二語習得研究“需求側”視角下的漢語學習者語料庫建設①
2020-04-03 09:12:56曹賢文
華文教學與研究 2020年1期
曹賢文
(南京大學海外教育學院,江蘇,南京210093)
近年來,基于大規模真實文本的、定量與定性分析相結合的研究方法正逐漸成為漢語教學與習得研究的一種主要方法,學習者語料庫①的基礎平臺作用日益受到重視。除了語言教學、辭書編纂和語言處理等方面的需要以外,二語習得研究也對建設高質量的學習者語料庫提出了迫切需求。在語料庫語言學研究中,有“語料庫指引”(corpus-informed)、“基于語料庫”(corpus-based)、“語料庫驅動”(corpus-driven)等研究路徑(梁茂成、李文中、許家金,2010;Callies,2015),這些研究路徑可視為根據語料庫之于語言與語言教學研究的作用,從語料庫資源平臺的“供給側”視角所做的分析。本文則嘗試從當前二語習得研究“需求側”視角,分析漢語學習者語料庫建設與二語習得研究的互動發展趨勢,探討如何加強漢語學習者語料庫建設以更好滿足二語習得研究的需要。
1.學習者語料庫建設與二語習得研究的互動發展趨勢
1.1 學習者語料庫建設與二語習得研究的互動關系
學習者產出的書面和口頭數據一向是二語習得研究的關鍵資源。Myles & Mitchell(2004:173)認為,“二語習得研究除了清晰的理論框架以外,最寶貴的資源是可使用的高質量數據”。崔希亮、張寶林(2011)也指出,漢語中介語語料庫在對外漢語教學相關研究中發揮了巨大作用,作為基于大規模真實文本分析方法所依托的基礎工程,作為國際漢語教學研究的基礎性平臺,高質量的漢語中介語語料庫的建設需求日益凸顯。
國際上學習者語料庫著名專家Granger等(2015:1)主編的《劍橋學習者語料庫研究手冊》中,將學習者語料庫定義為“按照明確的設計標準收集匯編的,由外語或二語學習者產出的自然數據或近乎自然數據的電子集合”。并總結了利用學習者語料庫進行研究的兩大優點:第一,這些數據庫通常非常大,包含了大量學習者,無疑比只涉及到有限學習者的少量數據樣本更有代表性。第二,語料庫為電子數據格式,可使用軟件工具提取和分析,不但可提供以往需要花費大量人力物力進行大規模調查才能獲得的數據,而且大大提高了分析和研究的效率。
二語習得研究與學習者語料庫建設存在密切的互動關系。一方面,學習者語料庫的出現大大便利了二語習得研究,利用學習者語料庫提供的大規模語料有助于深入揭示二語發展規律,建設學習者語料庫可有效促進二語習得研究;另一方面,二語習得理論為設計高質量的學習者語料庫提供了有力支撐,二語習得研究的需要大大推動了學習者語料庫的建設力度,二語習得研究方法的發展則對學習者語料庫的建設水平提出了更高的要求。例如,在學習者語料庫建設的早期階段,主要關注的是描寫而非解釋,這一階段的學習者語料庫基本上是相對簡單的共時語料集合。不過這種狀況已逐漸發生變化,近年來,學習者語料庫建設開始重視以二語習得理論作為設計的基礎,并在建設目標中更自覺地追求能有效服務于二語習得研究。
施春宏、張瑞朋(2013)認為,“就目前建庫實踐而言,中介語語料庫的建設基本上都是研究目標驅動的”。針對漢語學習者語料庫建設的現狀,鄭艷群(2018)呼吁,“應重視基于教學或學習理論研究的語料庫建設,這類語料庫目前尚屬空白”。因此,有必要從二語習得研究“需求側”視角系統地思考漢語學習者語料庫建設,以二語習得研究前沿理論和方法為指引,以更好滿足二語習得研究需要為目標,建設能有效服務于二語習得主要研究范式的高質量漢語學習者語料庫。
1.2 漢語中介語語料庫建設與漢語二語習得研究
