韓國漢語學習者中介語口語語料庫的建設及意義①
2020-04-03 09:12:56胡曉清許小星
華文教學與研究 2020年1期
胡曉清,許小星
(1.魯東大學文學院,山東,煙臺264025;2.韓國國立群山大學人文學院,韓國全羅北道,全州561756)
0.引言
近年來,漢語中介語語料庫建設不斷向縱深發展,建立口語語料庫并基于語料庫開展口語研究成為漢語作為第二語言教學研究的新趨勢。許多學者對漢語中介語口語語料庫的建設提出了可行性方案(崔希亮、張寶林,2011;權立宏,2017),也有一些院校、單位展開建庫實踐,如北京語言大學的“漢語學習者口語語料庫”(楊翼等,2006)、北京語言大學“HSK動態口語語料庫”(張寶林,2010)、香港中文大學“語言習得漢語口語語料庫(LAC/SC)”(吳偉平,2010),南京大學“漢語中介語口語語料庫”(在建)等。但遺憾的是,由于中介語口語語料采集、轉寫和標注的難度較大,口語語料庫的建設費時費力,目前能夠公開使用的漢語學習者口語語料庫較少。
基于此,本團隊在國別化中介語筆語語料庫建設的基礎上,開始探索國別化漢語中介語口語語料庫的建設。首期建立的是韓國學習者漢語中介語口語語料庫,簡稱為KHSKKC。語料庫語料來源于韓國漢語水平口語考試的現場錄音。在對語料進行轉寫后,從語音層面和句法層面兩個維度對語料進行了較為細致和全面的標注。
1.韓國學習者漢語口語語料庫的建庫價值
1.1 可對新HSK考試反撥效應研究提供支撐
以標準化考試語料為來源的漢語中介語口語語料對漢語水平考試的反撥效應明顯。在建的KHSKKC語料庫首次使用了新HSK口語語料,利用該語料庫提取的字表數據庫、詞表數據庫,在后續研究中將與新HSK詞匯大綱、漢字大綱等結合,進行相關性研究,這對HSK的信度、效度及測試對教學的反撥作用研究等均將起到一定的支撐作用。
1.2 可為國別化漢語教學研究提供支撐
在漢語教學研究界,對漢語教學“國別化”的呼聲越來越高(李如龍,2012等)。不同國家、不同母語和文化背景的學習者,學習漢語時表現出的中介語特征的確存在著差異。因此,甘瑞瑗、張普(2005)提出,“國別化”就是要“針對不同的國家而實行不同/差別的漢語的教學與研究”。國別化漢語中介語語料,為國別化教學大綱設計、國別化教材的編寫、國別化詞典的編撰提供可靠的依據,也為漢語作為第二語言的習得研究提供扎實的多維度基礎數據。
