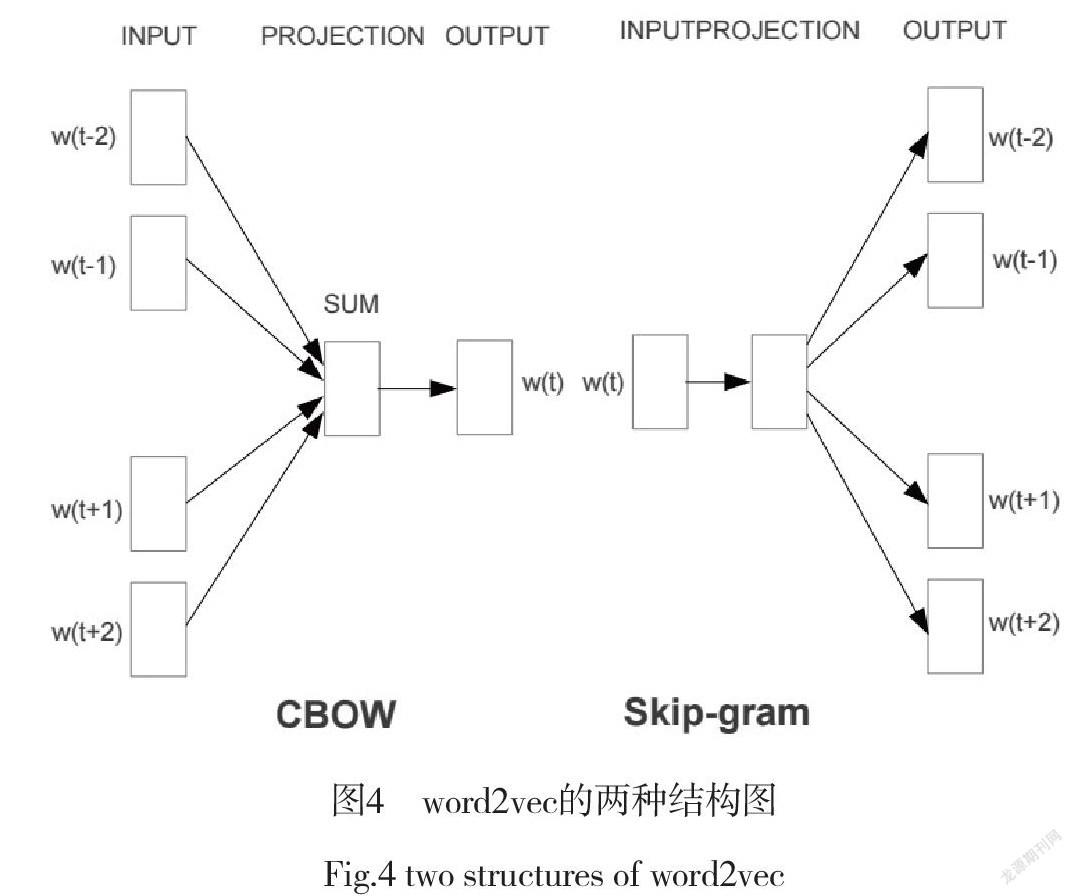
word2vec算法有兩種結構,分別為CBOW和skip-gram,它們的結構分別如圖4所示。
CBOW模式根據上下文n個詞計算某個詞的相關性,適合小語料;skip-gram模式根據某個詞計算上下文n個詞的相關性作為該詞的特征,適合大型語料。
我們通過調用python的gensim框架中word2vec模塊,采用skip-gram模式,設置計算一個詞前后五十個詞的相關性,對整本《紅樓夢》進行了訓練。訓練的結果顯示模型已經掌握了一些詞與詞之間結構的高級特征。圖5、圖-6給出了模型輸出與“賈寶玉”加“林黛玉”和“賈寶玉”加“薛寶釵”最相關的詞語。
我們將每一回目所有詞的特征相加后求平均作為該回目的文本特征,從而進一步作為SVM的輸入來訓練模型。
4.基于tf-idf的特征提取
tf指詞頻,idf指逆文本頻率指數,某一特定詞語的idf,可以由總文本數目除以包含該詞語的文件的數目,再將得到的商取對數得到。tf-idf算法的內容就是將一個詞的tf和idf相乘得到這個詞的權重或者特征。這樣做的好處在于能將那些真正對文本分類重要的詞作為文本的特征,而將那些雖然出現很多但毫不重要的詞例如“的”“了”給過濾掉,這正是乘積中idf項起到的作用。
我們用python的tensorflow框架實現了用tf-idf作為特征提取來對《紅樓夢》每一回的文本提取特征。
四、實驗和數據分析。
我們分別用幾種不同的特征提取方法提取了《紅樓夢》每一回的文檔特征,并分別連接了線性SVM和非線性SVM用來產生分類的結果。
對比表1,表2,表3,我們可以看出在200輪迭代后不同特征提取方法連接的非線性SVM分類器對于測試數據都已接近1的置信度成功分類,說明了《紅樓夢》每個回目的特征空間在映射的高維空間上是線性可分的,證明了在不同的回目上曹雪芹、高鶚兩位作者存在“可分的”差異。
我們也通過圖7可以看出,使用線性SVM作為分類器時訓練精度和測試精度不能收斂,存在震蕩,說明我們原先假設回目的特征空間線性近似可分是錯誤地。
我們還發現當迭代到100輪時,非線性SVM的損失已經收斂到0,然而訓練精度和測試精度還未達到最高。這也許會對那些優先考慮算法速度的任務很有幫助。
此外還有曲線平滑度的問題,在超參數相同的情況下,用主要人物出現頻數提取特征的測試曲線最為光滑,用虛詞出現頻數提取特征的測試曲線光滑度次之,用word2vec提取特征的曲線,光滑度最差。猜測在超參數相同的情況下,測試曲線的光滑可能與特征的維數有關,維數越高,越不光滑。
結束語