早在上世紀90年代,北京語言大學首開先河,建成首個真正意義上的漢語中介語語料庫——“漢語中介語語料庫系統”。近年來,不少大學或研究機構已建成或者正在建設一批不同類型的漢語中介語語料庫。例如:北京語言大學的HSK動態作文語料庫和全球漢語中介語語料庫、南京師范大學的外國留學生偏誤信息語料庫、魯東大學的多層偏誤標注的漢語中介語語料庫、中山大學的漢字偏誤中介語語料庫、暨南大學的留學生中介語語料庫、香港中文大學的語言習得漢語口語語料庫、南京大學的漢語中介語口語語料庫等等。
通過漢語中介語語料庫建設實踐的鍛煉,以及圍繞各項研究課題所需研究團隊的組建,專業學術研討會的定期召開,相關學術刊物所給予的支持,漢語中介語語料庫建設和研究逐漸形成了一支比較穩定的專業學術隊伍,成為了一個充滿活力的學術領域。例如,為了共同探討漢語中介語口語語料庫的建設、應用和研究,促進海內外相關領域專家、學者之間的交流與合作,進一步推動漢語中介語語料庫建設與基于語料庫的漢語教學研究的發展,北京語言大學、南京師范大學、南京大學、福建師范大學、揚州大學和美國萊斯大學等高校已經聯合召開了五屆“漢語中介語語料庫建設與應用國際學術討論會”,以及三屆“漢語中介語口語語料庫建設與應用國際研討會”。通過這些有組織的定期學術研討,學界在漢語中介語語料庫的建庫目標、語料采集、語料標注、檢索使用等方面取得了一定的共識,為推動語料庫建設及共建共享奠定了重要基礎。
由于得到了漢語中介語語料庫的有力支撐,最近一、二十年來,基于漢語中介語語料庫的研究得到較快發展,取得了不少代表性成果,例如,已正式出版的四屆《漢語中介語語料庫建設與應用國際學術討論會論文選集》,集中展示了漢語中介語語料庫建設與應用研究的最新成果。同時,《語言文字應用》、《世界漢語教學》、《語言教學與研究》等核心刊物相繼發表了一批本領域的高質量論文,另外一批基于漢語中介語語料庫的二語習得研究著作也陸續出版。
施春宏、張瑞朋(2013)指出,“不同的語料庫自然體現出不同的研究理論和研究方法,或者說不同的語料庫必須滿足不同的研究理念和研究方法”。從已有的漢語中介語語料庫所體現的二語習得理論和方法來看,或者從基于漢語中介語語料庫的過往習得研究來看,主要采用了以下幾種學習者語言分析理論和方法。
(1)偏誤分析
偏誤分析是由英國愛丁堡大學教授Corder(1967)最早提出的理論和方法,是對學生學習第二語言過程中所犯的偏誤進行分析,總結偏誤的類型和偏誤產生的原因,從而發現第二語言學習者產生偏誤的規律。上世紀80年代魯健驥(1984)首先把偏誤分析方法和中介語理論引入漢語二語習得研究。三十多年來偏誤分析在對外漢語教學界受到了普遍重視,產生了一大批研究成果,涵蓋了語音、詞語、語法、語篇、語用和漢字等各個方面。漢語二語習得研究中偏誤分析的研究成果數量最多,不過,其不足也顯而易見:只分析學習者語言錯誤的部分,對學習者語言的正確部分則棄置不談。“偏誤分析的最大弱點在于只研究中介語的偏誤部分,而且是橫切面式的靜態分析,并未研究中介語的正確部分。其結果,只能了解學習者未掌握的部分,而不能了解學習者已掌握的部分。這就割裂了中介語體系,看不到中介語的全貌及其動態的發展軌跡。”(劉珣,2000:202)
(2)頻率分析
頻率分析是研究中介語表現的一種主要方法,與偏誤分析只研究語言偏誤不同,頻率分析關注學習者語言中各種特征的使用頻率,既研究中介語的錯誤部分,也研究正確部分,是研究學習者語言表現、習得順序和發展過程的常用分析方法①例如,在漢語二語習得順序研究中常用的“正確使用相對頻率法”和“蘊含量表法”都是以頻率分析法為基礎。。頻率分析法通過對學習者語言特征的正誤情況進行統計和分析,來描述和解釋語言表現、習得順序和習得過程,與只關注中介語偏誤情況的偏誤分析相比,是一種進步,不過頻率分析仍是一種比較簡單的中介語表現分析方法,由于其測量指標比較單一,仍不足以全面地描述中介語的特征和規律。
(3)中介語對比分析