(1)為國別化漢語教學用字表、詞表的研制提供有力支撐
《漢語水平詞匯與漢字等級大綱》(以下簡稱《大綱》),研制于1992年(2001年進行了修訂),隨著時代的發展與進步,社會語言生活發生了巨大的變化,《大綱》逐漸不能滿足漢語學習者和漢語作為第二語言研究的需要。2010年出臺的《漢語國際教育用音節漢字詞匯等級劃分》(以下簡稱《等級劃分》)一個顯著的變化是將口語動態語料作為制定音節表、字表和詞表的依據之一。但需要注意的是,《大綱》和《等級劃分》中對字、詞的選擇仍然是純本體視角,而漢語國際教育用的字表、詞表除要依據母語者的使用頻率外,還應該將二語學習者口、筆語語料庫作為重要的參照。因此,對韓國學習者漢語口語的字表和詞表的提取、研究,為面向韓國的漢語教學用字表、詞表的研制提供了強有力的支撐。
(2)為漢語中介語口語、筆語對照研究提供有力保障
我們在語料庫建設中回避了“書面語”,代之以“筆語”,究其原因,一是參照了文秋芳、王立非(2008)“中國學生英語口筆語語料”的提法。更重要的是漢語二語學習者在從零起點到接近于漢語母語者的習得過程中,有相當長一段時間尚未形成書面語意識,他們所謂的“書面語”大多數情況下只是以筆語形式記錄下來的口語而已。那么漢語學習者的筆語在哪些階段出現了明顯的書面語化特征,從哪些節點他們的口語筆語發生了質的變化,這都需要將學習者的口、筆語進行對照方可顯現。目前,在漢語作為第二語言教學和研究領域,將漢語中介語進行口語和筆語對照研究的尚不多見。原因是多方面的,但有一點無需諱言,即對漢語中介語口語和筆語中用字、用詞及語法項目使用情況、口語書面語分化情況的研究均需借助大規模的漢語中介語口語語料和筆語語料,而目前的口語語料相對比較匱乏。我們建設的韓國學習者漢語中介語口語語料庫和早前建成的“國別化(韓國)漢語中介語發展語料庫(筆語)”(胡曉清,2018)形成對照組,為韓國學習者漢語中介語口語和筆語的對照研究提供了有力保障。
1.3 可豐富漢語中介語語料庫建設的內涵