本文基于幾種不同的特征提取方法和兩種SVM分類器對現存公認的《紅樓夢》120回目版本的文本建立了模型。通過迭代訓練,非線性SVM分類器能夠以接近1的置信度將每一回目的作者成功分類,證明了在不同的回目上曹雪芹、高鶚兩位作者存在“可分的”差異。
進一步地工作包括以下兩個方面:
(1)在通過word2vec訓練詞向量時,實際上將模型的訓練分成了兩塊:用于提取特征的單隱層網絡和用來分類的SVM。這樣使得后端更新的參數不能反饋到前端去更新單隱層網絡,不利于損失函數的收斂。假如能夠構造出一種能夠實現end-to-end的網絡結構,既能用來提取詞向量特征,又能用來文本分類,這樣參數可以用BP算法從后端更新到前端。有利于提升損失函數的收斂速度和測試的精度。
(2)對于《紅樓夢》這樣的特定語料,我們無法判斷樣本是否基于獨立同分布產生的。同時也存在類別不平衡的問題。進一步地工作將圍繞這兩個問題展開對模型的修正。
參考文獻:
[1]劉鈞杰.《紅樓夢》前八十回與后四十回言語差異考察[J].語言研究,1986,1(2):172-181.
[2]蔣紹愚.近代漢語研究概率[M].北京:北京大學出版社,2005.
[3]李賢平.《紅樓夢》成書新說[J].復旦學報 (社會科學版),2005,5(8):3-16.
[4]陳大康.從數理語言學看后四十回的作者——與陳炳藻先生商榷[J].紅樓夢學刊, 1987,1(2):293-318.
[5]施建軍.基于支持向量機技術的《紅樓夢》作者研究[J]. 紅樓夢學刊,2011,9(14):35-52.
[6]周志華.機器學習[M].北京:清華大學出版社,2016:2-3.
[7]Hinton, Geoffrey E. Learning distributed representation of concepts[C]. Pro-ceedings of the eighth annual conference of the cognitive science socith.1986
[8]N Cristianini, J Shawe-Taylor, An Introduction to Support Vector Machines[M] Cambridge Univer-sity Press, Cambridge, UK, 2000.
本文受江蘇省政策引導類計劃(產學研合作)-前瞻性聯合研究項目資助,項目編號:BY2016065-5。
作者簡介:吳士軍(1967-),男,本科,講師,主要研究方向為大數據分析。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