中介語對比分析是比利時魯汶大學教授Granger(1996)提出的一種基于學習者語料庫的中介語分析方法。根據Granger(1996)的中介語對比分析模型,這種分析方法包括兩個方面的比較:一是中介語與目標語的比較,以揭示二者之間的異同,反映中介語的多用、少用和誤用等使用特征,這是中介語對比分析的核心部分。二是不同母語背景的中介語語料的比較,以反映不同母語背景的學習者的語言輸出情況,揭示不同學習者群體的中介語使用特征。在提出上述分析理論和方法的同時,Granger率先創建了“英語學習者國際語料庫”(International Corpus of Learner English),開啟了相關實踐研究。近年來,這種方法開始進入漢語二語習得研究領域,并取得了一些研究成果(邢紅兵、辛鑫,2013)。不過,作為早期的中介語對比分析法,這種方法也存在一些缺陷。對此,Granger(2015)進行了反思和總結:既未考慮到由于功能變量和地域變量對參照語的多樣性的影響,也未能考慮任務變量、學習者個體變量等對中介語變體的影響。針對中介語對比分析的缺陷,Granger(2015)提出了中介語對比分析2.0模型,詳見下文。
2.二語習得研究和中介語分析方法的發展趨勢
上文所述的三種分析方法是已有的漢語中介語語料庫作為建庫研究目標的主要理論和方法,也是目前基于漢語中介語語料庫的習得研究所用的主要方法。近年來,隨著二語習得理論的發展,二語習得研究和中介語分析方法不斷進步。下面是目前國際上分析學習者語言研究中采用較多或正在發展的一些分析方法,可供漢語中介語語料庫建設時借鑒和參考。
(1)中介語多元對比分析(CIA 2.0)
在Granger提出的早期中介語對比分析模型里,主要是中介語與目標語的比較、不同母語背景的中介語之間的比較。之后,學界在此基礎上繼續探索,中介語對比進一步擴展到相同母語背景的不同水平中介語的比較,學習者母語與中介語的比較,學習者母語、中介語和目標語三者之間的比較,不同任務條件下的中介語比較,相同學習者不同縱向發展階段的中介語比較,學習者口語與書面語語料比較,雙語或多語環境下學習者母語或傳承語(heritage Language)與第二語言發展的比較,等等方面,中介語對比分析發展成為多因素、多層面、多角度的多元比較分析。
由于中介語是一個高變量,受多種多樣的語言、情境和個體因素的影響,中介語的變異性非常突出。為了彌補早期中介語對比分析的缺陷,Granger(2015:17)提出了中介語對比分析2.0模型(圖1),突出強調中介語和參照語(reference language)的變異性,以及該模型的多元互動對比特征,是中介語對比分析的新發展。我們將它稱為“中介語多元對比分析”。
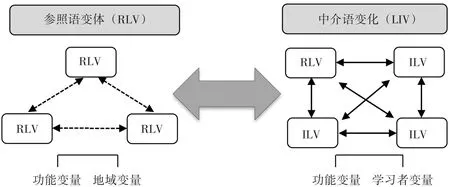
圖1:中介語對比分析2.0模型
(2)二語多維表現分析
二語多維表現分析,也叫“三性”分析,或“四性”分析。根據國外學者的研究(Wolfe-Quintero et al.,1998等),測量學習者語言發展的綜合表現通常包括三個維度:復雜性(complexity)、準確性(accuracy)和流利性(fluency),簡稱為“三性分析”(CAF analysis)。上世紀90年代以來,該分析方法逐漸發展出一套針對學習者語言表現的測量指標,并形成了相對可靠實用的操作框架。在此基礎上,一些學者就如何完善多維表現分析法提出了補充思考。例如,文秋芳、胡健(2010)提出在“三性”的基礎上,需增加一項多樣性,與復雜性、準確性和流利性一起組成“四性分析”。多維表現分析通過采用綜合測量框架可以更全面地展現學習者語言的面貌,并有利于揭示中介語系統多維互動發展的規律。目前漢語二語習得研究中單維表現分析較多,多維表現分析較少。由于建庫時設計目標的局限,迄今已建成的漢語中介語語料庫仍難以全面支持多維表現分析。
(3)二語動態發展分析
