基于XGBoost的火電機組污染物排放預測研究
2020-04-06 04:45:34李鐘欽
發電設備 2020年2期
關鍵詞:模型
周 虹, 陳 斌, 李鐘欽, 高 飛
(1. 上海漕涇熱電有限責任公司, 上海 201507;2. 上海發電設備成套設計研究院有限責任公司, 上海 200240)
2017年火電機組發電量占全國總發電量的70%以上,目前火力發電在我國發電結構中依然占據主導地位,但是火力發電過程中會排放出大量的粉塵、SO2及NOx等污染物[1-2]。隨著我國電力體制改革的不斷深化和節能減排的不斷推進,發電廠越來越重視污染物排放控制[3-4]。
污染物排放預測是控制污染物排放的一項重要工作,機組運行人員可以根據預測的污染物排情況來進行機組生產調度,及時降低污染物排放量[5-7]。
在現有的對污染物排放預測的研究中,學者分別從污染物排放的時序數據和特征、當前時刻機組運行的狀態等角度出發,探索不同方法在預測機組污染物排放方面的效果。任玉瓏等[8]使用Rains-Asia模型,從宏觀角度對西部地區未來10 a的SO2排放進行預測并提出相應建議。張書豪[9]基于灰色理論結合BP(Back Propagation)神經網絡模型和灰色模型(GM),提出了以GM(1,1)、GM(0,4)及BP神經網絡為主要結構的污染物排放預測模型。蘇銀皎等[10]提出使用改進小波神經網絡模型預測火電廠污染物的排放,并優化了特征提取方法,提升了神經網絡的輸入特征數據性能。楊訓政等[11]將深度學習中的長短期記憶(LSTM)網絡算法應用于污染物排放預測,同樣獲得不錯的效果。梁肖等[12]基于LSTM網絡算法,使用了配對的遺忘門和輸出門,優化了LSTM網絡算法的神經元結構,提出將改進型的LSTM循環神經網絡(ALSTM-RNN)算法用于火電機組污染物排放預測。
上述文獻所使用的方法是針對污染物排放時序數據進行預測,然而在實際機組運行過程中,影響污染物排放的因素除了時序數據本身的特征外,還有機組出力,以及季節、天氣、溫度等外界環境的影響,基于數值的算法模型則無法完成此任務。筆者針對GE 9F燃氣輪機(簡稱燃機)機組污染物排放影響因素較多的特點,提出了一種基于極端梯度提升(XGBoost)的算法,實現了污染物排放預測。