漢語中介語語料庫,按照語體來分有筆語語料庫和口語語料庫;從樣本來源來看,有多國別樣本,也有單國別樣本。在漢語作為第二語言教學和研究領域,筆語語料庫和多國別樣本語料庫數量上占有絕對的“優勢”。“韓國學習者漢語中介語口語語料庫”的建設探索補足漢語中介語語料庫建設的弱項,對漢語中介語口語語料庫建設規范的研究、對不同類型語料庫之間的對接和融合進行了有益的嘗試,豐富了漢語中介語語料庫的建設內涵。
2.韓國學習者漢語口語語料庫的建設原則
2.1 真實性原則
真實性是學習者語料庫建設的底線。因此語料轉寫要忠實于音頻原貌,考生說什么轉錄什么,包括考生對言語中的重復和修復,不做任何修改刪減,如實錄入。對于非正常停頓和轉寫人反復聽仍無法辨識的字詞或字串用標記來代替;口語語料里存在大量口頭語,如“嗯”“啊”“呃”等語氣詞均要如實轉寫。而一些非言語成分,如音頻中考生的笑聲和一些如呼氣、咳嗽等伴隨語音現象均要進行標示。
2.2 準確性原則
標點及符號的準確性:所有的標點均為中文、半角格式;所有添加的符號均為半角英文狀態。
文字的準確性:轉寫語料原則上沒有錯字和別字。
標注的準確性:在確立了標注范圍后,制定了較為細致的轉寫與標注規范,然后選取少量語料對標注員進行試轉寫與標注訓練,再進行集中討論與校正,深化對標注規范的理解,并補充完善標注規范,最終形成科學的、操作性強的標注手冊,最大限度保證標注員對語料聽辨轉寫和標記賦碼的一致性和準確性。
為了減輕標注員記憶標注代碼的負擔,并保證賦碼的一致性和準確性,我們開發了輔助轉寫與標注的軟件,標注員一邊收聽音頻,一邊在輔標軟件的文本編輯界面上進行轉寫,如需進行賦碼,點擊右鍵,從下拉菜單中選擇標記代碼,代碼便自動添加到文本之中。標注完成之后,文本自動保存在指定目錄下。此外,對文本的校對也可在該輔標軟件中完成。該軟件的開發大大提高了轉寫與標注的效率。
2.3 全面性原則
沒有任何加工的生語料,只能進行字、詞的檢索,語料經過斷句、分詞和標記詞性,可以進行詞的搭配和類聯結等研究;經過偏誤標注及對語料中正確語言表現進行標注,可以對漢語學習者的習得情況進行全方位的對比、考察與研究,大大提升了語料庫的使用價值。
2.4 便捷性原則