傳統的二語習得研究或多或少把學習者語言發展視為連續漸變的線性發展過程,而新興的動態系統理論(Larsen-Freeman,1997;Van Geert,2008;Larsen-Freeman & Ellis,2009) 認為,學習者語言是一個復雜、動態的發展過程,發展過程充滿了非線性的變異和變化現象。二語動態發展分析將學習者的語言發展變化作為核心內容,追蹤學習者語言發展的非線性動態軌跡,描述發展中的各種變異特征。二語動態發展研究基本上都采用縱向歷時設計,采用“移動極值圖表”(moving minmax graph)、“相變”(phase transition)等方法來描述學習者語言的發展變化,該分析方法對于揭示二語發展的非線性變化過程和變異特征具有很強的解釋力。不過,要廣泛運用這種歷時動態發展分析方法,需要大量中介語縱向發展語料的支持。
(4)學習者個體因素與語言表現的相關分析
學習者的語言系統是一個動態發展系統,其發展過程受到各種內外因素的影響。只有通過分析語言變量與各種內外因素之間的復雜互動,才能比較全面真實地揭示漢語二語習得特征和發展規律。為了研究學習者語言表現與影響因素的互動規律,除了需要得到大規模中介語語料支撐,也需要獲得影響中介語發展的各種變量的信息。在采集中介語語料的同時,除了補充學習者的性別、年齡、國籍、母語背景、漢語水平等常用的學習者元數據以外,在條件允許的情況下,還可以選擇一些重要的學習者個體因素變量,分門別類進行問卷或實驗采集,如學習動機、學習信念、學習策略、語言學能、認知風格、身份認同、情感焦慮等。通過學習者個體因素與語言表現的相關分析,可深入研究學習者個體因素對中介語形成和發展的影響。
(5)社會語言學因素與語言表現的互動分析
二語習得研究的首要目標是描述和解釋哪些因素影響學習者語言的發展及其變異和變化,從而制定有效的教學和學習策略,提供最好的幫助來促進語言學習,改善語言表現、提高語言水平。除了要加強學習者個體因素與語言表現的相關分析以外,也要重視各種社會語言學因素與語言表現(特別是中介語的變異性)的互動分析。在采集中介語語料的同時,可以選擇一些重要的社會交際因素,如交際參與者、交際情境、交際目的、表達方式、文本類型、輸入頻率、任務類型、反饋方式等,進行定向采集。通過社會交際因素與語言表現的相關分析,可深入研究學習者語言變異表現及其影響因素之間的發展規律。
(6)多模態二語話語分析或互動分析
模態是指“人類通過感官(如視覺、聽覺、觸覺等)跟外部環境(如人、機器、物件、動物等)之間的互動方式”(顧曰國,2013)。人類與外界的交互是多模態的,學習者語言能力是在多模態交互中建構和發展的。多模態分析可探討二語發展與非語言要素之間的互動關系。例如,利用多模態視頻語料,包含經過轉寫、處理與標注的語言文本及與文本緊密關聯的音視頻數據,分析二語表達過程中學習者的手勢、姿勢、目光、表情及場景等非語言符號與二語之間的互動關系。此外,從文本、聲音、圖像等多模態視角分析二語人機互動以及二語語音識別、手勢識別、情感識別等方面的應用研究也日益受到重視。
(7)雙語或多語發展分析
我們生活在一個多語世界,世界上有大量人口在多語言家庭、社區和社會中生活和學習,雙語或多語人是未來社會的發展趨勢。描述和解釋雙語環境中的語言互動規律、個人雙語或多語能力的發展,以及超語言技能(translanguaging)的培養,日益成為學界關注的焦點。由于缺少多語環境下的多語發展語料,個人多語能力的發展、多語的產生和理解、多語與認知的關系等方面的研究很不夠。以往二語習得領域有較多研究分析過一語對二語的遷移,而二語對一語的反向遷移則研究很少,二語、三語等非母語之間互相產生的語際影響研究也十分缺乏。此外,海外華裔漢語學習者的華語傳承語與所在地區主導語言或其他語言之間多語能力的互動發展狀況和規律也亟需加強研究。
(8)學習者網絡二語交際能力及其發展分析