1 XGBoost算法
XGBoost算法是一種可擴展的端到端基于樹的Boosting系統,是一種基于AdaBoost算法和梯度提升決策樹(GBDT)算法演化而來的提升算法。
1.1 GBDT算法
Boosting分類器屬于機器學習中的集成學習模型,其思想原理是利用很多個效率高但準確率相對較低的樹模型整合成為一個準確率較高的模型。GBDT算法是由FRIEDMAN J H[13]于2001年提出,該算法由梯度提升和決策樹整合而成。GBDT算法的具體流程是:
(1) 初始化。基于經驗估計損失函數極小化的常數值。
(2) 訓練。訓練樹的構成和參數:計算當前模型中損失函數負梯度值,作為殘差的估計;估計回歸樹葉子節點的區域,擬合殘差的近似值;利用線性搜索,估計葉子節點區域的值,目的是使損失函數達到極小化;更新回歸樹模型。
(3) 模型生成。滿足條件的回歸樹模型即最終模型,輸出模型。
1.2 XGBoost算法
通常來說,目標函數的優化效果決定了模型的準確性,目標函數優化效果越好,預測值就越接近真實值,模型的泛化能力也就越好。
不同于傳統的GBDT算法只利用一階導數信息的方式,XGBoost算法對損失函數進行了二階泰勒展開,并且在目標函數外引入了正則化項從整體上求最優解,以權衡目標函數的下降程度和模型的復雜程度,避免模型的過度擬合。XGBoost算法的原理是將原始數據集分割成多個子數據集,將每個子數據集隨機分配給基分類器進行預測,然后將弱分類的結果按照一定的權重進行計算來預測最后的結果。
首先,定義一個目標函數O為:
O(Φ)=L(Φ)+Ω(Φ)
(1)
式中:L為訓練損失函數;Ω為正則化項;Φ為模型參數,如最大樹深度、最小葉子節點權重等。
其次,確定訓練損失函數和正則化項。常用的損失函數有均方根誤差損失函數、log對數損失函數、指數損失函數、絕對值損失函數,由于均方根誤差ERMSE對結果中特大或特小的誤差反應較敏感,因此筆者選用ERMSE作為損失函數,其計算公式為:
(2)
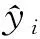