一個功能完善、使用便捷的語料庫檢索系統不僅要能提供方便靈活的檢索和統計功能,還應便于維護與功能擴展。漢語中介語口語語料庫檢索軟件能基于語料庫中添加的標記代碼,根據處理的目的來設計相應的算法規則,提取相應的信息,得到相應的檢索和統計結果。
3.韓國學習者漢語口語語料庫構成狀況
3.1 語料庫現有庫容及建庫流程
本語料庫的語料來源于韓國漢語水平口語考試的現場錄音,目前已對韓國漢語水平口語考試的1.5萬余個音頻進行了轉寫并對轉寫文本進行了標注,在此基礎上建設完成韓國學習者漢語口語語料數據庫并搭建了語料庫檢索系統。該語料庫的構建過程包括語料收集、文本轉寫、語料標注、語料庫檢索工具的開發,具體流程如圖1所示。
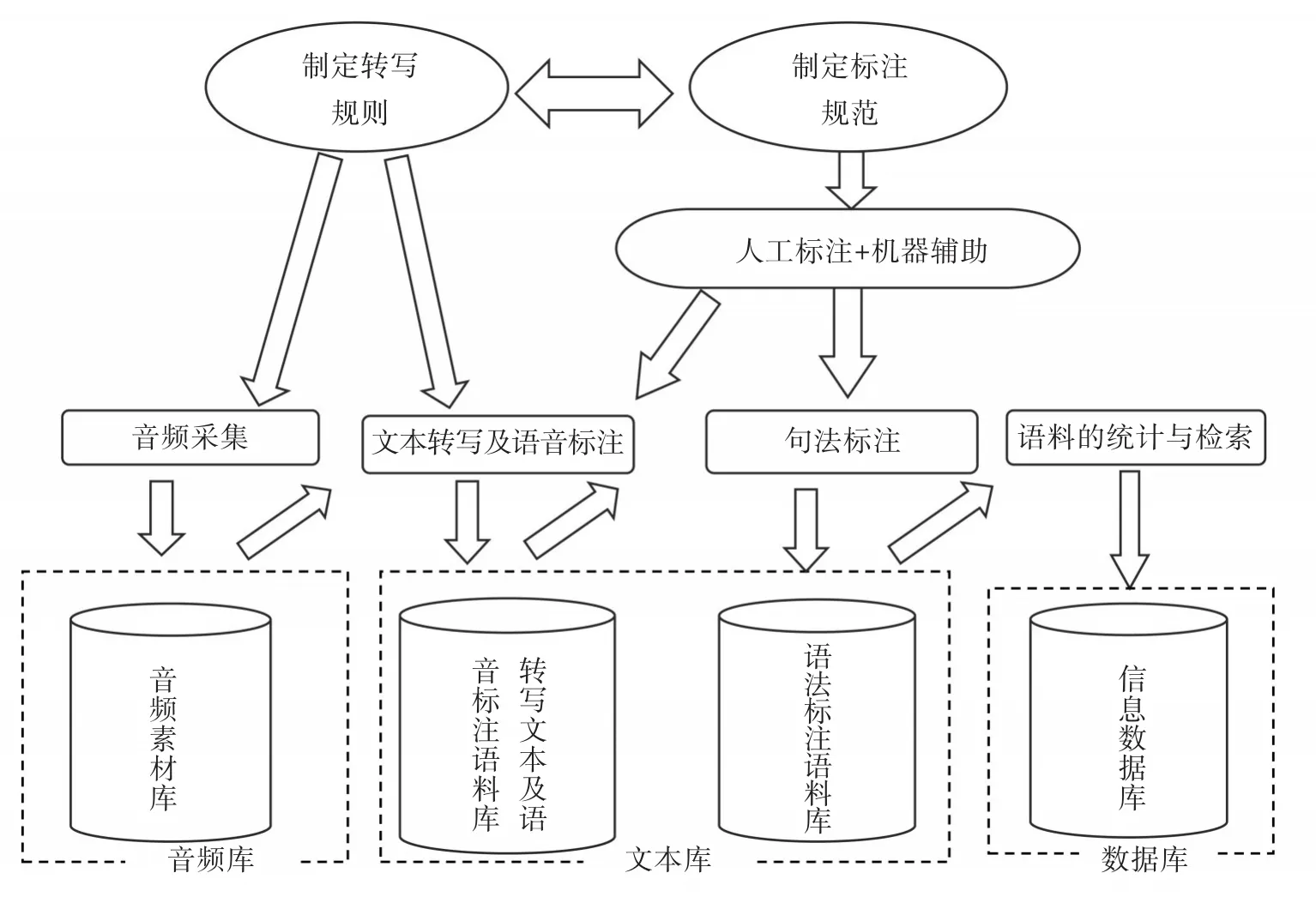
圖1:KHSKKC建設流程圖
3.2 語料的來源及預處理
本語料庫的語料來源于在韓國舉行的漢語水平口語考試的現場錄音。漢語水平口語考試(HSKK)分為初級、中級和高級三個等級,不同等級口語考試的考試內容均分為三個部分(見表1)。
口語語料庫音頻庫的二級目錄為考試等級(初級、中級、高級);每一個考試等級內按照考試年份、考場代碼、考生代碼依次建立目錄。每一個考生的所有音頻根據考試內容的不同劃分為T1、T2、T3三個子任務。在轉寫語料時,三個子任務轉寫為對應的三個txt文件,保證音頻庫和文本庫的結構層次清晰、便于管理。圖2展示了音頻庫和文本庫的庫結構。

表1:HSKK考試內容分布
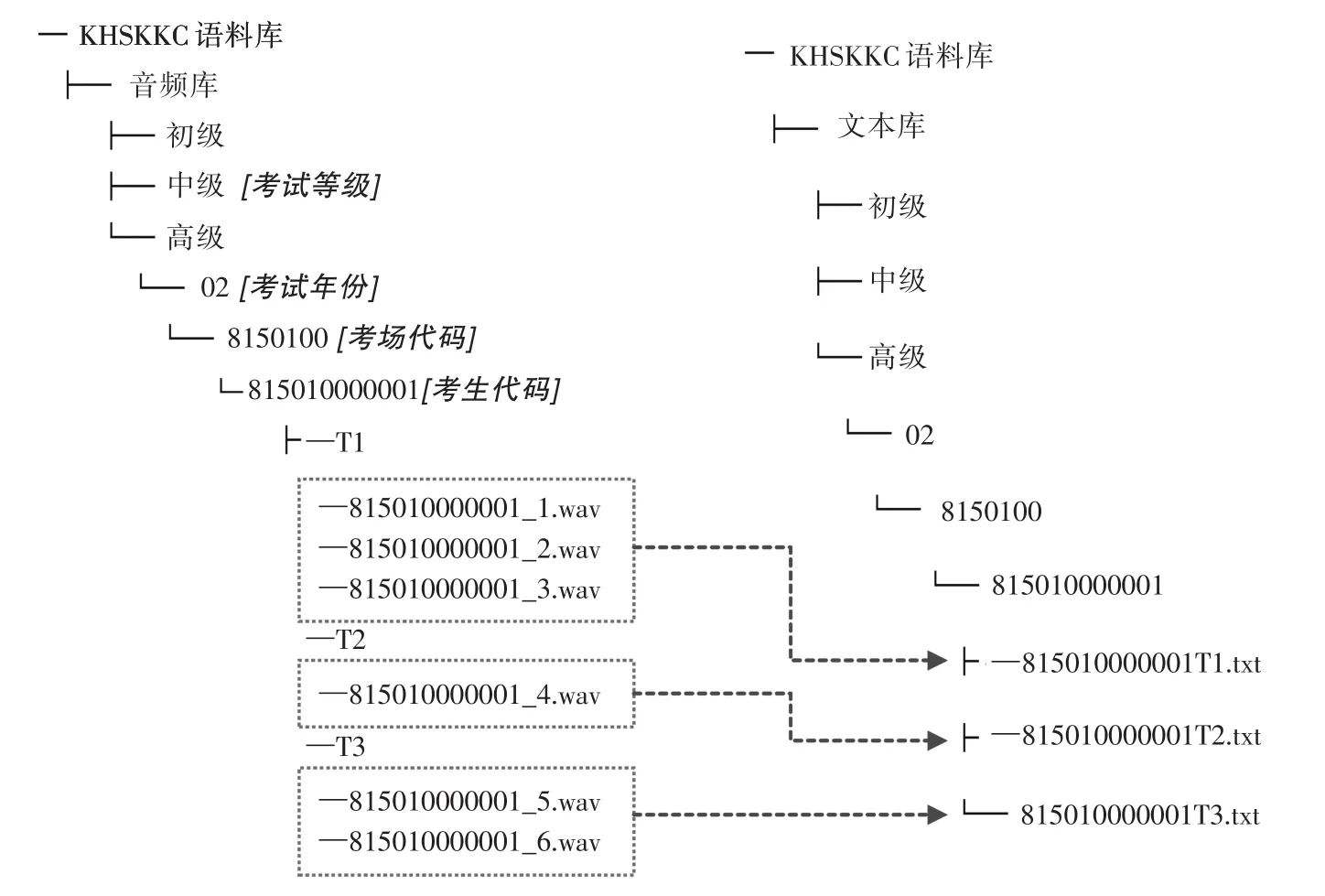
圖2:音頻庫和文本庫目錄樹
如一個考生的全部音頻因噪音太大而無法進行轉寫,就將該考生的所有音頻刪除。如一個考生的大部分音頻比較清晰、符合轉寫條件,為了最大限度保留并記錄音頻內容,將該考生的全部音頻整理歸檔,并依次進行轉寫,其中因噪音或者音質受損而無法轉寫的音頻在文庫本中對應的位置標記為<無效>。
3.3 語料的轉寫與標注
在新的技術條件下,母語口語語料的轉寫已非常方便快捷,而漢語中介語口語語料因大量的語音問題使自動轉寫準確率偏低,不得不仍然選用耗時耗力的人工轉錄方式。為此,我們制定了KHSKKC語料庫的轉寫原則與標注規范。