隨著寬帶無線移動通信技術的進一步發展和Web應用技術的不斷創新,我們正處在一個全新的信息時代,網絡世界日益與現實世界交互重疊在一起,人們的生產方式、生活方式和學習方式正在發生深刻變化。為了適應網絡時代的學習和生活,學習者網絡二語能力及其發展開始受到關注。可利用學習者網絡交際語料,如通過網絡聊天室、微信、QQ、博客、多人在線游戲、MOOCs課程等收集到的學習者語料,分析學習者網絡二語交際能力及其發展,或分析線上線下二語互動發展規律。
3.適應二語習得研究新需求的漢語學習者語料庫建設展望
以上是近年來興起的分析學習者語言的一些重要方法,代表了基于學習者語料庫的二語習得研究的發展趨勢。本文總結這些研究方法,并非期望所有的二語習得研究數據都由學習者語料庫提供,而是希望在建設學習者語料庫時,能夠確立先進的建庫理念和研究目標,能夠多考慮如何為二語習得研究提供亟需的數據支持。施春宏、張瑞朋(2013)指出,“基于不同的研究觀念和方法,自然會建立不同特征的語料庫”。因此,漢語中介語語料庫建設應關注二語習得研究的理論、方法和使用需求,從而提高語料庫的價值和使用效率。為了更好滿足未來二語習得研究的發展需要,我們認為,可從以下幾個方面加強學習者語料庫建設方法論的思考和相關建設實踐工作。
(1)建設好“全球漢語中介語語料庫”
與國外同類研究相比,基于漢語學習者語料庫的中介語對比分析研究發展得不夠充分。目前的研究主要集中在中介語與本族語語料、不同水平等級中介語語料之間的比較,至于不同母語背景的學習者語料、相同學習者不同任務條件下的語料、不同縱向發展階段語料、學習者口語與書面語語料等方面的比較研究則很薄弱。另外,已有研究中介語對比分析的維度單一,大都只是針對某個語法項目的使用頻率、正確率或錯誤率進行對比,至于中介語其他發展維度(如復雜性、流利性等)的綜合比較則很缺乏。究其原因很大程度上是由于已有的漢語中介語語料庫規模較小,語料不夠全面,各語料庫之間缺少統一的建設標準,功能比較單一且大都未能實現共享,因而難以提供足夠的、可以從不同層面和維度進行對比分析的豐富語料。
目前由北京語言大學牽頭、國內外多家單位參與共建的“全球漢語中介語語料庫”正在推進中,該語料庫得到教育部重大攻關項目和北京語言大學語言資源高精尖創新中心的大力支持,秉承共建共享、整合開放的理念,有效克服了現有語料庫規模小、語料不全面、標注內容不豐富、背景信息簡單等不足。目前“全球漢語中介語語料庫”已經完成了語料收集、書面語語料錄入、口語和視頻語料轉寫、標注規范的研制,以及語料庫建設與應用綜合平臺的開發等工作。建設一個“語料樣本多、規模大、來源廣、階段全、背景信息完備、標注內容全面”(崔希亮、張寶林,2011)的“全球漢語學習者語料庫”是一項極具挑戰性的任務,我們期待該語料庫建成后能夠更好地為漢語二語習得研究服務,能夠滿足中介語多種分析方法的需要。
(2)加強漢語中介語多維語料庫建設
現有漢語中介語語料庫基本是單模態的,其標注也基本是以偏誤標注為核心的單維標注,通常只能提供基于偏誤或正確性的單維分析,難以進行復雜性、流利性、多樣性等維度的多維分析。多維語料庫與多模態語料庫不同,多模態語料庫指語料由文本、聲音、圖像等不同模態構成,而多維語料庫主要強調從語料的準確性、流利性和復雜性等不同維度來呈現語言表現。從目前語言表現多維指標的標注和檢索來看,流利性指標可望通過計時軟件自動實現,準確性指標可通過偏誤標注反向呈現,復雜性和多樣性指標在現行語料庫基礎標注的基礎上增加相應內容也可以實現。目前,國內漢語中介語多維語料庫還沒有完成建設,現有語料庫遠遠不能滿足中介語多維表現分析所需數據的要求。“多維度語料庫從某種程度上打破了單模態和多模態語料庫的界線,可以說是語料庫從一維到多維再到立體的建設發展的必然趨勢”(周文華,2015)。今后需要加強中介語多維表現分析所需數據的采集、標注和檢索平臺的設計等工作,積極推進漢語中介語多維語料庫建設。
(3)建設好漢語中介語動態發展語料庫