回歸樹通過優化剪枝和控制數的深度來預測,其原理是控制模型的復雜度和正則化的極大似然估計。筆者所采用的正則化項也是基于這個思想,通過采用葉子節點數目T和葉節點分數的L2范數平方來定義正則化項:
(3)
式中:γ為閾值,是葉子節點數T的系數,可理解為對樹做了前剪枝;λ為正則化項里葉節點分數的L2范數平方的系數,用于防止過擬合;wj是樹葉上的分數向量。
根據以上訓練損失函數和正則化項,可以得出預測優化的目標函數為:
(4)
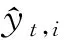
(5)
式中:ft(xi)為第t棵樹。
再進行二階泰勒展開后,可以得到對于第t次的目標函數Ot(Φ)為:
(6)
對目標函數進行二次泰勒展開后可以求解的目標函數只依賴于每個數據點在誤差函數的一階導數和二階導數,從而能更快并準確地得到最優的預測值。
2 污染物排放預測
2.1 特征提取
筆者使用的原始數據主要包括2 h內的天然氣質量流量、燃機有功功率、NOx排放質量濃度、日期、外界環境參數等,用于預測未來1 h內的NOx排放質量濃度,共形成46個特征參數。部分提取特征參數見表1。
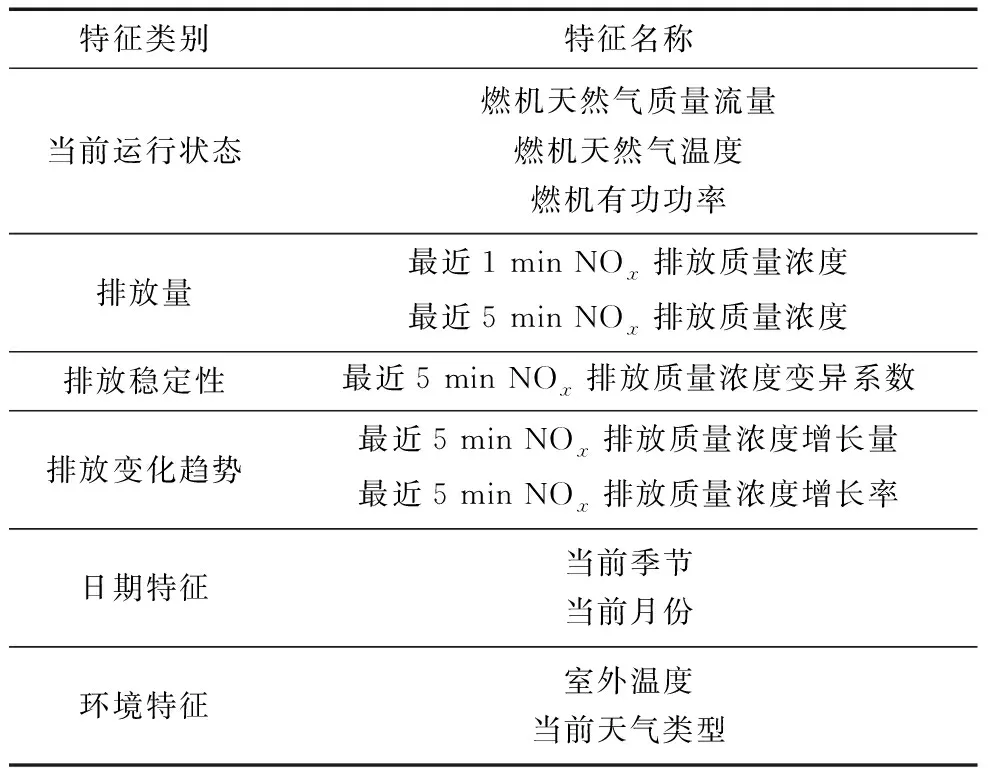
表1 部分提取特征參數
2.2 基于XGBoost算法的模型訓練
對原始數據進行特征提取后,轉換成獨熱編碼的方式,將其輸入到XGBoost算法模型中進行訓練。算法流程圖見圖1。
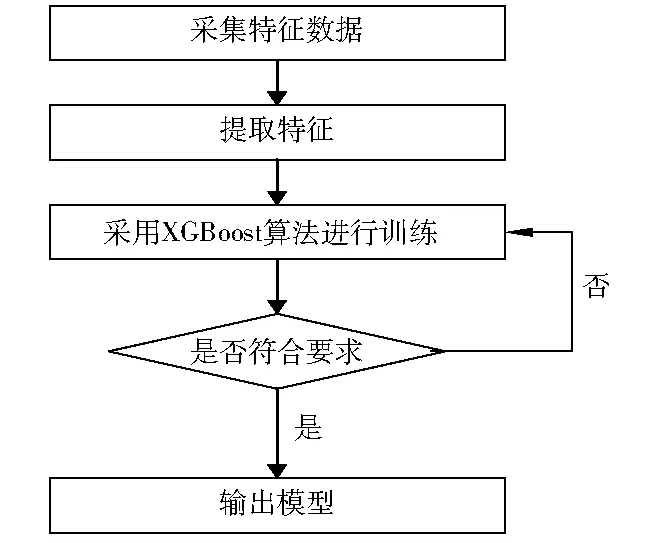
圖1 算法流程圖
筆者選擇ERMSE作為判斷預測誤差的標準,若訓練結果不滿足需求,則不斷調整模型參數重復訓練,其中可調整的參數主要包括最大樹深度、最小葉子節點權重、學習速率等。
3 結果及分析
筆者對比了不同參數下訓練結果的差異,最大樹深度對影響整個模型的復雜程度的影響見圖2。由圖2可知:隨著訓練次數的增加,ERMSE不斷下降,在訓練100次后基本穩定;對比不同最大樹深度的差異,最大樹深度取6、10、20時,隨著最大樹深度的增加,ERMSE不斷增大,因此最大樹深度最終選擇在6左右即可。