轉寫音頻語料遵循真實性原則,已如前述。為避免轉寫后重復聽錄音進行語音現象處理,最大限度地減少多人同時作業造成的聽辨嚴格度、準確度不一致問題,在確立轉寫原則的前提下,參考北京語言大學“全球漢語中介語語料庫”口語語料的轉寫與標注規范(張寶林等,2019),我們制定了較為細化的轉寫和標注規范。
口語語料轉寫時,轉錄員邊聽邊轉寫,在轉寫的同時需對文本語料進行語音層面的標注。對于如何確立口語語料庫標注內容,張寶林等(2019)指出“說話時伴隨的一些語音現象,例如笑聲、咳嗽聲之類,以及拖長的聲音。這些語音現象不一定是偏誤,在這里進行標注只是為了方便”,而我們認為非偏誤語音現象對口語不同維度的研究深具意義,因此標記時將其直接分為對語音現象的標注和對語音偏誤的標注兩類。其中語音現象的標記共有9個,語音偏誤的標記共有7個。具體標記詳見表2。
完成中介語口語語料轉寫和語音層面標注后,我們對文本語料進行了句法層面的標注。句法標注仍延續之前“國別化漢語中介語發展語料庫”筆語庫的標注模式,進行基礎標注和偏誤標注(胡曉清,2018)。基礎標注是對語料中正確的語言現象進行的標注,偏誤標注是對語料中不正確的語言現象進行的標注。目前我們對語料進行了分詞處理、基本句式的正誤標注等。
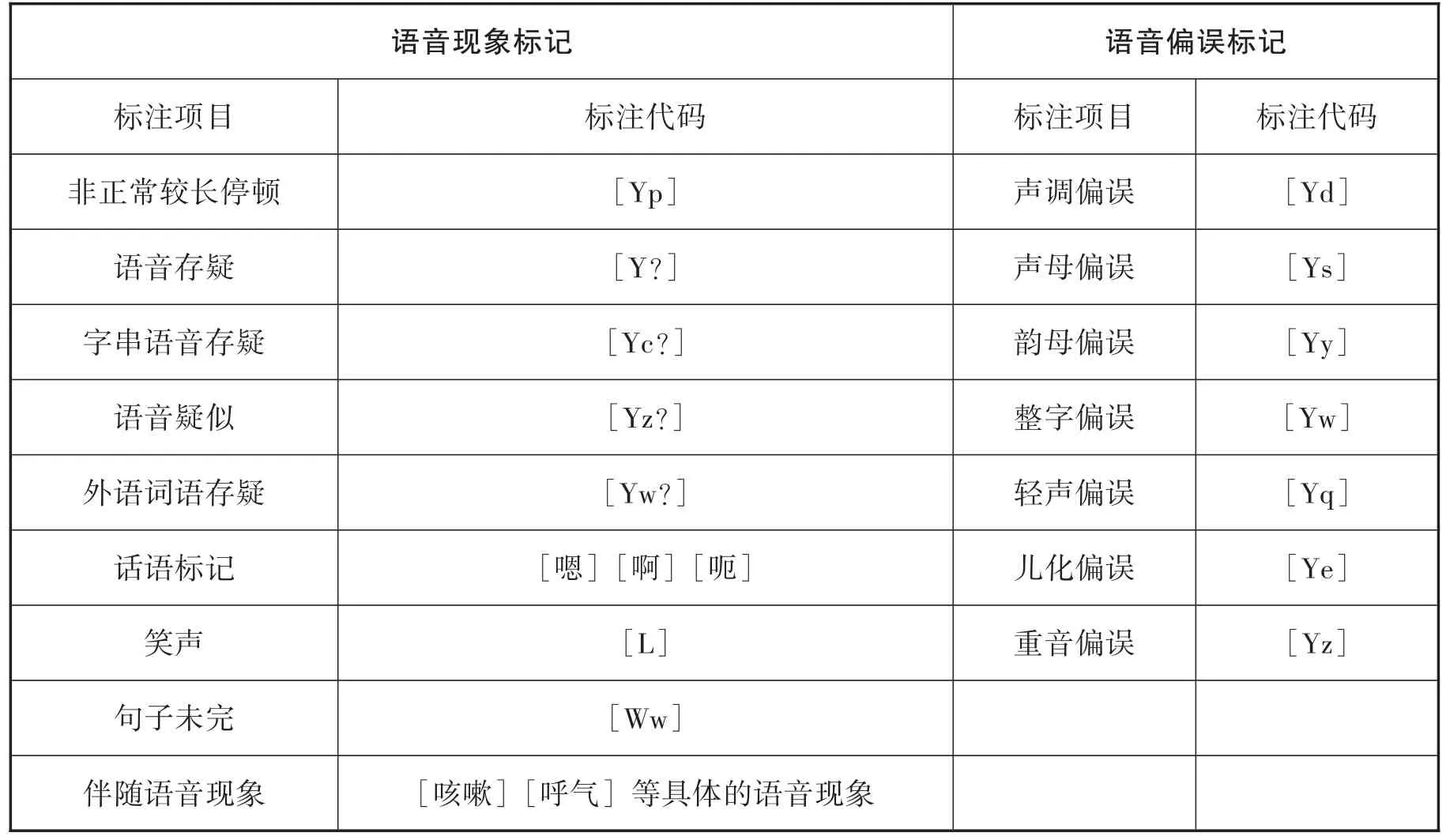
表2:語音標記詳表
3.4 KHSKKC檢索系統的開發
HSKKC檢索系統是基于Matlab2016a軟件開發的一個可執行文件,旨在為用戶提供便捷的查詢與統計功能。采用Matlab軟件開發檢索系統的優勢在于Matlab是一種解釋性語言,程序調試非常便捷;同時,Matlab軟件自帶大量的函數庫,非常便于復雜算法的開發。此外其后續的功能擴展容易實現,另外添加其他功能只需在原軟件上再加掛相應的處理函數即可。
該檢索系統可以生成語料庫的字表與詞表,也可以根據用戶的需求,使用信息組合進行檢索范圍的限定,對語料庫進行檢索查詢,對各項標注信息進行統計分析和數據提取。
4.語料庫建設中的難點和解決對策
4.1 轉寫難點及解決對策