在二語習得理論的發展歷史中,早期的個案追蹤及其縱向發展研究發揮了重要作用(Ellis,2008)。近年來,二語發展的動態系統理論成為熱點之后(Van Geert,2008;Larsen-Freeman & Ellis,2009),采集縱向發展語料,開展動態發展研究受到學界關注。目前漢語中介語語料庫基本都是共時截面語料庫,歷時縱向語料庫十分缺乏。一些學者提出,可利用不同語言水平等級語料構建類歷時語料庫(quasilongitudinal corpus),以解決縱向語料缺乏的問題(Granger,2002;顏明、肖奚強,2017)。不過,Gass & Selinker(2008:56)把這類數據稱為“偽縱向數據”(pseudolongitudinal data),認為用分層截面數據來取代縱向數據,其有效性充滿爭議。類歷時語料庫有一個基本假設:二語是線性發展的,習得過程是線性漸增的。然而二語發展并非總是連續上升的過程,學習者的進步模式除了線性上升或下降以外,也包括N形、Ω形、V形、U形等不同模式(文秋芳、胡健,2010),非線性過程是二語發展的常態。
客觀地說,類歷時語料和真正的歷時語料都是需要的,各有其效用。“對于研究漢語二語習得過程,既需要截面數據,也需要縱向數據,縱向追蹤語料庫起著共時語料庫難以替代的作用”(曹賢文,2013)。因此,需要花大力氣采集中介語發展過程中的多波縱向數據,通過加強漢語中介語動態發展語料庫建設,來支撐相關二語習得研究,尤其是深入考察中介語在時間軸上的變異和變化表現,對學習者中介語系統的動態發展軌跡作出比較完整的描述和解釋。
(4)建設好中介語及其影響變量聯動數據庫
中介語的發展從來都不是一種孤立的語言現象,只有通過分析語言變量與各種內外因素之間的復雜互動,才能比較全面真實地揭示漢語二語習得特征和發展規律。施春宏、張瑞朋(2013)指出,“無論是社會語言學,還是中介語理論/語言習得理論,最重要的目標就是描寫和解釋語言變異現象。而建立相應的語料庫,必然要對制約語言變異的因素做出合理而充分的說明”。因此,要加強中介語與多種影響變量之間的聯動數據收集和整理工作,建設中介語及其影響變量聯動數據庫。影響中介語發展的變量數據,主要包括三類:學習者元數據、個體差異數據和各種任務情景數據。學習者元數據包括學習者的性別、年齡、國籍、母語背景、漢語學習時間、漢語水平等基本信息。個體差異數據包括學習動機、學習信念、學習策略、語言學能、認知風格、身份認同、情感焦慮等學習者認知心理方面的變量數據。任務情景數據包括交際情境、表達方式、文本類型、輸入頻率、任務類型、反饋方式等社會互動方面的數據。已有的漢語中介語語料庫,一般都或多或少包含著學習者的一些元數據,但缺少影響學習者語言的其他變量數據,因而無法使用相關語料和數據進行更深入的分析和研究,今后需要重視將中介語語料與多種影響變量的聯動數據分批打包收集和整理。
(5)建設好漢語學習者多模態語料庫
黃偉(2015)認為,“開展漢語中介語多模態語料庫建設與研究工作不僅是漢語學習者語料庫建設的有益補充,更能夠在漢語作為第二語言的教學與習得研究領域發揮作用”。建設好漢語學習者多模態語料庫,不但可以為分析二語表達過程中學習者的手勢、姿勢、目光、表情及場景與二語之間的互動關系提供豐富的數據,還可以提供猶豫、不流暢等副語言現象和情感狀態方面的信息,甚至是皮膚電阻、心率、呼吸等生理信號方面的信息。由于多模態語料庫包含著非常豐富的非語言數據,國外多模態語料庫一般不采用傳統的“語料庫”(corpus)命名,而是使用“數據庫”(database)的稱謂。與傳統語料庫相比,建設漢語學習者多模態語料庫是一次觀念和技術的突破,在多模態數據的收集、多模態圖像與視頻分析軟件的研發、多模態數據的標注以及檢索平臺的設計等方面都帶來了全新的挑戰,正因如此,多模態語料庫將可以為漢語二語習得研究所提供前所未有的豐富信息。