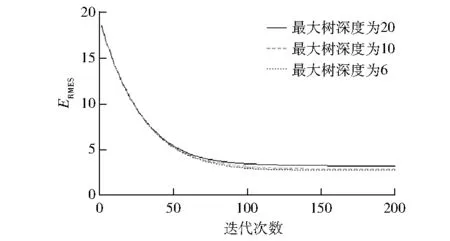
圖2 不同最大樹深度對應的訓練結果
最小葉子節點權重可以用于防止模型過擬合,其對ERMSE的影響見表2。由表2可知:當最小葉子節點權重低于0.5時,模型ERMSE基本不變,因此最小葉子節點權重最終選擇在0.3~0.5即可。
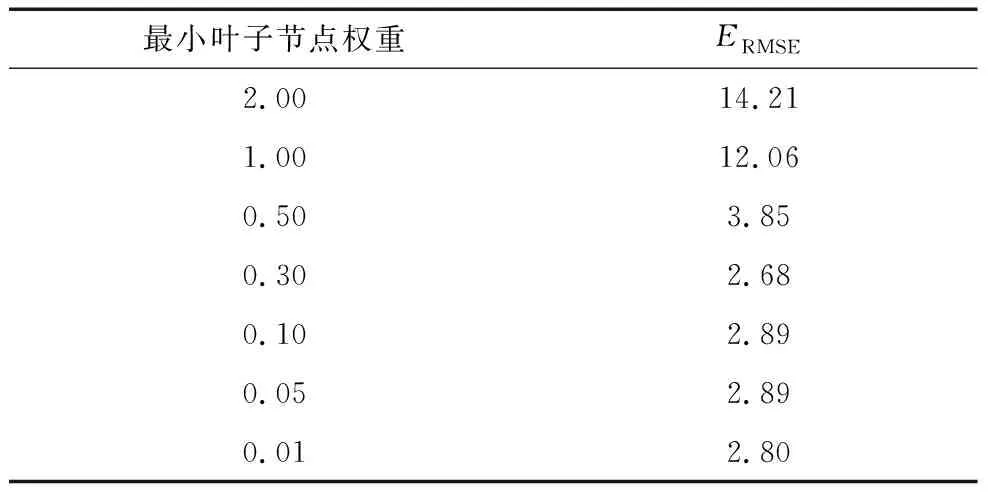
表2 最小葉子節點權重對ERMSE的影響
在最終選定模型中,最大樹深度為6,學習速率為0.02,最小葉子節點權重為0.3,輸入特征共15個,訓練最終模型。按照重要性排列的前7個特征參數見圖3。
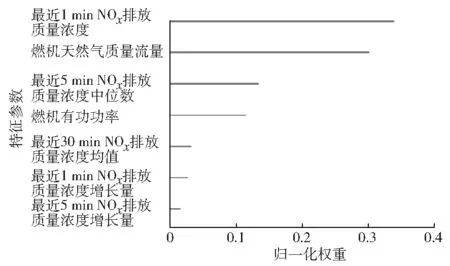
圖3 按照重要性排列的前7個特征參數
將數據按照樣本數量比為7∶3進行劃分訓練集和測試集,NOx排放質量濃度預測結果見圖5。ERMSE為2.43,平均相對誤差為15.9%。
總體上,基于XGBoost算法的污染物排放預測能夠滿足多源數據條件下的預測需求,能夠同時處理數值型和字符型的數據源,其預測結果的準確度也處于較高水平。
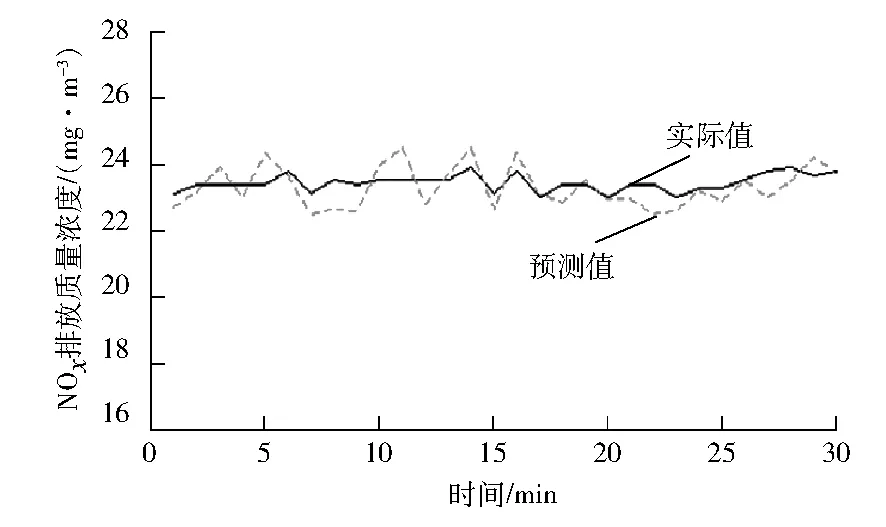
圖4 預測值與實際值對比
4 結語
筆者針對火電機組預測污染物排放問題,提出了一種使用XGBoost算法進行火電機組污染物排放預測的方法,該方法融合了機組運行數據特征,以及季節、天氣、溫度等外部數據特征,建立了預測模型,針對NOx排放質量濃度的實際值和預測值進行了誤差計算,最終整體ERMSE為2.43,平均相對誤差為15.9%,其預測值能夠為實際工作提供有效參考。
由于數據資源有限,所研究內容未涉及壓氣機進口空氣參數等強特征參數,未來可進一步擴展數據覆蓋面以提高模型泛化能力;所采用方法中特征提取部分依然依賴人為經驗,特征的全面性有待提高,下一步工作將研究使用卷積神經網絡模型來自動提取優化特征,并訓練模型,以進一步提高預測準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