口語語料轉寫是轉錄者對音頻語料的聽辨和轉錄的過程,需要真實準確地記錄學習者的口語表達內容。但由于很多考生特別是口語水平較低的考生發音不夠準確或者發音不到位,聲調、發音錯誤(如聲母偏誤/韻母偏誤等)或者模糊現象非常普遍比如例1,在音頻中,學習者將“旅行”的“旅”說成了“liu”,如果在轉寫時寫為“流行”,其實違背了說話者的本意,也會給后期的句法標注帶來困難。
例1:我的愛好是【旅】[Yy]行。去年,我去【旅】[Yy]行上海的時候,我對【旅】[Yd]行很感興趣,因為上海的夜景非常感動。
我們采取的處理對策是,如果轉寫者能夠準確判斷出此處對應的正確用字或用詞,則先錄入正字、正詞(即正確的字、正確的詞)再打上聲調偏誤或聲母偏誤/韻母偏誤等標記。如果轉寫者能夠聽清語音但由于表義模糊無法判斷考生所用字或詞,則以漢語拼音代替該字、詞。如果發音聽不清楚,無法判別正字,也無法替寫為拼音,則用無法識別的標記【】[Y?]來表示。
4.2 分詞和詞性標注的難點及解決對策
漢語中介語口語語料除存在語音偏誤、詞語和句法偏誤外,還有大量的停頓甚至中斷、重復和修復,導致機器自動分詞的效果極差。所以在現有的中介語口語語料庫建設中鮮有對語料進行分詞和詞性標注的。但在漢語中介語語料庫庫群建構理念下,為與筆語語料庫對齊,以便后期進行漢語學習者口筆語語料庫對照研究,我們選擇嘗試對口語語料進行分詞和詞性標注。
(1)對于預標記被分詞的處理
因為對口語語料轉寫的同時就進行了語音標注,這些標注對自動分詞產生極大的干擾,如例2。分詞后原文中所有的預標記都被切分(見例2)。為此,我們自編了程序,在人工校對分詞結果之前,先通過程序對標注文本進行清潔后再對其進行人工校對。
例2:我以前偶來偶爾參加朋友聚會,因為我最喜歡的我喜我最喜【歡】[Yd]在家【吃】[Yd]巧克力[L]。
自動分詞后:
我/r以前/f偶/d來/v偶爾/d參加/v朋友/n聚會/v,/w因為/p我/r最/d喜歡/v的/u我/r喜/Ag我/r最/d喜/Ag【/w歡/a】/w[/wYd/n]/w在家/v【/w吃/v】/w[/wYd/n]/w巧克力/n[/wL/n]/w./w
人工校對后:
我/r以前/f偶/d來/v偶爾/d參加/v朋友/n聚會/v,/w因為/p我/r最/d喜歡/v的/u我/r喜/Ag我/r最/d喜【歡】/v[Yd]/w在/p家/n【吃】/v[Yd]巧克力/n[L]。/w