(6)建設學習者多語發展語料庫
廣義的多語語料庫是含有兩種及以上語言的語料庫,是“任何系統收集的實證性語言數據,其收集的目的是為了讓語言研究者能夠對多語個體、多語社會以及多語交際進行分析”(Schmidt & W?rner,2012:XI)。全球話語已進入多語時代,多語制(multilingualism)將成為一種生活方式,個人多語言能力是融入世界的重要技能。通過建設漢語學習者多語發展語料庫,將可以為分析學習者的多語能力發展和多語交際規律提供必要的語料。尤其是海外華裔傳承語學習者的漢語與當地主導語言的雙語或多語發展語料,對于研究華語傳承語的特點、傳承語習得規律以及與主導語言之間的互動消長關系將會起到非常重要的支撐作用。
(7)建設漢語學習者網絡交際語料庫
網絡為我們提供了新的交際方式,也提供了新的話語平臺。隨著互聯網和信息技術的飛速發展和日益普及,網上交流已經成為人們學習、生活及參與社會活動的重要方式。虛擬化的網絡交際與傳統的現實交際愈來愈融合在一起,為研究二語學習者的語言發展帶來了全新的課題。通過收集學習者在網絡聊天室、微信、QQ、博客、多人在線游戲、MOOCs課程等平臺中產生的漢語語料,建設漢語學習者網絡交際語料庫,將可以為研究學習者網絡二語交際能力及其發展過程,以及分析線上線下二語互動發展規律提供有力的數據支持。
除了加強上述漢語學習者語料庫的建設以外,還應繼續建設一些聚焦漢語特征的專門語料庫,如漢語學習者語音語料庫、漢語學習者漢字語料庫等,以重點支持與漢語的獨特性有關的習得研究。由于二語習得理論和研究方法日益多元,著眼于滿足其研究需求的漢語學習者語料庫的建設可以采取兩條路徑并行發展,以適應不同的研究需要:第一,采取共建共享的方式,聯合學界力量建設通用型的大型語料庫,適應常規分析方法,滿足一般性研究需求;第二,鼓勵建設個性化、專門化的小型語料庫,作為支持新理論、新方法的探索,如果該研究范式逐漸由邊緣成為主流,則這種專門化的小型語料庫可進一步發展為大型語料庫。
漢語中介語語料庫建設的根本目的是為教學與研究服務,不過“由于建庫實踐中存在的隨意,現有的語料庫尚不能完全滿足漢語教學與研究的使用需求……目前,漢語中介語語料庫建設中存在的隨意性,已經成為制約語料庫建設發展的關鍵問題。”(張寶林、崔希亮,2015)本文根據二語習得研究和中介語分析方法的發展趨勢,結合漢語學習者語料庫的建設實踐,分析“需求側”視角下漢語學習者語料庫建設的相關問題,目的是想減少漢語中介語語料庫建設的隨意性,強化以應用為導向的語料庫建設和研究,以便根據新的形勢和發展需要,以前瞻性的構想和設計,加強合作、共建共享,提高漢語中介語語料庫的建設水平,在靜態、單一維度語料庫的基礎上進一步建設動態、多維、多模態、多語、網絡交際語料庫,“推動各種類型的語料庫的建設和發展”,盡可能滿足漢語中介語分析理論和方法的需要,更好地服務于語言習得研究和漢語國際教育事業。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
文苑(2020年4期)2020-05-30 12:35:30
中國外匯(2019年18期)2019-11-25 01:41:56
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年14期)2018-08-21 01:38:28
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
人大建設(2017年10期)2018-01-23 03:10:17
民生周刊(2017年19期)2017-10-25 10:29:03
山東工業技術(2016年15期)2016-12-01 05:31:22
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