(2)對于語素的處理
中介語口語語料中由于學習者在口語表達中有大量的停頓、重復或者修復,而產生了很多非“詞”的成分,這些成分有的是語素,有的是非語素字,在語料標注中要加以區分。如:
例3:或者/c我/r喜/Vg我/r也/d喜歡/v和/p姐姐/n聊天/v,/w但是/c現在/t我/r變/v我/r變化/v了/y,/w我/r喜歡/v參加/v朋友/n朋友/n們/k的/u聚會/v。/w
上述語料中由于學生自我修正出現了“變”和“喜”兩個修正項,前者標為動詞,后者標為語素。
(3)對于生造詞的處理
生造詞是二語學習者在表達中常見的偏誤,是學習者根據母語推演出或目的語泛化演變出的、漢語中不存在的“詞”(如下例中的“高學”)。那么到底要不要給生造詞標記詞性呢?如果不對其進行任何標記,在分詞中就可能會與其前/后的詞結合起來,造成分詞的麻煩。我們的處理策略是在語料標注中將生造詞標記為[Sz],但不加注詞性(如例4所示)。
例4:我/r覺得/v我/r的/u印象/n最/d深/a的/u一/m位/q老師/n是/v耐心/a的/u老師/n,/w我/r【高學】[Sz]的/u時候/n,/w我/r的/u學習/v成績/n不/d好/a,/w可是/c老師/n耐心/a等/v我/r,/w努力/v教/v我/r。/w
4.3 最大檢索化的處理
語料庫檢索軟件有轉寫語料查詢的功能,用戶可以根據需求檢索字、詞或者字符串。之前“韓國留學生漢語中介語發展語料庫(筆語)”的檢索軟件不能檢索到像“見……面”的用法,此次口語語料庫的檢索軟件對此進行了改進。此外,在對檢索軟件“轉寫語料查詢”功能進行測試時發現,由于語料中已有語音標記,如果一個詞中的某個語素有預標記的話,在“轉寫語料查詢”時,該詞所在語句無法檢索到。如例5中的“孤【單】[Yd]/a”,如要查詢“孤單”的使用情況,在“轉寫語料查詢”功能界面的查詢項直接輸入“孤單”,查詢不到“我/r在/p我/r我/r沒/d感到/v孤【單】[Yd]/a,/w”。為此,我們在檢索軟件后臺程序中將標注文本的預標記進行自動“清潔”,處理后,即使被檢索項有標記也能順利提取。
例5:但是/c但是/c參加/v朋友/n們/k的/u朋友/n們/k朋友/n聚會/v,/w我/r在/p我/r我/r沒/d感到/v孤【單】[Yd]/a,/w所以/c的/u自然/a的/u我/r也/d自然/a我/r經常/d參加/v朋友/n聚會/v。/w
5.本語料庫存在的問題與建設展望
韓國學習者漢語中介語口語語料庫的建設,目前來看,存在以下問題。
(1)語料庫需要進一步擴容。一是單純從數量上來講目前的語料規模還不夠大,與400余萬字的筆語語料數量相比差距較大。二是從語料來源看,目前主要是純HSK口試語料,形式不夠多樣。Eric Friginal,Joseph J.Lee等(2017)至少已采集了學術英語課堂上的學習者話語、英語會話訪談中的學習者話語、同伴反饋活動中的學習者話語等不同口語語料類型。因此,我們的語料庫下一步將拓展到日常交際口語、課堂表達口語等領域,現已搜集40小時以上的日常交際對話口語,隨后將不斷探索,以進一步豐富語料庫中的語料形式。
(2)需構建國別化漢語中介語口語語料庫。應將單國別的漢語學習者口語語料庫擴建為國別化的漢語中介語口語語料庫。所謂國別化語料庫不是多個單國別語料庫的疊加,而是一種建庫理念和范式,是以國別化研究為導向,以某個單國別語料庫建設為基礎,在單國別語料庫建設基礎上,根據不同國別學習者特點,對建庫原則、語料采集、標注規范等進行適應性調整,以鏈條延展式進行不同國別語料庫的建設。本次單國別的漢語學習者口語語料庫是國別化漢語中介語口語語料庫的先行探索,為下一步體系化建庫提供參考依據。同時,語料采集的方式也應從松散的較為隨意的各國別學習者語料采集,到更為嚴密的共同主題的不同國別學習者語料采集。這一點Gaёtanelle Gilquin,Sylvie De Cock & Sylviane Granger等(2010)已經有了良好的示范。
(3)在人工智能飛速發展的現在,母語語料庫(Native Corpora)已可實現自動錄入,文本加工也日益智能化。漢語中介語語料庫受制于學習者的偏誤干擾,在語料的錄入、加工、處理等方面仍然是人工化多于智能化。口語語料的轉錄則因學習者語音的偏誤或模糊不清導致效率低下。如何能夠借用更為智能化的手段加快口語語料的處理,也是下一步應探索的方向。
